
안녕하세요!
오늘은 사회행동과학에서의 다층분석(Multilevel Modeling)에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 다층모형(Multilevel Model)이란 무엇인가요?
여러분, 러시아의 전통 인형 ‘마트료시카’를 아시나요? 큰 인형 안에 작은 인형이, 그 안에 더 작은 인형이 들어있는 구조입니다. 우리의 사회현상, 특히 교육 현장의 데이터도 이와 같은 내포(Nesting) 구조를 가집니다.
예를 들어 볼까요?
- 학생들(작은 인형)은 학급(중간 인형)에 속해 있고, 학급은 다시 학교(큰 인형)에 속해 있습니다.
- 한 학생의 성적은 개인의 노력(학생 수준)에도 영향을 받지만, 훌륭한 선생님이나 학교의 예산(학교 수준)에도 영향을 받습니다.
과거에는 이런 데이터를 분석할 때 곤란을 겪었습니다. 학생들의 데이터가 서로 ‘독립적’이지 않음에도 불구하고, 분석 기술과 소프트웨어의 부족으로 이를 무시하고 분석했기 때문입니다. 하지만 1980년대와 90년대에 다층모형이 빠르게 도입되면서 , 각 수준(Level)별로 절편(기본 점수)과 기울기(변수의 영향력)가 다를 수 있음을 인정하고 이를 수식으로 아름답게 풀어낼 수 있게 되었습니다.
2. 분산의 분리와 급내상관계수(ICC)
어떤 학교의 수학 시험 점수들이 있다고 합시다. 점수들이 서로 다른 이유(분산)는 무엇일까요?
- 학교가 달라서 (학교 간 분산): 어떤 학교는 전반적으로 성적이 높고, 어떤 학교는 낮을 수 있습니다.
- 학생이 달라서 (학교 내 분산): 같은 학교 안에서도 공부를 잘하는 학생과 못하는 학생이 있습니다.
이를 수식으로 나타낸 기초 모형(무조건 모형, Null Model)은 다음과 같습니다.
- 1수준 (학생 수준): (학생 의 점수 는 자신이 속한 학교 의 평균 에 학생 개인의 오차 를 더한 값입니다.)
- 2수준 (학교 수준): (학교 의 평균 는 전체 평균 에 그 학교만의 고유한 편차 를 더한 값입니다.)
이를 하나로 합치면 전체 점수가 어떻게 구성되는지 한눈에 볼 수 있습니다.
여기서 급내상관계수(ICC, Intraclass Correlation)라는 아주 중요한 개념이 등장합니다. 전체 점수 차이 중에서 ‘학교 간의 차이’가 차지하는 비율을 의미합니다.
교수님의 팁! 💡 미국 대중들은 대체로 “좋은 학교”와 “나쁜 학교”의 차이가 엄청나게 크다고 생각합니다. 즉, 학교 간 분산이 클 것이라(ICC가 높을 것이라) 예상하죠. 하지만 실제 공립학교 데이터를 분석해보면, 학교 간의 차이는 전체의 20~30%에 불과하고, 나머지 70~80%는 같은 학교 내 학생들 간의 차이입니다! 다층분석은 이런 직관의 오류를 데이터로 바로잡아 줍니다.
3. 다층모형의 수식 이해: 학교 환경은 학생에게 어떤 영향을 미칠까?
이제 조금 더 나아가서, 학생의 특성(예: 성별, Sex)과 학교의 특성(예: 무상급식 비율, FSL – 가난한 학생이 얼마나 많은지를 나타내는 지표)을 모형에 넣어보겠습니다.
- 1수준 (학생): 학교 에 속한 학생 $i$의 성적 여기서 는 학교 의 평균 성적(절편)이고, 는 성별이 성적에 미치는 영향력(기울기)입니다. 학교마다 이 값이 다를 수 있습니다.
- 2수준 (학교):
학교의 무상급식 비율()이 학교의 평균 성적()뿐만 아니라, 성별에 따른 성적 차이()에도 영향을 준다는 가설을 세운 것입니다. 여기서 은 학생 수준의 성별과 학교 수준의 FSL이 만나는 상호작용(Interaction) 효과를 의미합니다.
4. 예측변수의 중심화 (Centering)
다층분석에서 절편()은 매우 중요합니다. 다음 단계(2수준)에서 종속변수 역할을 하기 때문이죠. 회귀분석에서 절편은 “모든 예측변수가 0일 때의 예측값”입니다. 만약 ‘키(Height)’로 ‘몸무게(Weight)’를 예측하는데, 단순히 변수를 그대로 쓰면 “키가 0cm일 때의 몸무게는 -300파운드”라는 황당한 결과가 나옵니다.
이런 문제를 해결하기 위해 평균 중심화(Mean Centering)를 합니다. 변수값에서 평균을 빼주는 것이죠. 이렇게 하면 변수값이 0일 때의 의미가 “평균적인 특성을 가졌을 때”로 바뀌어, 절편이 “평균적인 학생의 성적”이라는 아주 유용하고 직관적인 의미를 갖게 됩니다.
5. 모의 데이터 생성 및 R / jamovi 실습 스토리
자, 이제 배운 것을 직접 실습해 볼까요?
[가상의 연구 스토리]
김 교수는 20개의 중학교에서 각각 30명씩, 총 600명의 학생 데이터를 수집했습니다.
- 종속변수: 수학 성취도 (Math_Score)
- 1수준 변수 (학생): 주당 자기주도학습 시간 (Study_Time, 평균중심화 완료)
- 2수준 변수 (학교): 해당 학교의 무상급식 대상자 비율 (FSL_Ratio, 비율이 높을수록 저소득층 밀집 지역)
연구 가설:
- 자기주도학습 시간이 길수록 수학 점수가 높을 것이다.
- 무상급식 비율(FSL_Ratio)이 높은 학교일수록 전반적인 수학 평균이 낮을 것이다.
- 무상급식 비율이 높은 학교에서는 자기주도학습 시간의 효과(기울기)가 줄어들 것이다 (학교 인프라 부족 등의 이유로).
5-1. R을 활용한 모의 데이터 생성 및 분석
아래 R 코드를 실행하시면, 이론에 완벽히 부합하는 모의 데이터를 생성하고 다층분석을 수행할 수 있습니다.
R
# 필요한 패키지 로드
if(!require(lme4)) install.packages("lme4")
if(!require(lmerTest)) install.packages("lmerTest")
if(!require(ggplot2)) install.packages("ggplot2")
library(lme4)
library(lmerTest)
library(ggplot2)
# 재현성을 위한 시드 설정
set.seed(2026)
# 데이터 구조 설정
n_schools <- 20 # 학교 수
n_students <- 30 # 학교당 학생 수
N <- n_schools * n_students
# 2수준 데이터 (학교) 생성
school_id <- rep(1:n_schools, each = n_students)
# FSL 비율 (0.1 ~ 0.5 사이) 중심화
FSL_Ratio <- rep(runif(n_schools, 0.1, 0.5), each = n_students)
FSL_c <- FSL_Ratio - mean(FSL_Ratio)
# 학교 수준 오차 (Random Effects)
u0 <- rep(rnorm(n_schools, mean=0, sd=5), each = n_students) # 절편 오차
u1 <- rep(rnorm(n_schools, mean=0, sd=1), each = n_students) # 기울기 오차
# 1수준 데이터 (학생) 생성
# 자기주도학습 시간 (중심화)
Study_Time <- rnorm(N, mean=10, sd=3)
Study_c <- Study_Time - mean(Study_Time)
# 학생 수준 오차
e_ij <- rnorm(N, mean=0, sd=8)
# 고정 효과 (Fixed Effects) 모수 설정
gamma_00 <- 70 # 전체 평균 점수
gamma_01 <- -15 # FSL이 절편에 미치는 영향 (음수: 가난한 학교일수록 점수 낮음)
gamma_10 <- 3 # 학습 시간의 평균 기울기
gamma_11 <- -2 # FSL이 기울기에 미치는 영향 (부적 상호작용)
# 종속 변수 (수학 점수) 계산
Math_Score <- (gamma_00 + gamma_01 * FSL_c + u0) +
(gamma_10 + gamma_11 * FSL_c + u1) * Study_c +
e_ij
# 데이터 프레임 생성
my_data <- data.frame(school_id = as.factor(school_id),
Math_Score = Math_Score,
Study_c = Study_c,
FSL_c = FSL_c)
# CSV로 저장 (jamovi 실습용)
write.csv(my_data, "chap29.csv", row.names = FALSE)
# R 다층분석 (lme4 활용)
model <- lmer(Math_Score ~ Study_c * FSL_c + (1 + Study_c | school_id), data=my_data)
summary(model)
# 간단한 시각화: 학교별 기울기 차이
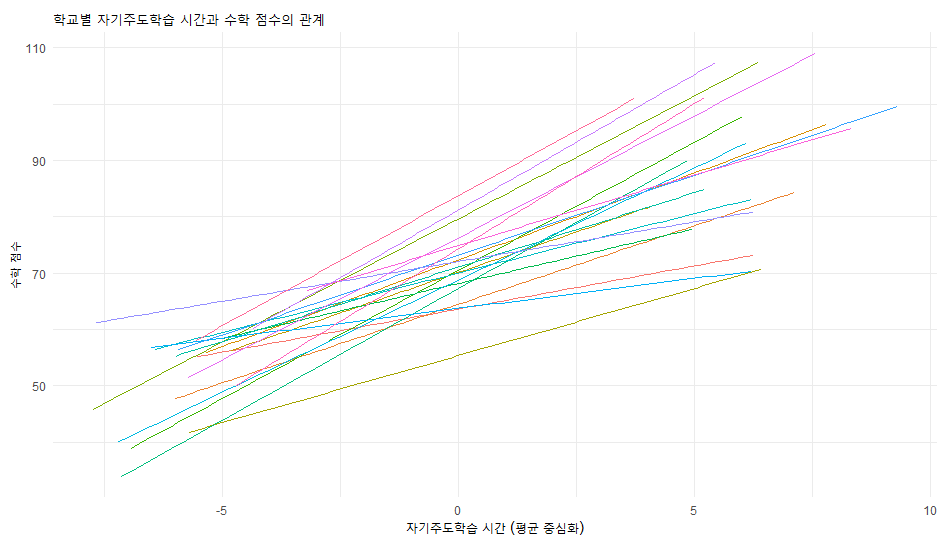
ggplot(my_data, aes(x = Study_c, y = Math_Score, color = school_id)) +
geom_smooth(method = "lm", se = FALSE, size = 0.5) +
theme_minimal() +
labs(title = "학교별 자기주도학습 시간과 수학 점수의 관계",
x = "자기주도학습 시간 (평균 중심화)", y = "수학 점수") +
theme(legend.position = "none")
위 코드를 통해 생성된 데이터의 형태는 대략 다음과 같습니다.
| school_id | Math_Score | Study_c | FSL_c |
| 1 | 75.2 | 1.2 | -0.15 |
| 1 | 68.5 | -0.8 | -0.15 |
| … | … | … | … |
| 20 | 58.1 | -2.1 | 0.22 |
5-2. jamovi를 활용한 다층분석 단계별 가이드
R이 부담스러우신 분들은 방금 생성한 CSV 파일을 jamovi에서 불러와 손쉽게 클릭만으로 분석할 수 있습니다! (jamovi의 GAMLj 모듈 설치가 선행되어야 합니다.)
- 데이터 불러오기: jamovi를 열고 위에서 만든
school_multilevel_data.csv를 엽니다.school_id변수의 데이터 타입을 ‘Nominal(명목형)’로 바꿔주세요. - 분석 메뉴 선택: 상단 탭에서
Linear Models➔Mixed Model(GAMLj)을 클릭합니다. - 변수 투입:
- Dependent Variable (종속변수):
Math_Score - Covariates (공변량/연속형 예측변수):
Study_c,FSL_c - Cluster Variables (군집 변수):
school_id
- Dependent Variable (종속변수):
- 고정 효과 (Fixed Effects) 설정: *
Study_c,FSL_c를 차례로 넣고, 두 변수를 함께 선택하여Study_c * FSL_c(상호작용항)도 모형에 추가합니다. - 무선 효과 (Random Effects) 설정:
- 기본적으로 절편(
Intercept)이school_id내에 들어가 있도록 설정되어 있습니다. - “학교마다 학습 시간의 효과도 다를 수 있다”는 가설을 검증하기 위해, 왼쪽 목록에서
Study_c를school_id클러스터 안으로 이동시킵니다.
- 기본적으로 절편(
- 결과 해석: 우측 결과 창에서 ‘Fixed Effects Parameters’ 표를 확인합니다.
Study_c의 $p$-value가 유의미한지,Study_c * FSL_c상호작용항이 유의미하여 “무상급식 비율이 높은 학교일수록 학습 시간의 효과가 정말로 반감되는지” 확인할 수 있습니다.
마무리
오늘은 다층모형이 어떻게 내포된 데이터를 아름답게 풀어내는지, 왜 중심화가 필요한지, 그리고 R과 jamovi를 이용해 현장 데이터를 어떻게 요리할 수 있는지 알아보았습니다. 학교 현장뿐만 아니라 개별 대상의 장기간 관찰(반복측정)이나 소규모 그룹 연구에도 다층모형은 강력한 무기가 됩니다.
어떠신가요? 수식 속에 숨겨진 현장의 스토리가 조금은 입체적으로 다가오셨기를 바랍니다. 다음 분석도 저와 함께 즐겁게 헤쳐나가 보시죠! 도움이 필요하시면 언제든 말씀해 주세요.
참고문헌
- Rindskopf, D. (2014). Multilevel Models in the Social and Behavioral Sciences. In The SAGE Handbook of Multilevel Modeling (pp. 521-539). SAGE Publications.