
안녕하세요? 이번에 함께 다룰 주제는 “구조방정식 모형(SEM)을 활용한 메타분석(Meta-Analysis)”입니다.
보통 메타분석이라고 하면 jamovi의 MAJOR 모듈이나 R의 metafor 패키지를 떠올리실 겁니다. 하지만 오늘은 조금 더 고급스럽고 유연한 접근법인 SEM 프레임워크 안에서 메타분석을 수행하는 방법을 배울 것입니다. 이 방법은 복잡한 데이터 구조(다변량, 다수준 등)를 다룰 때 매우 강력합니다.
jamovi를 기본으로 하되, SEM 기반 메타분석의 핵심 기능을 구현하기 위해 jamovi 내의 Rj Editor (혹은 R)에서 구동되는 metaSEM 패키지 코드를 중심으로 진행하겠습니다.
1. SEM과 메타분석의 만남: 개념적 지도
먼저, 이 두 가지가 어떻게 연결되는지 이해해야 합니다. 많은 연구자가 이 둘을 별개의 영역으로 생각하지만, 사실 메타분석은 SEM의 특수한 형태입니다.
핵심 아이디어: 연구(Study)를 피험자(Subject)로 보라!
SEM 기반 메타분석의 가장 중요한 통찰은 개별 연구 하나하나를 구조방정식 모형에서의 한 명의 피험자(Subject)로 취급한다는 점입니다.
| SEM 개념 | 메타분석 개념 |
| 피험자 (Subject) | 개별 연구 (Study) |
| 관측 변수 (Observed Variable) | 관측된 효과크기 (Observed Effect Size, ) |
| 잠재 변수 (Latent Variable) | 참 효과크기 (True Effect Size, ) |
| 측정 오차 분산 (Error Variance) | 표집 분산 (Sampling Variance, ) – 이미 알고 있는 값! |
| 잠재 변수 평균 (Mean) | 평균 효과크기 (Average Effect) |
| 잠재 변수 분산 (Variance) | 이질성 분산 (Heterogeneity Variance, ) |
2. 실습 시나리오: “AI 기반 작문 피드백의 효과”
이해를 돕기 위해 가상의 교육학 데이터를 생성해 보겠습니다.
연구 배경: 최근 교육 현장에서 ChatGPT와 같은 AI를 활용한 작문 피드백이 학생들의 글쓰기 능력에 미치는 영향에 대한 연구가 쏟아지고 있습니다. 우리는 지난 5년 동안 발표된 20편의 관련 연구를 수집했습니다.
데이터 변수:
Study: 연구 IDyi: 효과크기 (Hedges’ g, 작문 점수 차이)vi: 효과크기의 표집 분산 (Sampling Variance)Year: 출판 연도 (공변량)SchoolLevel: 학교급 (초등=0, 중등=1)
[실습] 데이터 생성 (R 코드)
jamovi의 Rj Editor를 열고 아래 코드를 실행하거나, RStudio를 사용하세요. 이 코드는 첨부 파일의 맥락에 맞춰 시뮬레이션 데이터를 생성합니다.
R
set.seed(20260105)
k <- 20 # 연구 수
# 참 효과크기 (평균 0.5, 이질성 분산 0.05)
true_effect <- rnorm(k, mean = 0.5, sd = sqrt(0.05))
# 샘플 사이즈에 따른 표집 분산 (vi) 생성
n <- sample(30:200, k, replace = TRUE)
vi <- 4/n # 근사적인 분산
# 관측된 효과크기 (yi) = 참값 + 오차
yi <- rnorm(k, mean = true_effect, sd = sqrt(vi))
# 공변량 생성
Year <- round(runif(k, 2018, 2024))
SchoolLevel <- sample(c(0, 1), k, replace = TRUE) # 0:Elementary, 1:Secondary
my_data <- data.frame(Study=1:k, yi=yi, vi=vi, Year=Year, SchoolLevel=SchoolLevel)
head(my_data)
3. 단변량 메타분석 (Univariate Meta-Analysis)
3.1 고정효과 모형 (Fixed-Effect Model)
고정효과 모형은 모든 연구가 동일한 참 효과크기()를 공유한다고 가정합니다. 즉, 연구 간의 차이는 오직 표집 오차(sampling error) 때문이라고 봅니다.
SEM으로 이를 표현하면 다음과 같습니다:
- 모형:
- 여기서 (각 연구의 는 이미 알고 있는 값으로 고정)
[SEM 도식화]
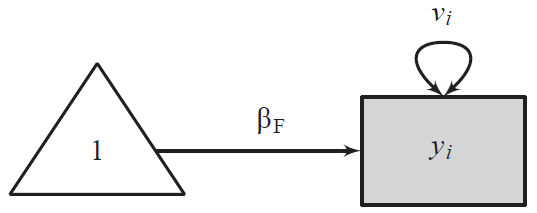
삼각형(상수 1)에서 네모()로 가는 화살표가 평균 효과()입니다. 이때 의 오차 분산은 로 고정됩니다.
3.2 무선효과 모형 (Random-Effects Model)
현실적으로 모든 연구의 효과가 같을 수는 없습니다. 연구 대상, 도구, 환경이 다르니까요. 무선효과 모형은 참 효과크기 자체가 분포()를 가진다고 가정합니다.
- 모형:
- 여기서 (이질성 분산, 추정해야 할 값)
[분석 도구: R metaSEM 패키지]
metaSEM 패키지는 OpenMx를 기반으로 하여 이러한 모델링을 아주 쉽게 해줍니다.
R
# install.packages("metaSEM") # 최초 1회 설치 필요
library(metaSEM)
# 무선효과 모형 실행
random_model <- meta(y = yi, v = vi, data = my_data, model.name = "Random Effects Model")
summary(random_model)
[해석]
- Intercept1: 추정된 평균 효과크기()입니다.
- Tau2(1,1): 연구 간 이질성 분산()입니다. 이 값이 0보다 크다면 연구들의 결과가 서로 다르다는 것을 의미합니다.
- : 총 분산 중 연구 간 이질성이 차지하는 비율입니다. (25%=낮음, 50%=중간, 75%=높음).
4. 혼합효과 모형 (Mixed-Effects Model): 메타 회귀
단순히 “효과가 다르다(이질성이 있다)”에서 멈추면 안 됩니다. “왜 다른가?”를 설명해야 합니다. 이를 위해 공변량(Covariate)을 도입하는 것을 혼합효과 모형 또는 메타 회귀(Meta-regression)라고 합니다.
우리의 시나리오에서는 “학교급(초등 vs 중등)”이 AI 피드백 효과를 조절하는지 알아보겠습니다.
SEM 모델링 방식
SEM에서는 공변량을 처리하는 두 가지 방식이 있습니다.
- 공변량을 변수(Variable)로 취급: 공변량의 평균과 분산도 모델 내에서 추정 (결측치 처리에 유리).
- 공변량을 설계 행렬(Design Matrix)로 취급: 전통적인 회귀분석 방식. 공변량 값은 고정된 것으로 간주.
우리는 metaSEM을 사용하여 간단하게 분석해 보겠습니다.
R
# 학교급(SchoolLevel)을 공변량으로 투입
mixed_model <- meta(y = yi, v = vi, x = SchoolLevel, data = my_data,
model.name = "Mixed Effects Model")
summary(mixed_model)
[결과 해석]
- Slope1 (Coeff): 학교급이 1단위 증가할 때(초등 중등), 효과크기의 변화량입니다.
- 만약 이 값이 음수(-)이고 유의하다면, “AI 피드백은 중등보다 초등에서 더 효과적이다”라고 해석할 수 있습니다.
- : 공변량이 설명하는 이질성 분산의 비율입니다. 설명력 지수라고 보시면 됩니다.
5. 다변량 메타분석 (Multivariate Meta-Analysis)
실제 교육 연구에서는 한 연구에서 여러 개의 결과 변수를 동시에 보고하는 경우가 많습니다.
예를 들어, “작문 점수(Writing Score)”와 “작문 흥미(Writing Interest)”를 동시에 측정했다고 합시다.
이 두 변수는 서로 상관이 있을 텐데, 이를 무시하고 각각 별도로 메타분석을 하면 오류가 발생합니다. SEM 기반 메타분석은 이 상관관계(Dependence)를 모델에 직접 포함할 수 있다는 강력한 장점이 있습니다.
시나리오 확장
- : 작문 점수 효과크기
- : 작문 흥미 효과크기
- 두 효과크기 간의 상관관계가 존재함.
[SEM 도식화]
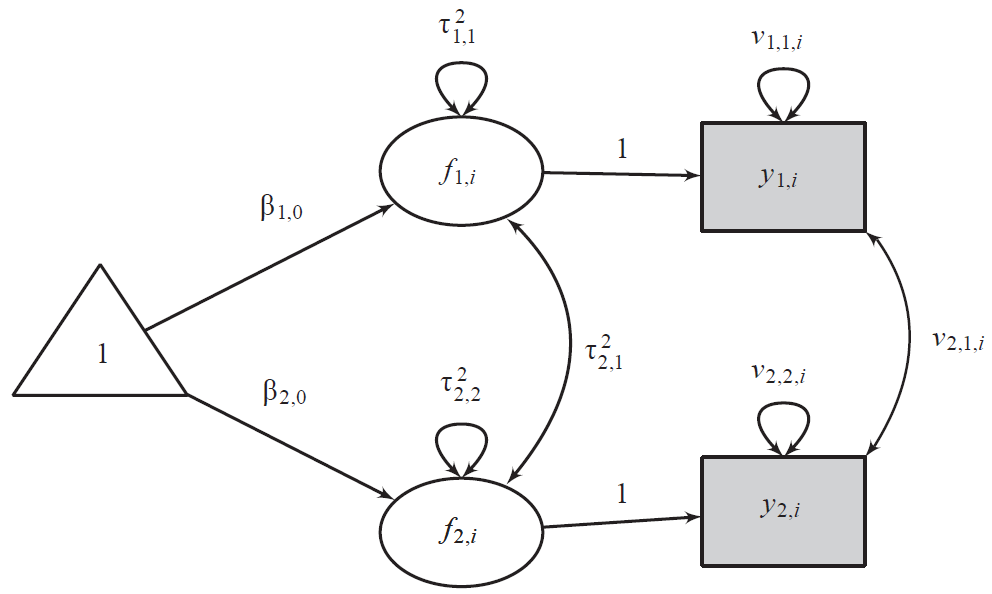
두 개의 잠재 변수()가 있고, 이 둘 사이에 공분산(화살표 연결)이 설정됩니다. 관측 변수의 오차들도 서로 상관될 수 있습니다.
R
library(metaSEM)
set.seed(20260105)
k <- 20 # 연구 수
# 1. 샘플 사이즈와 분산 생성
n <- sample(50:200, k, replace = TRUE)
v1 <- 4/n # 작문 점수의 분산
v2 <- 4/n # 작문 흥미의 분산
# 2. 공분산(Covariance) 생성
# 보통 연구 내 두 변수 간의 상관(r)을 가정하여 계산합니다 (예: r = 0.5)
r_within <- 0.5
cov12 <- r_within * sqrt(v1) * sqrt(v2)
# 3. 참 효과크기(Latent True Effects) 생성 (두 변수 간 상관 r = 0.6 가정)
# MASS 패키지를 이용해 상관된 참값을 만듭니다.
library(MASS)
true_means <- c(0.5, 0.3) # y1=0.5, y2=0.3
true_sigma <- matrix(c(0.05, 0.03, 0.03, 0.05), 2, 2) # 이질성 공분산 행렬
true_effects <- mvrnorm(k, true_means, true_sigma)
# 4. 관측된 효과크기(Observed Effects) 생성
y1 <- rnorm(k, true_effects[,1], sqrt(v1))
y2 <- rnorm(k, true_effects[,2], sqrt(v2))
# 5. 데이터 프레임 만들기 (multivariate_data)
multivariate_data <- data.frame(Study = 1:k,
y1 = y1,
y2 = y2,
v1 = v1,
cov12 = cov12,
v2 = v2)
# 데이터 확인
head(multivariate_data)
write.csv(multivariate_data,"chap36-2.csv",row.names = F)
# 다변량 무선효과 모형 실행
multi_model <- meta(y = cbind(y1, y2),
v = cbind(v1, cov12, v2),
data = multivariate_data,
model.name = "Multivariate_Meta")
summary(multi_model)
이 분석을 통해 우리는 “작문 실력이 늘면 흥미도 같이 느는가?”에 대한 종합적인 답을 얻을 수 있습니다.
6. 3수준 메타분석 (Three-Level Meta-Analysis)
교육 연구에서는 “한 논문에서 여러 개의 효과크기를 보고”하거나, “같은 연구자가 여러 논문을 쓰는” 경우가 많습니다. 즉, 데이터가 내재된(Nested) 구조를 가집니다.
- Level 1: 개별 효과크기의 표집 오차 (Sampling Variance)
- Level 2: 한 연구 내의 변동 (Within-study Variance)
- Level 3: 연구 간의 변동 (Between-study Variance)
이 구조를 무시하면 표준오차(Standard Error)가 과소 추정되어, 실제로는 효과가 없는데 있다고 잘못 결론 내릴 수 있습니다. SEM은 이를 다층 모형(Multilevel Model)으로 아주 깔끔하게 처리합니다.
[SEM 도식화]
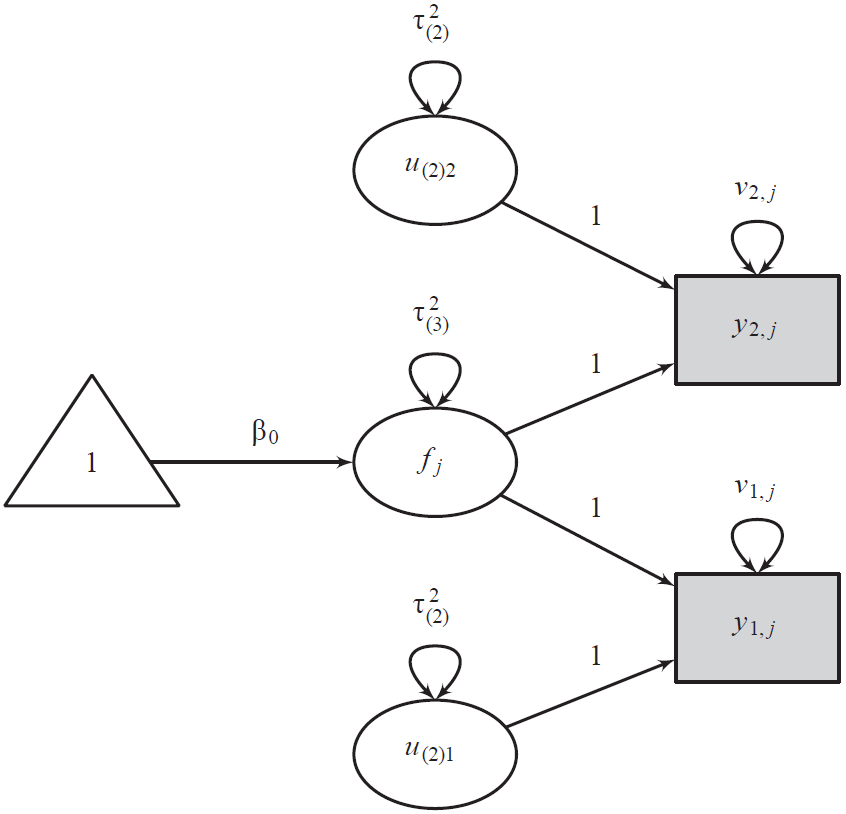
잠재 변수를 층위별로 설정하여, 연구 수준의 분산()과 연구 내 효과크기 수준의 분산()을 분리해 냅니다20.
R
# 3수준 메타분석 실행 (meta3L 함수 사용)
# cluster 변수는 '연구 ID'가 됩니다.
three_level_model <- meta3L(y = yi, v = vi, cluster = Study, data = my_data)
summary(three_level_model)
[해석의 핵심]
- I2_2 vs I2_3: 전체 변동 중 “연구 내 차이”()와 “연구 간 차이”()가 각각 얼마나 설명하는지 보여줍니다.
- 만약 가 매우 크다면, 어떤 연구(저자)가 수행했느냐에 따라 결과가 크게 달라진다는 뜻이므로 연구자의 특성을 탐색해봐야 합니다.
7. 요약 및 제언
오늘 우리는 첨부된 문헌을 바탕으로 SEM 기반 메타분석을 살펴보았습니다.
- 유연성: SEM 프레임워크를 사용하면 결측치 처리(FIML), 복잡한 제약 조건 설정, 다변량 및 다수준 분석이 훨씬 자유롭습니다.
- 확장성: 단순히 평균 효과를 구하는 것을 넘어, 효과크기들 간의 구조적 관계(예: 매개효과 메타분석)를 검증하는 MASEM(Meta-Analytic SEM)으로 나아갈 수 있는 발판이 됩니다.
WaurimaL의 제언:
여러분, 이제 단순한 평균 계산을 넘어 데이터의 구조를 파악하십시오. jamovi와 R의 metaSEM 패키지는 여러분의 연구를 한 단계 더 높은 수준(Top-tier Journal)으로 끌어올려 줄 강력한 무기입니다.
참고문헌
- Borenstein, M., Hedges, L. V., Higgins, J. P. T., & Rothstein, H. R. (2009). Introduction to meta-analysis. Wiley.
- Cheung, M. W.-L. (2008). A model for integrating fixed-, random-, and mixed-effects meta-analyses into structural equation modeling. Psychological Methods, 13(3), 182–202.
- Cheung, M. W.-L. (2013). Multivariate meta-analysis as structural equation models. Structural Equation Modeling: A Multidisciplinary Journal, 20(3), 429–454.
- Cheung, M. W.-L. (2014). Modeling dependent effect sizes with three-level meta-analyses: A structural equation modeling approach. Psychological Methods, 19(2), 211–229.
- Cheung, M. W.-L. (2015). Meta-analysis: A structural equation modeling approach. Wiley.
- Cheung, M. W.-L. (2015). metaSEM: An R package for meta-analysis using structural equation modeling. Frontiers in Psychology, 5, 1521.
- Cheung, M. W.-L. (2026). Structural Equation Modeling-Based Meta-Analysis. In Handbook of Structural Equation Modeling (Chapter 36).