
안녕하세요!
오늘은 다층모형(Multilevel Model)의 가정 위배 진단, 그래픽 분석, 그리고 적합도 평가에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
다층모형 진단: 우리 반 아이들의 성장 곡선, 제대로 그린 걸까?
안녕하세요, 대학원생 여러분. 오늘은 다층모형(MLM)을 돌리고 나서 “과연 이 결과가 믿을 만한가?”를 검증하는 단계, 즉 모형 진단(Model Diagnostics)에 대해 배워보겠습니다.
우리가 병원에서 엑스레이를 찍고 의사 선생님이 판독하듯이, 통계 모형을 만든 후에는 이 모형이 데이터와 잘 맞는지(Lack of Fit), 가정은 지켜졌는지 확인해야 합니다. ‘읽기 유창성 성장 모형’ 예시를 통해 하나씩 짚어보겠습니다.
1. 시나리오 및 데이터 생성 (The Scenario)
📖 연구 배경: “책 읽는 호랑이 프로젝트”
우리는 A 초등학교 3학년 학생 30명을 대상으로 6학기 동안(3학년 1학기 ~ 5학년 2학기) ‘읽기 유창성(Reading Fluency)’ 점수가 어떻게 변화하는지 추적했습니다.
- 연구 문제: 학생들의 읽기 능력은 시간이 지남에 따라 선형적으로 증가하는가? 학생마다 시작점(절편)과 성장 속도(기울기)는 다른가?
🛠️ R을 이용한 모의 데이터 생성
먼저 분석할 데이터를 만들어 봅시다. 이 데이터는 jamovi에서 불러와 실습할 수 있습니다.
R
# 필수 패키지 로드
if(!require(MASS)) install.packages("MASS")
if(!require(lme4)) install.packages("lme4")
if(!require(lattice)) install.packages("lattice")
set.seed(123)
# 1. 기본 설정
n_subjects <- 30 # 학생 수
n_timepoints <- 6 # 시점 수 (0~5)
N <- n_subjects * n_timepoints
# 2. 시간 변수 생성 (0, 1, 2, 3, 4, 5)
time <- rep(0:(n_timepoints-1), n_subjects)
subject_id <- rep(1:n_subjects, each=n_timepoints)
# 3. 무선 효과(Random Effects) 생성: 절편(초기값)과 기울기(성장률)
# 평균은 0, 분산-공분산 행렬 Sigma 설정
Sigma <- matrix(c(100, 20,
20, 15), nrow=2) # 절편분산 100, 기울기분산 15, 공분산 20
random_effects <- mvrnorm(n_subjects, mu=c(0, 0), Sigma=Sigma)
u0 <- rep(random_effects[,1], each=n_timepoints) # 학생별 고유 절편
u1 <- rep(random_effects[,2], each=n_timepoints) # 학생별 고유 기울기
# 4. 고정 효과(Fixed Effects) 설정
beta0 <- 150 # 전체 평균 초기 점수
beta1 <- 10 # 학기당 평균 성장 점수
# 5. 오차항(Residuals) 생성
error <- rnorm(N, mean=0, sd=10)
# 6. 종속변수(읽기 점수) 생성
# Y = (beta0 + u0) + (beta1 + u1)*Time + error
reading_score <- (beta0 + u0) + (beta1 + u1) * time + error
# 데이터 프레임 생성
data_school <- data.frame(
ID = as.factor(subject_id),
Time = time,
Score = reading_score
)
# 데이터 확인
head(data_school)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data_school, "chap24.csv", row.names = FALSE)2. 데이터 시각화: 트렐리스(Trellis) 그래프
텍스트에서는 모형을 수립하기 전, 데이터를 눈으로 확인하는 것이 매우 중요하다고 강조합니다. 이때 가장 강력한 도구가 트렐리스 플롯(Trellis Plot), 혹은 격자 그래프입니다.
🔍 왜 필요한가요?
전체 평균 그래프만 보면 개별 학생들의 독특한 패턴(누군가는 점수가 떨어지거나, 누군가는 급격히 오르는 등)을 놓칠 수 있습니다. 트렐리스 플롯은 “각 학생의 그래프를 우표처럼 모아서 한눈에 보는 것”입니다.
📊 분석 방법
- Jamovi:
Exploration>Scatterplot에서 X축에 Time, Y축에 Score를 넣고,Group에 ID를 넣으면 되지만, 30명을 다 보기는 어렵습니다. - R (Lattice 패키지): 텍스트에서 추천하는 방식입니다. 각 패널에 학생 한 명의 데이터와 회귀선을 그립니다.
R
# R 코드: 트렐리스 플롯 그리기
library(lattice)
xyplot(Score ~ Time | ID, data = data_school,
type = c("p", "r"), # p: 점, r: 회귀선
main = "학생별 읽기 유창성 성장 곡선 (Trellis Plot)",
xlab = "시간 (학기)", ylab = "읽기 점수",
layout = c(6, 5)) # 6열 5행으로 배치
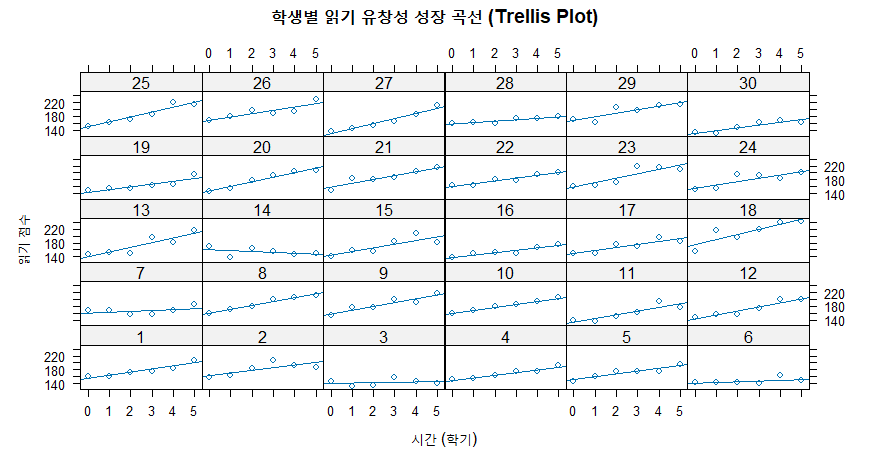
[해석] 이 그래프를 통해 우리는 다음을 직관적으로 알 수 있습니다.
- 절편의 차이: 시작 점수가 낮은 아이와 높은 아이가 섞여 있나? (무선 절편 필요성 확인)
- 기울기의 차이: 어떤 아이는 가파르게 성장하고, 어떤 아이는 완만한가? (무선 기울기 필요성 확인)
- 선형성: 점들이 직선 주변에 모여 있나, 아니면 곡선 형태인가?
3. 모형의 가정과 잔차(Residuals) 분석
다층모형은 크게 세 가지 가정을 전제로 합니다.
- 분포 가정: 오차항()과 무선 효과()는 정규분포를 따른다.
- 모형 구조: 이상치(Outlier)가 없으며 모든 관측치가 모형을 따른다.
- 함수 형태: 평균 반응은 선형적이다().
3.1 잔차의 두 얼굴: 주변 잔차 vs. 조건부 잔차
다층모형에서 잔차는 두 가지로 나뉩니다. 이 부분이 초심자가 가장 헷갈려 하는 부분입니다.
- 주변 잔차 (Marginal Residuals, ):
- “전체 평균 학생”과 “실제 학생 점수”의 차이입니다. 여기에는 학생 개인의 특성(무선 효과)도 오차에 포함되어 버립니다.
- 조건부 잔차 (Conditional Residuals, ):
- “그 학생의 예측된 성장선”과 “실제 점수”의 차이입니다. 순수한 오차()에 가깝습니다.
[진단 시 주의할 점] 텍스트에 따르면, 잔차 그림만으로는 모형의 가정을 완벽히 검증하기 어렵습니다. 특히 조건부 잔차는 서로 상관관계가 있을 수 있고, 표준화 과정에서 이상치가 가려지거나 평범한 값이 이상치처럼 보일 수 있기 때문입니다 .
3.2 정규성 검정의 함정 (Q-Q Plot의 배신)
보통 잔차의 정규성을 볼 때 Q-Q Plot을 많이 씁니다. 하지만 무선 효과(Random Effects)의 정규성을 Q-Q Plot으로 확인하는 것은 위험할 수 있습니다.
- 이유: McCulloch & Neuhaus(2011)에 따르면, 우리가 모형을 만들 때 이미 “정규분포를 따를 것이다”라고 가정하고 만들었기 때문에, 실제로는 정규분포가 아니더라도 Q-Q Plot에서는 정규분포처럼 보일 수 있습니다 .
4. 고급 진단: 무선 효과의 정규성 검정 (Order Selection Test)
그렇다면 “눈대중” 말고 진짜로 무선 효과가 정규분포인지 어떻게 알 수 있을까요? 텍스트에서는 순서 선택 검정(Order Selection Test)을 제안합니다.
💡 개념 설명 (초등학생 눈높이)
우리가 가진 데이터가 ‘종 모양(정규분포)’인지 확인하고 싶어요.
- 일단 종 모양(Normal)이라고 가정하고 맞는지 봅니다.
- 그다음 종 모양에 ‘혹’을 하나 붙여보고(Hermite polynomial 차수 추가), 더 잘 맞는지 봅니다.
- ‘혹’을 두 개 붙여보고 더 잘 맞는지 봅니다.
- 만약 ‘혹’이 없는 매끈한 종 모양일 때보다, 혹을 붙였을 때 설명력이 확 좋아진다면? “아, 이건 원래 종 모양이 아니었구나!”라고 판단하는 겁니다.
🛠️ 분석 구현 (jamovi & R)
jamovi는 아직 이 고급 검정을 메뉴로 제공하지 않습니다. 따라서 R을 사용하여 AIC(Akaike Information Criterion)를 이용한 약식 검정을 수행해 보겠습니다.
R
# R 코드: 정규성 가정 검토 (AIC 비교)
# H0: 무선 효과는 정규분포를 따른다.
model_null <- lmer(Score ~ Time + (1 + Time | ID), data = data_school, REML = FALSE)
# 비정규성을 반영하는 것은 복잡하므로, 여기서는 잔차 plot과 Q-Q plot을 통해
# 시각적으로 1차 점검을 하는 코드를 제시합니다.
# 1. 무선 효과 추출
ran_eff <- ranef(model_null)$ID
# 2. 시각적 확인 (Q-Q Plot)
par(mfrow=c(1,2))
qqnorm(ran_eff[,1], main = "Random Intercept Q-Q"); qqline(ran_eff[,1])
qqnorm(ran_eff[,2], main = "Random Slope Q-Q"); qqline(ran_eff[,2])
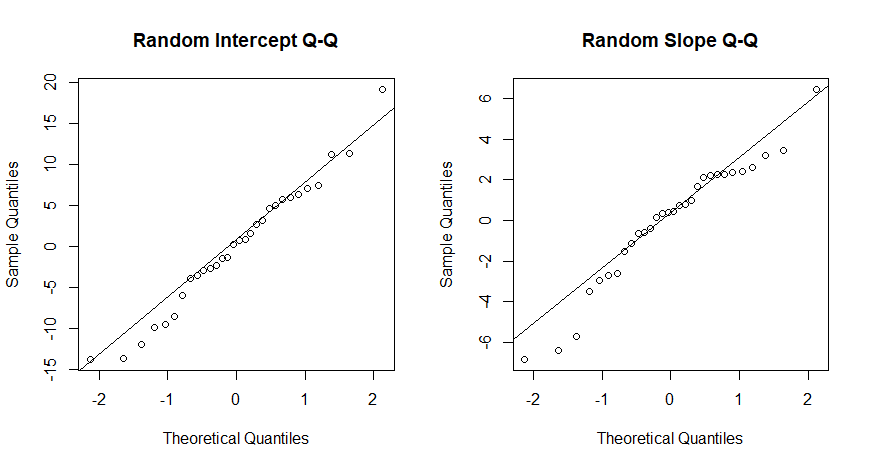
- 해석: 점들이 직선 위에 잘 놓여 있다면 정규성 가정을 만족한다고 볼 수 있습니다. 만약 심하게 휘어진다면,
Order Selection Test같은 고급 기법이나 비모수적 방법(Nonparametric methods)을 고려해야 합니다.
5. 이상치(Outlier)와 영향력 있는 관측치 탐색
어떤 학생의 데이터가 전체 분석 결과를 왜곡하고 있지는 않을까요?
5.1 분산 이동 모형 (Variance Shift Model)
특정 학생이 유난히 점수의 변동폭(오차 분산)이 클 수 있습니다. 이를 분산 이동(Variance Shift)이라고 합니다.
- 예: 철수는 기분파라 어떤 날은 100점, 어떤 날은 0점을 받습니다. 다른 학생들보다 이 훨씬 큽니다. 이런 경우 철수는 이상치(Outlier)로 볼 수 있습니다.
5.2 쿡의 거리 (Cook’s Distance)
단순 회귀분석처럼 다층모형에서도 쿡의 거리를 사용하여 영향력 있는 사례(Subject)를 찾습니다.
- 특정 학교나 특정 학생을 데이터에서 뺐을 때, 회귀계수()가 확 바뀐다면 그 대상은 영향력이 매우 큰 것입니다.
🛠️ 분석 구현 (jamovi)
jamovi의 GAMLj 모듈(설치 필요)을 사용하면 쿡의 거리를 쉽게 구할 수 있습니다.
- Jamovi:
Modules>jamovi library>GAMLj설치. Linear Models>Mixed Model선택.- Dependent Variable:
Score - Covariates:
Time - Cluster:
ID - Random Effects:
Intercept+Time(체크) - Options (혹은 Plots) 탭에서
Cook's Distance체크 (버전별 위치 상이, 보통Assumption Checks에 위치).
6. 고정 효과의 선형성 검정
우리는 읽기 실력이 ‘직선’으로 증가한다고 가정했습니다 (). 하지만 실제로는 처음에 급격히 늘다가 고학년이 되면 정체될 수도 있습니다(곡선).
🔍 진단 방법
- 잔차 그림: 잔차도(Residual Plot)에서 자 형태나 뒤집힌 자 형태가 나타나면 선형성 위배입니다.
- 해결책:
Time의 제곱항()을 모형에 추가하거나, 스플라인(Spline) 회귀를 사용합니다.
7. 결론 및 요약
다층모형 분석을 마친 후에는 반드시 다음 질문을 던져야 합니다.
- 개별 데이터를 확인했는가? (Trellis Plot)
- 잔차는 무작위로 분포하는가? (Conditional Residuals Plot)
- 무선 효과는 정규분포에 가까운가? (단, Q-Q plot의 한계 인지)
- 전체 결과를 뒤흔드는 이상한 학생(Outlier)은 없는가? (Cook’s Distance)
이 과정이 없다면, 아무리 복잡한 수식으로 계산된 결과라도 “모래 위에 지은 집”과 같습니다. 오늘 배운 진단 도구들을 활용하여 여러분의 연구 결과를 튼튼하게 만드시기 바랍니다.
참고문헌 (APA Style)
- Aerts, M., Claeskens, G., & Hart, J. D. (1999). Testing the fit of a parametric function. Journal of the American Statistical Association, 94, 869-879.
- Claeskens, G. (2015). Lack of fit, graphics, and multilevel model diagnostics. In The SAGE Handbook of Multilevel Modeling (pp. 425-443). SAGE Publications.
- Demidenko, E., & Stukel, T. A. (2005). Influence analysis for linear mixed-effects models. Statistics in Medicine, 24, 893-909.
- McCulloch, C. E., & Neuhaus, J. M. (2011). Misspecifying the shape of a random effects distribution: Why getting it wrong may not matter. Statistical Science, 26, 388-402.
- Verbeke, G., & Molenberghs, G. (2013). The gradient function as an exploratory goodness-of-fit assessment of the random effects distribution in mixed models. Biostatistics.