
안녕하세요!
오늘은 다층모형(Multilevel Modeling)에서 가정 위배에 대처하는 ‘강건한(Robust) 분석 방법’에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, 고급 강건성 분석(Robust SE, Bootstrapping, Bayesian) 등 jamovi 기본 기능의 한계를 넘어서는 부분은 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 서론: 왜 ‘강건한(Robust)’ 방법이 필요한가요?
교육 현장의 데이터는 교과서처럼 깔끔하지 않습니다.
예를 들어, 어떤 반에는 유독 책을 많이 읽는 ‘독서 영재(이상치, Outlier)’가 있을 수 있고, 어떤 학교는 학생 수가 너무 적을 수도 있습니다.
통계 분석을 할 때 우리는 흔히 “데이터가 정규분포를 따를 것이다(Normality)”, “분산이 일정할 것이다(Homoscedasticity)”라는 가정을 합니다. 하지만 현실 데이터가 이 약속을 어긴다면 어떻게 될까요? 우리가 내린 결론(통계적 유의성)이 틀릴 수도 있습니다.
이때 필요한 것이 바로 강건한(Robust) 방법입니다.
강건성(Robustness)이란? 데이터가 기본 가정(정규성 등)을 다소 위배하더라도, 통계적 추정 결과나 신뢰구간이 크게 흔들리지 않고 믿을 만한 결과를 내놓는 성질을 말합니다.
이제 가상의 ‘해바라기 초등학교’ 데이터를 만들어 이 문제를 해결해 봅시다.
2. 모의 데이터 생성: 해바라기 초등학교 이야기
우리는 “교사의 정서적 지지(Teacher Support)가 학생의 학업 스트레스(Stress)를 낮추는가?”를 연구하려고 합니다.
- 1수준(학생): 학업 스트레스(종속변수 ), 학생의 불안 성향(공변량 )
- 2수준(학급): 교사의 정서적 지지()
- 시나리오: 대부분의 학생은 평범하지만, 몇몇 학생은 불안 성향이 매우 높습니다(데이터가 한쪽으로 찌그러짐, Skewed). 또한, 몇몇 반은 학생 수가 적습니다.
먼저 R을 이용해 이 상황을 반영한 데이터를 생성해보겠습니다.
R
# R Code: 데이터 생성
set.seed(2026)
# 50개 학급(Class), 학급당 학생 수 5~25명(불균형)
n_classes <- 50
class_id <- rep(1:n_classes, times = sample(5:25, n_classes, replace = TRUE))
n_students <- length(class_id)
# 2수준 변수: 교사의 정서적 지지 (랜덤 효과 포함)
class_intercept <- rnorm(n_classes, mean = 50, sd = 10)
teacher_support <- rnorm(n_classes, mean = 5, sd = 2)
class_effect <- class_intercept[class_id]
support_level <- teacher_support[class_id]
# 1수준 변수: 학생의 불안 성향 (치우친 분포 생성 - Gamma 분포 활용)
student_anxiety <- rgamma(n_students, shape = 2, scale = 2)
# 이상치(Outlier) 추가: 몇몇 학생은 극도로 높은 불안을 가짐
student_anxiety[sample(1:n_students, 5)] <- 30
# 종속변수 생성 (Stress)
# 모델: Stress = 50 - 2*Support + 1.5*Anxiety + Random_Error
error <- rnorm(n_students, mean = 0, sd = 5)
stress <- 50 - 2 * support_level + 1.5 * student_anxiety + class_effect + error
# 데이터 프레임 생성
data <- data.frame(
ClassID = as.factor(class_id),
Stress = stress,
TeacherSupport = support_level,
Anxiety = student_anxiety
)
# 데이터 확인
head(data)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data, "chap22.csv", row.names = FALSE)
3. 진단(Diagnosis): 데이터의 건강검진
분석 전에 데이터가 가정을 잘 지키는지 확인해야 합니다. 책에서는 이상치(Outliers)와 다중공선성(Multicollinearity) 확인을 강조합니다.
3.1. 이상치 및 분포 확인 (Jamovi & R)
다층모형에서는 전체 데이터뿐만 아니라 수준별(Level-wise)로 잔차(Residual)를 확인해야 합니다. 하지만 SPSS나 일반 소프트웨어는 이를 잘 지원하지 않는 경우가 많습니다.
- Jamovi: [Exploration] -> [Descriptives]에서 ‘Box plot’과 ‘Q-Q plot’을 체크합니다.
- R 시각화:
R
# 상자수염그림(Boxplot)으로 이상치 확인
boxplot(data$Stress, main="학업 스트레스 분포(이상치 확인)")
# Q-Q plot으로 정규성 확인
qqnorm(data$Stress); qqline(data$Stress, col = "red")
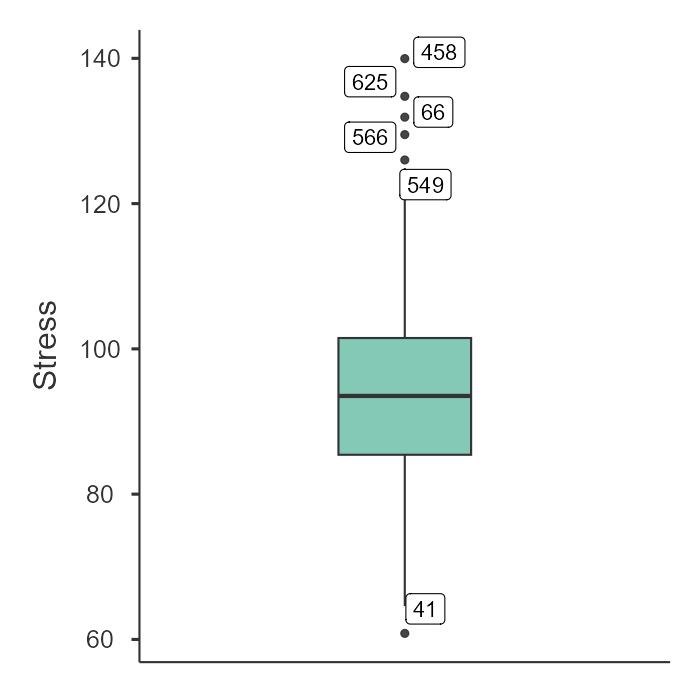
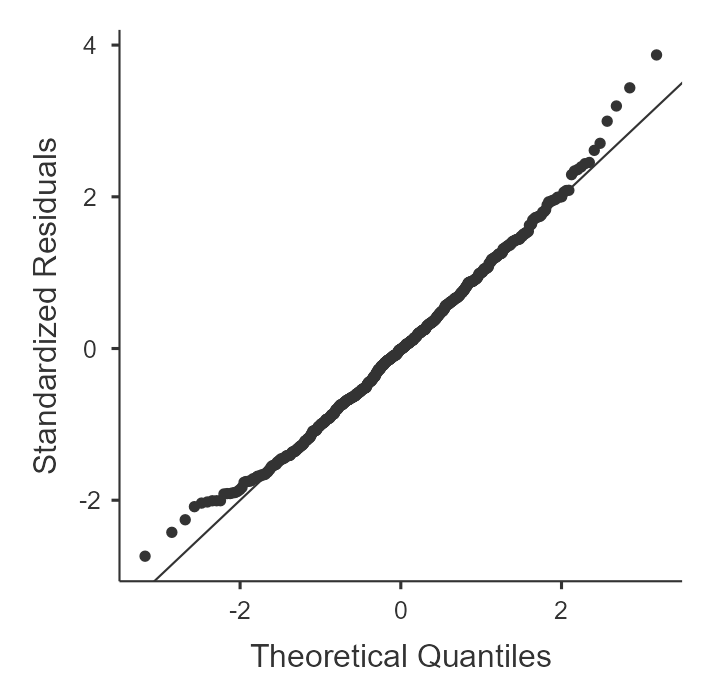
[해설] 만약 상자수염그림(Boxplot) 위쪽에 동그라미(Outlier)가 찍혀 있거나, Q-Q plot에서 점들이 붉은 선을 벗어난다면 정규성 가정이 위배된 것입니다. 우리 데이터에는 일부러 이상치를 넣었으므로 위배되었을 가능성이 큽니다.
4. 해결책 A: 강건한 표준오차 (Robust Standard Errors)
데이터가 정규성을 위배하거나 등분산성을 만족하지 못할 때 사용할 수 있는 첫 번째 무기는 ‘강건한 표준오차(Robust SE)’입니다. 샌드위치 추정량(Sandwich Estimator)이라고도 부릅니다.
4.1. 개념 설명
일반적인 최대우도법(ML)은 데이터가 정규분포라고 가정하고 표준오차를 계산합니다. 가정이 틀리면 표준오차가 너무 작게 계산되어, 실제로는 효과가 없는데도 “유의하다”고 잘못 결론 내릴 수 있습니다. Robust SE는 데이터의 잔차(Residual)를 직접 이용하여 표준오차를 보정합니다. 이를 통해 가정이 깨져도 올바른 검정 결과를 얻을 수 있습니다.
주의점: Robust SE가 제대로 작동하려면 2수준(학급)의 표본 크기가 충분해야 합니다(최소 50~100개 그룹 권장).
4.2. 분석 방법 (R)
Jamovi의 기본 Mixed Model 모듈은 아직 Robust SE를 직접 지원하지 않습니다. 따라서 R의 lme4와 clubSandwich 패키지를 사용합니다.
R
# 패키지 로드
library(lme4)
library(clubSandwich)
# 1. 일반적인 다층모형 적합 (Random Intercept Model)
model_lmer <- lmer(Stress ~ TeacherSupport + Anxiety + (1|ClassID), data = data)
# 2. 결과 확인 (일반 SE)
summary(model_lmer)
# 3. 강건한 표준오차(Robust SE) 구하기 (CR2 방식 권장)
robust_results <- coef_test(model_lmer, vcov = "CR2")
print(robust_results)
[결과 해석] 일반적인 summary 결과와 coef_test 결과를 비교해 보세요. 만약 정규성 위배가 심각하다면, Robust SE를 적용했을 때 표준오차(SE)가 커지고 p-value가 변할 수 있습니다. 이것이 더 보수적이고 안전한 결과입니다.
5. 해결책 B: 부트스트래핑 (Bootstrapping)
두 번째 방법은 컴퓨터의 힘을 빌리는 부트스트래핑입니다. 이론적인 분포(정규분포)에 의존하지 않고, 내 데이터를 수천 번 재표집(Resampling)하여 분포를 직접 만들어내는 방식입니다.
5.1. 개념 설명
우리의 데이터가 모집단 그 자체라고 가정하고, 여기서 복원추출을 통해 수천 개의 가상 데이터를 만듭니다.
- 다층모형에서의 주의점: 단순히 케이스를 뽑으면 안 됩니다. 학급 구조가 깨지기 때문입니다. 잔차 부트스트래핑(Residual Bootstrapping)이 가장 선호되는 방법입니다.
5.2. 분석 방법 (R)
이 역시 계산량이 많아 R을 사용합니다. lme4 패키지의 bootMer 함수를 사용합니다.
R
# 부트스트랩 함수 정의 (고정 효과 추출)
mySumm <- function(.) {
fixef(.)
}
# 부트스트래핑 실행 (nsim = 1000번 반복)
# use.u = TRUE는 랜덤 효과도 고려한다는 뜻
boot_results <- bootMer(model_lmer, mySumm, nsim = 1000, use.u = TRUE, type = "parametric")
# 95% 신뢰구간 계산
boot_CI <- boot.ci(boot_results, type = "perc", index = 1) # Intercept에 대한 예시
print(boot_results)
[장점] 부트스트래핑은 특히 매개효과 분석이나 분산 성분에 대한 신뢰구간을 구할 때 매우 강력합니다. 정규성 가정이 크게 위배되어도 믿을 만한 결과를 줍니다.
6. 해결책 C: 베이지안 추정 (Bayesian Estimation)
세 번째, 가장 강력하고 유연한 방법인 베이지안 추정입니다. 특히 표본 크기가 작을 때(학급 수가 적을 때) 매우 유용합니다.
6.1. 개념 설명
전통적인 통계(빈도주의)는 모수가 고정되어 있다고 보지만, 베이지안은 모수도 확률분포를 가진다고 봅니다.
- 사전 정보(Prior): 연구자가 미리 알고 있는 정보.
- 우도(Likelihood): 데이터에서 얻은 정보.
- 사후 분포(Posterior): 이 둘을 합쳐 업데이트된 결론.
강건성을 위해 정규분포 대신 꼬리가 긴 t-분포(t-distribution)를 가정하여 이상치의 영향을 줄일 수 있습니다.
6.2. 분석 방법 (R – brms 패키지)
brms 패키지는 베이지안 다층모형을 매우 쉽게 구현해 줍니다.
R
library(brms)
# 베이지안 다층모형 적합
# student: 정규분포 대신 t-분포를 사용하여 이상치에 강건하게 만듦
model_bayes <- brm(
Stress ~ TeacherSupport + Anxiety + (1|ClassID),
data = data,
family = student(), # 핵심: 강건성을 위해 student t 분포 사용
chains = 2, iter = 2000
)
# 결과 확인
summary(model_bayes)
plot(model_bayes) # 수렴 확인 (Trace plot)
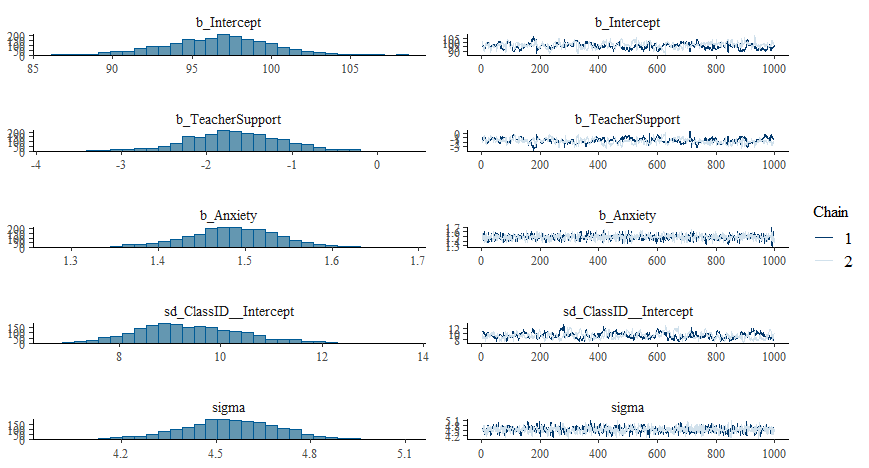
[해설] 베이지안 분석은 p-value 대신 신뢰구간(Credible Interval)을 제공합니다. 95% 구간 안에 0이 포함되지 않으면 “효과가 있다”고 봅니다. 특히 family = student() 옵션을 사용하면 이상치가 있어도 회귀계수가 크게 휘둘리지 않습니다.
7. 결론 및 요약
학교 현장 데이터처럼 가정이 위배되기 쉬운 자료를 다룰 때, 맹목적으로 일반적인 다층분석을 돌리는 것은 위험합니다.
- 진단하라: Jamovi나 R의 플롯을 통해 이상치와 분포를 확인하세요.
- 강건한 표준오차(Robust SE): 이상치가 있거나 이분산성이 의심될 때, 학급 수가 50개 이상이라면 가장 간편한 대안입니다.
- 부트스트래핑: 분산 추정치가 중요하거나 분포 가정을 피하고 싶을 때 유용합니다.
- 베이지안 추정: 학급 수가 적거나(20~50개 미만), 모형이 복잡하거나, 극단적인 이상치가 많을 때 최고의 선택입니다.
선생님, 연구자 여러분의 데이터가 조금 거칠더라도 걱정하지 마세요. 우리에게는 이처럼 든든한 ‘강건한 도구’들이 있습니다.
참고문헌 (APA Style)
- Eliason, S. R. (1993). Maximum likelihood estimation. Sage.
- Hox, J. J., & van de Schoot, R. (2013). Robust methods for multilevel analysis. In The SAGE Handbook of Multilevel Modeling (pp. 387-402). SAGE Publications Ltd.
- Maas, C. J. M., & Hox, J. J. (2004). Robustness issues in multilevel regression analysis. Statistica Neerlandica, 58(2), 127-137.
- Maas, C. J. M., & Hox, J. J. (2005). Sufficient sample sizes for multilevel modeling. Methodology, 1(3), 85-91.
- Tabachnick, B. G., & Fidell, L. S. (2007). Using multivariate statistics (5th ed.). Allyn & Bacon.
- Van der Leeden, R., Meijer, E., & Busing, F. M. T. A. (2008). Resampling multilevel models. In J. de Leeuw & E. Meijer (Eds.), Handbook of multilevel analysis (pp. 401-433). Springer.