
오늘은 SEM 분석의 여정에서 ‘지도’와 ‘나침반’ 역할을 하는 시각화(Visualizations)에 대해 깊이 있게 다뤄보겠습니다.
구조방정식은 수많은 변수 간의 복잡한 관계를 다루기 때문에, 단순히 수치만 봐서는 길을 잃기 십상입니다. 텍스트에 기반한 설명뿐만 아니라, 실제 교육 현장의 데이터를 가정한 시뮬레이션을 통해 이해를 돕겠습니다.
오늘 다룰 핵심 내용은 1) 모델 명세(설계도 그리기), 2) 데이터 탐색(재료 확인하기), 3) 결과 제시(스토리텔링)입니다.
1. 서론: 왜 시각화인가?
시각화는 단순히 결과를 예쁘게 포장하는 것이 아닙니다. 변수 간의 복잡한 관계를 접근하기 쉽고 간결하게 전달하는 데 필수적입니다. 통계 그래픽은 다변량 데이터를 탐색하고, 모델링 진단을 수행하며, 결과를 제시하는 중요한 역할을 합니다. 특히 SEM은 복잡한 방향성(화살표) 및 비방향성(상관) 관계의 네트워크를 표현하므로, 연구자들은 그래픽에 의존하여 모델을 명시하고 분석하고 결과를 제시합니다.
2. 모델 명세 (Model Specification): 설계도 그리기
모델 명세는 여러분의 가설을 수학적 방정식이나 경로도(Path Diagram)로 공식화하는 과정입니다. LISREL 행렬 표기법과 경로도는 서로 동형(isomorphism), 즉 완전히 일치하는 관계입니다.
2.1 기본 기호와 약속 (Syntax)
교육학 연구에서 흔히 보는 도형들의 의미를 명확히 합시다.
- 직사각형 (): 관측변수(Manifest Variable, MV). 실제 설문지 문항 점수나 시험 점수입니다. (예: 국어 성적, ‘수업에 만족한다’는 응답).
- 원/타원 (): 잠재변수(Latent Variable, LV). 직접 측정할 수 없으나 관측변수를 통해 추정되는 개념입니다. (예: 학업적 자기효능감, 교사 애착). 오차항(Error term)도 잠재변수의 일종이므로 원으로 표시합니다.
- 화살표 (): 방향성 관계(Directional relationship). 회귀계수와 같습니다. “A가 B에 영향을 미친다”는 뜻입니다.
- 양방향 화살표 (): 비방향성 관계(Nondirectional relationship). 공분산이나 상관관계를 의미합니다.
2.2 식별(Identification): 척도 설정하기
이 부분이 학생들이 가장 어려워하는 부분입니다. 잠재변수는 가상의 개념이라 척도(단위)가 없습니다. 따라서 우리가 단위를 강제로 부여해야(Scale setting) 추정이 가능해집니다.
방법 1: 단위 적재치 고정 (Marker Variable)
- 가장 흔한 방법입니다. 잠재변수에서 나가는 화살표 중 하나를 ‘1.0’으로 고정합니다.
- 교육 예시: ‘학업 스트레스’라는 잠재변수가 있을 때, ‘나는 시험 때 긴장한다’라는 1번 문항의 경로를 1로 고정하면, 잠재변수는 이 문항의 5점 척도 단위를 따라갑니다.
방법 2: 잠재변수 분산 고정 (Standardization)
- 잠재변수의 분산을 ‘1.0’으로 고정합니다.
- 이 경우 잠재변수는 표준점수(Z-score)와 같아지며, 해석 시 “잠재변수가 1 표준편차 증가할 때…”라고 해석합니다.
2.3 교육학 예제 모델: “자기조절학습이 학업성취에 미치는 영향”
다음과 같은 가상의 연구 모델을 상상해 봅시다.
- 외생변수(원인): 부모의 지원 (Parental Support)
- 내생변수(매개/결과): 자기조절학습 (Self-Regulated Learning), 학업성취 (Achievement)
- 가설: 부모의 지원은 자기조절학습을 높이고, 이는 다시 학업성취를 높일 것이다.
3. 데이터 탐색 (Modeling the Data): 재료 맛보기
모델을 돌리기 전에 데이터를 시각적으로, 수치적으로 탐색하는 ‘탐정 놀이(Sleuthing)’가 필수입니다. SEM은 다변량 분석이므로, 개별 변수의 분포뿐만 아니라 변수 간의 관계(행렬 플롯)를 함께 봐야 합니다.
3.1 시뮬레이션 데이터 생성 (Storytelling)
여러분의 이해를 돕기 위해 가상의 고등학교 1학년 학생 200명의 데이터를 생성해 보겠습니다.
[시나리오: S고등학교의 디지털 리터러시 연구]
S고등학교 교사들은 학생들의 ‘디지털 리터러시(DL)’가 ‘온라인 학습 몰입(Eng)’을 통해 ‘학업 만족도(Sat)’에 어떤 영향을 주는지 알고 싶습니다.
- 측정 도구: 각 요인당 3문항 (5점 리커트 척도).
- 특이사항: DL의 3번 문항은 역채점 문항일 가능성이 있어 분포 확인이 필요함.
이 데이터를 분석하기 전, 행렬 플롯(Matrix Plot)을 통해 다음을 확인해야 합니다.
- 정규성: 리커트 척도라 완벽한 정규분포는 아니지만, 심하게 찌그러져(Skewed) 있는지 확인.
- 상관관계: 같은 잠재변수로 묶인 문항들끼리 상관이 높은지().
- 특이점: 산점도에서 튀는 값이나 비선형 패턴이 있는지.
3.2 jamovi & R을 활용한 시각화 구현
jamovi는 GUI 기반이라 편리하지만, 교재의 [Figure 4.3]과 같은 정교한 행렬 플롯을 그리려면 jamovi 내의 Rj 모듈(R 코드 실행기)을 쓰거나 R을 써야 합니다. 여기서는 psych 패키지를 활용한 코드를 소개합니다.
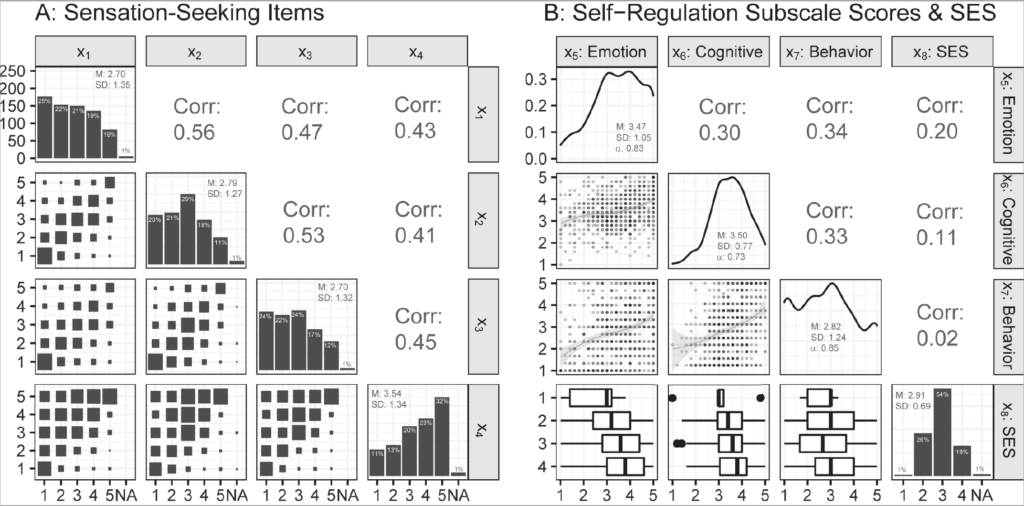
Note. From Handbook of structural equation modeling (p. 87), by R. H. Hoyle (Ed.), 2023, Guilford Press. Copyright 2023 by Guilford Press.
R
# R 코드 (jamovi Rj 에디터에 붙여넣기 가능)
# 가상 데이터 생성 및 시각화
set.seed(123)
library(psych)
library(MASS)
# 1. 데이터 생성 (N=200)
# 잠재변수 간 상관행렬 정의 (DL -> Eng -> Sat)
Sigma <- matrix(c(1.0, 0.5, 0.4,
0.5, 1.0, 0.6,
0.4, 0.6, 1.0), 3, 3)
latents <- mvrnorm(n = 200, mu = c(0,0,0), Sigma = Sigma)
# 관측변수 생성 (각 잠재변수당 3문항, 요인부하량 0.7~0.8 가정 + 오차)
create_item <- function(latent, loading) {
item <- loading * latent + sqrt(1 - loading^2) * rnorm(200)
item <- round(item * 1 + 3) # 5점 척도로 변환 (평균 3)
item <- pmax(1, pmin(5, item)) # 1~5점 범위 제한
return(item)
}
Data <- data.frame(
DL1 = create_item(latents[,1], 0.8),
DL2 = create_item(latents[,1], 0.75),
DL3 = create_item(latents[,1], 0.7),
Eng1 = create_item(latents[,2], 0.8),
Eng2 = create_item(latents[,2], 0.85),
Eng3 = create_item(latents[,2], 0.75),
Sat1 = create_item(latents[,3], 0.8),
Sat2 = create_item(latents[,3], 0.8),
Sat3 = create_item(latents[,3], 0.7)
)
# 2. 행렬 플롯 (Exploratory Graphic)
# 교재 [Figure 4.3]과 유사한 형태: 대각선(히스토그램), 하단(산점도), 상단(상관)
pairs.panels(Data,
method = "pearson", # 상관계수
hist.col = "#00AFBB",
density = TRUE, # 밀도 곡선
ellipses = TRUE, # 상관 타원
lm = TRUE, # 선형 회귀선
main = "디지털 리터러시, 몰입, 만족도 문항 간 행렬 플롯")
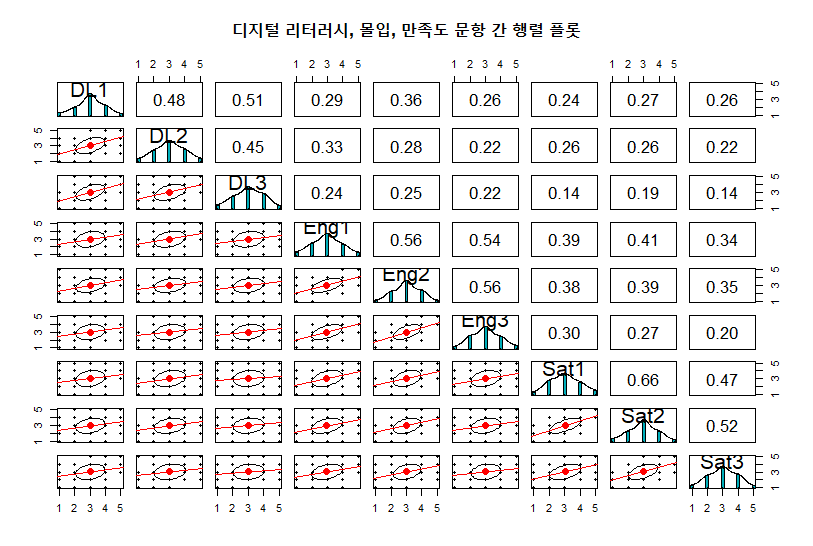
[분석 포인트]
- 위 코드를 실행하여 나온 그래프를 볼 때,
DL1,DL2,DL3끼리의 상관이 높다면(타원이 좁고 길쭉함), 이들이 하나의 요인(디지털 리터러시)으로 묶일 수 있음을 시사합니다. - 대각선의 히스토그램을 보고 한쪽으로 쏠림(천장/바닥 효과)이 없는지 확인합니다.
4. 결과 제시 (Presentation of Results): 효과적인 전달
분석이 끝나면 결과를 논문이나 발표 자료에 실어야 합니다. 이때 경로도, 표, 점 도표(Dot Plot) 세 가지 방법이 있습니다.
4.1 경로도 (Path Diagrams)
- 장점: 모델의 구조와 주요 수치를 한눈에 직관적으로 보여줍니다.
- 단점: 모델이 복잡해지면 정보 과부하가 걸립니다. 효과 크기나 신뢰구간(CI)까지 다 적으면 너무 지저분해집니다.
- 팁: 작은 모델에 추천합니다. jamovi의
SEMLj모듈은 분석 후 자동으로 경로도를 그려줍니다.
4.2 표 (Tables)
- 장점: 많은 정보(추정치, 표준오차, p값, 신뢰구간)를 콤팩트하게 담을 수 있습니다.
- 단점: 수치들의 상대적 크기를 한눈에 비교하기 어렵습니다.
- 팁: APA 스타일로 정리할 때 필수적입니다.
4.3 점 도표 (Dot Plots): 강력 추천
가장 강조하는 방식입니다.
- 개념: 추정치(Estimate)를 점으로 찍고, 95% 신뢰구간(CI)을 양옆의 콧수염(Whisker)으로 표현합니다.
- 장점:
- 비교 용이성: 어떤 경로 계수가 가장 큰지 시각적으로 즉시 비교 가능합니다.
- 유의성 판단: 신뢰구간이 0을 포함하는지(수염이 0 세로선을 건드리는지)를 보고 통계적 유의성을 직관적으로 판단합니다.
- 정렬(Ordering): 크기순으로 정렬하면 메시지가 더 명확해집니다.
[R을 이용한 점 도표 예시 생성]
여러분이 논문에 쓸 때 참고할 수 있도록, 위 시나리오 데이터의 분석 결과를 가정한 점 도표를 그려보겠습니다.
R
# 필요한 패키지 로드 (없으면 install.packages("ggplot2") 실행)
if (!require(ggplot2)) install.packages("ggplot2")
library(ggplot2)
# 1. SEM 분석 결과 데이터 생성 (가상 데이터)
# 실제 분석에서는 parameterEstimates(fit) 등의 함수로 추출한 값을 사용합니다.
sem_results <- data.frame(
Type = c(rep("구조 경로 (Structural)", 3), rep("측정 요인부하량 (Measurement)", 3)),
Parameter = c("디지털 리터러시 -> 몰입",
"몰입 -> 학업 만족도",
"디지털 리터러시 -> 학업 만족도",
"DL1 (문항1)", "DL2 (문항2)", "DL3 (문항3)"),
Estimate = c(0.65, 0.55, 0.15, 0.80, 0.75, 0.70), # 표준화 계수
Lower_CI = c(0.50, 0.40, -0.05, 0.70, 0.65, 0.60), # 95% 신뢰구간 하한
Upper_CI = c(0.80, 0.70, 0.35, 0.90, 0.85, 0.80) # 95% 신뢰구간 상한
)
# 2. 요인 순서 정렬 (크기순 정렬이 시각적 인지에 유리함 [cite: 848])
# Estimate 크기에 따라 Parameter 순서를 재조정
sem_results$Parameter <- reorder(sem_results$Parameter, sem_results$Estimate)
# 3. 점 도표(Dot Plot) 그리기
ggplot(sem_results, aes(x = Estimate, y = Parameter, color = Type)) +
# (1) 0점 기준선: 유의성 판단의 기준 (수직 점선)
geom_vline(xintercept = 0, linetype = "dashed", color = "gray50") +
# (2) 오차 막대 (Error Bars): 95% 신뢰구간 표현
geom_errorbarh(aes(xmin = Lower_CI, xmax = Upper_CI),
height = 0.2, size = 0.8) +
# (3) 점 (Points): 추정치(계수) 표현
geom_point(size = 3.5) +
# (4) 디자인 테마 및 색상 설정
scale_color_manual(values = c("steelblue", "darkorange")) +
theme_classic(base_family = "sans") + # 깔끔한 논문 스타일
# (5) 라벨 및 범례 설정
labs(title = "구조방정식 모델링 분석 결과: 표준화 계수 및 95% 신뢰구간",
subtitle = "디지털 리터러시가 학업 만족도에 미치는 영향 (매개효과 검증)",
x = "표준화 계수 (Standardized Estimate)",
y = NULL, # Y축 라벨 제거 (변수명이 있으므로)
caption = "Note. 오차 막대는 95% 신뢰구간을 나타냄. 0을 포함하면 유의하지 않음.") +
theme(legend.position = "bottom", # 범례를 아래로
legend.title = element_blank(), # 범례 제목 제거
plot.title = element_text(face = "bold", size = 14),
axis.text.y = element_text(color = "black", size = 11))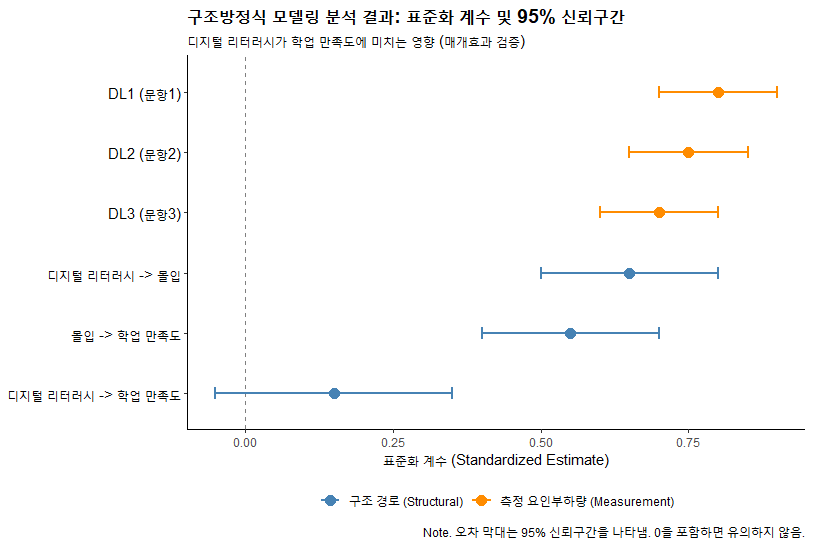
[해석 방법]
- DL -> Eng: 점이 0.65에 있고, 수염(CI)이 0을 지나지 않으므로 통계적으로 유의하고 효과가 큽니다.
- DL -> Sat (Direct): 점이 0.15에 있고, 수염이 0을 가로지릅니다. 즉, 디지털 리터러시가 만족도에 미치는 직접 효과는 유의하지 않다는 것을 바로 알 수 있습니다. 이것은 완전 매개(Full Mediation) 모형을 지지하는 증거가 됩니다.
5. 결론 및 제언
구조방정식 모델링에서 시각화는 선택이 아닌 필수입니다.
- 연구 설계 단계: 경로도를 그려보며 이론적 가설을 구체화하십시오.
- 분석 전 단계: 행렬 플롯(Matrix Plot)으로 데이터를 샅샅이 탐색(Sleuthing)하십시오.
- 결과 보고 단계: 복잡한 모델일수록 점 도표(Dot Plot)를 활용하여 효과 크기와 정밀성(신뢰구간)을 강조하십시오.
여러분의 연구가 훌륭한 시각화를 통해 더욱 빛나기를 바랍니다.
[참고문헌]
- Cleveland, W. S. (1984). Graphical methods for data presentation: Full scale breaks, dot charts, and multibased logging. The American Statistician, 38, 270-280.
- Jöreskog, K. G., & Sörbom, D. (2006). LISREL 8.8 for Windows [Computer software manual]. Scientific Software International.
- Pek, J., & Flora, D. B. (2018). Reporting effect sizes in original psychological research: A discussion and tutorial. Psychological Methods, 23(2), 208-225.
- Pek, J., Davisson, E. K., & Hoyle, R. H. (202x). Visualizations for Structural Equation Modeling. In Handbook of Structural Equation Modeling.
- Tukey, J. W. (1977). Exploratory data analysis. Addison-Wesley.