
안녕하세요, 여러분.
오늘은 우리가 배우고 있는 구조방정식 모델링(SEM: Structural Equation Modeling)이 도대체 어디서 왔고, 어떻게 지금의 강력한 도구가 되었는지 그 역사를 짚어보는 시간을 갖겠습니다. “역사”라고 하면 지루하게 느낄 수 있겠지만, SEM의 역사는 생물학, 사회학, 심리학, 경제학이라는 서로 다른 학문이 ‘인과관계 규명’이라는 하나의 목표를 향해 달려와 만나는 아주 흥미로운 대서사시입니다.
이 챕터는 Ross L. Matsueda의 “A Brief History of Structural Equation Modeling” 을 바탕으로, 내용을 대폭 보강하고 우리 교육학 분야의 예시를 곁들여 재구성했습니다.
제2장. 구조방정식 모델링의 역사와 발전: 융합과 혁신
1. 서론: SEM은 하루아침에 만들어지지 않았다
구조방정식(SEM)은 현대 사회과학 연구에서 가장 인기 있는 통계 기법 중 하나입니다. 하지만 SEM은 어느 한 천재가 뚝딱 만들어낸 것이 아닙니다. 지난 100여 년간 각기 다른 분야에서 “관찰된 데이터로 어떻게 보이지 않는 원인을 찾을 것인가?”라는 질문에 답하기 위해 개발된 방법론들이 1970년대에 극적으로 통합된 결과물입니다.
우리는 이 거대한 흐름을 크게 네 가지 단계로 나누어 살펴보겠습니다.
- 기초 확립기: 생물학, 사회학, 심리학, 경제학의 독자적 발전
- 학제 간 통합기: 1970년대, 잠재변수와 경로분석의 만남
- 확장기: 정규성 가정 위반과 범주형 자료의 처리
- 최신 발전기: 베이지안, 기계학습, 그리고 인과 추론의 재조명
2. SEM의 학문적 뿌리 (Foundations)
SEM의 뿌리는 놀랍게도 유전학(생물학)에서 시작되어 사회학, 심리학, 경제학으로 뻗어나갔습니다.
2.1. 생물학 및 유전학: Sewall Wright의 경로분석 (Path Analysis)
1918년, 젊은 유전학자 Sewall Wright는 기니피그의 뼈 크기와 털 색깔 유전을 연구하고 있었습니다. 그는 단순히 변수 간의 상관관계(Correlation)를 구하는 것만으로는 부족함을 느꼈습니다. 상관관계는 두 변수가 관련이 있다는 것은 알려주지만, “무엇이 원인이고 무엇이 결과인가?”는 말해주지 않기 때문이죠.
그래서 Wright는 경로분석(Path Analysis)을 창안했습니다. 그는 변수들 사이의 인과관계를 화살표로 연결한 경로도(Path Diagram)를 그렸습니다.
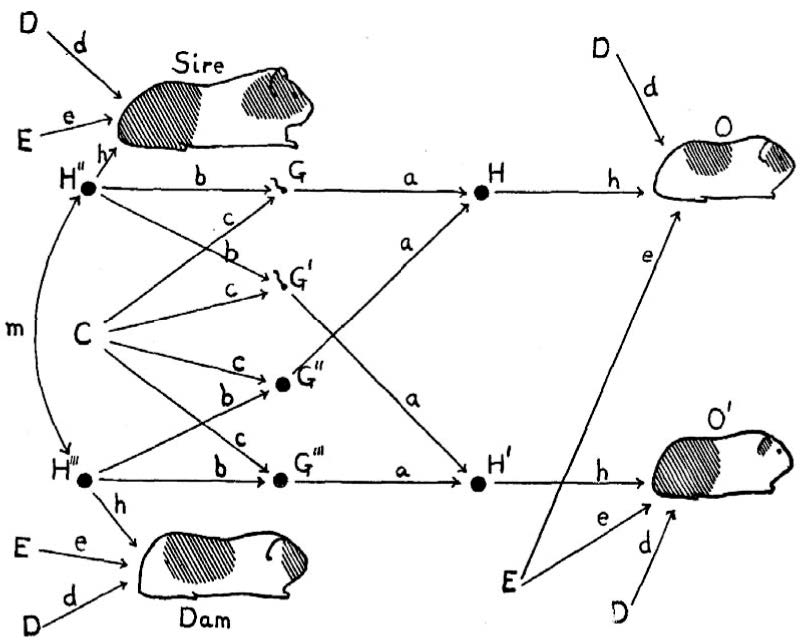
Note. From Handbook of structural equation modeling (p. 18), by R. H. Hoyle (Ed.), 2023, Guilford Press. Copyright 2023 by Guilford Press.
- 교육학적 예시: 여러분이 ‘부모의 지원(X)’이 ‘학생의 성적(Y)’에 미치는 영향을 본다고 가정해 봅시다. Wright의 방식에 따르면, 단순히 상관계수 을 보는 것이 아니라, 인과적 가정을 담은 경로 계수(path coefficient)를 통해 이 관계를 설명하려고 시도한 것입니다.
Wright는 이 복잡한 연립방정식 체계를 통해 유전(Heredity)과 환경(Environment)이 기니피그의 특성에 미치는 영향을 분해했습니다. 하지만 당시 통계학계의 주류였던 피어슨(Pearson) 학파와 피셔(Fisher) 학파는 Wright의 아이디어를 외면했습니다. “상관관계에서 인과를 찾으려 한다”는 이유로 말이죠.
2.2. 사회학: 인과 모델의 도입
사회학에서는 실험이 불가능한 경우가 많습니다. 예를 들어 “빈곤이 범죄에 미치는 영향”을 보기 위해 사람들을 강제로 빈곤하게 만들 수 없으니까요. 따라서 비실험 데이터(관찰 데이터)로 인과관계를 추론하는 것이 절실했습니다.
- Blalock과 Duncan: 1960년대 사회학자 Blalock과 Duncan은 Wright의 경로분석을 사회학으로 가져왔습니다.
- 지위 획득 모델 (Status Attainment Model): Blau와 Duncan(1967)은 아버지의 직업이 아들의 교육 수준을 거쳐 아들의 직업에 영향을 미치는 경로 모형을 제시했습니다. 이는 오늘날 우리가 교육사회학에서 흔히 보는 “가정배경 학업성취 사회적 성취” 모델의 시초입니다.
2.3. 심리학: 요인분석 (Factor Analysis)
심리학의 관심은 조금 달랐습니다. 심리학자들은 “지능(Intelligence)”이나 “창의성”처럼 눈에 보이지 않는 잠재변수(Latent Variable)를 측정하는 데 관심이 있었습니다.
- Spearman의 g요인: Spearman(1904)은 여러 과목의 성적(수학, 언어, 논리 등)이 서로 상관이 높은 것을 보고, 이들 뒤에 공통된 하나의 원인인 일반 지능(g factor)이 있다고 주장했습니다.
- 교육학적 적용: 우리가 “수리력”을 측정하기 위해 여러 개의 수학 문제를 풀게 하고, 그 점수들의 공통된 분산을 뽑아내는 것이 바로 요인분석의 원리입니다. 이를 통해 측정 오차(measurement error)를 제외한 진정한 능력을 추정할 수 있게 되었습니다.
2.4. 경제학: 연립방정식 모델 (Simultaneous Equation Models)
경제학자들은 수요와 공급처럼 서로가 서로에게 영향을 주는 양방향 인과관계(Reciprocal relationship)를 고민했습니다. 가격이 오르면 수요가 줄지만, 수요가 늘어나면 가격이 오르기도 하니까요.
- Haavelmo와 Cowles 위원회: 이들은 연립방정식 모델을 통해 변수들이 동시에 결정되는 시스템을 추정하는 방법을 개발했습니다. 이는 훗날 SEM에서 양방향 화살표(비재귀 모형)를 다룰 수 있는 이론적 토대가 되었습니다.
3. 학제 간 대통합 (Integration): 현대 SEM의 탄생
1970년대는 SEM의 역사에서 가장 중요한 시기입니다. 서로 다른 길을 걷던 경로분석(사회학/생물학), 요인분석(심리학), 연립방정식(경제학)이 하나로 합쳐졌기 때문입니다.
3.1. Jöreskog와 LISREL
이 통합의 중심에는 스웨덴의 통계학자 Karl Jöreskog가 있습니다. 그는 1970년, LISREL (Linear Structural RELations)이라는 모델과 컴퓨터 프로그램을 발표했습니다.
- 혁신: Jöreskog는 “측정 모델(요인분석)”과 “구조 모델(경로분석)”을 하나의 수식으로 결합했습니다.
- 측정 모델: (관측변수가 잠재변수를 어떻게 측정하는가?)
- 구조 모델: (잠재변수들끼리 어떤 인과관계를 맺는가?)
- 이로써 우리는 “측정 오차를 통제한 상태에서 잠재변수 간의 인과관계”를 분석할 수 있게 되었습니다. 이것이 바로 오늘날 우리가 쓰는 SEM의 표준입니다.
3.2. Hauser와 Goldberger의 통찰
Hauser와 Goldberger(1971)는 관측되지 않는 변수(Unobservables)를 처리하는 방식을 정교화하며, 최대우도법(ML)이 어떻게 최적의 추정치를 제공하는지 증명했습니다. 그들은 “Walking Dog Model”(개 산책 모델)이라 불리는 다중 지표 모델을 통해 이를 설명했습니다.
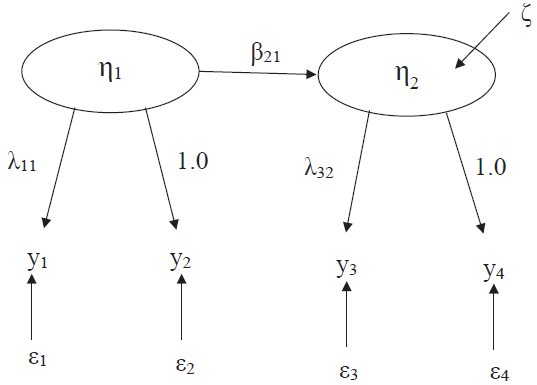
Note. From Handbook of structural equation modeling (p. 23), by R. H. Hoyle (Ed.), 2023, Guilford Press. Copyright 2023 by Guilford Press.
4. [실습 및 시뮬레이션] 교육학적 예시: 통합된 SEM의 위력
이론만으로는 와닿지 않을 수 있습니다. 1970년대 통합의 의의를 보여주기 위해, 교육학적 상황을 가정한 모의 데이터를 생성하고 분석해보겠습니다.
시나리오: “가정의 사회경제적 배경(SES)”이 “학교 적응(School Adjustment)”을 매개로 “학업 성취도(Achievement)”에 미치는 영향을 보고 싶습니다.
- 전통적 경로분석: SES, 적응, 성취도를 각각 하나의 점수(관측변수)로만 봅니다. 측정 오차를 고려하지 못합니다.
- 통합된 SEM: SES, 적응, 성취도를 각각 여러 문항으로 측정한 잠재변수로 설정하여 측정 오차를 제거하고 구조적 관계를 봅니다.
아래는 R을 사용하여 이 가상의 상황을 시뮬레이션하고 분석하는 코드입니다. (jamovi에서는 SEMLj 모듈을 설치하여 아래와 유사한 구조로 분석할 수 있습니다.)
# 필요한 패키지 로드
if(!require(lavaan)) install.packages("lavaan")
library(lavaan)
# 1. 데이터 생성 (Backstory: N=500명의 고등학생 데이터)
# SES: 부모소득(inc), 부모학력(edu)
# School_Adj(학교적응): 교사관계(rel_t), 교우관계(rel_f), 학교흥미(intr)
# Ach(성취도): 중간고사(mid), 기말고사(fin), 모의고사(mock)
set.seed(1234)
N <- 500
# 구조 모델 (Latent Regression)
# SES -> Adj (0.4), SES -> Ach (0.3), Adj -> Ach (0.5)
SES <- rnorm(N)
Adj <- 0.4*SES + rnorm(N, 0, 0.8) # 오차항 포함
Ach <- 0.3*SES + 0.5*Adj + rnorm(N, 0, 0.7)
# 측정 모델 (Measurement Model)
# 각 잠재변수가 관측변수를 생성
inc <- 1.0*SES + rnorm(N, 0, 0.5)
edu <- 0.8*SES + rnorm(N, 0, 0.5)
rel_t <- 1.0*Adj + rnorm(N, 0, 0.6)
rel_f <- 0.9*Adj + rnorm(N, 0, 0.6)
intr <- 0.8*Adj + rnorm(N, 0, 0.6)
mid <- 1.0*Ach + rnorm(N, 0, 0.4)
fin <- 1.1*Ach + rnorm(N, 0, 0.4)
mock <- 0.9*Ach + rnorm(N, 0, 0.4)
# 데이터프레임 생성
Data <- data.frame(inc, edu, rel_t, rel_f, intr, mid, fin, mock)
# 2. SEM 모델 명세 (Lavaan Syntax)
model <- '
# 측정 모델 (Measurement Model)
SES =~ inc + edu
Adjustment =~ rel_t + rel_f + intr
Achievement =~ mid + fin + mock
# 구조 모델 (Structural Model)
Achievement ~ Adjustment + SES
Adjustment ~ SES
'
# 3. 모델 적합
fit <- sem(model, data=Data)
# 4. 결과 요약
summary(fit, standardized=TRUE, fit.measures=TRUE)생성된 예제 파일: chap02
해설: 위 코드를 실행하면, 단순히 관측값의 평균을 내어 회귀분석을 한 것보다 더 정교한 결과를 얻습니다. 측정 오차(Measurement Error, )가 분리되었기 때문입니다. 이것이 바로 Jöreskog가 이룩한 혁신의 핵심입니다.
5. 방법론적 확장: 현실 데이터의 문제 해결
1980년대 이후, 연구자들은 SEM의 기본 가정(다변량 정규성 등)이 실제 데이터에서는 잘 지켜지지 않는다는 비판에 직면했습니다.
5.1. 정규성 가정 위반의 해결 (Browne의 기여)
대부분의 교육 데이터(예: 설문조사 5점 척도)는 완벽한 정규분포를 따르지 않습니다.
- ADF (Asymptotically Distribution-Free) 추정: Browne(1984)은 데이터가 정규분포를 따르지 않아도 정확한 추정치를 얻을 수 있는 ADF 추정법을 개발했습니다. 다만, 이 방법은 매우 큰 표본을 요구한다는 단점이 있어, 이후 Satorra-Bentler와 같은 수정된 통계량들이 개발되어 널리 쓰이게 되었습니다.
5.2. 범주형 자료와 서열 척도
설문조사의 “매우 그렇다 ~ 매우 아니다”는 엄밀히 말하면 연속형 변수가 아니라 서열(Ordinal) 변수입니다.
- Muthén의 기여: Muthén(1984)은 범주형 변수를 분석할 때 다류 상관계수(Polychoric correlation)를 사용하여 잠재변수 간의 관계를 추정하는 프레임워크를 완성했습니다. 이를 통해 리커트 척도 데이터도 SEM에서 엄밀하게 다룰 수 있게 되었습니다.
6. 최신 흐름: SEM의 현재와 미래 (Recent Advances)
이제 SEM은 단순한 인과모형을 넘어 다양한 통계적 난제들을 해결하는 종합 플랫폼으로 진화했습니다.
6.1. 잠재성장모형 (Latent Growth Models)
학생들의 성적은 시간에 따라 변합니다. SEM은 이제 횡단적 분석뿐만 아니라 종단적 변화도 모델링합니다.
- LGM: 학생들의 초기 성적(Intercept)과 성장 속도(Slope)를 잠재변수로 설정하여, “누가 더 빨리 성장하는가?”, “무엇이 성장을 촉진하는가?”를 분석합니다.
- 잠재계층 성장모형 (LCGA): 모든 학생이 똑같은 패턴으로 성장하지 않습니다. 어떤 그룹은 성적이 급상승하고, 어떤 그룹은 정체될 수 있습니다. Nagin과 Muthén은 이러한 이질적인 하위 그룹을 찾아내는 혼합 모형(Mixture Model)을 SEM에 결합했습니다.
6.2. 베이지안 접근 (Bayesian Approaches)
전통적인 빈도주의(Frequentist) 통계는 p-value에 의존하지만, 최근에는 사전 정보(Prior)를 결합하여 추정의 정확성을 높이는 베이지안 SEM이 확산되고 있습니다.
- MCMC: 복잡한 모형의 파라미터 분포를 시뮬레이션을 통해 추정하는 기법으로, 기존 ML 방식으로는 풀기 어려웠던 복잡한 모델도 추정 가능하게 했습니다.
6.3. 인과 추론의 재발견 (Causality)
“상관관계는 인과관계가 아니다”라는 말은 통계학의 철칙이었습니다. 하지만 Pearl, Rubin 등은 “그렇다면 언제 인과라고 부를 수 있는가?”에 대해 수학적으로 답하기 시작했습니다.
- 반사실적 접근 (Counterfactuals): “만약 이 학생이 다른 교수법을 받았다면 어땠을까?”라는 잠재적 결과(Potential Outcomes) 프레임워크가 SEM에 도입되었습니다.
- Pearl의 그래프 모형: 변수 간의 인과 구조를 그래프로 표현하고, d-separation과 같은 규칙을 통해 어떤 변수를 통제해야 진정한 인과효과를 얻을 수 있는지 식별합니다.
6.4. 기계학습과 SEM (Machine Learning)
최근에는 기계학습(Machine Learning)이 SEM에 들어왔습니다.
- SEM Trees: 의사결정나무(Decision Tree) 기법을 사용하여, 모형의 경로 계수가 달라지는 집단(예: 성별, 소득수준 등)을 자동으로 탐색합니다.
- TETRAD: 인공지능 알고리즘을 사용하여 데이터만으로 인과 구조를 “발견”하려는 시도들도 이루어지고 있습니다.
7. 결론
구조방정식 모델링(SEM)은 단순한 통계 도구가 아닙니다. 그것은 생물학의 유전 법칙, 사회학의 인과 추론, 심리학의 잠재적 구성 개념, 경제학의 상호의존성이 만나 빚어낸 지적 융합의 결정체입니다.
여러분은 이제 이 강력한 도구를 손에 쥐고 있습니다. 중요한 것은 복잡한 수식이 아니라, “내 연구 가설을 어떤 구조로 설명할 것인가?“라는 여러분의 통찰력입니다. SEM은 그 통찰력을 검증해 주는 든든한 파트너가 될 것입니다.
참고문헌 (References)
- Bollen, K. A. (1989). Structural equations with latent variables. New York: Wiley.
- Browne, M. W. (1984). Asymptotically distribution-free methods for the analysis of covariance structures. British Journal of Mathematical and Statistical Psychology, 37, 62-83.
- Duncan, O. D. (1966). Path analysis: Sociological examples. American Journal of Sociology, 72, 1-16.
- Hauser, R. M., & Goldberger, A. S. (1971). The treatment of unobservable variables in path analysis. In H. L. Costner (Ed.), Sociological methodology 1971 (pp. 81-87). San Francisco: Jossey-Bass.
- Jöreskog, K. G. (1970). A general method for analysis of covariance structures. Biometrika, 57, 239-251.
- Matsueda, R. L. (2012). A Brief History of Structural Equation Modeling. In R. H. Hoyle (Ed.), Handbook of Structural Equation Modeling (pp. 17-48). Guilford Press.
- Muthén, B. (1984). A general structural equation model with dichotomous, ordered categorical, and continuous latent variable indicators. Psychometrika, 49, 115-132.
- Pearl, J. (2000). Causality: Models, reasoning, and inference. Cambridge, UK: Cambridge University Press.
- Spearman, C. (1904). General intelligence, objectively determined and measured. American Journal of Psychology, 15, 201-293.
- Wright, S. (1921). Correlation and causation. Journal of Agricultural Research, 20, 557-585.