오늘은 결측치(Missing Data)의 처리와 다층모형을 활용한 분석에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
학교 현장에서 종단 연구(시간의 흐름에 따른 변화 관찰)를 하다 보면 필연적으로 결측치(Missing Data)를 마주하게 됩니다. 학생이 전학을 가거나, 아파서 결석하거나, 혹은 시험이 너무 어려워 백지를 내고 도망가는 경우들이죠.
과거에는 컴퓨터 성능의 한계로 인해 결측치가 있는 데이터를 단순히 삭제하거나 평균으로 대충 채워 넣는 방법을 썼습니다. 하지만 이제는 EM 알고리즘이나 다중 대체(Multiple Imputation), 그리고 다층모형(Mixed Models)과 같은 강력한 도구들이 있어 더 정확한 추론이 가능해졌습니다.
이 강의에서는 가상의 “읽기 능력 향상 프로그램” 데이터를 통해 결측치를 어떻게 다뤄야 하는지 알아보겠습니다.
1. 시나리오: “책벌레 만들기 프로젝트”
우리는 S 초등학교 3학년 학생 100명을 대상으로 4개월 동안 ‘읽기 능력 향상 프로그램’을 진행했습니다.
측정 시점: 0개월(사전), 1개월, 2개월, 3개월 (총 4회)
문제 상황: 시간이 지날수록 읽기 점수가 낮은 학생들이 흥미를 잃고 프로그램에 참여하지 않기 시작했습니다. (즉, 데이터가 빠지기 시작함)
이 상황을 이해하기 위해 먼저 결측의 종류(메커니즘)를 알아야 합니다.
1.1 결측 메커니즘의 이해 (기초 개념)
이 부분은 초등학생에게 설명하듯 아주 쉽게 풀어보겠습니다.
MCAR (Missing Completely At Random, 완전 무작위 결측):
예시: 급식실에 가다가 넘어져서 시험지를 잃어버린 경우입니다. 학생의 읽기 능력이나 성격과는 아무 상관 없이, 순전히 운 나쁘게 데이터가 사라진 것이죠.
특징: 무시하고 분석해도 결과가 크게 왜곡되지 않습니다(단지 표본 수가 줄어들 뿐).
MAR (Missing At Random, 무작위 결측):
예시:“지난달 점수”가 낮은 학생이 이번 달에 결석할 확률이 높은 경우입니다.
핵심: 결측된 이유가 우리가 관측한 데이터(지난달 점수)로 설명이 됩니다. 우리가 이미 가지고 있는 정보로 “아, 쟤는 지난번에 못 봐서 안 왔구나”라고 추측할 수 있다면 MAR입니다. 다층모형은 이 가정하에서 아주 강력합니다.
MNAR (Missing Not At Random, 비무작위 결측):
예시: 오늘 시험이 너무 어려워서, 혹은 오늘 기분이 너무 우울해서 시험을 안 본 경우입니다.
핵심: 결측된 이유가 측정하지 못한 값(오늘의 우울감, 오늘의 실제 실력) 자체에 의존합니다. 이건 해결하기 가장 까다로운 문제입니다.
2. 분석 준비: 데이터 생성 (R & jamovi)
자, 이제 R을 이용해 MAR(지난달 점수가 낮으면 결측 발생) 상황을 가정한 모의 데이터를 생성해 보겠습니다.
[R Code] 데이터 생성
R
# ==============================================================================
# 1. 라이브러리 로드 및 환경 설정
# ==============================================================================
# 필요한 패키지가 없다면 install.packages("lme4") 등으로 설치해야 합니다.
if(!require(lme4)) install.packages("lme4")
if(!require(ggplot2)) install.packages("ggplot2")
if(!require(dplyr)) install.packages("dplyr")
if(!require(tidyr)) install.packages("tidyr")
library(lme4)
library(ggplot2)
library(dplyr)
library(tidyr)
set.seed(123) # 재현성을 위해 시드 고정
# ==============================================================================
# 2. 데이터 생성 (Truth)
# ==============================================================================
n_subjects <- 200 # 학생 수 (표본을 좀 늘려서 효과를 명확히 함)
n_timepoints <- 4 # 시점 수 (0, 1, 2, 3개월)
time <- 0:3
sigma_error <- 2 # 오차의 표준편차
# 개인별 성장 곡선 파라미터 (Random Effects)
# 절편 평균 50, 표준편차 5 / 기울기 평균 5, 표준편차 2
intercepts <- rnorm(n_subjects, 50, 5)
slopes <- rnorm(n_subjects, 5, 2)
data_long <- data.frame()
for(i in 1:n_subjects){
# 진점수(True Score)
y_true <- intercepts[i] + slopes[i] * time
# 관측값(Observed Score) = 진점수 + 오차
y_obs <- y_true + rnorm(n_timepoints, 0, sigma_error)
subject_data <- data.frame(
ID = as.factor(i),
Time = time,
Score = y_obs,
True_Score = y_true # 비교용 진점수
)
data_long <- rbind(data_long, subject_data)
}
# ==============================================================================
# 3. 결측치(MAR) 생성
# ==============================================================================
# 시나리오: 직전 시점 점수가 낮으면, 그 다음 시점부터 80% 확률로 중도 탈락
data_missing <- data_long
data_missing$Missing <- FALSE
for(i in unique(data_missing$ID)){
subj_rows <- which(data_missing$ID == i)
# Time 1부터 3까지 순차적으로 확인 (Time 0은 결측 없음 가정)
for(t in 2:4){
# 직전 시점(t-1)의 점수 확인
prev_score <- data_missing$Score[subj_rows[t-1]]
# 직전 점수가 48점 미만(하위권)이면 80% 확률로 탈락 발생
if(!is.na(prev_score) && prev_score < 48){
if(runif(1) < 0.8){
# 현재 시점부터 끝까지 NA 처리 (Monotone Dropout)
data_missing$Score[subj_rows[t:4]] <- NA
data_missing$Missing[subj_rows[t:4]] <- TRUE
break
}
}
}
}
# 전체 결측률 확인
cat("총 결측 비율:", mean(is.na(data_missing$Score)), "\n")
# ==============================================================================
# 4. 분석 데이터셋 준비
# ==============================================================================
# [Case 1] True CC (Listwise Deletion)
# 결측치가 하나라도 있는 학생은 통째로 제거
valid_ids <- data_missing %>%
group_by(ID) %>%
filter(sum(is.na(Score)) == 0) %>%
pull(ID) %>%
unique()
data_cc_true <- data_missing %>% filter(ID %in% valid_ids)
cat("CC 분석에 포함된 학생 수:", length(unique(data_cc_true$ID)), "/", n_subjects, "\n")
# [Case 2] MM (Available Case)
# 결측이 있어도 그대로 사용 (data_missing 원본 사용)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data_missing, "chap23.csv", row.names = FALSE)
상황 설명: 원래대로라면 모든 학생의 성적이 올랐어야 합니다(기울기 5). 하지만 성적이 낮은 학생들이 중간에 그만두게 만들었습니다(MAR). 이제 이 데이터를 분석해 봅시다.
3. 잘못된 분석 방법들: 단순한 방법의 함정
단순한 방법(Simple Methods)들이 얼마나 위험한지 경고하고 있습니다.
3.1 완전 사례 분석 (Complete Case Analysis, CC)
방법: 결측치가 하나라도 있는 학생은 분석에서 몽땅 제외합니다.
문제점: 성적이 낮은 학생들이 주로 빠졌으므로, 끝까지 남은 학생들은 “우등생”들뿐입니다. 결과적으로 프로그램의 효과가 과대평가(Bias) 됩니다. 표본 수도 줄어들어 통계적 검정력도 떨어집니다.
3.2 마지막 관측값 이월 (Last Observation Carried Forward, LOCF)
방법: 1개월 차에 그만둔 학생의 점수를 2, 3개월 차에도 똑같이 복사해 넣습니다.
문제점: “학생의 성장은 멈췄다”고 가정하는 것입니다. 성장 곡선 모형에서는 이 방법이 성장의 기울기를 과소평가하게 만들거나, 오차의 분산을 왜곡시킵니다. 아주 보수적인(효과가 없다고 하는) 결과를 내는 것 같지만, 실제로는 엉뚱한 결론을 낼 수 있어 위험합니다.
4. 올바른 분석 방법: MAR 가정하의 접근
4.1 직접 우도 분석 (Direct Likelihood) / 다층모형 (Mixed Models)
이 방법은 우리가 데이터를 억지로 채워 넣거나 지우지 않고, 있는 데이터 그대로(observed data) 분석하는 것입니다. 다층모형(Linear Mixed Model)은 결측이 무작위(MAR)로 발생했다면, 관측된 데이터와 변수 간의 상관관계를 이용해 편향되지 않은 추정치를 제공합니다.
[jamovi 실습 가이드] 다층모형 분석
데이터 불러오기: 위에서 생성한 reading_program_MAR.csv를 엽니다.
분석 메뉴:Analyses > Linear Models > Mixed Models를 선택합니다.
변수 설정:
Dependent Variable (종속변수):Score
Covariates (공변량):Time
Cluster (군집 변수):ID (학생 개인)
Random Effects (무선 효과):
Time과 Intercept를 Random Coefficients에 넣습니다. (학생마다 초기치와 성장 속도가 다르므로)
결과 해석:
jamovi는 내부적으로 lme4 또는 nlme 패키지를 사용하며, 이는 결측치가 있는 경우에도 REML(제한된 최대우도) 방식을 통해 사용 가능한 모든 데이터를 활용해 파라미터를 추정합니다.
[R Code 비교]
R
# ==============================================================================
# 5. 다층모형 적합 (Model Fitting)
# ==============================================================================
# 1) Truth (결측 없는 원본 데이터 - 기준점)
fit_truth <- lmer(Score ~ Time + (Time | ID), data = data_long)
# 2) True CC (편향된 데이터)
fit_cc_true <- lmer(Score ~ Time + (Time | ID), data = data_cc_true)
# 3) MM (결측 있는 데이터 + 다층모형)
fit_mm <- lmer(Score ~ Time + (Time | ID), data = data_missing)
# ==============================================================================
# 6. 결과 비교 및 출력
# ==============================================================================
# 고정 효과(Fixed Effects) 추출 함수
get_fixed <- function(model, name) {
coefs <- fixef(model)
data.frame(
Model = name,
Intercept = coefs["(Intercept)"],
Slope = coefs["Time"]
)
}
res_truth <- get_fixed(fit_truth, "1. Truth (기준)")
res_cc <- get_fixed(fit_cc_true, "2. True CC (편향)")
res_mm <- get_fixed(fit_mm, "3. MM (보정)")
# 결과 합치기
results <- rbind(res_truth, res_cc, res_mm)
rownames(results) <- NULL
print("===== [모형별 고정 효과(Fixed Effects) 추정치 비교] =====")
print(results)
cat("\n* 설명: Truth의 Slope(약 5.0)에 가까울수록 좋은 분석입니다.\n")
cat("* True CC는 하위권 학생이 제거되어 Slope가 과대평가될 가능성이 높습니다.\n")
# ==============================================================================
# 7. 시각화 (Visualization)
# ==============================================================================
# 예측된 회귀선 생성을 위한 데이터
pred_data <- data.frame(Time = seq(0, 3, 0.1))
# 각 모형의 예측값 계산 (Fixed Effect만 사용)
pred_data$Truth <- fixef(fit_truth)[1] + fixef(fit_truth)[2] * pred_data$Time
pred_data$CC <- fixef(fit_cc_true)[1] + fixef(fit_cc_true)[2] * pred_data$Time
pred_data$MM <- fixef(fit_mm)[1] + fixef(fit_mm)[2] * pred_data$Time
# 데이터를 긴 형태(Long Format)로 변환 (ggplot용)
plot_data <- pred_data %>%
pivot_longer(cols = c("Truth", "CC", "MM"), names_to = "Model", values_to = "Score")
# 그래프 그리기
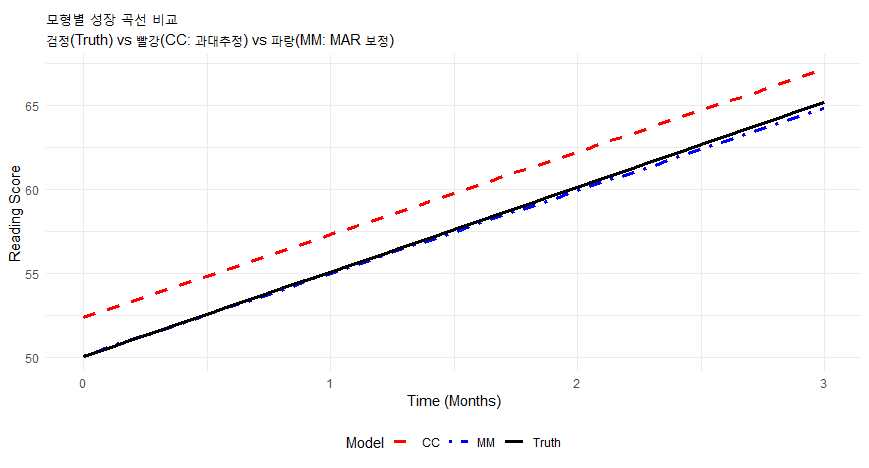
ggplot(plot_data, aes(x = Time, y = Score, color = Model, linetype = Model)) +
geom_line(size = 1.2) +
scale_color_manual(values = c("Truth" = "black", "CC" = "red", "MM" = "blue")) +
scale_linetype_manual(values = c("Truth" = "solid", "CC" = "dashed", "MM" = "dotdash")) +
labs(title = "모형별 성장 곡선 비교",
subtitle = "검정(Truth) vs 빨강(CC: 과대추정) vs 파랑(MM: MAR 보정)",
y = "Reading Score", x = "Time (Months)") +
theme_minimal() +
theme(legend.position = "bottom")
결과 비교 시사점:
진짜 값(True): 기울기(Time) ≈ 5.0
완전 사례(CC): 낮은 점수 학생이 빠져서 남은 우등생들의 가파른 성장만 반영될 수 있음(혹은 중도 탈락자가 성장세가 꺾인 아이들이라면 오히려 과대 추정). 시뮬레이션에 따라 다르지만 보통 편향됨. * 다층모형(MM): 결측이 있어도 기울기가 5.0에 가깝게 복원됩니다. 이것이 바로 다층모형의 힘입니다!
4.2 다중 대체 (Multiple Imputation, MI)
결측치를 한 번만 채우는 게 아니라, M번(보통 5~10번) 채워서 M개의 데이터셋을 만듭니다.
Imputation: 그럴듯한 값들로 빈칸을 채웁니다(불확실성 반영).
Analysis: M개의 데이터셋을 각각 분석합니다.
Pooling: M개의 결과를 하나로 합칩니다.
jamovi에서는 기본 모듈에서 MI를 직접 지원하는 파이프라인이 약하지만, Rj 모듈을 쓰거나 R을 이용해 수행할 수 있습니다. 교재에서는 다층모형(Direct Likelihood)과 MI가 MAR 가정하에서 둘 다 타당하다고 합니다. 다만, 공변량(Covariate) 자체에 결측이 있을 때는 MI가 더 유용할 수 있습니다.
5. 고급 주제: 비무작위 결측 (MNAR)과 민감도 분석
만약 학생이 “그냥 기분이 나빠서(우리가 측정 안 한 변수)” 빠졌다면(MNAR) 어떻게 할까요? 이때는 다층모형도 완벽하지 않습니다.
5.1 패턴 혼합 모형 (Pattern-Mixture Models)
학생들을 “탈락 시점”에 따라 그룹(패턴)으로 나누어 분석하는 방법입니다.
예: 끝까지 남은 그룹, 2개월 차에 나간 그룹, 3개월 차에 나간 그룹.
각 그룹별로 성장 곡선이 어떻게 다른지 봅니다.
교재의 Vorozole 연구 예시처럼, 탈락 패턴을 공변량으로 넣어 분석할 수 있습니다.
5.2 선택 모형 (Selection Models)
성적 모형과 탈락 확률 모형(로지스틱 회귀 등)을 동시에 결합해서 분석하는 아주 복잡한 방법입니다. Heckman의 Tobit 모델과 유사한 개념입니다.
5.3 민감도 분석 (Sensitivity Analysis)
우리가 가정한 결측 메커니즘(MAR)이 틀렸을 수도 있습니다. 그래서 “만약 이게 MNAR이라면 결과가 어떻게 바뀔까?”를 테스트해보는 것입니다.
jamovi나 R에서 분석한 뒤, “결측된 값들이 관측된 값보다 평균적으로 k점 더 낮다고 가정해보자”라고 시나리오를 바꾸어가며 결과가 뒤집히는지 확인합니다.
6. 결론 및 제언
교재와 분석 결과를 종합하여 여러분께 드리는 제언은 다음과 같습니다.
LOCF나 CC는 이제 그만: 이 방법들은 편향이 심하므로 주 분석으로 쓰지 마십시오.
다층모형(Direct Likelihood)을 기본으로: jamovi의 Mixed Models는 별도의 조치 없이도 MAR 가정하에서 훌륭한 결과를 냅니다. 이것을 일차적 분석(Primary Analysis)으로 삼으세요.
민감도 분석 수행: 결측이 MNAR일 가능성을 배제할 수 없으므로, 다양한 가정하에서도 결과가 견고한지 확인하는 것이 현명합니다.
학교 현장의 데이터는 아이들의 숨겨진 사연(결측)을 담고 있습니다. 무작정 지우기보다 그 패턴을 이해하고 적절한 통계적 도구를 사용하는 것이 연구자의 윤리이자 책무입니다.
참고문헌 (APA Style)
Beunckens, C., Molenberghs, G., & Kenward, M. G. (2005). Tutorial: Direct likelihood analysis versus simple forms of imputation for missing data in randomized clinical trials. Clinical Trials, 2(4), 379–386.
Little, R. J. A., & Rubin, D. B. (2002). Statistical analysis with missing data (2nd ed.). New York: John Wiley & Sons.
Molenberghs, G., & Kenward, M. G. (2007). Missing data in clinical studies. Chichester: John Wiley & Sons.
Molenberghs, G., & Verbeke, G. (2012). Missing Data. In The SAGE Handbook of Multilevel Modeling (pp. 403–424). SAGE Publications.
Verbeke, G., & Molenberghs, G. (2000). Linear mixed models for longitudinal data. New York: Springer-Verlag.
안녕하세요? 오늘은 연구자들이 데이터를 분석할 때 가장 빈번하게 마주하지만, 동시에 가장 골치 아픈 문제인 ‘결측치(Missing Data)’를 구조방정식 모델(SEM)에서 어떻게 처리해야 하는지 깊이 있게 다뤄보겠습니다.
단순히 결측치를 삭제하는 과거의 방식에서 벗어나, 현대 통계학의 표준인 완전 정보 최대 우도법(FIML)과 다중 대치법(MI)을 중심으로 학습해 봅시다. 여러분의 이해를 돕기 위해 교육 현장의 가상 데이터를 활용하여 설명하겠습니다.
1. 결측치 처리의 필요성과 이론적 배경
교육 연구에서 학생들의 설문 데이터나 성적 데이터를 수집하다 보면, 특정 문항에 응답하지 않거나 전학 등으로 인해 데이터가 누락되는 경우가 많습니다. 과거에는 결측치가 있는 사례를 통째로 삭제(Listwise Deletion)하곤 했으나, 이는 표본 크기를 줄여 통계적 검증력을 약화시킬 뿐만 아니라, 특정 집단이 조직적으로 응답을 누락했을 경우 심각한 편향(Bias)을 초래합니다1.
결측치 발생 기제 (Missing Data Processes)
결측치를 처리하기 전, 루빈(Rubin, 1976)이 제안한 세 가지 발생 기제를 이해해야 합니다.
완전 무작위 결측 (MCAR): 결측이 관찰된 데이터나 관찰되지 않은 데이터와 전혀 상관없이 발생한 경우입니다. (예: 설문지가 단순히 배달 사고로 분실됨)
무작위 결측 (MAR): 결측이 다른 관찰된 변수와는 상관이 있지만, 결측된 값 자체와는 상관이 없는 경우입니다. 현대적 결측치 처리법의 기본 가정입니다. (예: 기초 학력이 낮은 학생이 학업 중단으로 인해 기말고사 점수가 누락됨)
비무작위 결측 (MNAR): 결측이 누락된 값 자체와 관련이 있는 경우입니다. (예: 성적이 매우 낮은 학생이 부끄러워서 일부러 성적을 기입하지 않음)
2. 가상 시나리오 및 모의 데이터 생성
강의를 위해 다음과 같은 교육 연구 시나리오를 설정하겠습니다.
연구 주제: 교사의 지지가 학생의 학업 자기효능감을 매개로 학교 행복감에 미치는 영향
독립변수: 교사의 지지 (Teacher Support)
매개변수: 학업 자기효능감 (Self-Efficacy, 3개 문항)
종속변수: 학교 행복감 (School Happiness, 3개 문항)
보조변수(Auxiliary Variable): 부모의 학업 관여도 (Parental Involvement) – 모델에는 없으나 결측치 추정을 돕기 위해 활용
R을 이용한 모의 데이터 생성 스크립트
jamovi에서 불러올 수 있도록 결측치가 포함된 500명의 가상 데이터를 생성합니다.
R
# 필요한 라이브러리
library(MASS)
set.seed(2025)
N <- 500
# 변수 간 상관관계 설정 (교사지지, 효능감1-3, 행복감1-3, 부모관여)
mu <- rep(0, 8)
sigma <- matrix(0.5, 8, 8); diag(sigma) <- 1
data <- mvrnorm(N, mu, sigma)
colnames(data) <- c("T_Sup", "Eff1", "Eff2", "Eff3", "Hap1", "Hap2", "Hap3", "P_Inv")
df <- as.data.frame(data)
# MAR 기제에 의한 결측치 생성: 교사 지지가 낮은 학생일수록 효능감 응답 누락 확률 높음
missing_idx <- which(df$T_Sup < quantile(df$T_Sup, 0.3))
df$Eff1[sample(missing_idx, 50)] <- NA
df$Hap1[sample(1:N, 30)] <- NA # 일부는 MCAR
write.csv(df, "School_Missing_Data.csv", row.names = FALSE)
완전 정보 최대 우도법(Full-Information Maximum Likelihood)은 관찰된 데이터를 모두 사용하여 로그 우도(Log-likelihood) 함수를 계산하는 방식입니다. 결측치가 있는 사례를 버리지 않고, 관찰된 데이터만을 사용하여 해당 사례의 우도 값을 계산합니다.
jamovi에서의 분석 방법
SEMLj 라이브러리를 설치합니다.
SEMLj 모듈을 실행하고 모델을 설정합니다.
Options 탭에서 Missing values 설정을 FIML로 선택합니다.
참고: jamovi의 기본 SEMLj 엔진인 lavaan은 FIML을 통해 결측치를 효율적으로 처리합니다.
보조 변수(Auxiliary Variables)의 활용
결측치가 MAR 가정에 더 가깝게 부합하도록 하기 위해, 모델에 직접 포함되지 않지만 결측과 관련이 있는 변수(부모 관여도)를 활용할 수 있습니다.
포화 상관 모델 (Saturated Correlates Model): 보조 변수를 모델 내 모든 외생 변수와 상관시키고, 내생 변수의 잔차와 상관시키는 방식입니다.
4. 다중 대체법 (Multiple Imputation, MI)
다중 대체법은 결측치를 단일 값이 아닌 여러 번 추정하여 여러 개의 ‘완성된’ 데이터셋을 만드는 방식입니다.
분석의 3단계
대체 단계 (Imputation): MCMC 알고리즘 등을 활용하여 결측치가 채워진 개(보통 20~100개)의 데이터셋 생성.
분석 단계 (Analysis): 각 데이터셋에 대해 구조방정식 모델을 독립적으로 분석.
결합 단계 (Pooling): 루빈의 규칙(Rubin’s Rules)을 적용하여 결과를 하나로 통합.
jamovi/R 구현 (R 기반 설명)
jamovi의 일부 플러그인에서도 MI를 지원하지만, 구조방정식의 경우 R의 mice 패키지와 lavaan을 병행하는 것이 가장 정교합니다.
R
library(mice)
library(lavaan)
# 1. 대치 단계 (20개의 데이터셋 생성)
imp <- mice(df, m = 20, method = 'pmm', seed = 2025)
# 2. 분석 및 결합 단계
model <- '
Efficacy =~ Eff1 + Eff2 + Eff3
Happiness =~ Hap1 + Hap2 + Hap3
Efficacy ~ T_Sup
Happiness ~ Efficacy + T_Sup
'
fit_mi <- with(imp, sem(model, data = subset(df)))
# pool 결과를 사용하여 최종 추정치 산출
5. 분석 결과의 비교 및 해석
FIML과 MI는 동일한 가정(MAR) 하에서 보통 거의 일치하는 결과를 보여줍니다.
구분
FIML (완전 정보 최대 우도)
MI (다중 대치법)
장점
한 번의 분석으로 완료, 효율적임
범주형 데이터 처리에 유연함
단점
보조 변수 추가 시 모델이 복잡해짐
분석 과정이 번거롭고 시간이 소요됨
적합도
모델 적합도 지수 즉시 제공
각 세트의 지수를 평균하여 산출
6. 결론 및 제언
교육 연구에서 결측치는 피할 수 없는 현상입니다. 하지만 FIML이나 MI와 같은 현대적인 기법을 사용한다면, 결측치로 인한 편향을 최소화하고 연구의 타당성을 높일 수 있습니다.
데이터가 연속형이고 분석 모델이 명확하다면 FIML을 우선 권장합니다.
변수 중에 범주형 변수가 많거나 비선형 효과를 분석해야 한다면 MI가 더 유리합니다.
구조방정식 모델링 시 “결측치가 있으니 해당 학생을 삭제하겠다”는 생각은 이제 접어두시고, 데이터를 최대한 활용하는 통계적 지혜를 발휘해 보시기 바랍니다.
참고문헌 (APA Style)
Arbuckle, J. L. (1996). Full information estimation in the presence of incomplete data. In G. A. Marcoulides & R. E. Schumacker (Eds.), Advanced structural equation modeling (pp. 243–277). Erlbaum.
Enders, C. K. (2022). Applied missing data analysis (2nd ed.). Guilford Press.
Graham, J. W. (2003). Adding missing-data-relevant variables to FIML-based structural equation models. Structural Equation Modeling: A Multidisciplinary Journal, 10(1), 80–100.
Little, R. J. A., & Rubin, D. B. (2020). Statistical analysis with missing data (3rd ed.). Wiley.
Rubin, D. B. (1987). Multiple imputation for nonresponse in surveys. Wiley.
Schafer, J. L. (1997). Analysis of incomplete multivariate data. Chapman & Hall.