
안녕하세요!
오늘은 개체 내 오차 구조(Within-Individual Error Structures)의 복잡성과 모델링에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
우리가 학교에서 학생들의 성장을 추적할 때(종단 연구), 단순히 “평균 점수가 올랐나?”만 보는 것은 반쪽짜리 분석입니다. 학생 개개인이 어떻게 변화하는지, 그 변화의 폭(분산)은 일정한지, 어제의 성적이 오늘의 성적에 얼마나 영향을 미치는지(상관)를 파악해야 합니다. 제공해주신 텍스트는 이러한 공분산 구조(Covariance Structure)를 어떻게 모델링할 것인가에 대한 깊이 있는 통찰을 제공합니다.
1. 교육 현장의 예시: “읽기 유창성 성장 프로젝트”
이해를 돕기 위해 가상의 시나리오를 설정하겠습니다.
상황: A 초등학교에서 3학년 학생 50명을 대상으로 ‘읽기 유창성(1분당 읽은 단어 수)’을 1년 동안 4회(3월, 6월, 9월, 12월) 측정했습니다.
핵심 질문:
- 모든 학생의 읽기 실력 격차(분산)는 3월이나 12월이나 똑같을까요? (등분산성)
- 3월 성적이 좋은 학생은 6월에도 좋을까요? 12월까지 그 영향이 갈까요? (계열 상관)
2. 기본 모델과 개념 (The General Model)
우리는 데이터를 다음의 선형 회귀 모델로 표현할 수 있습니다.
- : 학생들의 읽기 점수 벡터
- (고정 효과): 전체 학생들의 평균적인 성장 곡선 (예: 시간이 지날수록 점수가 오른다).
- (임의 효과): 학생 개인별 특성 (예: 어떤 학생은 시작부터 잘하고, 어떤 학생은 성장 속도가 빠르다).
- (오차 항): 설명되지 않는 나머지 변동. 오늘의 핵심 주제는 바로 이 의 구조인 를 파헤치는 것입니다.
3. 데이터 시각화와 진단 (Diagnostics)
모델링을 하기 전에 눈으로 확인해야 합니다. 텍스트에서는 프로파일 도표(Profile Plot), OSM, PRISM을 추천합니다.
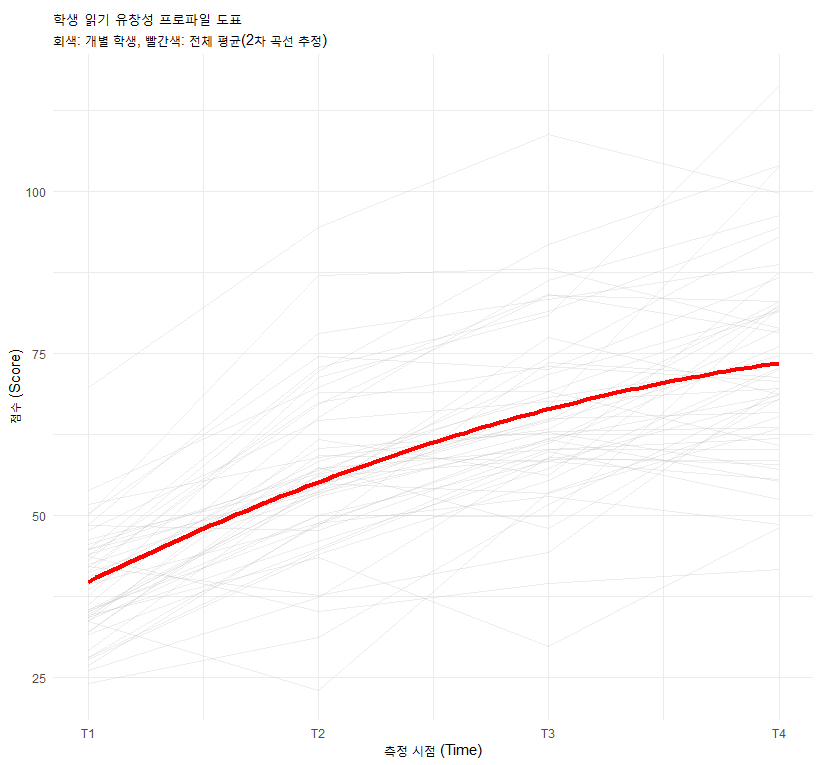
3.1 프로파일 도표 (Profile Plot)
학생 개개인의 성장 궤적을 그린 그래프입니다.
- 해석: 선들이 서로 꼬이지 않고 나란히 간다면? 학생 내 상관이 높음(잘하던 애가 계속 잘함).
- 분산: 시간이 갈수록 선들의 폭이 넓어진다면? 이분산성(Heterogeneity) 존재.
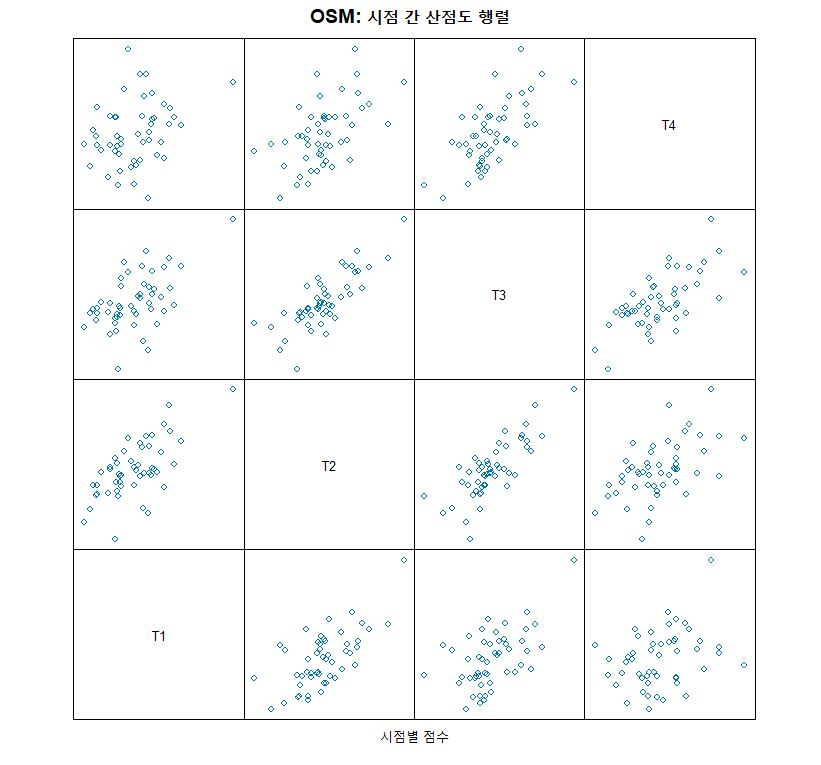
3.2 OSM (Ordinary Scatterplot Matrix)
모든 시점 간의 산점도 행렬입니다.
- 특징: 대각선에서 멀어질수록(시간 격차가 클수록) 상관관계가 어떻게 변하는지 보여줍니다. 읽기 데이터에서는 보통 시간이 지날수록(대각선에서 멀어질수록) 상관이 낮아지는 패턴을 보입니다.
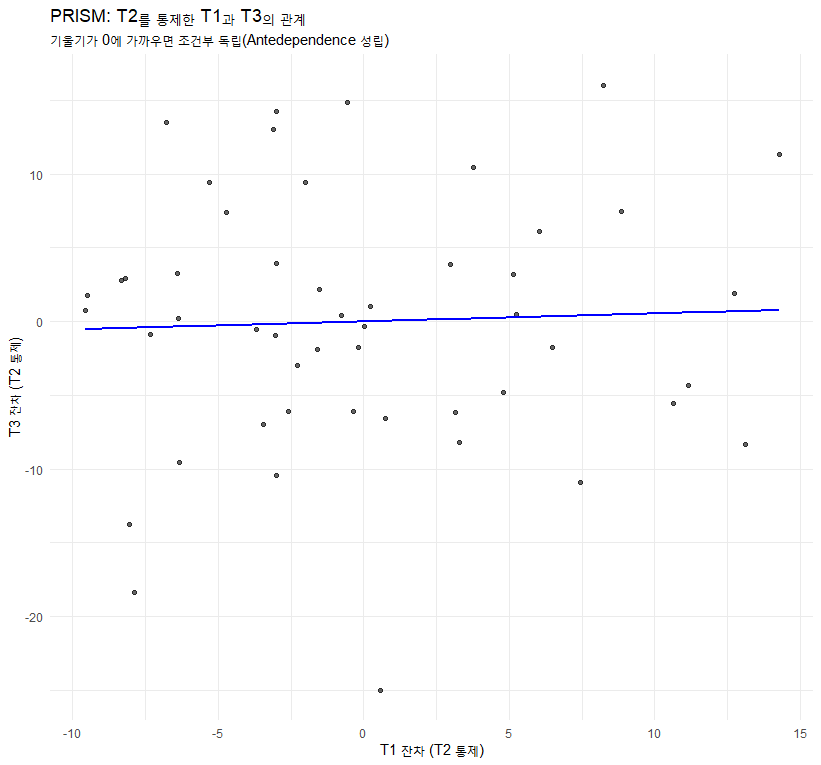
3.3 PRISM (Partial Regression-on-Intervenors Scatterplot Matrix)
이것은 저자(Zimmerman)가 강조하는 고급 도구입니다.
- 개념: 과 의 관계를 볼 때, 중간 시점인 의 영향을 제거하고(통제하고) 봅니다.
- 해석: 만약 를 통제했을 때 과 의 관계가 사라진다면(무작위 산포), 이는 “조건부 독립”을 의미하며, Antedependence 모델이나 AR(1) 모델이 적합하다는 강력한 신호입니다.
4. 공분산 구조 모델링: 유연성 vs 간명성
어떤 모델을 선택해야 할까요? 너무 단순하면 현실을 반영 못 하고(과소적합), 너무 복잡하면 추정이 어렵습니다(과대적합). 이 둘 사이의 균형(Balance)이 핵심입니다.
4.1 가장 단순한 모델들 (Parsimonious)
- 복합 대칭 (Compound Symmetry, CS):
- 가정: 3월의 분산 = 12월의 분산. 3월-6월 상관 = 3월-12월 상관. 모든 것이 일정함.
- 교육적 현실: 글쎄요, 보통 고학년이 될수록 격차(분산)가 커지고, 먼 시점 간의 상관은 떨어지기 때문에 현실적이지 않을 수 있습니다.
- 구조:
- 1차 자기회귀 (AR(1)):
- 가정: 바로 전 시험 성적이 다음 시험에 가장 큰 영향을 줌. 시간이 멀어질수록 상관이 지수적으로 감소 ().
- 교육적 현실: 성장 데이터에 매우 적합합니다. 단, 분산이 일정하다고 가정하는(Homogeneous) 한계가 있습니다.
4.2 중간 단계의 모델들 (Heterogeneous & Banded)
- 이분산 자기회귀 (Heterogeneous AR, ARH(1)):
- AR(1)과 같지만, 시점별로 분산(시험 점수의 퍼짐 정도)이 다를 수 있게 허용합니다. 학년이 올라갈수록 실력 격차가 벌어지는 현상을 설명하기 좋습니다.
- 토플리츠 (Toeplitz, TOEP):
- AR(1)처럼 시간이 지날수록 상관이 변하지만, 그 패턴을 처럼 강제로 수학적 공식에 넣지 않고 자유롭게 둡니다(Band 구조). 더 유연하지만 파라미터가 많아집니다.
4.3 가장 유연한 모델들 (Flexible)
- 무구조 (Unstructured, UN):
- 가정: 아무런 제약이 없습니다. 모든 시점의 분산과 상관을 각각 다 추정합니다.
- 장단점: 가장 정확하지만, 측정 시점이 많아지면 추정해야 할 파라미터가 기하급수적으로 늘어나() 모델이 터질 수 있습니다.
- Antedependence (AD) 및 Structured AD (SAD) 모델:
- 텍스트의 핵심 제안: 1차 자기회귀(AR1)는 너무 딱딱하고, 무구조(UN)는 너무 무겁습니다.
- AD 모델: 시점 간의 “조건부 독립”을 가정하여 파라미터를 줄이면서도, 비정상성(Non-stationarity: 분산과 상관이 변하는 성질)을 허용하는 똑똑한 모델입니다.
- SAD 모델은 이를 더 구조화하여 파라미터 수를 수준으로 줄여 간명성을 확보합니다.
5. 분석 실습: R과 jamovi 활용
이제 가상의 “읽기 유창성 데이터”를 생성하고, 위에서 배운 모델들을 비교 분석해 보겠습니다.
(참고: jamovi의 GAMLj 모듈이나 Linear Mixed Models는 CS, AR1, UN, Toeplitz 등을 지원하지만, PRISM 도표나 고급 AD 모델은 R이 필요합니다. 따라서 R 코드를 중심으로 설명하고 jamovi 활용법을 덧붙이겠습니다.)
5.1 R을 이용한 모의 데이터 생성 및 시각화
R
# 필요한 라이브러리 로드
library(MASS)
library(nlme)
library(lattice)
library(ggplot2)
# --- 1. 가상의 읽기 유창성 데이터 생성 (Backstory) ---
# 50명의 학생, 4회 측정 (t=1, 2, 3, 4)
# 가정: 시간이 갈수록 분산이 커지고(이분산), 상관은 멀어질수록 낮아짐(AR 구조)
set.seed(2024)
N <- 50
Time <- 4
Mean_Vector <- c(40, 55, 65, 72) # 시간별 평균 점수 상승
Sigma <- matrix(0, Time, Time)
# 공분산 행렬 생성 (ARH(1) 구조와 유사하게 설정)
# 분산은 100, 140, 180, 220으로 증가
vars <- c(100, 140, 180, 220)
cor_rho <- 0.7 # 1-lag 상관계수
for(i in 1:Time){
for(j in 1:Time){
Sigma[i,j] <- sqrt(vars[i]) * sqrt(vars[j]) * (cor_rho^abs(i-j))
}
}
# 데이터 생성
data_matrix <- mvrnorm(n = N, mu = Mean_Vector, Sigma = Sigma)
colnames(data_matrix) <- c("T1", "T2", "T3", "T4")
df_wide <- data.frame(ID = 1:N, data_matrix)
# Long format으로 변환 (분석용)
df_long <- reshape(df_wide, direction = "long", varying = list(2:5),
v.names = "Score", timevar = "Time", times = 1:4)
df_long <- df_long[order(df_long$ID, df_long$Time), ]
# --- 2. 진단 시각화 ---
# (1) 프로파일 도표 (Profile Plot) [cite: 65]
ggplot(df_long, aes(x = Time, y = Score, group = ID)) +
geom_line(alpha = 0.5) +
geom_smooth(aes(group = 1), method = "loess", color = "red", size = 1.5) +
labs(title = "학생 읽기 유창성 프로파일 도표", subtitle = "시간에 따른 개별 성장 곡선") +
theme_minimal()
# (2) OSM (Ordinary Scatterplot Matrix)
splom(df_wide[,2:5],
main = "OSM: 시점 간 산점도 행렬",
pscales = 0, varname.cex = 0.8)
# (3) PRISM (간략화된 개념적 구현) [cite: 127]
# T1과 T3의 관계에서 T2를 통제한 편상관을 시각적으로 확인
res_T1_T2 <- residuals(lm(T1 ~ T2, data = df_wide))
res_T3_T2 <- residuals(lm(T3 ~ T2, data = df_wide))
plot(res_T1_T2, res_T3_T2,
main = "PRISM 예시 (T1 vs T3 | T2)",
xlab = "T1 | T2 residuals", ylab = "T3 | T2 residuals")
abline(lm(res_T3_T2 ~ res_T1_T2), col="blue")
# 설명: 이 점들이 무작위로 퍼져있으면(기울기가 0에 가까우면) 조건부 독립 -> AD 모델 적합
# --- 3. 모델 적합 및 비교 (gls 함수 사용) ---
# Model 1: 복합 대칭 (Compound Symmetry) - 너무 단순함 [cite: 232]
fit_cs <- gls(Score ~ factor(Time), data = df_long,
correlation = corCompSymm(form = ~ 1 | ID))
# Model 2: AR(1) - 등분산 가정 [cite: 250]
fit_ar1 <- gls(Score ~ factor(Time), data = df_long,
correlation = corAR1(form = ~ 1 | ID))
# Model 3: Unstructured (무구조) - 가장 유연함 [cite: 498]
fit_un <- gls(Score ~ factor(Time), data = df_long,
correlation = corSymm(form = ~ 1 | ID),
weights = varIdent(form = ~ 1 | Time)) # 이분산 허용
# Model 4: ARH(1) (이분산 AR1) - 현실적 대안
fit_arh1 <- gls(Score ~ factor(Time), data = df_long,
correlation = corAR1(form = ~ 1 | ID),
weights = varIdent(form = ~ 1 | Time))
# --- 4. 모델 선택 (AIC/BIC 비교) [cite: 47, 55] ---
anova(fit_cs, fit_ar1, fit_un, fit_arh1)
5.2 jamovi에서의 분석 절차
jamovi에서는 [Linear Mixed Models] 메뉴를 사용합니다.
- 데이터 불러오기: 위에서 생성한 데이터를 csv로 저장하여 jamovi에서 엽니다.
- 분석 설정:
Dependent Variable: ScoreCovariates: Time (또는 Factors로 설정)Cluster: ID
- Random Effects & Covariance Structure:
- jamovi 옵션 중 Residual Covariance (혹은 Random Effect의 상관 구조) 설정 탭을 찾습니다.
- 여기서
Unstructured,AR(1),Compound Symmetry등을 선택할 수 있습니다.
- 모델 비교: 각 모델별로 AIC/BIC 값을 확인하여 가장 작은 값을 가진 모델을 선택합니다. (보통 교육 성장 데이터는 ARH(1)이나 Unstructured가 잘 나옵니다).
6. 결론 및 제언 (Conclusions)
이 장의 저자들(Núñez-Antón & Zimmerman)은 다음과 같이 결론짓습니다.
- 평균과 공분산을 함께 보라: 평균적인 성장만 보지 말고, 오차의 구조(변동성, 상관성)를 함께 모델링해야 정확한 추론이 가능합니다.
- 균형을 찾아라: 무조건 복잡한 모델(Unstructured)이 좋은 것이 아닙니다. 데이터의 특성(비정상성, 계열 상관 등)을 반영하되, 가능한 한 파라미터 수가 적은 모델(예: Structured Antedependence 등)을 찾는 것이 최선입니다.
- 시각화를 믿어라: 통계 수치(AIC/BIC)도 중요하지만, 프로파일 도표와 PRISM 등을 통해 데이터의 실제 패턴을 눈으로 확인하는 것이 강력한 진단 도구가 됩니다.
[User를 위한 다음 단계]
위의 R 코드를 복사하여 RStudio에서 실행해 보시겠습니까? 생성된 그래프(프로파일 도표, PRISM)를 통해 방금 설명한 “조건부 독립” 개념이 시각적으로 어떻게 나타나는지 직접 확인해 보시면 이해가 훨씬 빠를 것입니다.
참고문헌 (References)
- Akaike, H. (1974). A new look at the statistical model identification. IEEE Transactions on Automatic Control, 19, 716-723.
- Diggle, P. J., Heagerty, P. J., Liang, K.-Y., & Zeger, S. L. (2002). Analysis of longitudinal data (2nd ed.). Oxford University Press.
- Gabriel, K. R. (1962). Ante-dependence analysis of an ordered set of variables. Annals of Mathematical Statistics, 33, 201-212.
- Goldstein, H. (2003). Multilevel statistical model (3rd ed.). Arnold.
- Kenward, M. G. (1987). A method for comparing profiles of repeated measurements. Applied Statistics, 36, 296-308.
- Laird, N. M., & Ware, J. H. (1982). Random-effects models for longitudinal data. Biometrics, 38, 963-974.
- Núñez-Antón, V., & Zimmerman, D. L. (2001). Parametric modeling of growth curve data: An overview (with discussion). Test, 10, 1-73.
- Zimmerman, D. L. (2000). Viewing the correlation structure in longitudinal data through a PRISM. The American Statistician, 54, 310-318.
- Zimmerman, D. L., & Núñez-Antón, V. (2010). Antedependence models for longitudinal data. Chapman & Hall/CRC.