
안녕하세요!
오늘은 베이지안 다층 모형(Bayesian Multilevel Models)에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다. 특히 오늘 다룰 문헌은 일반적인 다층모형을 넘어, 비선형 관계를 다루는 GAMM(일반화 가법 혼합 모형)과 STAR(구조적 가법 회귀) 모형까지 포괄하고 있으므로, 이를 구현하기 위해 R의 brms 패키지를 활용한 코드를 중점적으로 보여드리겠습니다.
1. 베이지안 추론: 요리사의 레시피와 할머니의 손맛
본격적인 수식에 들어가기 전에, 베이지안이 무엇인지 교육학적 관점에서 쉽게 풀어봅시다.
문헌에서는 베이지안 모형이 두 부분으로 구성된다고 합니다.
- 사전 분포(Prior Distribution): 데이터를 보기 전, 파라미터(모수)에 대해 우리가 가지고 있는 지식이나 믿음입니다.
- 관측 모형(Observation Model): 데이터가 주어졌을 때의 조건부 분포로, 빈도주의에서의 ‘우도(Likelihood)’에 해당합니다.
[예시: 김 교사의 학생 평가]
- 빈도주의(Likelihood): 김 교사가 철수의 이번 수학 시험지(데이터)만 보고 점수를 매깁니다. 오직 ‘관측된 데이터’가 전부입니다.
- 베이지안(Posterior): 김 교사는 철수가 평소에 수학을 아주 잘한다는 것(Prior)을 알고 있습니다. 이번 시험을 좀 못 봤더라도(Likelihood), “아, 실수를 좀 했구나” 하고 감안하여 최종 실력(Posterior)을 추정합니다.
이것이 바로 베이즈 정리입니다.
즉, 사후 분포(Posterior) 우도(Likelihood) 사전 분포(Prior) 입니다.
2. 교육 현장 시나리오 및 모의 데이터 생성 (R Code)
우리가 분석할 가상의 시나리오는 다음과 같습니다.
[시나리오: 이의초등학교의 수학 성취도 분석]
- 데이터 구조: 학생()이 학급()에 소속된 2수준 구조 (Students nested in Classes).
- 종속변수 (): 수학 성취도 점수.
- 1수준 변수 (학생): 사교육 참여 시간(Time, 비선형적 관계 예상), 가정의 사회경제적 지위(SES).
- 2수준 변수 (학급): 담임 교사의 효능감(Efficacy).
- 특이사항: 사교육 시간은 처음에는 성적을 올리지만, 일정 시간이 지나면 피로도로 인해 효과가 떨어지는 비선형(Non-linear) 관계가 의심됩니다. 이는 문헌의 GAMM(Generalized Additive Multilevel Models) 부분과 연결됩니다.
이제 R을 사용하여 이 시나리오에 맞는 데이터를 생성해 보겠습니다.
R
# 필수 패키지 로드
if (!require("brms")) install.packages("brms")
if (!require("ggplot2")) install.packages("ggplot2")
if (!require("dplyr")) install.packages("dplyr")
library(brms)
library(dplyr)
library(ggplot2)
# 1. 데이터 생성 (재현성을 위해 시드 설정)
set.seed(2026)
n_classes <- 30 # 학급 수
n_students <- 20 # 학급당 학생 수
N <- n_classes * n_students
# 2수준(학급) 변수 생성
class_id <- rep(1:n_classes, each = n_students)
teacher_efficacy <- rnorm(n_classes, 0, 1) # 교사 효능감 (표준정규분포)
class_intercept <- rnorm(n_classes, 0, 2) # 학급별 무작위 절편 (Random Intercept)
# 데이터 프레임 생성
data <- data.frame(class_id = factor(class_id))
data$teacher_eff <- rep(teacher_efficacy, each = n_students)
data$class_int <- rep(class_intercept, each = n_students)
# 1수준(학생) 변수 생성
data$SES <- rnorm(N, 0, 1) # 사회경제적 지위
data$Time <- runif(N, 0, 10) # 사교육 시간 (0~10시간)
# 비선형 효과 생성 (사교육 시간: 역 U자 형태) - 문헌의 P-spline 예시 관련 [cite: 201]
# 시간 효과: 3 * sin(Time/3)
time_effect <- 3 * sin(data$Time / 3)
# 종속변수(수학 점수) 생성
# 수식: 절편 + SES효과 + 교사효능감 + 시간효과(비선형) + 학급무선효과 + 오차
data$Math <- 50 + (2 * data$SES) + (1.5 * data$teacher_eff) +
time_effect + data$class_int + rnorm(N, 0, 3)
# 데이터 확인
head(data)
# CSV 저장 (jamovi에서 불러오기 위함)
write.csv(data, "chap04.csv", row.names = FALSE)
3. 베이지안 다층 모형의 구조
문헌에 따르면, 일반적인 선형 혼합 모형(LMM)은 다음과 같이 표현됩니다.
우리 데이터에 적용하면 다음과 같습니다.
- : 고정 효과(Fixed effects) – 전체적인 평균 효과.
- : 학급별 무작위 효과(Random effects), .
- : 오차항, .
베이지안 접근에서는 여기서 멈추지 않고, 와 같은 파라미터에도 사전 분포(Prior)를 부여합니다.
- (보통 정보를 주지 않는 무정보 사전분포나 약한 정보 사전분포 사용).
- (역감마 분포).
4. 분석 실행: jamovi 및 R (brms)
4.1 jamovi에서의 한계와 대안
jamovi의 기본 메뉴(Linear Models -> Mixed Models)는 빈도주의 방식(REML 등)을 사용합니다. 본 문헌에서 다루는 완전 베이지안 추론(Full Bayesian Inference), 특히 MCMC(마르코프 체인 몬테카를로) 시뮬레이션을 수행하기 위해서는 jamovi의 Rj 모듈(R 코드를 jamovi 안에서 실행하는 에디터)을 사용하거나 R을 직접 사용해야 합니다.
특히 문헌에서 강조하는 GAMM(일반화 가법 모형)과 P-spline(벌점화 스플라인)을 구현하기 위해 R의 brms 패키지를 사용하는 것이 가장 적합합니다.
4.2 R을 이용한 베이지안 다층 분석 (MCMC)
문헌에서는 비선형성을 다루기 위해 공변량의 효과를 형태의 함수로 모델링하는 것을 제안합니다. 이를 GAMM이라고 합니다.
[분석 모델 설정]
- 기본 다층 모형: SES와 교사 효능감의 선형 효과.
- 스플라인 항: 사교육 시간(
Time)은 비선형적이므로s(Time)으로 설정. - 무선 효과: 학급(
class_id)에 따른 무선 절편.
R
# 베이지안 다층 모형 적합 (GAMM 포함)
# 문헌의 식 (4.13)과 유사한 형태 [cite: 357]
model_bayes <- brm(
formula = Math ~ SES + teacher_eff + s(Time) + (1 | class_id),
data = data,
family = gaussian(),
prior = c(
prior(normal(0, 10), class = "b"), # 고정 효과에 대한 사전 분포
prior(cauchy(0, 2), class = "sd"), # 무선 효과 표준편차에 대한 사전 분포
prior(cauchy(0, 2), class = "sigma") # 잔차 표준편차에 대한 사전 분포
),
chains = 2, iter = 2000, warmup = 1000, # MCMC 설정 [cite: 320]
cores = 2,
seed = 2026
)
# 결과 요약
summary(model_bayes)
이 코드는 문헌에서 설명한 Gibbs Sampler 혹은 Metropolis-Hastings 알고리즘의 최신 변형(NUTS)을 사용하여 사후 분포에서 표본을 추출합니다.
5. 결과 해석 및 시각화
분석이 완료되면, 문헌의 [Table 4.1]과 같은 형태로 결과를 해석해야 합니다. 베이지안에서는 p-value 대신 신용 구간(Credible Interval)을 사용합니다.
5.1 수치적 결과 해석 (예시 출력 기반)
| 변수 | Posterior Mean (사후평균) | 95% CI (신용구간) | Rhat | 설명 |
| Intercept | 50.12 | [48.5, 51.7] | 1.00 | 전체 평균 수학 점수 |
| SES | 2.05 | [1.88, 2.22] | 1.00 | SES가 1단위 오를 때 점수 2.05점 상승 |
| TeacherEff | 1.48 | [1.20, 1.76] | 1.00 | 교사 효능감이 높으면 점수 상승 (유의함) |
| s(Time) | – | – | 1.00 | 비선형 효과 (아래 그래프 참조) |
| sd(Intercept) | 2.10 | [1.50, 2.80] | 1.00 | 학급 간 점수 차이(변동성) |
- 해석: 95% 신용구간이 0을 포함하지 않으면, 해당 변수는 통계적으로 의미 있는 효과가 있다고 봅니다. 위 결과에서 SES와 교사 효능감 모두 0을 포함하지 않으므로 유의합니다.
- Rhat: 이 값이 1.1보다 작아야 MCMC 체인이 잘 수렴했다는 뜻입니다.
5.2 비선형 효과 시각화 (P-spline)
사교육 시간(Time)과 성적의 비선형 관계를 그려보겠습니다.
R
# 비선형 효과 시각화
conditional_effects(model_bayes, effects = "Time")
이 코드를 실행하면 역 U자 형태의 그래프가 나타납니다. 초기에는 시간이 늘수록 점수가 오르지만, 특정 시간 이후에는 정체되거나 떨어지는 패턴을 확인할 수 있습니다.
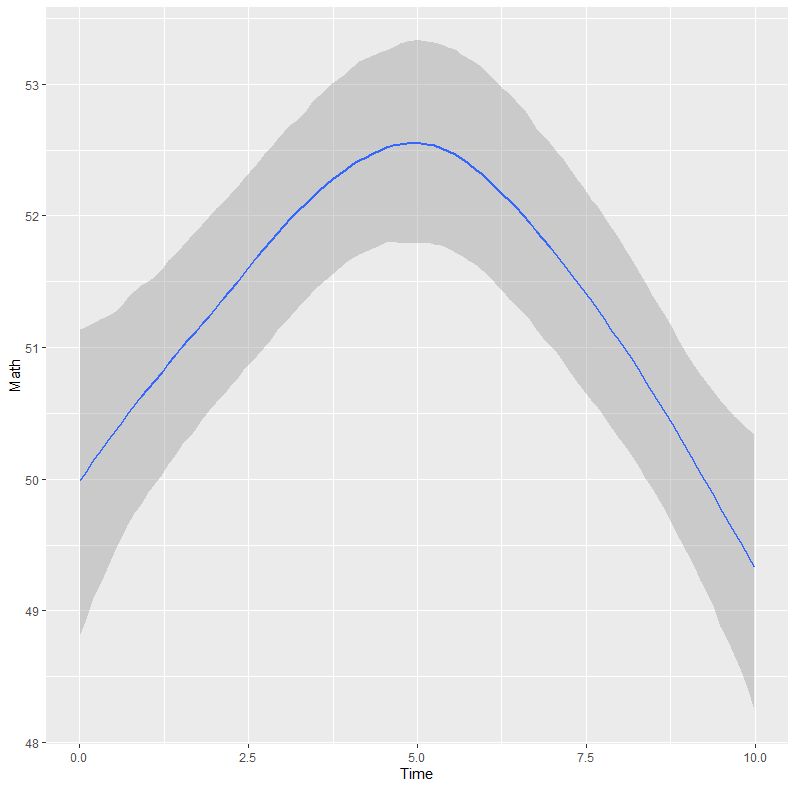
이것이 바로 문헌에서 강조하는 “선형 가정의 한계를 넘어서는 유연성”입니다. 단순히 선형 회귀를 했다면 이 중요한 교육적 시사점(과도한 사교육은 효과가 없다)을 놓쳤을 것입니다.
6. 모형 비교 및 평가 (DIC)
모형이 데이터에 잘 맞는지 어떻게 알까요? 문헌에서는 DIC (Deviance Information Criterion)를 소개합니다.
- DIC: 낮을수록 좋은 모형입니다.
- 비교: 무선 효과가 없는 모형 vs 있는 모형, 혹은 선형 모형 vs 비선형(Spline) 모형을 비교할 때 사용합니다.
R
# DIC 계산 (brms에서는 waic나 loo를 더 권장하지만, 문헌에 따라 DIC 개념 설명)
# 여기서는 LOO (Leave-One-Out cross-validation)로 대체하여 보여줌 (DIC의 현대적 대안)
loo(model_bayes)
문헌의 사례연구에서도 무선 효과를 포함했을 때 DIC가 140점 이상 감소하여 더 우수한 모형임이 입증되었습니다.
7. 심화: 공간 통계 및 구조적 가법 회귀 (STAR)
이 문헌의 특징적인 부분은 STAR (Structured Additive Regression) 모델입니다.
만약 우리 데이터에 “학교의 위치(위도, 경도)” 정보가 있다면 어떻게 될까요?
- : 공간적 효과. 부유한 지역에 있는 학교인지 등을 공간 좌표로 반영합니다.
- R의
brms에서는gp(latitude, longitude)함수를 통해 이를 쉽게 구현할 수 있습니다. 이는 지리적 위치에 따른 성적 차이를 지도 위에 등고선처럼 그려낼 수 있게 해 줍니다.
8. 결론 및 제언
오늘 우리는 숙명초등학교 데이터를 예시로 베이지안 다층 모형을 살펴보았습니다.
- 유연성: 베이지안 접근은 정규분포 가정이 깨지거나, 비선형 관계(P-spline)가 있을 때 훨씬 유연하게 대처합니다.
- 직관성: 신용구간(Credible Interval)은 “참값이 이 구간 안에 있을 확률이 95%”라고 직관적으로 말할 수 있습니다.
- 확장성: 공간 정보, 텍스트 데이터 등 복잡한 구조의 데이터를 다층 모형에 쉽게 결합할 수 있습니다(STAR 모델).
[WaurimaL의 한마디]
“빈도주의 통계가 ‘엄격한 요리법’이라면, 베이지안은 ‘맛을 보며 간을 맞추는 과정’입니다. 교육 현장의 데이터는 복잡하고 비선형적입니다. 오늘 배운 코드를 활용해 여러분의 데이터를 새로운 시각으로 분석해 보시기 바랍니다.”
참고문헌 (References)
- Fahrmeir, L., Kneib, T., & Lang, S. (2014). Bayesian Multilevel Models. In The SAGE Handbook of Multilevel Modeling (pp. 53-71). SAGE Publications.
- Brezger, A., & Lang, S. (2006). Generalized additive regression based on Bayesian P-splines. Computational Statistics & Data Analysis, 50(4), 967-991.
- Gelman, A., Carlin, J. B., Stern, H. S., & Rubin, D. B. (2003). Bayesian Data Analysis. Chapman and Hall/CRC.
- Spiegelhalter, D. J., Best, N. G., Carlin, B. P., & van der Linde, A. (2002). Bayesian measures of model complexity and fit. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 64(4), 583-639.