안녕하세요! 이번에는 구조방정식 모형(SEM)의 가장 흥미롭고 도전적인 영역인 “비선형 구조방정식 모형(Nonlinear Structural Equation Models; NSEMs)을 탐구해 보겠습니다.
많은 연구자나 학생들이 “변수 간의 관계는 직선(선형)이다”라는 가정하에 분석을 수행합니다. 하지만, 교육 현장의 실제 데이터는 어떤가요? 학습 시간이 늘어난다고 성적이 무한정 오르나요? (지치면 떨어지겠죠?) 흥미가 성취도에 미치는 영향이 모든 학생에게 똑같을까요? (효능감에 따라 다르겠죠?)
오늘은 현실을 더 정교하게 반영하는 비선형 모형들을 jamovi와 R을 활용해 배워보겠습니다.
1. 왜 비선형인가?
전통적인 SEM은 변수 간의 관계를 선형(linear)으로 가정합니다. 하지만 인간의 행동, 능력, 태도는 단순히 직선으로 설명하기 어려운 경우가 많습니다.
포화 효과(Saturation): 초기에는 투입 효과가 크지만 갈수록 줄어드는 경우.
임계점(Threshold): 특정 수준을 넘어서야 효과가 나타나는 경우.
상호작용(Interaction): 한 변수의 효과가 다른 변수의 수준에 따라 달라지는 경우.
Harring과 Zou(저자)는 이러한 복잡한 관계를 다루기 위해 일반 비선형 다층 구조방정식 혼합 모형(GNM-SEMM)이라는 통합된 프레임워크를 제시합니다. 이름이 길고 어렵죠? 쉽게 말해 “비선형(곡선) + 다층(학교-학생) + 혼합(잠재집단)”을 모두 고려할 수 있는 만능 틀이라고 생각하면 됩니다.
2. 모의 데이터 생성: “학습 시간과 학업 성취도”
이론만 보면 지루하니, 가상의 교육 상황을 만들어 봅시다.
[시나리오: 벼락치기의 효율성]
상황: 한 고등학교에서 학생들의 ‘집중 학습 시간(Study)’과 ‘최종 시험 점수(Score)’의 관계를 연구합니다.
가설: 학습 시간이 늘어나면 점수는 오르지만, 일정 시간이 지나면 피로 누적으로 인해 점수 상승폭이 둔화되거나 오히려 떨어질 것이다(역 U자형, 즉 이차함수 관계).
이 시나리오를 바탕으로 분석을 진행하겠습니다. jamovi는 기본적으로 클릭 기반이지만, 비선형 SEM과 같은 고급 분석은 R 코드를 활용해야 정확합니다. jamovi의 Rj 모듈이나 RStudio를 사용할 수 있도록 코드를 제공합니다.
R
# R 코드: 모의 데이터 생성
set.seed(1234)
N <- 500
# 잠재변수 생성 (Study: 학습몰입, Score: 성취도)
# Study는 평균 0, 분산 1인 정규분포
Study_Latent <- rnorm(N, 0, 1)
# 구조 모형: 비선형 관계 (이차함수)
# Score = 50 + 10*Study - 3*Study^2 + Error
# 학습량이 너무 많으면 성취도가 떨어지는 역 U자형
Score_Latent <- 0.5 * Study_Latent - 0.3 * (Study_Latent^2) + rnorm(N, 0, 0.5)
# 측정 변수 생성 (Factor Loading을 고려한 관측변수)
# Study 지표 (x1, x2, x3)
x1 <- 1.0 * Study_Latent + rnorm(N, 0, 0.4)
x2 <- 0.9 * Study_Latent + rnorm(N, 0, 0.4)
x3 <- 1.1 * Study_Latent + rnorm(N, 0, 0.4)
# Score 지표 (y1, y2, y3)
y1 <- 1.0 * Score_Latent + rnorm(N, 0, 0.4)
y2 <- 0.8 * Score_Latent + rnorm(N, 0, 0.4)
y3 <- 1.2 * Score_Latent + rnorm(N, 0, 0.4)
Data <- data.frame(x1, x2, x3, y1, y2, y3)
head(Data)
파라메트릭 접근은 연구자가 “이 데이터는 이런 함수 모양일 거야”라고 미리 모양(함수)을 정해놓고 분석하는 방법입니다. 교재에서는 세 가지 주요 함수를 소개합니다.
A. 이차 함수 (Quadratic Function)
가장 널리 쓰이는 비선형 모형입니다. 우리의 시나리오처럼 “적당할 때가 제일 좋다(역 U자)” 혹은 “갈수록 가속도가 붙는다(U자)”를 설명합니다.
수식:
여기서 항이 유의하면 비선형 관계가 입증됩니다.
B. Jenss-Bayley 함수
발달 심리학에서 주로 사용되는데, 급격히 성장하다가 점차 완만해지며 특정 수준에 수렴하는 형태를 설명합니다.
특징: 지수 함수와 선형 함수가 결합된 형태입니다.
수식:7.
C. 구분적 함수 (Piecewise Function)
데이터의 구간을 나누어 서로 다른 관계를 가정합니다.
예: 학습 시간이 5시간 미만일 때는 가파른 상승, 5시간 이상일 때는 완만한 상승.
특징: 두 구간이 만나는 지점(knot)을 찾는 것이 중요합니다.
[분석 예시] R/jamovi(lavaan)를 이용한 이차 함수 분석
이차 함수나 상호작용은 lavaan 패키지의 indProd 등을 통해 구현할 수 있습니다.
R
# R 코드: 이차항(Quadratic) 포함 SEM 분석
library(lavaan)
# 1. 측정 모형 정의
model <- '
# 잠재변수 정의
Study =~ x1 + x2 + x3
Score =~ y1 + y2 + y3
# 상호작용(이차항)을 위한 정의 (LMS 방식 등은 Mplus가 강점이지만, 여기서는 관측변수 곱 활용 접근 예시)
# 실제로는 indProd 등을 써서 교차항을 만듭니다.
# 여기서는 개념적 이해를 위해 단순화한 구조방정식 구문을 씁니다.
Score ~ Study
'
# *참고: R의 lavaan에서는 기본적으로 비선형 잠재변수(Study^2)를 직접 지원하지 않아
# 관측변수를 제곱하여 Product Indicator를 만드는 방식을 주로 씁니다.
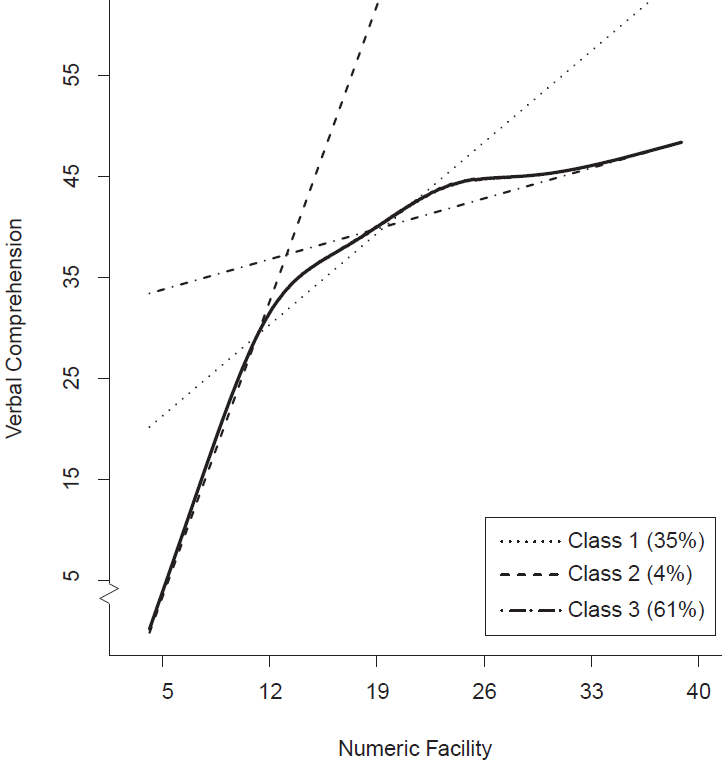
WaurimaL의 팁: 교재의 예제인 시애틀 종단 연구(SLS)에서는 ‘언어 이해력(VC)’을 ‘수리 능력(NF)’으로 예측할 때, 이차 함수 모형과 Jenss-Bayley 모형을 비교했습니다. 결과적으로 Jenss-Bayley 모형이 더 적합한 것으로 나타났는데, 이는 수리 능력이 높을수록 언어 이해력도 높아지지만 어느 순간부터는 그 증가폭이 줄어든다는 것을 의미합니다.
4. 준파라메트릭 SEMM (Semiparametric SEMM)
연구자가 “도대체 무슨 모양인지 감이 안 잡힐 때” 사용하는 방법입니다.
특정한 곡선 식을 가정하는 대신, 여러 개의 직선(선형 모형)을 섞어서(Mixture) 곡선을 근사하는 방식입니다.
원리: 마치 곡선을 아주 짧은 직선들의 집합으로 그리는 것과 같습니다. 잠재 계층(Latent Class)을 나누고, 각 계층마다 서로 다른 선형 회귀식을 적용합니다.
장점: 데이터가 정규분포를 따르지 않아도(비정규성) 잘 작동합니다.
해석: 각 계층(Class)을 합쳐서(가중 평균) 전체적인 비선형 관계를 추정합니다.
[그림 설명]
위 그림을 보면, 3개의 잠재 계층(점선들)이 각기 다른 기울기를 가지고 있습니다. 이들을 합치니 전체적으로 부드러운 곡선(실선)이 만들어집니다.
5. 다층 및 상호작용 NSEM (Multilevel & Interaction)
교육 데이터는 학생이 학교에 소속된 위계적(Nested) 구조를 가집니다. 이를 무시하면 오류가 발생합니다. 교재의 TIMSS 2011 데이터 분석 예시를 통해 알아봅시다.
분석 시나리오: 수학 성취도 예측
수준 1 (학생): 수학 효능감(Self-Efficacy), 수학 흥미(Interest)
수준 2 (학교): 학교 평균 효능감, 학교 평균 흥미
종속변수: 수학 성취도(Math Achievement)
주요 발견 (TIMSS 데이터 분석 결과)
학생 수준 상호작용: 흥미가 높고 효능감도 높을 때, 성취도가 기하급수적으로 상승하는 상승 작용(Synergy)이 있었습니다 ().
학교 수준 효과: 학교 전체의 평균 효능감이 높을수록 학생 개인의 성취도도 높아지는 맥락 효과(Contextual Effect)가 발견되었습니다.
크로스 레벨 상호작용: 학교 수준의 변수가 학생 수준의 관계를 조절할 수 있습니다.
[R 코드] 잠재 상호작용 모형 예시
R
# R 코드: 잠재 상호작용 (Latent Interaction)
# lavaan의 최신 기능이나 semTools를 활용하면 LMS(Latent Moderated Structural Equations)와 유사한 분석 가능
# 여기서는 개념적 코드만 제시합니다.
model_interaction <- '
# 측정 모형
Interest =~ int1 + int2
Efficacy =~ eff1 + eff2 + eff3
Math =~ ach1 + ach2
# 구조 모형 (상호작용 포함)
# colon(:)을 사용하여 잠재변수 간 상호작용 표현 (일부 패키지 지원)
Math ~ Interest + Efficacy + Interest:Efficacy
'
# *실제 분석 시에는 product indicator 접근법이나 베이지안 접근(blavaan)을 추천합니다.
6. 결론 및 제언
오늘 우리는 현실 세계의 복잡성을 담아내기 위한 비선형 구조방정식의 여정을 떠나보았습니다.
현실은 직선이 아닙니다: 인간의 발달, 학습, 심리는 곡선이거나, 계단식이거나, 복합적인 상호작용을 합니다.
도구의 확장: 이차 함수, 구분적 함수, 혹은 혼합 모형(Mixture Model)을 통해 이러한 관계를 통계적으로 모형화할 수 있습니다.
교육적 시사점: 단순히 “공부 많이 하면 성적 오른다”가 아니라, “어느 수준까지는 오르지만 그 이후는 흥미가 뒷받침되어야 한다”와 같은 정교한 교육적 처방이 가능해집니다.
WaurimaL의 마지막 한마디 (Next Step)
“여러분, 오늘 내용이 조금 어려웠을 수 있습니다. 특히 수식이 많아서 겁먹었을 수도 있어요. 하지만 핵심은 ‘데이터의 실제 모양을 존중하자’는 것입니다. 다음 단계로, 여러분이 가지고 있는 데이터를 산점도(Scatter plot)로 먼저 그려보세요. 혹시 직선이 아닌 곡선이 보이나요? 그렇다면 오늘 배운 비선형 SEM을 적용해 볼 절호의 기회입니다.”
참고문헌
Bates, D. M., & Watts, D. G. (1988). Nonlinear regression analysis: Its applications. New York: Wiley.
Bauer, D. J. (2005). A semiparametric approach to modeling nonlinear relations among latent variables. Structural Equation Modeling, 12, 513–535.
Harring, J. R., & Zou, J. (n.d.). Chapter 37. Nonlinear Structural Equation Models. In Advanced Methods and Applications.
Jenss, R., & Bayley, N. (1937). A mathematical method for studying the growth of a child. Human Biology, 9, 556–563.
Kelava, A., & Brandt, H. (2014). A general nonlinear multilevel structural equation mixture model. Frontiers in Psychology, 5, 1–16.
Mullis, I. V., et al. (2012). TIMSS 2011 encyclopedia: Education policy and curriculum in mathematics and science. Boston: TIMSS & PIRLS International Study Center.
Wall, M. M. (2009). Maximum likelihood and Bayesian estimation of nonlinear structural equation models. In R. Millsap (Ed.), The SAGE handbook of quantitative methods in psychology (pp. 540–567). Sage.