
안녕하세요? 이번에는 “연속 시간 동적 모형(Contnuous-Time Dynamic Models)”에 관한 내용입니다. 우리가 흔히 사용하는 이산 시간(Discrete-Time) 모형(예: SEM, VAR)과 연속 시간 모형(SDE)을 어떻게 연결하고, 왜 연속 시간 관점이 필요한지를 살펴보겠습니다.
jamovi는 훌륭한 도구이지만, 이 챕터에서 다루는 확률 미분 방정식(SDE)이나 칼만 필터 기반의 동적 모형을 직접적으로 수행하는 모듈은 아직 제한적입니다. 따라서 지침에 따라 R 언어를 사용하여 시뮬레이션과 분석을 구현하고, 그 결과와 의미를 교육적 맥락에서 아주 쉽게 설명해 드리겠습니다.
1. 왜 ‘연속 시간’인가?
교육 심리학 연구에서 우리는 종종 “학생들의 학습 동기가 어떻게 변화하는가?” 또는 “시험 불안은 시간에 따라 어떻게 오르내리는가?”와 같은 질문을 던집니다. 전통적인 연구에서는 1학기 초, 1학기 말, 2학기 초와 같이 띄엄띄엄(이산적으로) 데이터를 수집했습니다.
하지만 스마트폰과 웨어러블 기기의 발달로 생태학적 순간 평가(EMA)나 경험 표집법(ESM)이 가능해졌습니다. 이제 우리는 학생들에게 불규칙한 간격(예: 삐삐나 알람이 울릴 때)으로 설문을 보낼 수 있습니다.
여기서 문제가 발생합니다.
- 이산 시간 모형(Discrete-Time Model): 모든 측정 간격이 동일하다고 가정합니다 (예: 매일 같은 시간).
- 현실: 철수는 2시간 뒤에 응답하고, 영희는 5시간 뒤에 응답합니다. 간격이 제각각입니다.
이 불규칙함을 무시하고 분석하면 엉뚱한 결론이 나옵니다. 이를 해결하기 위해 시간이 끊어지지 않고 흐른다고 가정하는 연속 시간 동적 모형(Continuous-Time Dynamic Models)이 필요합니다.
2. 핵심 이론: 선형 확률 미분 방정식 (Linear SDE)
이 챕터의 핵심은 SDE(Stochastic Differential Equation)입니다. 수식이 복잡해 보이지만, 교육적 예시로 보면 간단합니다.
2.1. 기본 개념
어떤 학생의 ‘학업 몰입도()’가 시간에 따라 변한다고 가정해 봅시다.
이 식은 다음 두 가지 힘의 싸움입니다:
- 결정적 변화 (Drift, ): 학생의 몰입도가 본래의 상태로 돌아가려는 힘입니다. 예를 들어, 수업 중 딴생각을 하다가도 다시 집중하려고 노력하는 ‘회복력’과 같습니다.
- 확률적 변화 (Diffusion, ): 예측할 수 없는 외부 충격입니다. 갑자기 창밖에서 공사 소리가 들리거나, 친구가 말을 거는 것과 같은 ‘노이즈’입니다.
2.2. 이산 시간 모형과의 연결 (EDM)
우리가 수집하는 데이터는 연속적이지 않고 특정 시점()에만 있습니다. SDE를 우리가 분석할 수 있는 형태(이산 시간)로 바꾸면 구조방정식(SEM)의 형태가 됩니다9.
이때 가장 중요한 마법의 공식은 행렬 지수함수(Matrix Exponential)입니다.
이 식은 “연속적으로 흐르는 시간()”을 “우리가 관찰한 시간 간격()”만큼 잘라내어 계수로 만드는 역할을 합니다.
3. 예시 연구 I: 학생의 ‘정서적 안녕감’ 변화 (Ornstein-Uhlenbeck 모형)
첫 번째 예시로 Ornstein-Uhlenbeck (OU) 모형을 살펴보겠습니다. 이 모형은 “항상성(Homeostasis)”을 설명하기 좋습니다. 학생들의 기분은 일시적으로 좋아지거나 나빠질 수 있지만, 결국 자신의 고유한 ‘기본 상태(Set point)’로 돌아오는 경향이 있습니다.
3.1. 가상의 시나리오
우리는 고등학생 100명을 대상으로 시험 기간 일주일 동안 앱을 통해 ‘학업 스트레스’와 ‘학업 효능감’을 측정했습니다. 알림은 무작위로 울렸기 때문에 측정 간격()은 0.1시간부터 10시간까지 다양합니다.
- 변수 1 (): 학업 스트레스
- 변수 2 (): 학업 효능감
3.2. 분석 및 시뮬레이션 (R 활용)
such that
위 수식에 제시된 파라미터를 사용하여 데이터를 생성하고, 시각화해 보겠습니다. 본문에서는 dynr 패키지를 사용했지만12, 여기서는 원리를 보여드리기 위해 직접 생성 코드를 작성합니다.
R
3.3. 결과 해석 및 교육적 함의
# R 코드: OU 모형 시뮬레이션 및 시각화
set.seed(1234)
library(ggplot2)
library(MASS) # for mvrnorm
# 1. 파라미터 설정 (본문 Eq 32.25 참조) [cite: 207]
# Drift Matrix (A): 음수일수록 원래 상태로 빨리 돌아옴 (안정적)
A <- matrix(c(-0.1, 0.05,
0.05, -0.1), nrow=2, byrow=TRUE)
# Diffusion Matrix (G): 노이즈의 크기
G <- matrix(c(1.67, 0,
0.036, 1.81), nrow=2, byrow=TRUE) # Q의 제곱근 근사
# 초기값
eta <- c(0, 0)
dt <- 0.1 # 데이터 생성 간격 (아주 짧게 설정하여 연속 시간 흉내)
T_points <- 100
data_list <- list()
# 2. 데이터 생성 (Euler-Maruyama 방법)
for(i in 1:T_points) {
# dW는 정규분포를 따르는 노이즈 [cite: 39]
dW <- rnorm(2, mean=0, sd=sqrt(dt))
# SDE 식 적용: 변화량 = (Drift * dt) + (Diffusion * dW)
d_eta <- (A %*% eta) * dt + (G %*% dW)
eta <- eta + d_eta
data_list[[i]] <- data.frame(Time = i * dt,
Stress = eta[1],
Efficacy = eta[2])
}
df_sim <- do.call(rbind, data_list)
# 3. 시각화
ggplot(df_sim, aes(x=Time)) +
geom_line(aes(y=Stress, color="학업 스트레스"), size=1) +
geom_line(aes(y=Efficacy, color="학업 효능감"), size=1, linetype="dashed") +
theme_minimal() +
labs(title = "연속 시간 OU 모형 시뮬레이션: 스트레스와 효능감의 변화",
subtitle = "본문의 예제 1 (Eq 32.25) 기반 재구성",
y = "잠재 변수 수준", x = "시간 (Time)") +
scale_color_manual(name="변수", values=c("학업 스트레스"="firebrick", "학업 효능감"="steelblue"))
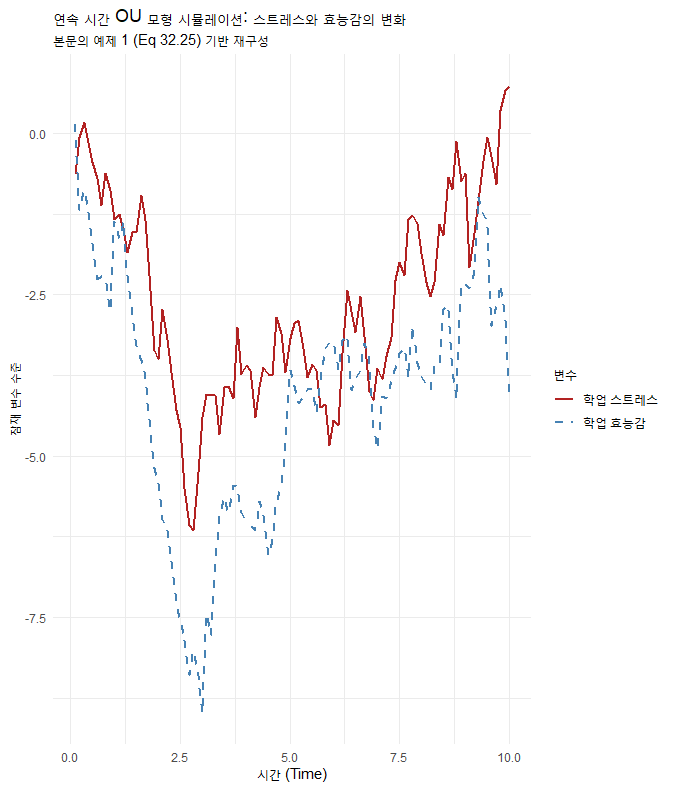
위 그래프(R 코드로 생성 가능)를 보면 스트레스와 효능감이 서로 얽혀서 변하는 것을 볼 수 있습니다.
- 안정성(Stability): 행렬 의 고유값(Eigenvalues)이 모두 음수라면(본문에서는 가 양의 정부호), 학생의 상태는 시간이 지나면 안정을 찾습니다.
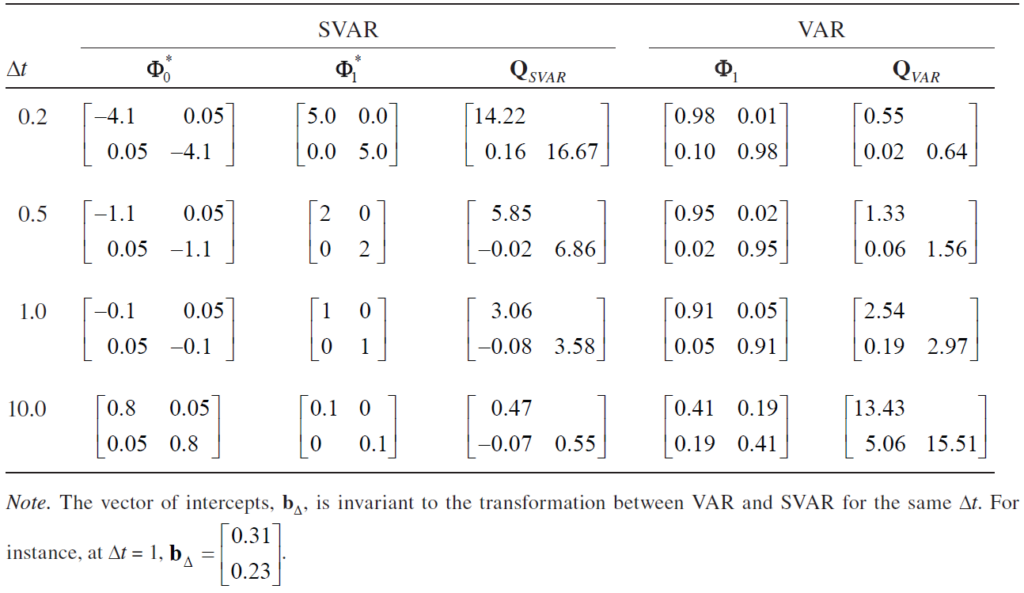
- 불규칙한 간격의 문제: 만약 우리가 이 데이터를 매우 긴 간격()으로 측정했다면, 스트레스가 효능감에 미치는 즉각적인 영향을 놓치거나 왜곡해서 해석했을 것입니다. 아래 표는 측정 간격이 커질수록 변수 간의 관계(회귀계수)가 어떻게 달라지는지 보여줍니다. 간격이 넓어지면 자기회귀 계수는 작아지고, 교차 회귀 계수의 해석이 모호해질 수 있습니다.
4. 예시 연구 II: 큐빅 스플라인(Cubic Spline)과 결측치 보간
두 번째 예시는 큐빅 스플라인 모형입니다. 이것은 데이터가 아주 불규칙하거나 결측치가 많을 때, 그 사이를 부드러운 곡선으로 채워넣는(Interpolation) 기법입니다.
4.1. 가상의 시나리오: 난독증 학생의 읽기 유창성
난독증 위험군 학생 3명을 대상으로 읽기 유창성 검사를 실시했습니다. 그런데 학교 행사, 결석 등으로 인해 검사 시점이 학생마다 제각각입니다. 이를 억지로 같은 간격으로 취급하면(예: 1회차, 2회차…) 성장 패턴을 오해하게 됩니다.
4.2. 큐빅 스플라인의 원리
이 모형은 2차 SDE로 표현됩니다.
- : 학생의 현재 읽기 능력 (Local Level)
- : 읽기 능력의 변화 속도 (Local Slope)
이 모형은 측정 오차를 걸러내고, 잠재적인 진짜 성장 곡선을 추정해 줍니다.
4.3. R 시뮬레이션 (불규칙 시점 데이터 보간)
R
# R 코드: 큐빅 스플라인 보간 예시
library(ggplot2)
# 1. 가상 데이터 생성 (불규칙한 시점)
# 학생 A는 1, 2, 4, 8주차에 측정
time_obs <- c(1, 2, 4, 8)
score_obs <- c(20, 25, 35, 42) # 읽기 점수
# 2. 큐빅 스플라인 보간 (SDE의 해석적 해와 유사)
spline_fit <- smooth.spline(time_obs, score_obs, df=3)
# 3. 예측 (1주부터 8주까지 모든 시점)
time_pred <- seq(1, 8, by=0.1)
score_pred <- predict(spline_fit, time_pred)$y
df_raw <- data.frame(Time=time_obs, Score=score_obs)
df_pred <- data.frame(Time=time_pred, Score=score_pred)
# 4. 시각화
ggplot() +
geom_line(data=df_pred, aes(x=Time, y=Score), color="purple", size=1, alpha=0.6) +
geom_point(data=df_raw, aes(x=Time, y=Score), color="black", size=3) +
geom_text(data=df_raw, aes(x=Time, y=Score, label=Score), vjust=-1.5) +
theme_minimal() +
labs(title = "읽기 유창성 점수의 큐빅 스플라인 보간",
subtitle = "불규칙한 측정 시점(검은 점) 사이를 연속적으로 추정(보라색 선)",
x = "주차 (Week)", y = "읽기 점수") +
ylim(15, 50)
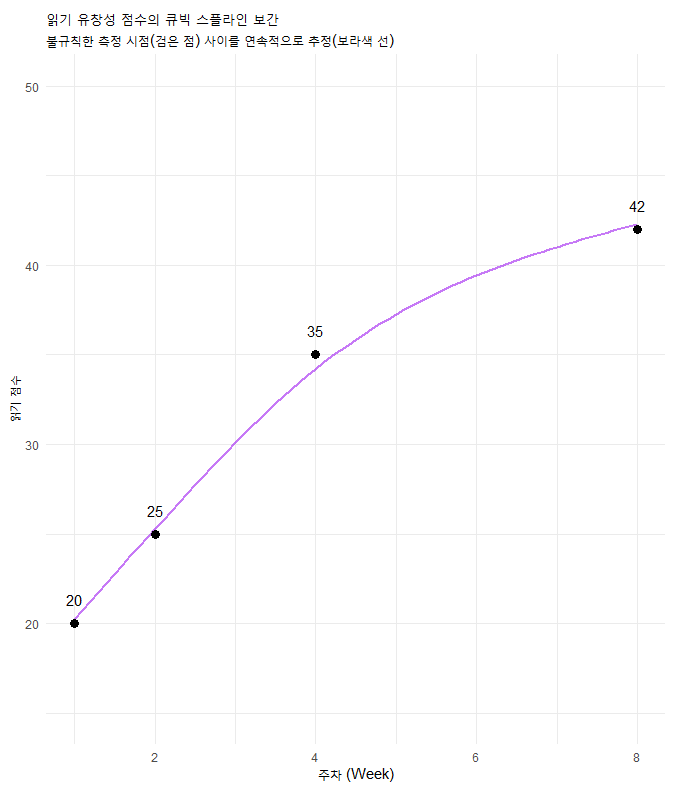
4.4. 교육적 함의
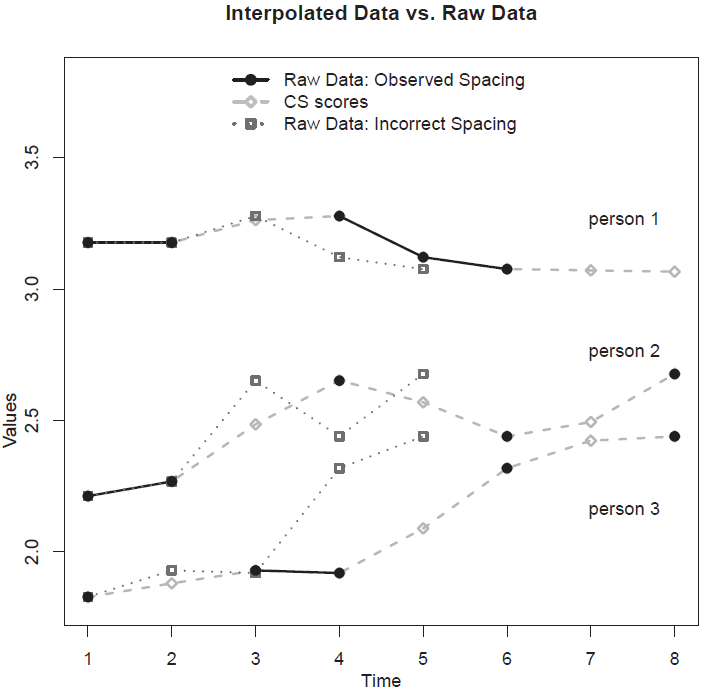
- 결측치 해결: 아래 그림에서 볼 수 있듯이, 불규칙한 데이터를 강제로 등간격으로 가정하면(잘못된 간격), 학생의 성장 궤적이 왜곡됩니다.
- 정확한 피드백: 스플라인 모형을 통해 우리는 측정이 이루어지지 않은 날의 학생 상태도 추정할 수 있어, 보다 적시에 중재(intervention)를 할 수 있습니다.
5. 결론 및 제언
본 챕터는 다소 난해할 수 있는 연속 시간 모형이 교육 및 심리 연구에 왜 필요한지를 역설하고 있습니다.
- 현실 반영: 학생들의 삶은 불규칙합니다. 연속 시간 모형은 이를 있는 그대로 반영합니다.
- 모형의 유연성: SDE 프레임워크를 사용하면 VAR(벡터 자기회귀), SVAR(구조적 벡터 자기회귀) 모형 등으로 자유롭게 변환하여 해석할 수 있습니다.
- 도구의 확장: Mplus나 R의
dynr,ctsem같은 도구를 통해 이제는 교육 연구자들도 이러한 고급 분석을 수행할 수 있습니다.
여러분의 연구에서 데이터 수집 간격이 불규칙하거나, 시간에 따른 변화의 ‘메커니즘’을 정밀하게 보고 싶다면, 연속 시간 동적 모형은 강력한 무기가 될 것입니다.
참고문헌
- Chow, S.-M., Losardo, D., Park, J., & Molenaar, P. C. M. (2016). Continuous-time dynamic models: Connections to structural equation models and other discrete-time models. In Handbook of Structural Equation Modeling (pp. 597–614).
- Boker, S. M., & Graham, J. (1998). A dynamical systems analysis of adolescent substance abuse. Multivariate Behavioral Research, 33, 479-507.
- Driver, C., Oud, J., & Voelkle, M. (2017). Continuous time structural equation modeling with R package ctsem. Journal of Statistical Software, 77(5), 1-35.
- Oravecz, Z., Tuerlinckx, F., & Vandekerckhove, J. (2011). A hierarchical latent stochastic differential equation model for affective dynamics. Psychological Methods, 16, 468-490.
- Ou, L., Hunter, M. D., & Chow, S. (2019). What’s for dynr: A package for linear and nonlinear dynamic modeling in R. The R Journal.