
안녕하세요!
오늘은 다층모형(Multilevel Modeling) 분석의 핵심이면서도 많은 연구자가 가장 헷갈려 하는 주제, 바로 “예측변수의 중심화(Centering Predictors)”와 “맥락 효과(Contextual Effects)”에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 초등학생도 이해할 수 있는 직관적인 설명과 대학원 수준의 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 다층분석 여행을 위한 시나리오: “수학 불안”과 “학업 성취”
자, 우리가 교육청의 의뢰를 받은 연구자라고 상상해 봅시다. 우리는 ‘수학 불안(Math Anxiety)’이 ‘수학 문제 해결력(Math Problem Solving)’에 미치는 영향을 알고 싶습니다.
- 데이터 구조: 학생()들이 학교()에 소속된 2수준(2-level) 구조입니다.
- 변수:
- (종속변수): 수학 문제 해결력 점수
- (독립변수): 수학 불안 점수 (높을수록 불안함)
단순 회귀분석과 달리, 다층모형에서는 이 (불안 점수)를 그냥 넣을지, 아니면 가공해서 넣을지에 따라 결과 해석이 완전히 달라집니다. 여기서 “가공”하는 방법이 바로 중심화(Centering)입니다.
2. 왜 중심화(Centering)가 중요한가요?
단일 수준(Single-level) 회귀분석에서는 점수를 중심화(예: 평균 빼기)하더라도 절편만 바뀌고 기울기는 그대로입니다. 하지만 다층모형에서는 중심화 방식에 따라 기울기 추정치(Slope)와 모형 적합도가 모두 바뀔 수 있습니다.
이유는 간단합니다. 학생의 점수()는 두 가지 정보를 동시에 담고 있기 때문입니다.
- 학교 내 위치 (): 우리 학교 친구들에 비해 내가 얼마나 불안한가?
- 학교 간 차이 (): 우리 학교가 다른 학교에 비해 평균적으로 얼마나 불안한가?
이 두 가지를 어떻게 처리하느냐에 따라 전체 평균 중심화(CGM)와 집단 평균 중심화(CWC)로 나뉩니다.
3. 두 가지 중심화 방법: CGM vs. CWC
(1) 전체 평균 중심화 (Grand Mean Centering: CGM)
모든 학생의 점수에서 전체 평균()을 뺍니다.
- 수식:
- 의미: “전국 평균에 비해 내 불안도가 얼마나 높은가?” (절대적인 수준)
- 특징:
- 원점수와 정보량이 같습니다. 단지 0점의 위치만 바뀝니다.
- 학교 간 차이(학교 평균의 차이)가 그대로 보존됩니다.
- 따라서 CGM을 사용한 기울기()는 학생 개인의 효과와 학교 분위기의 효과가 섞여 있는(Composite) 값입니다.
(2) 집단 평균 중심화 (Group Mean Centering: CWC)
학생의 점수에서 그 학생이 속한 학교의 평균()을 뺍니다. 이를 ‘맥락 내 중심화(Centering Within Context)’라고도 합니다.
- 수식:
- 의미: “우리 학교 친구들에 비해 내가 얼마나 더 불안한가?” (상대적인 수준)
- 특징:
- 학교 간 차이를 완전히 제거합니다. 모든 학교의 평균이 0이 됩니다.
- 이 변수는 오직 학교 내(Within-cluster) 변동만 담고 있습니다.
- 따라서 CWC를 사용한 기울기()는 순수한 개인 수준(학생 수준)의 효과만을 추정합니다.
(위 태그는 CWC의 개념인 ‘개구리 연못 효과(Frog Pond Effect)’를 시각적으로 이해하는 데 도움을 줄 수 있습니다. 내가 속한 연못(학교) 내에서의 상대적 위치를 의미합니다.)
4. 맥락 효과(Contextual Effects)와 “개구리 연못”
연구자가 흔히 범하는 실수는 “CWC가 학교 효과를 제거하니까 더 좋은 것 아닌가?”라고 생각하는 것입니다. 하지만 연구 질문(Research Question)에 따라 선택해야 합니다.
여기서 맥락 모형(Contextual Model)이 등장합니다. 이것은 개인의 점수()와 학교의 평균 점수()를 동시에 모형에 넣는 것입니다.
수식 비교
- CWC 모델:
- : 개인 효과 (학교 내에서 불안이 1단위 높을 때 성적 변화)
- : 맥락 효과(학교 효과) (학교 평균 불안이 1단위 높을 때 학교 평균 성적 변화)
- CGM 모델:
- 흥미롭게도, 이 경우 는 학교 평균의 효과와 개인 효과의 차이(Difference)를 나타냅니다.
핵심 요약:
맥락 효과를 분석할 때 CGM과 CWC는 수학적으로 동등(Equivalent)합니다. 단지 해석이 다를 뿐입니다.
- CWC의 : 학교 평균이 성적에 미치는 직접적인 영향.
- CGM의 : (학교 효과) – (개인 효과)의 차이 값.
5. 교수님의 조언: 언제 무엇을 써야 할까요?
Enders 교수의 챕터 내용을 바탕으로 명쾌한 가이드라인을 표로 정리해 드립니다.
| 연구 목적 | 추천 방법 | 이유 |
| 1. 맥락 효과 확인 (학교 분위기가 중요한가?) | 둘 다 가능 | CGM과 CWC는 수학적으로 변환 가능하며 동일한 모형 적합도를 가짐. |
| 2. 2수준 예측변수 (예: 학교 설립 유형) | CGM | 2수준 변수는 학교 내 변동이 없으므로 CWC가 불가능함. 보통 전체 평균 중심화 사용. |
| 3. 1수준 예측변수 (개인 특성) | 이론에 따라 | 절대적 수치가 중요하면(예: 절대적인 공부 시간) CGM. 상대적 위치가 중요하면(예: 자아개념, 친구와의 비교) CWC. |
| 4. 상호작용 효과 (조절효과 분석) | CWC 권장 | CGM 사용 시 ‘수준 간 상호작용(Cross-level)’과 ‘집단 간 상호작용’이 뒤섞여 해석이 모호해질 위험이 큼. |
| 5. 통제변수 (단순히 통제만 할 때) | CGM | 공변량 분석(ANCOVA)처럼 학교 간 차이를 조정(Adjust)하여 2수준 효과를 순수하게 보려면 CGM이 적절함. |
6. R과 jamovi를 이용한 실습
이제 이론을 실제 데이터로 구현해 보겠습니다.
(1) 가상 데이터 생성 (R Code)
이 코드는 챕터의 예제(Montague et al., 2011)와 유사한 구조로, 40개 학교에 25명씩 총 1,000명의 학생 데이터를 생성합니다.
R
# 필요한 패키지 로드
if(!require(MASS)) install.packages("MASS")
if(!require(lme4)) install.packages("lme4")
if(!require(tidyverse)) install.packages("tidyverse")
if(!require(jmv)) install.packages("jmv") # jamovi 연동
set.seed(12345)
# 1. 파라미터 설정
n_schools <- 40 # 학교 수
n_students <- 25 # 학교당 학생 수
total_n <- n_schools * n_students
# 2. 학교 수준(Level 2) 데이터 생성
# 학교 평균 불안감(School_Anxiety_Mean)과 학교 효과(u0j)
school_data <- data.frame(
school_id = 1:n_schools,
school_anx_mean = rnorm(n_schools, mean = 0, sd = 1), # 학교별 불안 평균
u0j = rnorm(n_schools, mean = 0, sd = sqrt(4.8)) # 절편의 변동 (약 4.8) [cite: 156]
)
# 3. 학생 수준(Level 1) 데이터 생성
data <- data.frame(
student_id = 1:total_n,
school_id = rep(1:n_schools, each = n_students)
)
# 학교 데이터 병합
data <- merge(data, school_data, by = "school_id")
# 학생 개인의 불안감 생성 (학교 평균 + 개인 편차)
# Within-school SD = 1, Between-school SD = 1
data$math_anx_raw <- data$school_anx_mean + rnorm(total_n, mean = 0, sd = 1)
# 4. 종속변수(수학 문제해결력) 생성
# 모형: Y = 10.73 + 0.33*(Within_Anx) + 0.85*(Between_Anx) + Error [cite: 321]
# CWC 계수: 0.33, Contextual 계수(B2): 0.85 가정
beta_0 <- 10.73
beta_within <- 0.33
beta_between <- 0.85
sigma_e <- sqrt(4.54) # [cite: 156]
# 변수 계산
data$anx_group_mean <- ave(data$math_anx_raw, data$school_id, FUN = mean) # 집단 평균
data$anx_cwc <- data$math_anx_raw - data$anx_group_mean # CWC 변수
data$anx_grand_mean <- mean(data$math_anx_raw) # 전체 평균
data$anx_cgm <- data$math_anx_raw - data$anx_grand_mean # CGM 변수
data$school_anx_centered <- data$anx_group_mean - data$anx_grand_mean # 중심화된 학교 평균
# 종속변수 생성 수식 (Contextual Model 기반)
data$math_score <- beta_0 +
beta_within * data$anx_cwc +
beta_between * data$school_anx_centered +
data$u0j +
rnorm(total_n, 0, sigma_e)
# 데이터 확인
head(data)
(2) jamovi 분석 가이드
jamovi에서는 GAMj 모듈을 쓰거나 기본 Linear Models -> Mixed Model을 사용합니다. 하지만 가장 명확한 방법은 위 R 코드처럼 변수를 미리 계산(Compute)해서 투입하는 것입니다.
Step 1: 변수 생성 (jamovi ‘Data’ 탭)
- Group Mean (학교 평균) 만들기:
- New Computed Variable -> 이름:
Mean_Anx_School - 수식:
VMEAN(Math_Anx, group_by=School_ID)(이 기능이 없다면 R에서 만들어 가져오는 것을 추천)
- New Computed Variable -> 이름:
- CWC 변수 만들기:
- New Computed Variable -> 이름:
Anx_CWC - 수식:
Math_Anx - Mean_Anx_School
- New Computed Variable -> 이름:
- CGM 변수 만들기:
- New Computed Variable -> 이름:
Anx_CGM - 수식:
Math_Anx - VMEAN(Math_Anx)
- New Computed Variable -> 이름:
Step 2: 분석 실행 (Analyses -> Mixed Models)
- CWC 모형 분석:
- Dependent Variable:
Math_Score - Cluster:
School_ID - Covariates:
Anx_CWC(Fixed Effect에 추가) - Random Effects: Intercept에
School_ID체크.
- Dependent Variable:
- 맥락 모형(Contextual Model) 분석:
- Covariates에
Anx_CWC와Mean_Anx_School두 개를 동시에 넣습니다. - 이렇게 하면
Anx_CWC의 계수는 개인 효과,Mean_Anx_School의 계수는 맥락 효과가 됩니다.
- Covariates에
(3) R을 이용한 시각화 (CGM vs CWC)
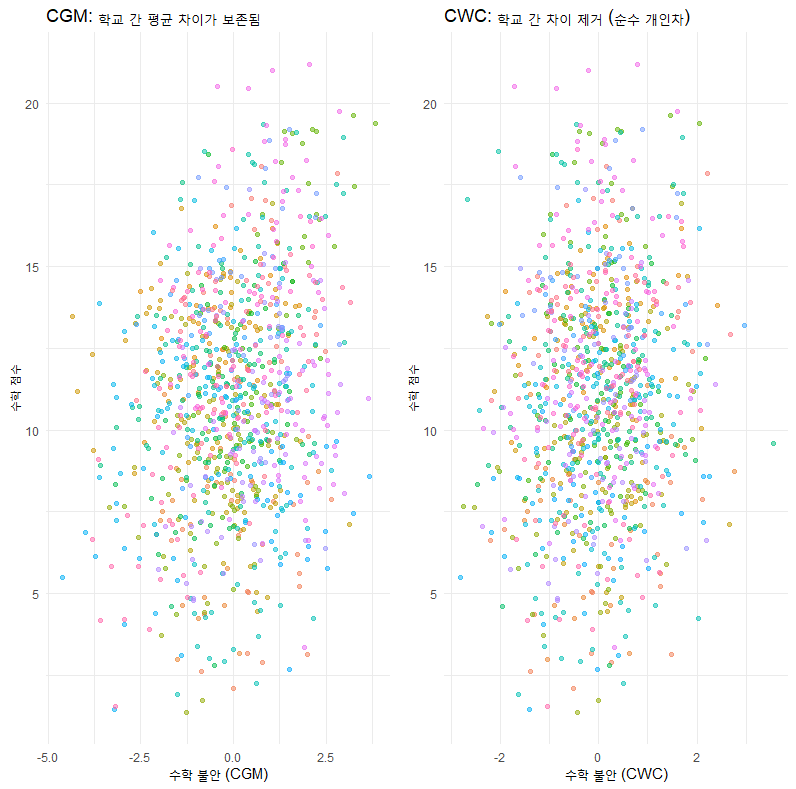
교재의 [Figure 6.2]와 [Figure 6.3]을 재현하여 데이터 구조가 어떻게 바뀌는지 보여드리겠습니다.
R
# CGM 시각화 (학교 간 차이 보존됨)
p1 <- ggplot(data, aes(x = anx_cgm, y = math_score, color = as.factor(school_id))) +
geom_point(alpha = 0.5) +
theme_minimal() +
theme(legend.position = "none") +
labs(title = "CGM: 학교 간 평균 차이가 보존됨", x = "수학 불안 (CGM)", y = "수학 점수")
# CWC 시각화 (모든 학교 평균이 0으로 정렬됨)
p2 <- ggplot(data, aes(x = anx_cwc, y = math_score, color = as.factor(school_id))) +
geom_point(alpha = 0.5) +
theme_minimal() +
theme(legend.position = "none") +
labs(title = "CWC: 학교 간 차이 제거 (순수 개인차)", x = "수학 불안 (CWC)", y = "수학 점수")
# 그래프 출력
gridExtra::grid.arrange(p1, p2, ncol = 2)
이 코드를 실행하면, CGM 그래프에서는 학교별로 점수 뭉치가 좌우로 퍼져 있는 반면(학교 간 불안 차이 존재), CWC 그래프에서는 모든 학교의 점수 뭉치가 가운데(0)를 중심으로 수직 정렬된 것을 볼 수 있습니다.
7. 결론: 무엇을 기억해야 할까요?
- 중심화는 단순한 옵션이 아닙니다. 연구 결과의 의미를 바꿉니다.
- CWC는 학교 효과를 제거합니다. 오직 ‘내 학교 안에서의 상대적 위치’만 봅니다.
- CGM은 학교 효과와 개인 효과를 섞습니다. ‘전체에서의 절대적 위치’를 봅니다.
- 연구 질문에 귀를 기울이세요. “절대적인 점수”가 중요한지(CGM), “남들과의 비교”가 중요한지(CWC) 판단하십시오.
여러분의 연구가 단순한 통계 돌리기가 아니라, 데이터 속에 숨겨진 교육적 맥락을 정확히 짚어내는 통찰이 되기를 바랍니다.
참고문헌
- Enders, C. K. (2013). Centering predictors and contextual effects. In M. A. Scott, J. S. Simonoff, & B. D. Marx (Eds.), The SAGE handbook of multilevel modeling (pp. 89-108). SAGE Publications.
- Kreft, I. G. G., de Leeuw, J., & Aiken, L. S. (1995). The effect of different forms of centering in hierarchical linear models. Multivariate Behavioral Research, 30(1), 1–21.
- Marsh, H. W., & Hau, K.-T. (2003). Big-Fish-Little-Pond effect on academic self-concept: A cross-cultural (26-country) test of the negative effects of academically selective schools. American Psychologist, 58(5), 364–376.