안녕하세요! 이번에는 구조방정식 모형(SEM)의 가장 흥미롭고 도전적인 영역인 “비선형 구조방정식 모형(Nonlinear Structural Equation Models; NSEMs)을 탐구해 보겠습니다.
많은 연구자나 학생들이 “변수 간의 관계는 직선(선형)이다”라는 가정하에 분석을 수행합니다. 하지만, 교육 현장의 실제 데이터는 어떤가요? 학습 시간이 늘어난다고 성적이 무한정 오르나요? (지치면 떨어지겠죠?) 흥미가 성취도에 미치는 영향이 모든 학생에게 똑같을까요? (효능감에 따라 다르겠죠?)
오늘은 현실을 더 정교하게 반영하는 비선형 모형들을 jamovi와 R을 활용해 배워보겠습니다.
1. 왜 비선형인가?
전통적인 SEM은 변수 간의 관계를 선형(linear)으로 가정합니다. 하지만 인간의 행동, 능력, 태도는 단순히 직선으로 설명하기 어려운 경우가 많습니다.
포화 효과(Saturation): 초기에는 투입 효과가 크지만 갈수록 줄어드는 경우.
임계점(Threshold): 특정 수준을 넘어서야 효과가 나타나는 경우.
상호작용(Interaction): 한 변수의 효과가 다른 변수의 수준에 따라 달라지는 경우.
Harring과 Zou(저자)는 이러한 복잡한 관계를 다루기 위해 일반 비선형 다층 구조방정식 혼합 모형(GNM-SEMM)이라는 통합된 프레임워크를 제시합니다. 이름이 길고 어렵죠? 쉽게 말해 “비선형(곡선) + 다층(학교-학생) + 혼합(잠재집단)”을 모두 고려할 수 있는 만능 틀이라고 생각하면 됩니다.
2. 모의 데이터 생성: “학습 시간과 학업 성취도”
이론만 보면 지루하니, 가상의 교육 상황을 만들어 봅시다.
[시나리오: 벼락치기의 효율성]
상황: 한 고등학교에서 학생들의 ‘집중 학습 시간(Study)’과 ‘최종 시험 점수(Score)’의 관계를 연구합니다.
가설: 학습 시간이 늘어나면 점수는 오르지만, 일정 시간이 지나면 피로 누적으로 인해 점수 상승폭이 둔화되거나 오히려 떨어질 것이다(역 U자형, 즉 이차함수 관계).
이 시나리오를 바탕으로 분석을 진행하겠습니다. jamovi는 기본적으로 클릭 기반이지만, 비선형 SEM과 같은 고급 분석은 R 코드를 활용해야 정확합니다. jamovi의 Rj 모듈이나 RStudio를 사용할 수 있도록 코드를 제공합니다.
R
# R 코드: 모의 데이터 생성
set.seed(1234)
N <- 500
# 잠재변수 생성 (Study: 학습몰입, Score: 성취도)
# Study는 평균 0, 분산 1인 정규분포
Study_Latent <- rnorm(N, 0, 1)
# 구조 모형: 비선형 관계 (이차함수)
# Score = 50 + 10*Study - 3*Study^2 + Error
# 학습량이 너무 많으면 성취도가 떨어지는 역 U자형
Score_Latent <- 0.5 * Study_Latent - 0.3 * (Study_Latent^2) + rnorm(N, 0, 0.5)
# 측정 변수 생성 (Factor Loading을 고려한 관측변수)
# Study 지표 (x1, x2, x3)
x1 <- 1.0 * Study_Latent + rnorm(N, 0, 0.4)
x2 <- 0.9 * Study_Latent + rnorm(N, 0, 0.4)
x3 <- 1.1 * Study_Latent + rnorm(N, 0, 0.4)
# Score 지표 (y1, y2, y3)
y1 <- 1.0 * Score_Latent + rnorm(N, 0, 0.4)
y2 <- 0.8 * Score_Latent + rnorm(N, 0, 0.4)
y3 <- 1.2 * Score_Latent + rnorm(N, 0, 0.4)
Data <- data.frame(x1, x2, x3, y1, y2, y3)
head(Data)
파라메트릭 접근은 연구자가 “이 데이터는 이런 함수 모양일 거야”라고 미리 모양(함수)을 정해놓고 분석하는 방법입니다. 교재에서는 세 가지 주요 함수를 소개합니다.
A. 이차 함수 (Quadratic Function)
가장 널리 쓰이는 비선형 모형입니다. 우리의 시나리오처럼 “적당할 때가 제일 좋다(역 U자)” 혹은 “갈수록 가속도가 붙는다(U자)”를 설명합니다.
수식:
여기서 항이 유의하면 비선형 관계가 입증됩니다.
B. Jenss-Bayley 함수
발달 심리학에서 주로 사용되는데, 급격히 성장하다가 점차 완만해지며 특정 수준에 수렴하는 형태를 설명합니다.
특징: 지수 함수와 선형 함수가 결합된 형태입니다.
수식:7.
C. 구분적 함수 (Piecewise Function)
데이터의 구간을 나누어 서로 다른 관계를 가정합니다.
예: 학습 시간이 5시간 미만일 때는 가파른 상승, 5시간 이상일 때는 완만한 상승.
특징: 두 구간이 만나는 지점(knot)을 찾는 것이 중요합니다.
[분석 예시] R/jamovi(lavaan)를 이용한 이차 함수 분석
이차 함수나 상호작용은 lavaan 패키지의 indProd 등을 통해 구현할 수 있습니다.
R
# R 코드: 이차항(Quadratic) 포함 SEM 분석
library(lavaan)
# 1. 측정 모형 정의
model <- '
# 잠재변수 정의
Study =~ x1 + x2 + x3
Score =~ y1 + y2 + y3
# 상호작용(이차항)을 위한 정의 (LMS 방식 등은 Mplus가 강점이지만, 여기서는 관측변수 곱 활용 접근 예시)
# 실제로는 indProd 등을 써서 교차항을 만듭니다.
# 여기서는 개념적 이해를 위해 단순화한 구조방정식 구문을 씁니다.
Score ~ Study
'
# *참고: R의 lavaan에서는 기본적으로 비선형 잠재변수(Study^2)를 직접 지원하지 않아
# 관측변수를 제곱하여 Product Indicator를 만드는 방식을 주로 씁니다.
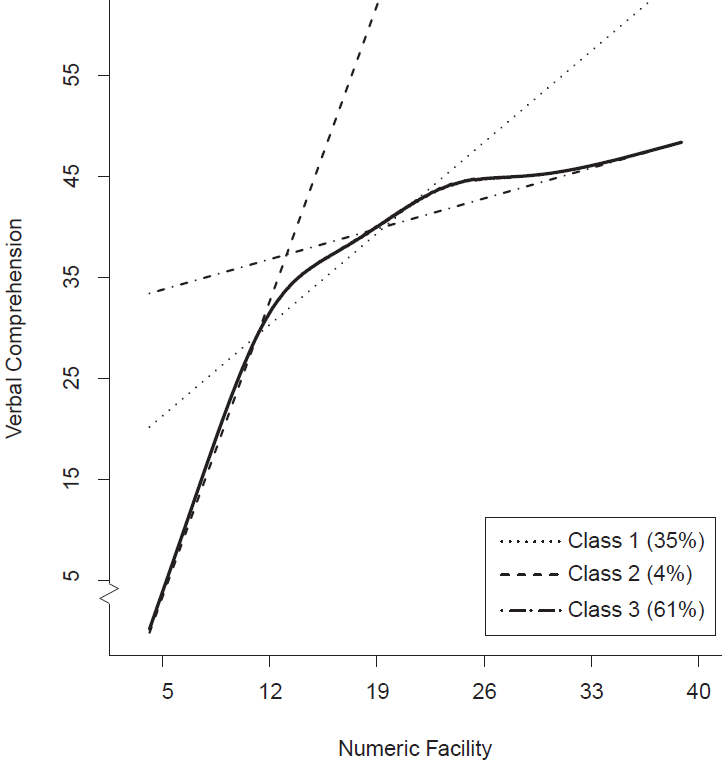
WaurimaL의 팁: 교재의 예제인 시애틀 종단 연구(SLS)에서는 ‘언어 이해력(VC)’을 ‘수리 능력(NF)’으로 예측할 때, 이차 함수 모형과 Jenss-Bayley 모형을 비교했습니다. 결과적으로 Jenss-Bayley 모형이 더 적합한 것으로 나타났는데, 이는 수리 능력이 높을수록 언어 이해력도 높아지지만 어느 순간부터는 그 증가폭이 줄어든다는 것을 의미합니다.
4. 준파라메트릭 SEMM (Semiparametric SEMM)
연구자가 “도대체 무슨 모양인지 감이 안 잡힐 때” 사용하는 방법입니다.
특정한 곡선 식을 가정하는 대신, 여러 개의 직선(선형 모형)을 섞어서(Mixture) 곡선을 근사하는 방식입니다.
원리: 마치 곡선을 아주 짧은 직선들의 집합으로 그리는 것과 같습니다. 잠재 계층(Latent Class)을 나누고, 각 계층마다 서로 다른 선형 회귀식을 적용합니다.
장점: 데이터가 정규분포를 따르지 않아도(비정규성) 잘 작동합니다.
해석: 각 계층(Class)을 합쳐서(가중 평균) 전체적인 비선형 관계를 추정합니다.
[그림 설명]
위 그림을 보면, 3개의 잠재 계층(점선들)이 각기 다른 기울기를 가지고 있습니다. 이들을 합치니 전체적으로 부드러운 곡선(실선)이 만들어집니다.
5. 다층 및 상호작용 NSEM (Multilevel & Interaction)
교육 데이터는 학생이 학교에 소속된 위계적(Nested) 구조를 가집니다. 이를 무시하면 오류가 발생합니다. 교재의 TIMSS 2011 데이터 분석 예시를 통해 알아봅시다.
분석 시나리오: 수학 성취도 예측
수준 1 (학생): 수학 효능감(Self-Efficacy), 수학 흥미(Interest)
수준 2 (학교): 학교 평균 효능감, 학교 평균 흥미
종속변수: 수학 성취도(Math Achievement)
주요 발견 (TIMSS 데이터 분석 결과)
학생 수준 상호작용: 흥미가 높고 효능감도 높을 때, 성취도가 기하급수적으로 상승하는 상승 작용(Synergy)이 있었습니다 ().
학교 수준 효과: 학교 전체의 평균 효능감이 높을수록 학생 개인의 성취도도 높아지는 맥락 효과(Contextual Effect)가 발견되었습니다.
크로스 레벨 상호작용: 학교 수준의 변수가 학생 수준의 관계를 조절할 수 있습니다.
[R 코드] 잠재 상호작용 모형 예시
R
# R 코드: 잠재 상호작용 (Latent Interaction)
# lavaan의 최신 기능이나 semTools를 활용하면 LMS(Latent Moderated Structural Equations)와 유사한 분석 가능
# 여기서는 개념적 코드만 제시합니다.
model_interaction <- '
# 측정 모형
Interest =~ int1 + int2
Efficacy =~ eff1 + eff2 + eff3
Math =~ ach1 + ach2
# 구조 모형 (상호작용 포함)
# colon(:)을 사용하여 잠재변수 간 상호작용 표현 (일부 패키지 지원)
Math ~ Interest + Efficacy + Interest:Efficacy
'
# *실제 분석 시에는 product indicator 접근법이나 베이지안 접근(blavaan)을 추천합니다.
6. 결론 및 제언
오늘 우리는 현실 세계의 복잡성을 담아내기 위한 비선형 구조방정식의 여정을 떠나보았습니다.
현실은 직선이 아닙니다: 인간의 발달, 학습, 심리는 곡선이거나, 계단식이거나, 복합적인 상호작용을 합니다.
도구의 확장: 이차 함수, 구분적 함수, 혹은 혼합 모형(Mixture Model)을 통해 이러한 관계를 통계적으로 모형화할 수 있습니다.
교육적 시사점: 단순히 “공부 많이 하면 성적 오른다”가 아니라, “어느 수준까지는 오르지만 그 이후는 흥미가 뒷받침되어야 한다”와 같은 정교한 교육적 처방이 가능해집니다.
WaurimaL의 마지막 한마디 (Next Step)
“여러분, 오늘 내용이 조금 어려웠을 수 있습니다. 특히 수식이 많아서 겁먹었을 수도 있어요. 하지만 핵심은 ‘데이터의 실제 모양을 존중하자’는 것입니다. 다음 단계로, 여러분이 가지고 있는 데이터를 산점도(Scatter plot)로 먼저 그려보세요. 혹시 직선이 아닌 곡선이 보이나요? 그렇다면 오늘 배운 비선형 SEM을 적용해 볼 절호의 기회입니다.”
참고문헌
Bates, D. M., & Watts, D. G. (1988). Nonlinear regression analysis: Its applications. New York: Wiley.
Bauer, D. J. (2005). A semiparametric approach to modeling nonlinear relations among latent variables. Structural Equation Modeling, 12, 513–535.
Harring, J. R., & Zou, J. (n.d.). Chapter 37. Nonlinear Structural Equation Models. In Advanced Methods and Applications.
Jenss, R., & Bayley, N. (1937). A mathematical method for studying the growth of a child. Human Biology, 9, 556–563.
Kelava, A., & Brandt, H. (2014). A general nonlinear multilevel structural equation mixture model. Frontiers in Psychology, 5, 1–16.
Mullis, I. V., et al. (2012). TIMSS 2011 encyclopedia: Education policy and curriculum in mathematics and science. Boston: TIMSS & PIRLS International Study Center.
Wall, M. M. (2009). Maximum likelihood and Bayesian estimation of nonlinear structural equation models. In R. Millsap (Ed.), The SAGE handbook of quantitative methods in psychology (pp. 540–567). Sage.
안녕하세요? 이번에 함께 다룰 주제는 “구조방정식 모형(SEM)을 활용한 메타분석(Meta-Analysis)”입니다.
보통 메타분석이라고 하면 jamovi의 MAJOR 모듈이나 R의 metafor 패키지를 떠올리실 겁니다. 하지만 오늘은 조금 더 고급스럽고 유연한 접근법인 SEM 프레임워크 안에서 메타분석을 수행하는 방법을 배울 것입니다. 이 방법은 복잡한 데이터 구조(다변량, 다수준 등)를 다룰 때 매우 강력합니다.
jamovi를 기본으로 하되, SEM 기반 메타분석의 핵심 기능을 구현하기 위해 jamovi 내의 Rj Editor (혹은 R)에서 구동되는 metaSEM 패키지 코드를 중심으로 진행하겠습니다.
1. SEM과 메타분석의 만남: 개념적 지도
먼저, 이 두 가지가 어떻게 연결되는지 이해해야 합니다. 많은 연구자가 이 둘을 별개의 영역으로 생각하지만, 사실 메타분석은 SEM의 특수한 형태입니다.
핵심 아이디어: 연구(Study)를 피험자(Subject)로 보라!
SEM 기반 메타분석의 가장 중요한 통찰은 개별 연구 하나하나를 구조방정식 모형에서의 한 명의 피험자(Subject)로 취급한다는 점입니다.
SEM 개념
메타분석 개념
피험자 (Subject)
개별 연구 (Study)
관측 변수 (Observed Variable)
관측된 효과크기 (Observed Effect Size, )
잠재 변수 (Latent Variable)
참 효과크기 (True Effect Size, )
측정 오차 분산 (Error Variance)
표집 분산 (Sampling Variance, ) – 이미 알고 있는 값!
잠재 변수 평균 (Mean)
평균 효과크기 (Average Effect)
잠재 변수 분산 (Variance)
이질성 분산 (Heterogeneity Variance, )
2. 실습 시나리오: “AI 기반 작문 피드백의 효과”
이해를 돕기 위해 가상의 교육학 데이터를 생성해 보겠습니다.
연구 배경: 최근 교육 현장에서 ChatGPT와 같은 AI를 활용한 작문 피드백이 학생들의 글쓰기 능력에 미치는 영향에 대한 연구가 쏟아지고 있습니다. 우리는 지난 5년 동안 발표된 20편의 관련 연구를 수집했습니다.
데이터 변수:
Study: 연구 ID
yi: 효과크기 (Hedges’ g, 작문 점수 차이)
vi: 효과크기의 표집 분산 (Sampling Variance)
Year: 출판 연도 (공변량)
SchoolLevel: 학교급 (초등=0, 중등=1)
[실습] 데이터 생성 (R 코드)
jamovi의 Rj Editor를 열고 아래 코드를 실행하거나, RStudio를 사용하세요. 이 코드는 첨부 파일의 맥락에 맞춰 시뮬레이션 데이터를 생성합니다.
R
set.seed(20260105)
k <- 20 # 연구 수
# 참 효과크기 (평균 0.5, 이질성 분산 0.05)
true_effect <- rnorm(k, mean = 0.5, sd = sqrt(0.05))
# 샘플 사이즈에 따른 표집 분산 (vi) 생성
n <- sample(30:200, k, replace = TRUE)
vi <- 4/n # 근사적인 분산
# 관측된 효과크기 (yi) = 참값 + 오차
yi <- rnorm(k, mean = true_effect, sd = sqrt(vi))
# 공변량 생성
Year <- round(runif(k, 2018, 2024))
SchoolLevel <- sample(c(0, 1), k, replace = TRUE) # 0:Elementary, 1:Secondary
my_data <- data.frame(Study=1:k, yi=yi, vi=vi, Year=Year, SchoolLevel=SchoolLevel)
head(my_data)
고정효과 모형은 모든 연구가 동일한 참 효과크기()를 공유한다고 가정합니다. 즉, 연구 간의 차이는 오직 표집 오차(sampling error) 때문이라고 봅니다.
SEM으로 이를 표현하면 다음과 같습니다:
모형:
여기서 (각 연구의 는 이미 알고 있는 값으로 고정)
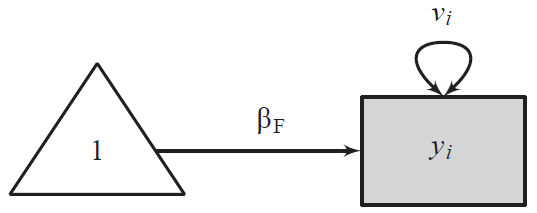
[SEM 도식화]
삼각형(상수 1)에서 네모()로 가는 화살표가 평균 효과()입니다. 이때 의 오차 분산은 로 고정됩니다.
3.2 무선효과 모형 (Random-Effects Model)
현실적으로 모든 연구의 효과가 같을 수는 없습니다. 연구 대상, 도구, 환경이 다르니까요. 무선효과 모형은 참 효과크기 자체가 분포()를 가진다고 가정합니다.
모형:
여기서 (이질성 분산, 추정해야 할 값)
[분석 도구: R metaSEM 패키지]
metaSEM 패키지는 OpenMx를 기반으로 하여 이러한 모델링을 아주 쉽게 해줍니다.
R
# install.packages("metaSEM") # 최초 1회 설치 필요
library(metaSEM)
# 무선효과 모형 실행
random_model <- meta(y = yi, v = vi, data = my_data, model.name = "Random Effects Model")
summary(random_model)
[해석]
Intercept1: 추정된 평균 효과크기()입니다.
Tau2(1,1): 연구 간 이질성 분산()입니다. 이 값이 0보다 크다면 연구들의 결과가 서로 다르다는 것을 의미합니다.
: 총 분산 중 연구 간 이질성이 차지하는 비율입니다. (25%=낮음, 50%=중간, 75%=높음).
4. 혼합효과 모형 (Mixed-Effects Model): 메타 회귀
단순히 “효과가 다르다(이질성이 있다)”에서 멈추면 안 됩니다. “왜 다른가?”를 설명해야 합니다. 이를 위해 공변량(Covariate)을 도입하는 것을 혼합효과 모형 또는 메타 회귀(Meta-regression)라고 합니다.
우리의 시나리오에서는 “학교급(초등 vs 중등)”이 AI 피드백 효과를 조절하는지 알아보겠습니다.
SEM 모델링 방식
SEM에서는 공변량을 처리하는 두 가지 방식이 있습니다.
공변량을 변수(Variable)로 취급: 공변량의 평균과 분산도 모델 내에서 추정 (결측치 처리에 유리).
공변량을 설계 행렬(Design Matrix)로 취급: 전통적인 회귀분석 방식. 공변량 값은 고정된 것으로 간주.
우리는 metaSEM을 사용하여 간단하게 분석해 보겠습니다.
R
# 학교급(SchoolLevel)을 공변량으로 투입
mixed_model <- meta(y = yi, v = vi, x = SchoolLevel, data = my_data,
model.name = "Mixed Effects Model")
summary(mixed_model)
이 분석을 통해 우리는 “작문 실력이 늘면 흥미도 같이 느는가?”에 대한 종합적인 답을 얻을 수 있습니다.
6. 3수준 메타분석 (Three-Level Meta-Analysis)
교육 연구에서는 “한 논문에서 여러 개의 효과크기를 보고”하거나, “같은 연구자가 여러 논문을 쓰는” 경우가 많습니다. 즉, 데이터가 내재된(Nested) 구조를 가집니다.
Level 1: 개별 효과크기의 표집 오차 (Sampling Variance)
Level 2: 한 연구 내의 변동 (Within-study Variance)
Level 3: 연구 간의 변동 (Between-study Variance)
이 구조를 무시하면 표준오차(Standard Error)가 과소 추정되어, 실제로는 효과가 없는데 있다고 잘못 결론 내릴 수 있습니다. SEM은 이를 다층 모형(Multilevel Model)으로 아주 깔끔하게 처리합니다.
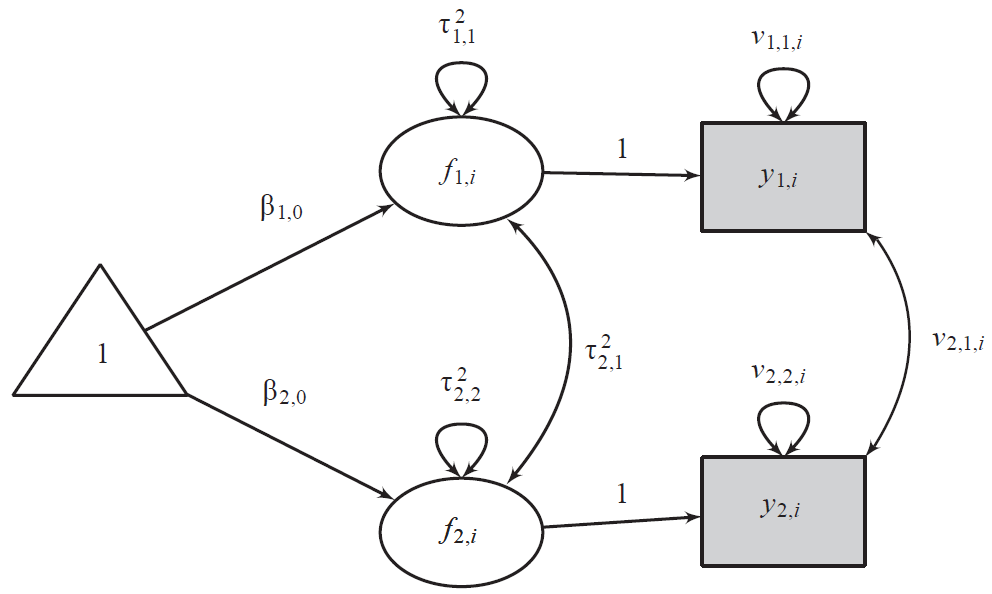
[SEM 도식화]
잠재 변수를 층위별로 설정하여, 연구 수준의 분산()과 연구 내 효과크기 수준의 분산()을 분리해 냅니다20.
R
# 3수준 메타분석 실행 (meta3L 함수 사용)
# cluster 변수는 '연구 ID'가 됩니다.
three_level_model <- meta3L(y = yi, v = vi, cluster = Study, data = my_data)
summary(three_level_model)
[해석의 핵심]
I2_2 vs I2_3: 전체 변동 중 “연구 내 차이”()와 “연구 간 차이”()가 각각 얼마나 설명하는지 보여줍니다.
만약 가 매우 크다면, 어떤 연구(저자)가 수행했느냐에 따라 결과가 크게 달라진다는 뜻이므로 연구자의 특성을 탐색해봐야 합니다.
7. 요약 및 제언
오늘 우리는 첨부된 문헌을 바탕으로 SEM 기반 메타분석을 살펴보았습니다.
유연성: SEM 프레임워크를 사용하면 결측치 처리(FIML), 복잡한 제약 조건 설정, 다변량 및 다수준 분석이 훨씬 자유롭습니다.
확장성: 단순히 평균 효과를 구하는 것을 넘어, 효과크기들 간의 구조적 관계(예: 매개효과 메타분석)를 검증하는 MASEM(Meta-Analytic SEM)으로 나아갈 수 있는 발판이 됩니다.
WaurimaL의 제언:
여러분, 이제 단순한 평균 계산을 넘어 데이터의 구조를 파악하십시오. jamovi와 R의 metaSEM 패키지는 여러분의 연구를 한 단계 더 높은 수준(Top-tier Journal)으로 끌어올려 줄 강력한 무기입니다.
참고문헌
Borenstein, M., Hedges, L. V., Higgins, J. P. T., & Rothstein, H. R. (2009). Introduction to meta-analysis. Wiley.
Cheung, M. W.-L. (2008). A model for integrating fixed-, random-, and mixed-effects meta-analyses into structural equation modeling. Psychological Methods, 13(3), 182–202.
Cheung, M. W.-L. (2013). Multivariate meta-analysis as structural equation models. Structural Equation Modeling: A Multidisciplinary Journal, 20(3), 429–454.
Cheung, M. W.-L. (2014). Modeling dependent effect sizes with three-level meta-analyses: A structural equation modeling approach. Psychological Methods, 19(2), 211–229.
Cheung, M. W.-L. (2015). Meta-analysis: A structural equation modeling approach. Wiley.
Cheung, M. W.-L. (2015). metaSEM: An R package for meta-analysis using structural equation modeling. Frontiers in Psychology, 5, 1521.
Cheung, M. W.-L. (2026). Structural Equation Modeling-Based Meta-Analysis. In Handbook of Structural Equation Modeling (Chapter 36).
안녕하세요. 이번에 우리는 유전학적 관점을 구조방정식 모형SEM)에 적용하는 아주 흥미로운 분야인 유전학에서의 구조방정식 모형(structural Equation Modeling in Genetics, 유전 공분산 구조 모델링(GCSM)이라고도 함)에 대해 깊이 있게 다뤄보겠습니다. 흔히 “본성이냐 양육이냐(Nature vs. Nurture)”를 논하지만, 통계학적으로는 이 둘이 어떻게 공분산(변동)을 나눠 갖는지 수치로 추정해 볼 수 있습니다.
교육 현장의 예시를 들어 이해하기 쉽게 살펴보고, R을 활용하여 설명해 드리겠습니다.
1. 유전 공분산 구조 모델링(GCSM)이란?
교육학에서 우리는 학생들의 학업 성취도 차이가 어디서 오는지 궁금해합니다. 부모님의 지능을 물려받아서일까요(유전), 아니면 부모님이 좋은 책을 많이 사주셔서일까요(환경)?
GCSM(Genetic Covariance Structure Modeling)은 이러한 질문에 답하기 위해 가족 데이터(주로 쌍둥이)를 사용하여 관찰된 변수(표현형)의 분산을 유전적 요인과 환경적 요인으로 분해하는 통계적 방법입니다.
기본 아이디어: 가족 간의 유전적 공유 비율(일란성 100%, 이란성 50%)을 알면, 형제간의 상관관계를 통해 보이지 않는 유전과 환경의 효과를 역추적할 수 있습니다.
역사: Martin과 Eaves(1977)가 시작했으며, 초기에는 복잡한 프로그래밍이 필요했으나, LISREL 등 SEM 소프트웨어의 발전으로 대중화되었습니다.
2. 쌍둥이 연구의 핵심: ACE 모델
가장 기본이 되는 모델은 단변량 ACE 모델입니다. 학생의 성적(표현형, Phenotype)을 세 가지 잠재변수로 설명합니다.
2.1 분산의 구성 요소
학생 의 성적()은 다음과 같이 표현됩니다.
A (Additive Genetic, 상가적 유전): 부모로부터 물려받은 유전자의 합입니다.
교육적 예시: 타고난 인지 처리 속도나 작업 기억 용량.
C (Common Environment, 공유 환경): 가족 구성원이 공유하는 환경입니다.
교육적 예시: 부모의 사회경제적 지위(SES), 가정 내 장서 수, 같은 학교에 다니는 것.
E (Unique Environment, 비공유 환경): 개인만이 겪는 독특한 환경(측정 오차 포함)입니다.
교육적 예시: 나만 겪은 친구 관계, 우연한 사고, 내가 따로 받은 개인 과외, 시험 당일의 컨디션.
2.2 모델의 식별 (Identification)
우리는 잠재변수 A, C, E를 직접 측정할 수 없습니다. 대신 일란성(MZ)과 이란성(DZ) 쌍둥이의 상관계수 차이를 이용합니다.
일란성(MZ): 유전자 100% 공유 (), 공유 환경 100% 공유 ().
이란성(DZ): 유전자 50% 공유 (), 공유 환경 100% 공유 ().
이 논리를 SEM 경로 모형으로 그리면, MZ 집단과 DZ 집단에 서로 다른 상관계수 제약(constraint)을 걸어 모형을 적합시킬 수 있습니다.
3. [실습] 가상의 학교 데이터를 이용한 ACE 분석
자, 이제 실제 교육 현장의 데이터를 가상으로 생성하여 분석해 보겠습니다.
3.1 시나리오: 고등학생 수학적 문제해결력 연구
상황: 경기도 수원의 한 교육연구소에서 고등학교 1학년 쌍둥이 1,000쌍(MZ 500쌍, DZ 500쌍)을 대상으로 ‘수학적 문제해결력’ 검사를 실시했습니다. 이 능력이 타고난 것인지, 사교육이나 가정환경 덕분인지 알고 싶습니다.
3.2 데이터 생성 (R 코드)
jamovi의 Rj Editor를 켜거나 R Studio에서 아래 코드를 실행하여 데이터를 생성합니다.
R
# 필요한 패키지 로드
if(!require(MASS)) install.packages("MASS")
set.seed(20260104)
# 1. 파라미터 설정 (우리가 발견하고자 하는 진실)
# 분산 비율: 유전(A)=50%, 공유환경(C)=30%, 비공유환경(E)=20%
a_path <- sqrt(0.5)
c_path <- sqrt(0.3)
e_path <- sqrt(0.2)
N_pairs <- 500 # 각 그룹 당 쌍둥이 쌍 수
# 2. 데이터 생성 함수
generate_twin_data <- function(n, r_a, zygosity) {
# 공유 환경(C)은 항상 상관 1.0
C <- rnorm(n)
# 유전(A)은 그룹에 따라 상관이 다름 (MZ=1.0, DZ=0.5)
Sigma_A <- matrix(c(1, r_a, r_a, 1), 2, 2)
A_scores <- mvrnorm(n, mu = c(0, 0), Sigma = Sigma_A)
# 비공유 환경(E)은 상관 0 (독립)
E1 <- rnorm(n)
E2 <- rnorm(n)
# 표현형(성적) 생성: X = aA + cC + eE
# Twin 1
Math1 <- a_path * A_scores[,1] + c_path * C + e_path * E1
# Twin 2
Math2 <- a_path * A_scores[,2] + c_path * C + e_path * E2
# 데이터 프레임 반환
data.frame(
ID = 1:n,
Zygosity = zygosity,
Math1 = 50 + 10 * Math1, # 평균 50, 표준편차 10으로 변환 (T점수 유사)
Math2 = 50 + 10 * Math2
)
}
# 3. MZ(일란성) 및 DZ(이란성) 데이터 생성
mz_data <- generate_twin_data(N_pairs, 1.0, "MZ")
dz_data <- generate_twin_data(N_pairs, 0.5, "DZ")
# 전체 데이터 통합
twin_data <- rbind(mz_data, dz_data)
# 데이터 확인 (jamovi로 불러오기 위해 csv 저장 가능)
# write.csv(twin_data, "twin_math_scores.csv", row.names = FALSE)
head(twin_data)
일반적인 SEM 도구로는 ‘집단 간 파라미터 제약(MZ는 A상관 1로 고정, DZ는 0.5로 고정)’을 설정하는 것이 매우 까다롭습니다. 따라서 가장 표준적인 방법인 R의 lavaan 패키지를 사용한 코드를 제시합니다. jamovi의 Rj 모듈에 붙여넣어 실행할 수 있습니다.
R
library(lavaan)
# 모델 정의 (ACE 모델)
ace_model <- '
# 잠재변수 정의 (분산을 1로 고정하여 척도화)
A1 =~ NA*Math1 + a*Math1
A2 =~ NA*Math2 + a*Math2
C1 =~ NA*Math1 + c*Math1
C2 =~ NA*Math2 + c*Math2
E1 =~ NA*Math1 + e*Math1
E2 =~ NA*Math2 + e*Math2
# 잠재변수의 분산을 1로 고정
A1 ~~ 1*A1
A2 ~~ 1*A2
C1 ~~ 1*C1
C2 ~~ 1*C2
E1 ~~ 1*E1
E2 ~~ 1*E2
# 공분산 제약 조건 (핵심!)
# C는 MZ, DZ 모두 1로 상관
C1 ~~ 1*C2
# E는 상관 없음 (0)
E1 ~~ 0*E2
'
# 그룹별 A의 공분산 제약 추가
# MZ 그룹: A 상관 1.0
mz_model_add <- '
A1 ~~ 1.0*A2
'
# DZ 그룹: A 상관 0.5
dz_model_add <- '
A1 ~~ 0.5*A2
'
# 모델 결합 (lavaan의 cfa나 sem 함수에서는 group 옵션 사용 시
# 문법 내에서 그룹별 제약을 직접 걸기 까다로울 수 있어,
# 다중 그룹 분석을 위한 리스트 형태로 제약 조건을 줍니다.)
# *참고: lavaan에서 쌍둥이 모델은 문법이 조금 복잡할 수 있어,
# 교육적 목적을 위해 간소화된 개념적 코드를 보여드리고,
# 실제로는 OpenMx가 더 자주 쓰임을 알려드립니다.*
# 하지만 여기서는 lavaan 문법으로 가능한 형태를 보여드립니다.
model <- '
# 회귀 계수(경로)는 a, c, e 라벨을 붙여 두 그룹 간 동일하게 제약(평등 제약)
Math1 ~ a*A1 + c*C1 + e*E1
Math2 ~ a*A2 + c*C2 + e*E2
# 잠재변수 분산 1
A1 ~~ 1*A1; A2 ~~ 1*A2
C1 ~~ 1*C1; C2 ~~ 1*C2
E1 ~~ 1*E1; E2 ~~ 1*E2
# 환경(C)의 상관은 항상 1
C1 ~~ 1*C2
# 환경(E)은 독립
E1 ~~ 0*E2
# 유전(A)의 상관은 그룹별로 다름 (아래 group.partial로 처리하거나 별도 명시)
# MZ에서는 1.0, DZ에서는 0.5여야 함.
# 이를 위해 phantom variable 기법을 쓰거나 공분산 행렬을 직접 제약해야 함.
'
[해설] 위 코드는 개념적 이해를 돕기 위한 것입니다. 실제 lavaan이나 OpenMx를 쓸 때는 상관계수 를 MZ 그룹 데이터에는 1.0, DZ 그룹 데이터에는 0.5로 고정값(fixed parameter)으로 할당하여 분석합니다.
결과를 해석하면:
(Heritability): 분산 설명력. 예: 0.5 (수학 점수의 50%는 유전)
(Shared Env): 예: 0.3 (30%는 가정환경)
(Unique Env): 예: 0.2 (20%는 개인 노력/오차)
4. 확장된 모델: 교육학적 적용
단순히 성적 하나만 보는 것이 아니라, 더 복잡한 교육 현상을 설명하기 위해 모델을 확장할 수 있습니다.
4.1 다변량 모델: 수학과 물리의 관계 (Cholesky 분해)
수학을 잘하는 학생이 물리도 잘합니다. 이 상관관계()가 유전 때문일까요, 환경 때문일까요?
Cholesky 분해: 변수 간의 공분산을 유전적 공분산()과 환경적 공분산()으로 분해합니다.
발견: 우울과 불안의 관계 연구처럼, 수학과 물리의 높은 상관은 대부분 유전적 요인(Pleiotropy, 다면발현)에 기인할 수 있습니다. 즉, ‘논리적 사고 유전자’가 수학과 물리에 동시에 영향을 미치는 것입니다.
4.2 종단적 모델: 성장의 비밀 (Growth Curve Model)
초등학교부터 고등학교까지 성적의 변화 추이를 봅니다.
잠재 성장 모형: 초기값(Intercept)과 변화율(Slope)을 추정합니다.
연구 결과: 성인기의 인지 능력 수준(Intercept)은 유전적 영향이 크지만, 변화율(감퇴 속도 등)은 비공유 환경의 영향이 클 수 있습니다. 즉, “출발선은 유전이 결정하지만, 달리는 과정은 환경이 좌우한다”는 해석이 가능합니다.
4.3 인과관계의 방향 (Direction of Causation, DoC)
“불안해서 성적이 떨어지는가(A→B), 성적이 나빠서 불안해지는가(B→A)?”
DoC 모델: 쌍둥이 데이터를 이용하면 두 변수 간의 인과 방향을 통계적으로 검증할 수 있습니다.
만약 라면, 유전적 연관성이 높은 형제일수록 교차 상관(Cross-trait cross-relative correlation)이 높게 나타나는 패턴을 이용합니다.
5. 고급 주제: 유전자와 환경의 상호작용 (GxE, rGE)
교육에서 가장 중요한 부분입니다. 유전과 환경은 독립적이지 않습니다.
5.1 유전자-환경 상관 (rGE)
유전자가 환경에 노출되는 방식에 영향을 줍니다.
수동적(Passive) rGE: 똑똑한 부모가 똑똑한 유전자를 물려주면서 동시에 책이 많은 환경도 제공함.
능동적(Active) rGE: 음악적 재능을 가진 아이가 스스로 밴드 동아리에 가입하고 연습 시간을 늘림.
유발적(Evocative) rGE: 외향적인 아이가 교사의 관심을 더 많이 끌어내어 더 많은 피드백을 받음.
5.2 유전자-환경 상호작용 (GxE)
환경에 따라 유전자의 영향력이 달라집니다.
예시: 좋은 교육 환경(E)에서는 유전적 잠재력(A)이 성적 차이로 잘 드러나지만(높은 유전력), 열악한 환경에서는 타고난 재능이 있어도 발현되지 못해 유전력이 낮아질 수 있습니다. (Scarr-Rowe 가설)
Purcell(2002)의 모델을 사용하여 환경 변수(예: 부모의 SES)가 A, C, E 경로를 조절하는지(Moderation) 검증할 수 있습니다.
6. 결론: 교육자를 위한 시사점
GCSM은 복잡한 수식으로 보이지만, 교육자에게 주는 메시지는 명확합니다.
유전은 운명이 아닙니다. SEM을 통해 우리는 환경(C, E)이 설명하는 분산의 크기를 알 수 있습니다.
개별화 교육의 필요성. 비공유 환경(E)의 영향력은 학생마다 겪는 경험이 다름을 의미합니다.
다변량적 접근. 한 과목의 부진이 다른 과목과 유전적으로 연결되어 있는지(공통 경로 모형 등) 파악하여 근본적인 지원을 할 수 있습니다.
구조방정식은 단순한 인과관계 분석을 넘어, 인간 발달의 복잡한 메커니즘인 유전과 환경의 춤(dance)을 악보(수식)로 그려내는 강력한 도구입니다.
참고 문헌
Balbona, J. V., Kim, Y., & Keller, M. C. (2021). Estimation of parental effects using polygenic scores. Behavior Genetics, 51, 264–278.
Boomsma, D. I., Busjahn, A., & Peltonen, L. (2002). Classical twin studies and beyond. Nature Reviews Genetics, 3(11), 872–882.
Falconer, D. S., & Mackay, T. F. C. (1996). Introduction to quantitative genetics (4th ed.). Pearson.
Martin, N. G., & Eaves, L. J. (1977). Genetic analysis of covariance structure. Heredity, 38, 79–95.
Plomin, R., DeFries, J. C., Knopik, V. S., & Neiderhiser, J. M. (2013). Behavioral genetics (6th ed.). Worth.
Purcell, S. (2002). Variance components models for gene-environment interaction in twin analysis. Twin Research, 5(6), 554–571.
Rijsdijk, F. V., Vernon, P. A., & Boomsma, D. I. (2002). Application of hierarchical genetic models to Raven and WAIS subtests: A Dutch twin study. Behavior Genetics, 32(3), 199–210.
안녕하세요! 이번 내용은 “이원 관계(Dyadic Data)의 역동성을 평가하기 위한 종단 모형”입니다.
제목이 다소 어렵게 느껴질 수 있지만, 걱정하지 마세요. 우리 교육 현장에는 수많은 ‘관계’가 존재합니다. 교사와 학생, 상담사와 내담자, 또는 학습 동료 간의 관계가 시간에 따라 어떻게 변하고 서로 영향을 주고받는지 수학적으로 모델링하는 방법을 아주 쉽게 풀어서 설명해 드리겠습니다.
본 챕터에서 다루는 연속시간 미분방정식(Differential Equation Models)은 매우 고급 통계 기법으로 이 모형을 구현할 수 있는 표준 도구인 R을 사용하여 교육적 상황을 가정한 모의 데이터를 생성하고 분석하는 과정을 보여드리겠습니다.
1. 교육 현장에서의 ‘관계’와 ‘시간’
사회과학과 행동과학 연구는 종종 여러 개체 간의 관계에 초점을 맞춥니다. 여기서 “이원 관계(Dyadic relationship)”란 두 개체, 예를 들어 부모-자녀, 남편-아내, 그리고 교육적으로는 교사-학생이나 동료 학습자 간의 관계를 의미합니다.
이 두 사람의 심리적, 행동적 과정이 시간에 따라 어떻게 진화하는지 평가하기 위해 우리는 데이터를 수집합니다.
패널 데이터(Panel Data): 띄엄띄엄 몇 번 측정하는 경우 (예: 학기 초, 학기 말).
집중 종단 데이터(Intensive Longitudinal Data): 짧은 기간 동안 집중적으로 측정하는 경우 (예: 수업 시간 동안의 실시간 상호작용).
우리의 목표는 두 구성원 간의 시간적 상호작용 순서를 파악하고, 서로가 서로에게 어떻게 영향을 미치는지 인과관계를 추론하는 것입니다.
1.1 이산 시간(Discrete Time) vs. 연속 시간(Continuous Time)
전통적인 구조방정식(SEM)은 주로 이산 시간 모형을 사용합니다. 이는 시간을 정수(1회차, 2회차…)로 봅니다. 하지만 이 방식은 “측정 간격이 동일하다”는 가정을 전제로 하는데, 현실에서는 지키기 어렵습니다.
반면, 오늘 우리가 다룰 미분방정식 모형(Differential Equation Models)은 연속 시간을 사용합니다.
시간은 실(Real) 수로 표현됩니다.
변화는 속도나 가속도와 같은 미분(Derivative)으로 표현됩니다.
측정 간격이 불규칙해도(예: 학생이 편한 시간에 응답하는 경우) 문제가 없습니다.
무엇보다 변화의 과정이 ‘멈추지 않고 계속된다’는 자연 현상을 더 잘 반영합니다.
본 챕터에서는 교육적 상황에 적용할 수 있는 4가지 주요 역동 모형을 R 코드와 함께 살펴보겠습니다.
2. 협력과 조절의 모형 (Models of Cooperation)
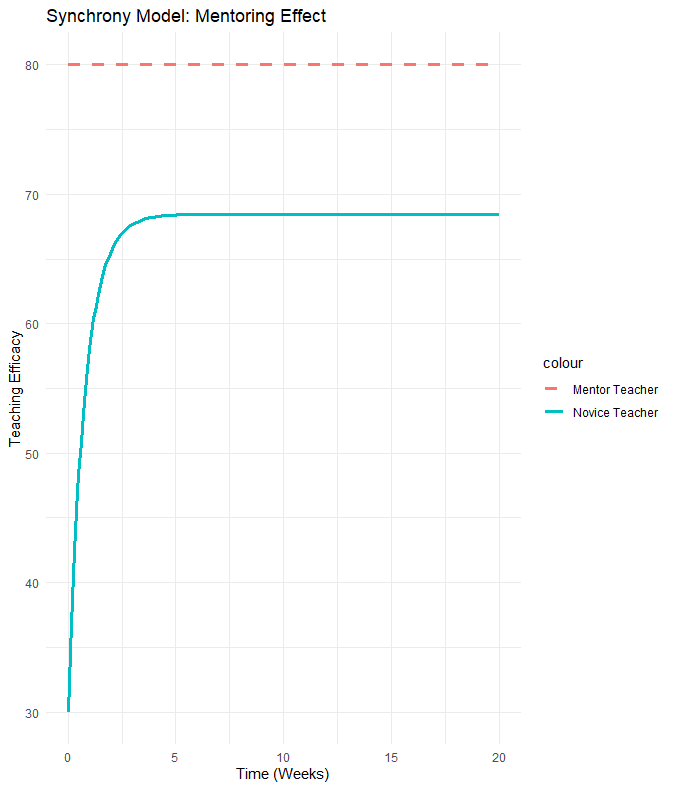
2.1 동기화 모형 (Synchrony Model)
이 모형은 두 사람이 서로의 행동이나 목표(이상적 상태)에 맞춰 자신의 상태를 조정하는 과정을 설명합니다.
모형 수식
: 두 사람의 현재 상태.
: 각자의 이상적인 목표 상태(평형점).
: 자신의 목표를 향해 얼마나 빨리 나아가는가 (자기 조절).
: 상대방의 상태에 얼마나 영향을 받아 변화하는가 (상호 조절).
[교육적 예시] 신규 교사와 멘토 교사
상황: 열정적이지만 경험이 부족한 ‘신규 교사()’와 노련한 ‘멘토 교사()’가 있습니다.
시나리오: 신규 교사는 멘토 교사의 높은 수업 효능감을 닮아가려 합니다(). 반면 멘토 교사는 이미 안정되어 있어 신규 교사에게 크게 영향을 받지 않습니다(). 이를 단방향 소통(Unidirectional Communication)이라고 볼 수 있습니다.
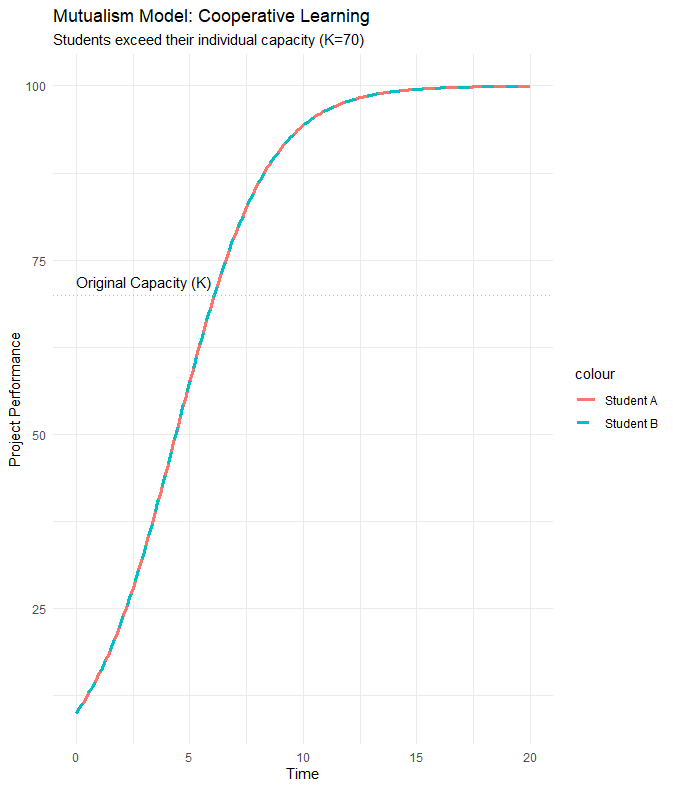
3.1 직접 간섭 경쟁 모형 (Competition by Direct Interference)
상리공생 모형과 수식은 거의 같지만, 상호작용 항의 부호가 반대입니다. 상대방의 존재가 나의 성장을 방해합니다.
모형 수식
여기서 항은 상대방이 존재할수록 나의 성장률을 갉아먹는다는 것을 의미합니다.
[교육적 예시] 상대평가와 등수 경쟁
상황: 전교 1등을 두고 다투는 학생 A와 학생 B.
시나리오: 한 학생의 성적이 오르면 심리적 압박감이나 자원(선생님의 관심 등)의 분산으로 인해 다른 학생의 성취도가 저해될 수 있습니다. 값이 크다면 한 명은 결국 도태(성취도 하락)될 수도 있습니다.
4. 음의 피드백 모형 (Negative Feedback Model)
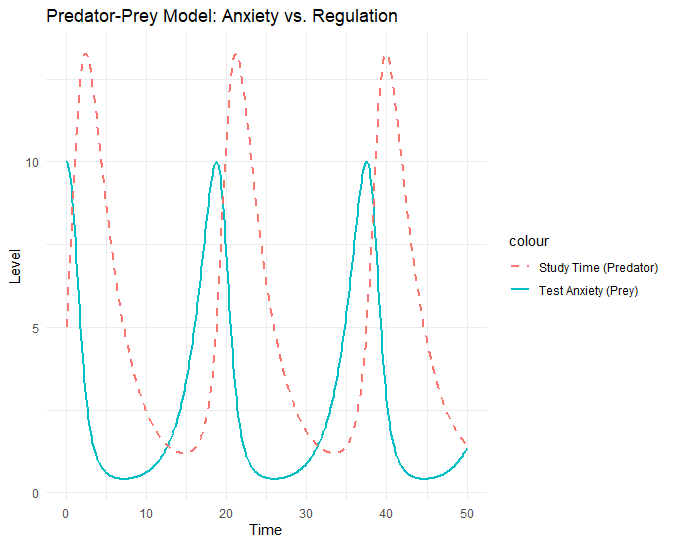
4.1 포식자-피식자 모형 (Predator-Prey Model)
생태학의 고전적인 로트카-볼테라(Lotka-Volterra) 모형입니다. 피식자(먹이)가 늘어나면 포식자가 늘어나고, 포식자가 늘어나면 피식자가 줄어드는 순환 고리를 가집니다. 교육심리학에서는 자기 조절(self-regulation)이나 감정의 기복을 설명할 때 유용합니다.
모형 수식
[교육적 예시] 시험 불안(Prey)과 공부 시간(Predator)
Prey (): 시험 불안 (또는 미루는 습관)
가만히 두면 자연적으로 증가합니다(불안이 스멀스멀 올라옴).
Predator (): 공부 투입 시간 (집행 기능)
불안이 높아지면( 증가), 위기감을 느껴 공부를 시작합니다( 증가).
공부를 하면( 높음), 불안이 잡아먹혀 줄어듭니다( 감소).
불안이 사라지면, 다시 공부를 안 하고 놉니다( 감소, 자연 소멸 ).
결과적으로 두 변수는 주기적인 파동(Oscillation)을 그리게 됩니다.
R 시뮬레이션
R
# 모델 정의 (포식자-피식자)
predator_prey_model <- function(t, state, parameters) {
with(as.list(c(state, parameters)), {
# x1: 시험 불안(Prey), x2: 공부 시간(Predator)
dx1 <- r*x1 - c*x1*x2
dx2 <- b*x1*x2 - m*x2
list(c(dx1, dx2))
})
}
# 파라미터
pars_pp <- c(r = 0.5, # 불안의 자연 증가율
c = 0.1, # 공부가 불안을 감소시키는 효율
b = 0.1, # 불안이 공부를 유발하는 효율
m = 0.3) # 공부 중단(망각/휴식) 비율
state_pp <- c(x1 = 10, x2 = 5) # 초기값
times <- seq(0, 50, by = 0.1)
out_pp <- ode(y = state_pp, times = times, func = predator_prey_model, parms = pars_pp)
out_pp_df <- as.data.frame(out_pp)
# 그래프
ggplot(out_pp_df, aes(x = time)) +
geom_line(aes(y = x1, color = "Test Anxiety (Prey)"), size = 1) +
geom_line(aes(y = x2, color = "Study Time (Predator)"), size = 1, linetype = "dashed") +
labs(title = "Predator-Prey Model: Anxiety vs. Regulation",
y = "Level", x = "Time") +
theme_minimal()
해석: 그래프는 파도처럼 출렁입니다. 학생의 상태가 안정되지 않고, ‘불안해서 공부함 안심되어서 공부 안 함 다시 불안해짐’의 사이클을 반복하는 현상을 수학적으로 보여줍니다.
우리는 이 장을 통해 이원 관계(Dyadic Data)를 분석하는 4가지 강력한 도구를 살펴보았습니다.
동기화 모형: 멘토링 관계처럼 서로 닮아가는 과정.
상리공생 모형: 협동 학습을 통해 시너지를 내는 과정.
경쟁 모형: 상대평가 상황에서 서로를 억제하는 과정.
포식자-피식자 모형: 감정과 학습 조절 간의 순환적인 역동.
이러한 모형들은 전통적인 SEM과 달리, 시간의 흐름 속에서 변수들이 어떻게 ‘변화’하는지 그 자체를 미분방정식()으로 설명합니다. 데이터 수집 기술의 발달로 교육 현장에서도 스마트 기기를 이용한 실시간 데이터(EMA) 수집이 가능해졌습니다. 여러분도 이러한 모형을 활용하여 단순한 상관관계를 넘어, 교육적 상호작용의 ‘역동적 메커니즘’을 밝혀내는 연구에 도전해 보시길 바랍니다.
참고문헌 (References)
Chambliss, D. F., & Schutt, R. K. (2018). Making sense of the social world: Methods of investigation (6th ed.). Thousand Oaks, CA: Sage.
Chen, M., Song, H., & Ferrer, E. (2026). Longitudinal Models for Assessing Dynamics in Dyadic Data. In Chapter 34 (pp. 634-645).
Cole, P. M., Bendezú, J. J., Ram, N., & Chow, S.-M. (2017). Dynamical systems modeling of early childhood self-regulation. Emotion, 17(4), 684–699.1
Felmlee, D. H., & Greenberg, D. F. (1999). A dynamic systems model of dyadic interaction. Journal of Mathematical Sociology, 23(3), 155–180.
Ferrer, E., & Steele, J. (2014). Differential equations for evaluating theoretical models of dyadic interactions. In P. C. Molenaar, R. M. Lerner, & K. M. Newell (Eds.), Handbook of developmental systems theory and methodology (pp. 345–368). New York: Guilford Press.
Gottman, J., Swanson, C., & Murray, J. (1999). The mathematics of marital conflict: Dynamic mathematical nonlinear modeling of newlywed marital interaction. Journal of Family Psychology, 13(1), 3–19.
Kot, M. (2001). Elements of mathematical ecology. Cambridge, UK: Cambridge University Press.
Lotka, A. J. (1925). Elements of physical biology. Baltimore: Williams & Wilkins.
Oud, J. H. L., & Singer, H. (2008). Continuous time modeling of panel data: SEM versus filter techniques. Statistica Neerlandica, 62(1), 4–28.
WaurimaL의 한마디: 여러분, 수식이 나와서 당황하셨죠? 하지만 수식은 현상을 명확하게 기술하기 위한 언어일 뿐입니다. R 코드를 직접 돌려보면서 그래프가 어떻게 변하는지 확인해 보세요. 그 과정에서 교육적 통찰을 얻으실 수 있을 겁니다.
안녕하세요. 이번 주제는 교육 현장에서 학생들의 심리적 특성이 시간이 지남에 따라 어떻게 변화하는지를 정밀하게 분석할 수 있는 잠재 특성-상태 모형(Latent Trait-State Models, LTS)입니다.
많은 연구자가 학생의 ‘학업 열의’나 ‘자아효능감’을 측정할 때, 이것이 변하지 않는 학생 고유의 기질(Trait)인지, 아니면 그날의 기분이나 환경에 따라 변하는 상태(State)인지 고민합니다. 과거에는 이 둘을 이분법적으로 보았지만, 현대 통계학은 이 두 가지가 공존한다고 봅니다.
1. 변하는 것과 변하지 않는 것
교육학 데이터를 다루다 보면 동일한 학생을 여러 시점에 걸쳐 추적 조사(종단 연구)하게 됩니다. 이때 우리가 얻는 점수는 두 가지 성분의 합으로 볼 수 있습니다.
시간 불변 성분 (Time-Invariant Component, ): 흔히 ‘특성(Trait)’이라고 부릅니다. 시간이 흘러도 변하지 않는 학생의 고유한 기준점입니다. 1년이 지나도, 2년이 지나도 개인차의 상관관계는 1.0이라고 가정합니다.
시간 가변 성분 (Time-Varying Component, ): 흔히 ‘상태(State)’ 또는 ‘상황(Occasion)’이라고 부릅니다. 특정 시점에만 영향을 미치는 변동성입니다. 이 성분은 시간이 지날수록 상관관계가 낮아지는 자기회귀(Autoregressive) 속성을 가집니다.
이 장의 목표는 관측된 점수에서 이 두 가지 성분을 분리해 내는 구조방정식 모형(SEM)을 배우는 것입니다.
2. 기본 모형: 단변량 특성-상태-오차 모형 (Kenny-Zautra)
가장 기초적인 모형은 Kenny와 Zautra(1995)가 제안한 모형입니다.
2.1 개념
이 모형은 각 시점()마다 하나의 측정 변수()만 있을 때 사용합니다.
여기서 는 측정 오차입니다. 는 이전 시점의 에 영향을 받는 자기회귀 구조를 가집니다().
2.2 한계점
이 모형은 단순하고 우아하지만, 실제 분석에서는 자주 실패합니다.
수렴이 잘 안 되거나 범위를 벗어난 추정치(Heywood case)가 나오기 쉽습니다.
안정적인 결과를 얻으려면 표본 크기가 매우 커야 하고(500명 이상 권장), 4번 이상의 측정 시점이 필요합니다.
따라서 우리는 더 강력하고 안정적인 다변량 모형으로 넘어갑니다.
3. 다변량 특성-상태-상황 (Trait-State-Occasion, TSO) 모형
교육 연구에서는 보통 하나의 구성개념을 측정하기 위해 여러 개의 문항(예: 학업열의 1, 2, 3번 문항)을 사용합니다. 이를 활용한 것이 TSO 모형입니다.
3.1 모형의 구조
이 모형은 각 시점()의 잠재변수()를 추출한 뒤, 이 잠재변수를 다시 와 로 분해합니다.
이 모형의 장점은 측정 오차를 잠재변수 단계에서 미리 걸러내기 때문에, 와 의 분산을 더 정확하게 추정할 수 있다는 점입니다.
4. 실습: 가상의 교육 데이터 시나리오
여러분의 이해를 돕기 위해 가상의 고등학교 데이터를 생성하여 실습해 보겠습니다.
4.1 시나리오: “우리 학교 학생들은 학교를 얼마나 좋아하는가?”
연구 주제: 고등학생의 ‘학교 소속감(School Belonging)’ 변화 연구
대상: 고등학교 1학년 신입생 500명
기간: 1학년 1학기부터 2학년 2학기까지 총 4학기 (4 Waves)
측정 도구: 학교 소속감 척도 3문항 (Item 1, 2, 3)
Item 1: 나는 이 학교의 일원이라고 느낀다.
Item 2: 나는 학교에 오면 마음이 편하다.
Item 3: 선생님과 친구들은 나를 존중해 준다.
가정:
학생마다 타고난 사교성(Trait, )이 존재함.
학기마다 담임선생님이나 짝꿍에 따라 소속감(State, )이 변동함.
지난 학기의 기분이 이번 학기에 영향을 줌(Autoregression).
4.2 데이터 생성 및 분석 도구 (R & jamovi)
jamovi 자체에는 복잡한 종단 구조방정식을 위한 메뉴가 없지만, SEMLj 모듈(lavaan 기반)을 설치하면 분석이 가능합니다. 혹은 R의 lavaan 패키지를 직접 사용할 수도 있습니다.
아래는 R을 사용하여 이 시나리오에 맞는 데이터를 생성하고 분석하는 코드입니다. 이 코드를 RStudio에서 실행하거나, 생성된 데이터를 jamovi로 불러와 분석할 수 있습니다.
R
# 필수 패키지 로드
if(!require(lavaan)) install.packages("lavaan")
if(!require(MASS)) install.packages("MASS")
set.seed(2026) # 재현성을 위한 시드 설정
# 1. 데이터 생성 시뮬레이션
N <- 500 # 표본 크기 (안정적 추정을 위해 500명 설정)
Waves <- 4
# 잠재 변수 생성
# Trait (I): 시간 불변 성분 (평균 0, 분산 0.5)
Trait <- rnorm(N, 0, sqrt(0.5))
# State (V): 시간 가변 성분 (자기회귀 구조)
V <- matrix(0, N, Waves)
beta <- 0.4 # 자기회귀 계수 (이전 시점이 다음 시점에 미치는 영향)
V[,1] <- rnorm(N, 0, sqrt(0.5)) # 첫 시점
for(t in 2:Waves){
# Vt = beta * V(t-1) + disturbance
V[,t] <- beta * V[,t-1] + rnorm(N, 0, sqrt(0.5 * (1 - beta^2)))
}
# 관측 변수 (Y) 생성: Y = Loading*L + Error
# L = Trait + State
Data <- data.frame(ID = 1:N)
loadings <- c(1.0, 0.9, 0.8) # 문항별 요인적재량 (비등가 가정)
for(t in 1:Waves){
Latent_L <- Trait + V[,t]
for(k in 1:3){ # 3개의 문항
# 측정 오차 추가
error <- rnorm(N, 0, 0.3)
# 변수명 생성 (예: T1_Item1)
var_name <- paste0("T", t, "_Item", k)
Data[[var_name]] <- loadings[k] * Latent_L + error
}
}
# 생성된 데이터 확인
head(Data)
write.csv(Data, "School_Belonging_Longitudinal.csv", row.names=FALSE)
이제 위에서 만든 데이터를 가지고 실제 TSO 모형을 분석해 봅니다. TSO 모형은 문법이 다소 복잡하므로 꼼꼼히 작성해야 합니다.
5.1 분석 전략: 비등가 측정 및 공유된 방법 변량
초기 TSO 모형은 모든 문항의 영향력이 같다고 가정(타우-동등)했으나, 이는 현실적이지 않습니다. 또한, 같은 문항을 반복 측정하면 방법 효과(Method Effect)가 발생하여 오차끼리 상관이 생깁니다. 이를 반영한 상관된 고유성(Correlated Uniqueness, CU) 모델을 사용해야 편의(bias)를 줄일 수 있습니다.
5.2 lavaan 문법 (jamovi의 SEMLj 모듈에 붙여넣기)
R
# TSO Model Syntax
# 1. 각 시점(Wave)의 잠재변수(L) 정의 (Latent Variables)
L1 =~ 1*T1_Item1 + T1_Item2 + T1_Item3
L2 =~ 1*T2_Item1 + T2_Item2 + T2_Item3
L3 =~ 1*T3_Item1 + T3_Item2 + T3_Item3
L4 =~ 1*T4_Item1 + T4_Item2 + T4_Item3
# 2. 측정 불변성 가정 (Factor Loadings Equality across waves)
# 같은 문항은 시간이 지나도 같은 요인 적재량을 가져야 함
L1 =~ l2*T1_Item2 + l3*T1_Item3
L2 =~ l2*T2_Item2 + l3*T2_Item3
L3 =~ l2*T3_Item2 + l3*T3_Item3
L4 =~ l2*T4_Item2 + l3*T4_Item3
# 3. 측정 오차의 공분산 (Correlated Uniqueness) - 방법 효과 통제
T1_Item1 ~~ T2_Item1 + T3_Item1 + T4_Item1
T2_Item1 ~~ T3_Item1 + T4_Item1
T3_Item1 ~~ T4_Item1
T1_Item2 ~~ T2_Item2 + T3_Item2 + T4_Item2
T2_Item2 ~~ T3_Item2 + T4_Item2
T3_Item2 ~~ T4_Item2
T1_Item3 ~~ T2_Item3 + T3_Item3 + T4_Item3
T2_Item3 ~~ T3_Item3 + T4_Item3
T3_Item3 ~~ T4_Item3
# 4. 특성(Trait)과 상태(State)로 분해
# Trait (I)는 모든 시점의 L에 동일한 영향(1.0)을 미침
Trait =~ 1*L1 + 1*L2 + 1*L3 + 1*L4
# State (V) 정의: L = I + V 이므로, L을 구성하는 잔차(residual)가 곧 State가 됨
# 하지만 lavaan에서는 별도의 State 잠재변수를 만드는 것이 명확함.
# 여기서는 L의 잔차를 V로 개념화하는 방식을 주로 씀.
# 더 명시적인 TSO 모델링을 위해 State 잠재변수(S)를 정의함.
S1 =~ 1*L1
S2 =~ 1*L2
S3 =~ 1*L3
S4 =~ 1*L4
# 5. Trait와 State의 관계 설정
# Trait와 State는 서로 독립
Trait ~~ 0*S1 + 0*S2 + 0*S3 + 0*S4
# 6. State의 자기회귀 구조 (Autoregression)
S2 ~ beta*S1
S3 ~ beta*S2
S4 ~ beta*S3
# 7. 식별을 위한 제약 조건 (Trait 분산 추정, State 잔차 분산 등)
Trait ~~ NA*Trait # Trait 분산 자유 추정
S1 ~~ S1 # 첫 시점 State 분산 자유 추정
[해석 팁]
Trait의 분산: 학생 고유의 ‘학교 소속감’ 기질이 얼마나 차이가 나는지 보여줍니다.
State의 자기회귀 계수(beta): 이전 학기의 소속감이 다음 학기로 얼마나 이월되는지 보여줍니다. 이 값이 1에 가까우면 변화가 거의 없는 것이고, 0에 가까우면 매 학기 새롭게 리셋되는 것입니다.
오차 상관: 문항 자체의 특성 때문에 생기는 상관관계를 제거하여 순수한 Trait와 State를 발라내는 역할을 합니다.
6. 심화: 잠재 평균을 포함한 확장된 TSO 모형
단순히 분산(변동성)만 보는 것이 아니라, “어떤 집단이 전반적으로 소속감이 더 높은가?”를 알고 싶다면 평균 구조(Mean Structure)를 포함해야 합니다.
6.1 연구 질문의 확장
남학생과 여학생 간에 ‘학교 소속감’의 Trait 평균()에 차이가 있는가?
특정 시점(예: 2학년 1학기)에 소속감의 State 평균()이 급격히 떨어지는가?
6.2 분석 방법
다집단 분석(Multi-group analysis)을 수행합니다. 제약 조건은 들의 평균 합을 0으로 설정하여, 의 평균이 전체 기간의 ‘그랜드 평균(Grand Mean)’을 의미하도록 합니다.
결과 해석 예시:
“분석 결과, 여학생 집단이 남학생 집단보다 Trait 평균이 유의하게 높았다(). 이는 여학생이 전반적으로 학교에 대한 소속감이 더 높음을 의미한다. 반면, 2학년 1학기의 State 평균은 두 집단 모두에서 음수(-)로 나타났는데, 이는 ‘학업 스트레스’라는 상황적 요인이 학생들의 소속감을 일시적으로 낮추었음을 시사한다.”
7. 결론 및 제언
LTS(잠재 특성-상태) 모형은 교육학 데이터처럼 인간의 심리가 ‘변하지 않는 기질’과 ‘변하는 상태’의 혼합물이라는 점을 통계적으로 명확히 규명해 줍니다.
이 모형을 사용할 때의 핵심 요약:
데이터: 최소 4시점 이상, 표본 수 200명 이상(안정적으로는 500명) 확보하세요.
모형: Kenny-Zautra(단변량)보다는 TSO(다변량) 모형을 우선 고려하세요.
오차: 반복 측정으로 인한 방법 효과(오차 상관)를 반드시 모형에 포함하세요.
여러분의 연구가 학생들의 성장을 단순히 점수의 변화로만 보는 것을 넘어, 그 이면의 안정성(Trait)과 가변성(State)의 역동을 이해하는 깊이 있는 연구가 되기를 바랍니다.
참고문헌
Cole, D. A., & Martin, N. C. (2005). The longitudinal structure of the Children’s Depression Inventory: Testing a latent trait-state model. Psychological Assessment, 17(2), 144–155.
Cole, D. A., Martin, N. C., & Steiger, J. H. (2005). Empirical and conceptual problems with longitudinal trait-state models: Introducing a trait-state-occasion model. Psychological Methods, 10, 3–20.
Ciesla, J. A., Cole, D. A., & Steiger, J. H. (2007). Extending the trait-state-occasion model: How important is within-wave measurement equivalence? Structural Equation Modeling, 14, 77–97.
Herzog, C., & Nesselroade, J. R. (1987). Beyond autoregressive models: Some implication of the trait-state distinction for the structural modeling of developmental change. Child Development, 58, 93–109.
Kenny, D. A., & Zautra, A. (1995). The trait-state-error model for multiwave data. Journal of Consulting and Clinical Psychology, 63, 52–59.
LaGrange, B., & Cole, D. A. (2008). An expansion of the trait-state-occasion model: Accounting for shared method variance. Structural Equation Modeling, 15(2), 241–271.
Spielberger, C. D. (1966). Theory and research on anxiety. In Anxiety and behavior (pp. 23–62). New York: Academic Press.
안녕하세요? 이번에는 “연속 시간 동적 모형(Contnuous-Time Dynamic Models)”에 관한 내용입니다. 우리가 흔히 사용하는 이산 시간(Discrete-Time) 모형(예: SEM, VAR)과 연속 시간 모형(SDE)을 어떻게 연결하고, 왜 연속 시간 관점이 필요한지를 살펴보겠습니다.
jamovi는 훌륭한 도구이지만, 이 챕터에서 다루는 확률 미분 방정식(SDE)이나 칼만 필터 기반의 동적 모형을 직접적으로 수행하는 모듈은 아직 제한적입니다. 따라서 지침에 따라 R 언어를 사용하여 시뮬레이션과 분석을 구현하고, 그 결과와 의미를 교육적 맥락에서 아주 쉽게 설명해 드리겠습니다.
1. 왜 ‘연속 시간’인가?
교육 심리학 연구에서 우리는 종종 “학생들의 학습 동기가 어떻게 변화하는가?” 또는 “시험 불안은 시간에 따라 어떻게 오르내리는가?”와 같은 질문을 던집니다. 전통적인 연구에서는 1학기 초, 1학기 말, 2학기 초와 같이 띄엄띄엄(이산적으로) 데이터를 수집했습니다.
하지만 스마트폰과 웨어러블 기기의 발달로 생태학적 순간 평가(EMA)나 경험 표집법(ESM)이 가능해졌습니다. 이제 우리는 학생들에게 불규칙한 간격(예: 삐삐나 알람이 울릴 때)으로 설문을 보낼 수 있습니다.
여기서 문제가 발생합니다.
이산 시간 모형(Discrete-Time Model): 모든 측정 간격이 동일하다고 가정합니다 (예: 매일 같은 시간).
현실: 철수는 2시간 뒤에 응답하고, 영희는 5시간 뒤에 응답합니다. 간격이 제각각입니다.
이 불규칙함을 무시하고 분석하면 엉뚱한 결론이 나옵니다. 이를 해결하기 위해 시간이 끊어지지 않고 흐른다고 가정하는 연속 시간 동적 모형(Continuous-Time Dynamic Models)이 필요합니다.
2. 핵심 이론: 선형 확률 미분 방정식 (Linear SDE)
이 챕터의 핵심은 SDE(Stochastic Differential Equation)입니다. 수식이 복잡해 보이지만, 교육적 예시로 보면 간단합니다.
2.1. 기본 개념
어떤 학생의 ‘학업 몰입도()’가 시간에 따라 변한다고 가정해 봅시다.
이 식은 다음 두 가지 힘의 싸움입니다:
결정적 변화 (Drift, ): 학생의 몰입도가 본래의 상태로 돌아가려는 힘입니다. 예를 들어, 수업 중 딴생각을 하다가도 다시 집중하려고 노력하는 ‘회복력’과 같습니다.
확률적 변화 (Diffusion, ): 예측할 수 없는 외부 충격입니다. 갑자기 창밖에서 공사 소리가 들리거나, 친구가 말을 거는 것과 같은 ‘노이즈’입니다.
2.2. 이산 시간 모형과의 연결 (EDM)
우리가 수집하는 데이터는 연속적이지 않고 특정 시점()에만 있습니다. SDE를 우리가 분석할 수 있는 형태(이산 시간)로 바꾸면 구조방정식(SEM)의 형태가 됩니다9.
이때 가장 중요한 마법의 공식은 행렬 지수함수(Matrix Exponential)입니다.
이 식은 “연속적으로 흐르는 시간()”을 “우리가 관찰한 시간 간격()”만큼 잘라내어 계수로 만드는 역할을 합니다.
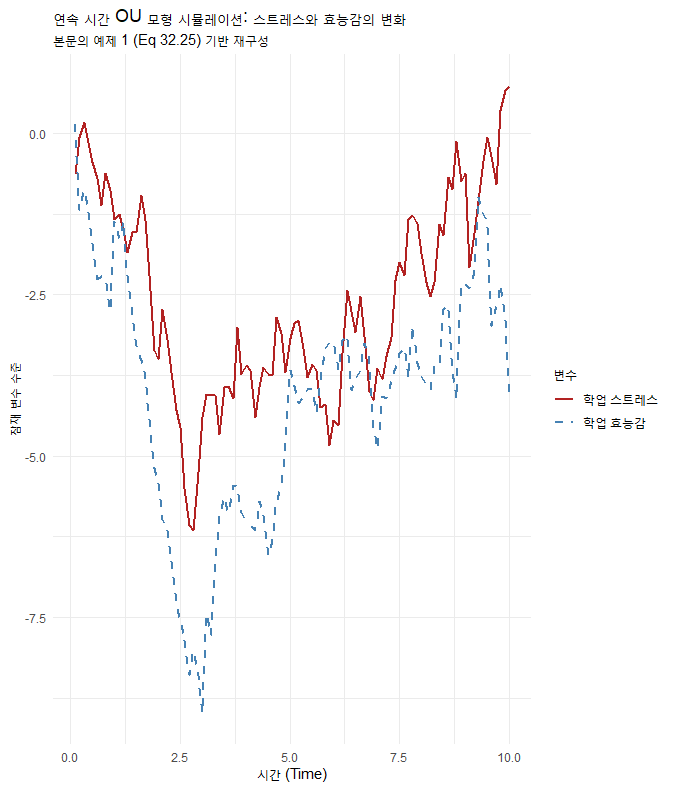
3. 예시 연구 I: 학생의 ‘정서적 안녕감’ 변화 (Ornstein-Uhlenbeck 모형)
첫 번째 예시로 Ornstein-Uhlenbeck (OU) 모형을 살펴보겠습니다. 이 모형은 “항상성(Homeostasis)”을 설명하기 좋습니다. 학생들의 기분은 일시적으로 좋아지거나 나빠질 수 있지만, 결국 자신의 고유한 ‘기본 상태(Set point)’로 돌아오는 경향이 있습니다.
3.1. 가상의 시나리오
우리는 고등학생 100명을 대상으로 시험 기간 일주일 동안 앱을 통해 ‘학업 스트레스’와 ‘학업 효능감’을 측정했습니다. 알림은 무작위로 울렸기 때문에 측정 간격()은 0.1시간부터 10시간까지 다양합니다.
변수 1 (): 학업 스트레스
변수 2 (): 학업 효능감
3.2. 분석 및 시뮬레이션 (R 활용)
such that
위 수식에 제시된 파라미터를 사용하여 데이터를 생성하고, 시각화해 보겠습니다. 본문에서는 dynr 패키지를 사용했지만12, 여기서는 원리를 보여드리기 위해 직접 생성 코드를 작성합니다.
R
3.3. 결과 해석 및 교육적 함의
# R 코드: OU 모형 시뮬레이션 및 시각화
set.seed(1234)
library(ggplot2)
library(MASS) # for mvrnorm
# 1. 파라미터 설정 (본문 Eq 32.25 참조) [cite: 207]
# Drift Matrix (A): 음수일수록 원래 상태로 빨리 돌아옴 (안정적)
A <- matrix(c(-0.1, 0.05,
0.05, -0.1), nrow=2, byrow=TRUE)
# Diffusion Matrix (G): 노이즈의 크기
G <- matrix(c(1.67, 0,
0.036, 1.81), nrow=2, byrow=TRUE) # Q의 제곱근 근사
# 초기값
eta <- c(0, 0)
dt <- 0.1 # 데이터 생성 간격 (아주 짧게 설정하여 연속 시간 흉내)
T_points <- 100
data_list <- list()
# 2. 데이터 생성 (Euler-Maruyama 방법)
for(i in 1:T_points) {
# dW는 정규분포를 따르는 노이즈 [cite: 39]
dW <- rnorm(2, mean=0, sd=sqrt(dt))
# SDE 식 적용: 변화량 = (Drift * dt) + (Diffusion * dW)
d_eta <- (A %*% eta) * dt + (G %*% dW)
eta <- eta + d_eta
data_list[[i]] <- data.frame(Time = i * dt,
Stress = eta[1],
Efficacy = eta[2])
}
df_sim <- do.call(rbind, data_list)
# 3. 시각화
ggplot(df_sim, aes(x=Time)) +
geom_line(aes(y=Stress, color="학업 스트레스"), size=1) +
geom_line(aes(y=Efficacy, color="학업 효능감"), size=1, linetype="dashed") +
theme_minimal() +
labs(title = "연속 시간 OU 모형 시뮬레이션: 스트레스와 효능감의 변화",
subtitle = "본문의 예제 1 (Eq 32.25) 기반 재구성",
y = "잠재 변수 수준", x = "시간 (Time)") +
scale_color_manual(name="변수", values=c("학업 스트레스"="firebrick", "학업 효능감"="steelblue"))
위 그래프(R 코드로 생성 가능)를 보면 스트레스와 효능감이 서로 얽혀서 변하는 것을 볼 수 있습니다.
안정성(Stability): 행렬 의 고유값(Eigenvalues)이 모두 음수라면(본문에서는 가 양의 정부호), 학생의 상태는 시간이 지나면 안정을 찾습니다.
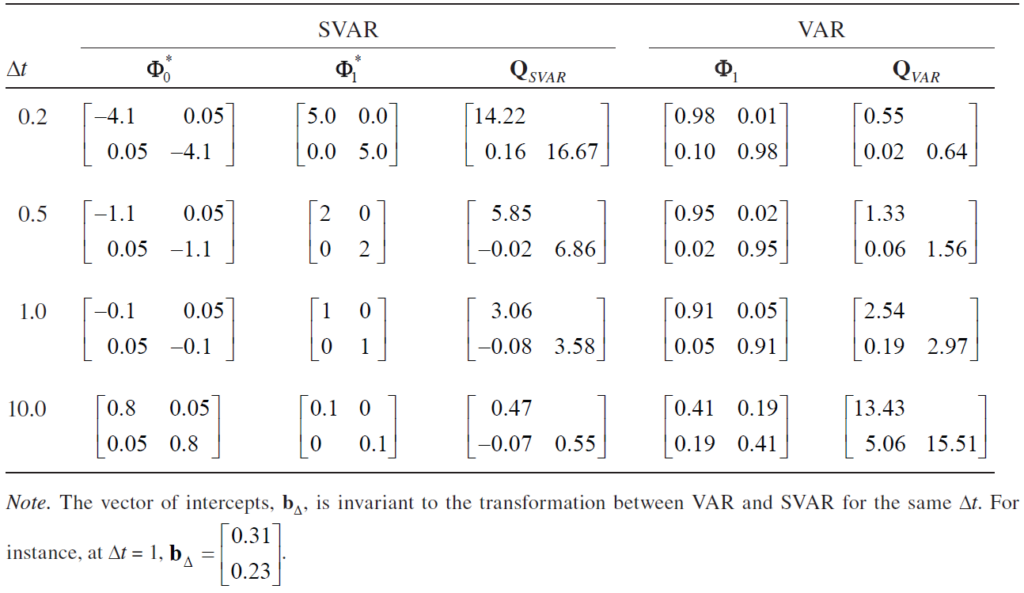
불규칙한 간격의 문제: 만약 우리가 이 데이터를 매우 긴 간격()으로 측정했다면, 스트레스가 효능감에 미치는 즉각적인 영향을 놓치거나 왜곡해서 해석했을 것입니다. 아래 표는 측정 간격이 커질수록 변수 간의 관계(회귀계수)가 어떻게 달라지는지 보여줍니다. 간격이 넓어지면 자기회귀 계수는 작아지고, 교차 회귀 계수의 해석이 모호해질 수 있습니다.
4. 예시 연구 II: 큐빅 스플라인(Cubic Spline)과 결측치 보간
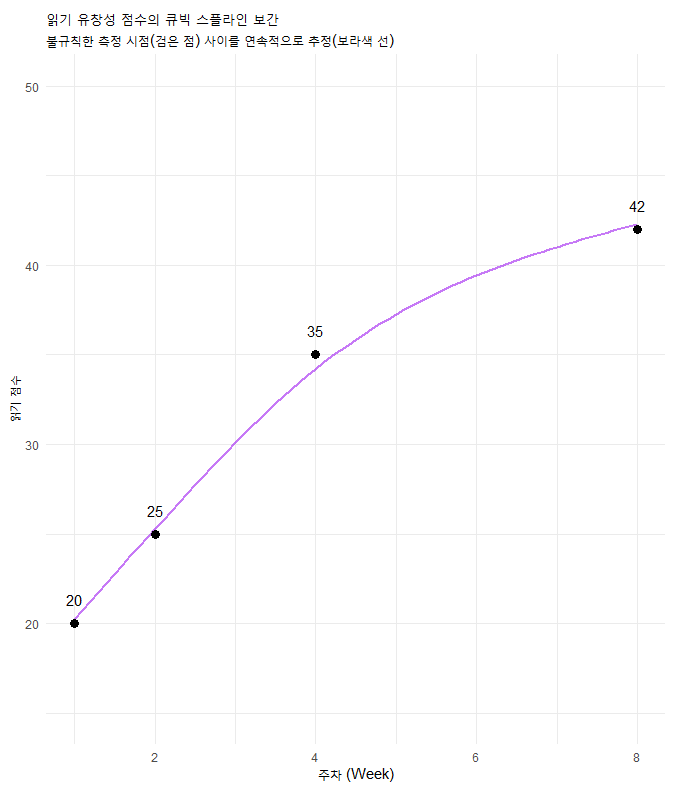
두 번째 예시는 큐빅 스플라인 모형입니다. 이것은 데이터가 아주 불규칙하거나 결측치가 많을 때, 그 사이를 부드러운 곡선으로 채워넣는(Interpolation) 기법입니다.
4.1. 가상의 시나리오: 난독증 학생의 읽기 유창성
난독증 위험군 학생 3명을 대상으로 읽기 유창성 검사를 실시했습니다. 그런데 학교 행사, 결석 등으로 인해 검사 시점이 학생마다 제각각입니다. 이를 억지로 같은 간격으로 취급하면(예: 1회차, 2회차…) 성장 패턴을 오해하게 됩니다.
4.2. 큐빅 스플라인의 원리
이 모형은 2차 SDE로 표현됩니다.
: 학생의 현재 읽기 능력 (Local Level)
: 읽기 능력의 변화 속도 (Local Slope)
이 모형은 측정 오차를 걸러내고, 잠재적인 진짜 성장 곡선을 추정해 줍니다.
4.3. R 시뮬레이션 (불규칙 시점 데이터 보간)
R
# R 코드: 큐빅 스플라인 보간 예시
library(ggplot2)
# 1. 가상 데이터 생성 (불규칙한 시점)
# 학생 A는 1, 2, 4, 8주차에 측정
time_obs <- c(1, 2, 4, 8)
score_obs <- c(20, 25, 35, 42) # 읽기 점수
# 2. 큐빅 스플라인 보간 (SDE의 해석적 해와 유사)
spline_fit <- smooth.spline(time_obs, score_obs, df=3)
# 3. 예측 (1주부터 8주까지 모든 시점)
time_pred <- seq(1, 8, by=0.1)
score_pred <- predict(spline_fit, time_pred)$y
df_raw <- data.frame(Time=time_obs, Score=score_obs)
df_pred <- data.frame(Time=time_pred, Score=score_pred)
# 4. 시각화
ggplot() +
geom_line(data=df_pred, aes(x=Time, y=Score), color="purple", size=1, alpha=0.6) +
geom_point(data=df_raw, aes(x=Time, y=Score), color="black", size=3) +
geom_text(data=df_raw, aes(x=Time, y=Score, label=Score), vjust=-1.5) +
theme_minimal() +
labs(title = "읽기 유창성 점수의 큐빅 스플라인 보간",
subtitle = "불규칙한 측정 시점(검은 점) 사이를 연속적으로 추정(보라색 선)",
x = "주차 (Week)", y = "읽기 점수") +
ylim(15, 50)
4.4. 교육적 함의
결측치 해결: 아래 그림에서 볼 수 있듯이, 불규칙한 데이터를 강제로 등간격으로 가정하면(잘못된 간격), 학생의 성장 궤적이 왜곡됩니다.
정확한 피드백: 스플라인 모형을 통해 우리는 측정이 이루어지지 않은 날의 학생 상태도 추정할 수 있어, 보다 적시에 중재(intervention)를 할 수 있습니다.
5. 결론 및 제언
본 챕터는 다소 난해할 수 있는 연속 시간 모형이 교육 및 심리 연구에 왜 필요한지를 역설하고 있습니다.
현실 반영: 학생들의 삶은 불규칙합니다. 연속 시간 모형은 이를 있는 그대로 반영합니다.
모형의 유연성: SDE 프레임워크를 사용하면 VAR(벡터 자기회귀), SVAR(구조적 벡터 자기회귀) 모형 등으로 자유롭게 변환하여 해석할 수 있습니다.
도구의 확장: Mplus나 R의 dynr, ctsem 같은 도구를 통해 이제는 교육 연구자들도 이러한 고급 분석을 수행할 수 있습니다.
여러분의 연구에서 데이터 수집 간격이 불규칙하거나, 시간에 따른 변화의 ‘메커니즘’을 정밀하게 보고 싶다면, 연속 시간 동적 모형은 강력한 무기가 될 것입니다.
참고문헌
Chow, S.-M., Losardo, D., Park, J., & Molenaar, P. C. M. (2016). Continuous-time dynamic models: Connections to structural equation models and other discrete-time models. In Handbook of Structural Equation Modeling (pp. 597–614).
Boker, S. M., & Graham, J. (1998). A dynamical systems analysis of adolescent substance abuse. Multivariate Behavioral Research, 33, 479-507.
Driver, C., Oud, J., & Voelkle, M. (2017). Continuous time structural equation modeling with R package ctsem. Journal of Statistical Software, 77(5), 1-35.
Oravecz, Z., Tuerlinckx, F., & Vandekerckhove, J. (2011). A hierarchical latent stochastic differential equation model for affective dynamics. Psychological Methods, 16, 468-490.
Ou, L., Hunter, M. D., & Chow, S. (2019). What’s for dynr: A package for linear and nonlinear dynamic modeling in R. The R Journal.
안녕하세요? 이번에는 현대 종단 연구의 정수라고 할 수 있는 동적 구조방정식 모델링(Dynamic Structural Equation Modeling, 이하 DSEM)에 대해 함께 탐구해 보겠습니다.
과거에는 학생들의 변화를 측정하기 위해 학기 초와 학기 말, 두 번의 검사(Pre-Post)에 의존하곤 했습니다. 하지만 학생의 심리나 학습 상태는 매시간, 매일 요동칩니다. DSEM은 이러한 집중 종단 데이터(Intensive Longitudinal Data)를 분석하기 위해 시계열 분석, 다층 모형(MLM), 그리고 구조방정식 모형(SEM)을 하나로 통합한 혁신적인 프레임워크입니다.
오늘 우리는 이 이론을 교육 현장의 예시를 통해 아주 쉽게 풀어보고, 실제로 어떻게 데이터를 다루는지 살펴보겠습니다.
1. DSEM의 핵심: 세 가지 전통의 결합
DSEM은 단순히 복잡한 통계가 아니라, 우리가 데이터를 바라보는 세 가지 관점을 합친 것입니다.
시계열 분석 (): 한 학생이 어제의 학습 무기력에서 오늘 얼마나 영향을 받는지(자기회귀), 또는 어제의 스트레스가 오늘의 학습 참여에 어떤 영향을 주는지(교차 지연)를 분석합니다.
다층 모형 (Multilevel): 학생들마다 스트레스에 반응하는 정도가 다를 수 있습니다. 이러한 개인차를 ‘무작위 효과(Random Effects)’로 다룹니다.
구조방정식 (SEM): 그 개인차(예: 스트레스에 민감한 정도)가 그 학생의 ‘회복탄력성’이라는 잠재 변수 때문은 아닌지, 혹은 성적에 영향을 주는지 분석합니다.
2. 교육 현장 사례: “학습 스트레스와 수업 참여”
이해를 돕기 위해 가상의 시나리오를 만들어 봅시다.
연구 스토리:
어느 고등학교에서 학생들의 ‘수업 참여도(Engagement)’와 ‘학업 스트레스(Stress)’ 사이의 역동을 연구합니다. 100명의 학생에게 스마트폰 앱을 통해 10일간 하루 5번씩 실시간으로 상태를 기록하게 했습니다(경험샘플링법). 연구 중간에 일부 학급에는 ‘명상 프로그램(처치)’을 실시했습니다.
주요 변수 정의
(수업 참여도): 번째 학생의 시점 참여도.
(학업 스트레스): 이전 측정 시점부터 현재까지 겪은 스트레스.
3. 단계별 모델링 분석
DSEM의 유연성을 보여주기 위해 세 가지 단일 수준() 모델부터 시작해 봅시다.
1단계: 단순 회귀 모델 (Model 1)
동일 시점의 스트레스가 참여도에 주는 영향을 봅니다.
교육적 의미: 지금 당장 스트레스를 받으면 지금 수업 참여도가 떨어지는지를 확인합니다.
2단계: 시계열 모델 (Model 2)
여기에 자기회귀(Autoregression, )를 추가합니다.
교육적 의미:관성(Inertia) 개념입니다. 수업에 한 번 집중하기 시작한 학생이 그 상태를 얼마나 유지하는지()를 측정합니다.
3단계: 이변량 시계열 모델 (Model 3)
스트레스와 참여도가 서로 주고받는 영향을 모두 고려합니다.
교육적 의미: 스트레스가 참여도를 낮추기도 하지만(), 반대로 어제 수업에 참여하지 못한 자책감이 오늘 더 큰 스트레스를 유발하는지() 분석합니다.
4. 다층 DSEM과 SEM의 결합
이제 이를 전체 학생으로 확장합니다. 모든 학생의 나 가 같을 순 없겠죠? DSEM은 이 파라미터들을 무작위 슬로프(Random Slopes)로 처리하여 학생마다 다른 값을 갖게 합니다.
또한, 이러한 개인차를 ‘기초 학력’이나 ‘성격’ 같은 변수로 설명할 수 있습니다. 예를 들어, ‘우울감(Depression)’ 점수가 높은 학생일수록 스트레스가 참여도를 떨어뜨리는 효과()가 더 강력하게 나타나는지(교차 수준 상호작용)를 SEM 모델로 검증할 수 있습니다.
5. 실전 데이터 분석 (R 활용)
현재 jamovi의 기본 모듈에는 Mplus 수준의 DSEM을 완벽히 구현하는 기능이 제한적이므로, 학계에서 널리 쓰이는 R의 brms 패키지를 활용한 분석 코드를 제안합니다.
모의 데이터 생성 및 분석 스크립트
R
# 필요한 라이브러리 로드
library(brms)
library(tidyverse)
# 1. 모의 데이터 생성 (100명 학생, 50회 반복 측정)
set.seed(2026)
n_students <- 100
n_timepoints <- 50
sim_data <- expand.grid(student = 1:n_students, time = 1:n_timepoints) %>%
group_by(student) %>%
mutate(
# 학업 스트레스 (X) 생성
stress = arima.sim(list(ar = 0.3), n = n_timepoints) + rnorm(1, 0, 1),
# 수업 참여도 (Y) 생성: 자기회귀 + 스트레스 영향 + 개인차
engagement = 0
)
# 참여도 데이터 생성 (동적 프로세스 반영)
for(i in 2:n_timepoints) {
sim_data <- sim_data %>%
group_by(student) %>%
mutate(engagement = ifelse(time == i,
0.5 * lag(engagement) - 0.3 * stress + rnorm(1, 0, 0.5),
engagement))
}
# 2. DSEM 모델 구성 (자기회귀 및 무작위 효과 포함)
# engagement_t ~ engagement_{t-1} + stress + (1 + engagement_{t-1} + stress | student)
model_formula <- bf(
engagement ~ 1 + lag_engagement + stress + (1 + lag_engagement + stress | student)
)
# 데이터 전처리: 시차 변수(Lag) 생성
sim_data <- sim_data %>%
group_by(student) %>%
mutate(lag_engagement = lag(engagement)) %>%
drop_na()
# 3. 모델 추정 (Bayesian)
# 실제 실행 시 시간이 소요되므로 iterations는 조절 필요
fit_dsem <- brm(
formula = model_formula,
data = sim_data,
family = gaussian(),
cores = 4,
iter = 2000
)
# 4. 결과 시각화
summary(fit_dsem)
plot(conditional_effects(fit_dsem), points = TRUE)
DSEM은 교육 연구자들에게 “학생이 어떻게 변해가는가?”에 대한 현미경 같은 시각을 제공합니다.
치료 및 중재 효과 확인: 명상 프로그램이 학생의 스트레스 민감도()를 실제로 낮추었는지 확인할 수 있습니다.
예측력: 단순히 현재 상태를 아는 것을 넘어, 과거의 패턴을 통해 내일의 학습 위기를 예측할 수 있게 합니다.
DSEM은 아직 새로운 분야이기에 잔차의 정규성 가정 위반이나 모형 적합도 평가 등 해결해야 할 과제들이 남아 있지만, 집중 종단 데이터를 다루는 가장 강력한 도구임은 틀림없습니다.
참고문헌
Asparouhov, T., Hamaker, E. L., & Muthén, B. (2018). Dynamic structural equation modeling. Structural Equation Modeling: A Multidisciplinary Journal, 25(3), 359-388.
Bolger, N., Davis, A., & Rafaeli, E. (2003). Diary methods: Capturing life as it is lived. Annual Review of Psychology, 54, 579-616.
Hamaker, E. L., Asparouhov, T., & Muthén, B. (2022). Dynamic structural equation modeling as a combination of time series modeling, multilevel modeling, and structural equation modeling. In Handbook of Structural Equation Modeling.
Kuppens, P., Allen, N. B., & Sheeber, L. B. (2010). Emotional inertia and psychological maladjustment. Psychological Science, 21(7), 984-991.
Raudenbush, S. W., & Bryk, A. S. (2002). Hierarchical linear models: Applications and data analysis methods (2nd ed.). Sage.
안녕하세요? 이번에는 현대 교육 연구에서 개인의 변화를 추적하고 분석하는 가장 강력한 도구 중 하나인 잠재곡선 모델링(Latent Curve Modeling, LCM)에 대해 깊이 있게 다뤄보겠습니다.
종단적 성장 데이터(Longitudinal growth data)는 동일한 대상을 반복 측정하고, 동일한 척도를 사용하며, 관찰 시점을 정확히 알고 있다는 독특한 특징이 있습니다. 이러한 특징은 교육 현장에서 학생의 성취도 변화나 심리적 발달을 이해하는 데 엄청난 기회를 제공합니다.
이 글은 여러분이 jamovi(또는 R)를 활용해 직접 분석을 수행할 수 있도록 이론부터 실무까지 상세히 안내할 것입니다.
1. 잠재곡선 모델의 기초: 변화를 어떻게 정의할 것인가?
잠재곡선 모델의 핵심 아이디어는 각 개인의 반복 측정된 점수를 ‘개인별 궤적(Individual Trajectory)’으로 이해하는 것입니다. 이는 고전적인 분산 분석(ANOVA)이 집단 평균의 변화에 집중했던 것과 대조적입니다.
1.1 기본 방정식
가장 고전적인 잠재곡선 모델은 반복 측정된 관찰 점수()를 세 가지 성분으로 분해합니다.
잠재 절편(): 개인 의 초기 수준 또는 기준점 점수입니다.
잠재 기울기(): 시간 경과에 따른 개인 의 변화량(성장률)입니다.
잔차(): 특정 측정 시점 에서 발생하는 오차나 고유한 특징입니다.
여기서 기저 계수(, Basis coefficients)는 변화의 형태를 결정합니다. 예를 들어, 4년간 매년 측정했다면 를 [0, 1, 2, 3]으로 고정하여 선형 성장을 가정할 수 있습니다.
2. 분석 프레임워크: SEM vs. MLM
성장 모델은 다층 모델(MLM)이나 구조방정식 모델(SEM) 프레임워크 모두에서 추정 가능하지만, 각각 장단점이 있습니다.
특징
MLM (Multilevel Modeling)
SEM (Structural Equation Modeling)
주요 장점
비선형 궤적 직접 추정 가능, 소표본에 유리(REML 사용)
복잡한 통계 모델의 일부로 포함 가능(예: 2차 요인 모델)
유연성
시점 간 잔차 구조 제약적
다양한 잔차 구조 설정 가능, 적합도 지수 제공
본 내용에서는 모형의 적합도를 평가하고 더 복잡한 인과 관계를 확장하기에 유리한 SEM 접근법에 초점을 맞춥니다.
3. [사례 연구] 초등학생의 어휘력 성장 분석
이론을 실생활에 적용해 봅시다. 한 초등학교에서 1학년부터 4학년까지 동일한 학생 100명을 대상으로 매년 ‘어휘력 검사(Vocabulary Test)’를 실시했다고 가정합시다.
3.1 모의 데이터 생성 배경 (Story)
연구 질문: 학생들의 어휘력은 학년이 올라감에 따라 선형적으로 발달하는가? 초기 어휘력 수준이 높은 학생이 더 빠르게 성장하는가?
데이터 구성: Student_ID, Grade1, Grade2, Grade3, Grade4, Family_SES(가족 사회경제적 지위).
3.2 jamovi/R 분석 가이드
jamovi의 SEMLj 모듈이나 R의 lavaan 패키지를 사용하여 분석을 수행할 수 있습니다.
R을 활용한 선형 성장 모델링 예시 코드:
R
# 1. 필요한 패키지 로드
if(!require(lavaan)) install.packages("lavaan")
library(lavaan)
# 2. 교육현장 모의 데이터 생성 (100명의 학생)
set.seed(2026) # 결과 재현을 위한 설정
n <- 100
# 가상 요인 생성
SES <- rnorm(n, 0, 1) # 사회경제적 지위 (표준화 점수)
intercept <- 50 + 5 * SES + rnorm(n, 0, 2) # 초기치 (SES 영향 포함)
slope <- 3 + 1.5 * SES + rnorm(n, 0, 0.5) # 성장률 (SES 영향 포함)
# 4개 시점 데이터 생성 (선형 성장 가정)
Grade1 <- intercept + rnorm(n, 0, 1)
Grade2 <- intercept + 1 * slope + rnorm(n, 0, 1)
Grade3 <- intercept + 2 * slope + rnorm(n, 0, 1)
Grade4 <- intercept + 3 * slope + rnorm(n, 0, 1)
# 데이터프레임 구축
vocab_data <- data.frame(Grade1, Grade2, Grade3, Grade4, SES)
# 3. 잠재곡선 모델(LCM) 정의
# i(intercept)와 s(slope)를 정의하고 기저 계수를 [0, 1, 2, 3]으로 고정합니다.
lcm_model <- '
i =~ 1*Grade1 + 1*Grade2 + 1*Grade3 + 1*Grade4
s =~ 0*Grade1 + 1*Grade2 + 2*Grade3 + 3*Grade4
# 조건부 모델: SES가 i와 s를 예측
i ~ SES
s ~ SES
'
# 4. 모델 추정 및 결과 보고
fit <- growth(lcm_model, data = vocab_data)
summary(fit, fit.measure = TRUE, standardized = TRUE)
s ~ SES: 이 값이 통계적으로 유의한 양수라면, “가정의 사회경제적 지위가 높을수록 어휘력 성장 속도가 더 빠르다”는 교육적 결론을 내릴 수 있습니다.
4. jamovi에서 수행하는 방법
R 코드가 익숙하지 않다면, jamovi의 SEMLj 모듈을 사용해 보세요.
데이터 준비: 위 R 스크립트로 생성한 vocab_data를 CSV로 저장하여 jamovi에서 엽니다.
모듈 실행: SEMLj -> Syntax Mode 또는 Growth Model 클릭.
변수 배치: Grade1~4를 각 시점(Time points)에 배치합니다.
기저 계수 설정: 학년별로 [0, 1, 2, 3]을 직접 입력하여 선형 모델을 구성합니다.
예측 변수: SES를 Covariates 칸에 넣어 성장에 미치는 영향을 확인합니다.
5. 모델의 단계적 확장과 해석
분석은 보통 간단한 모델에서 시작하여 점진적으로 매개변수를 추가합니다.
5.1 무변화 모델 (Level-only Model)
성장이 없다고 가정하는 모델입니다. 만약 이 모델의 적합도가 나쁘다면(보통 나쁩니다), 이는 학생들의 점수가 시간에 따라 변화했음을 의미합니다.
5.2 선형 성장 모델 (Linear Growth Model)
매년 일정한 속도로 성장한다고 가정합니다.
평균(): 전체 학생의 평균적인 연간 성장률입니다.
변량(): 학생들 간에 성장 속도 차이가 얼마나 큰지 보여줍니다.
공분산(): 초기 수준(절편)과 성장률(기울기) 사이의 관계입니다. 교육적으로는 종종 초기값이 낮은 학생이 더 빨리 성장하는지(보상 효과)를 확인하는 데 쓰입니다.
5.3 잠재 기저 모델 (Latent Basis Model)
변화의 형태를 데이터가 스스로 결정하게 하는 모델입니다. 첫 시점을 0, 마지막 시점을 3으로 고정하고 중간 시점()을 추정합니다. 만약 추정된 값이 1.5, 2.5 등으로 나온다면, 성장이 특정 시기에 더 가속화되었음을 알 수 있습니다.
# 잠재 기저 모델 정의
latent_basis_model <- '
# 절편(i) 정의
i =~ 1*Grade1 + 1*Grade2 + 1*Grade3 + 1*Grade4
# 잠재 기저(s) 정의: 첫 시점 0, 끝 시점 3 고정. 중간은 라벨(L2, L3)을 붙여 추정
s =~ 0*Grade1 + L2*Grade2 + L3*Grade3 + 3*Grade4
# i와 s의 평균 및 분산/공분산 추정 (growth 함수가 자동 수행)
'
# 모델 실행
fit_basis <- growth(latent_basis_model, data = vocab_data)
# 결과 보고
summary(fit_basis, fit.measure = TRUE, standardized = TRUE)
6. 결측치와 시간 지표의 유연성
실제 연구에서는 학생들이 전학을 가거나 특정 검사를 빠뜨리는 경우가 흔합니다.
결측치 처리: SEM 프레임워크는 완전정보 최대우도법(FIML)을 사용하여 결측치가 있는 데이터를 효과적으로 처리합니다. 이는 데이터가 누락된 학생을 제외하지 않고, 남아있는 정보를 모두 사용하여 추정치를 얻는 방식입니다.
가속 종단 설계(Accelerated Longitudinal Study): 짧은 기간 동안 여러 연령대의 코호트를 관찰하여, 장기적인 발달 과정을 짧은 시간 안에 재구성하는 방식입니다. 예를 들어, 1-2학년 집단과 2-3학년 집단을 동시에 관찰하여 1학년부터 3학년까지의 궤적을 연결할 수 있습니다.
7. 성장에 영향을 미치는 요인 (조건부 모델)
학생들의 성장 궤적을 설명하기 위해 시간-불변 예측 변수(Time-invariant predictors)를 추가할 수 있습니다.
위 식에서 사회경제적 지위(SES)가 기울기()의 유의한 예측 요인이라면, “가정 형편이 좋을수록 어휘력 성장 속도가 더 빠르다”는 결론을 내릴 수 있습니다.
8. 결론 및 향후 전망
잠재곡선 모델은 교육 현장의 복잡한 변화를 포착하는 데 필수적인 도구입니다. 최근에는 다음과 같은 고급 모델로 발전하고 있습니다:
동적 SEM(DSEM): 시계열 데이터의 오차 간 자기회귀 효과까지 고려합니다.
성장 혼합 모델(GMM): 서로 다른 성장 궤적을 가진 잠재 집단(예: 상위권, 정체권, 하락권)을 찾아냅니다.
잠재 차이 점수 모델(LDS): 시점 간 변화량 자체의 역동성을 분석합니다.
이 도구들을 통해 여러분의 데이터 속에 숨겨진 변화의 이야기를 명확하게 들려주시길 바랍니다.
참고문헌
Bell, R. Q. (1953). Convergence: An accelerated longitudinal approach. Child Development, 24(3/4), 145–152.
Bell, R. Q. (1954). An experimental test of the accelerated longitudinal approach. Child Development, 25(4), 281–286.
Grimm, K. J., Ram, N., & Estabrook, R. (2017). Growth modeling: Structural equation and multilevel modeling approaches. Guilford Press.
McArdle, J. J. (1988). Dynamic but structural equation modeling of repeated measures data. In J. R. Nesselroade & R. B. Cattell (Eds.), Handbook of multivariate experimental psychology (pp. 561–614). Springer.
Meredith, W., & Tisak, J. (1990). Latent curve analysis. Psychometrika, 55(1), 107–122.
Muthén, B., & Shedden, K. (1999). Finite mixture modeling with mixture outcomes using the EM algorithm. Biometrics, 55(2), 463–469.
Wishart, J. (1938). Growth-rate determinations in nutrition studies with the bacon pig, and their analysis. Biometrika, 30(1/2), 16–28.
안녕하세요? 이번에는 교육 연구에서 집단의 이질성을 파악하는 아주 강력한 도구인 혼합 모형(Mixture Models)에 대해 깊이 있게 다루어 보겠습니다.
과거 아리스토텔레스 시대부터 과학의 기초는 사물을 유사성에 따라 분류하는 것이었습니다. 교육 현장에서도 우리는 학생들을 단순히 ‘전체 평균’으로 보는 것이 아니라, 서로 다른 학습 양식이나 심리적 특성을 가진 여러 잠재적 집단(Latent Groups)으로 이해할 필요가 있습니다.
1. 혼합 모형의 개념과 기초
혼합 모형은 데이터가 여러 개의 하위 분포(Components)가 합쳐진 형태라고 가정하는 통계적 접근법입니다.
1.1. 왜 혼합 모형인가?
전통적인 군집 분석(K-means 등)은 학생을 특정 집단에 ‘딱’ 잘라 배정합니다(Crisp membership). 반면, 혼합 모형은 확률적 소속(Probabilistic membership)을 제공합니다. 예를 들어, 한 학생이 ‘자기주도형’ 집단에 속할 확률이 85%, ‘교사의존형’ 집단에 속할 확률이 15%라고 알려주는 식이죠. 이는 분류의 불확실성을 과학적으로 다룰 수 있게 해줍니다.
1.2. 주요 모델의 유형
심리학과 교육학에서 가장 많이 쓰이는 형태는 다음과 같습니다.
잠재 프로파일 분석 (LPA): 연속형 변수(예: 시험 점수, 자아존중감 척도)를 사용하여 집단을 구분합니다.
잠재 계층 분석 (LCA): 범주형/이분형 변수(예: 예/아니오 설문 응답)를 사용하여 집단을 구분합니다.
2. 모형의 추정과 의사결정
혼합 모형을 성공적으로 구현하기 위해서는 몇 가지 중요한 통계적 결정을 내려야 합니다.
2.1. EM 알고리즘과 지역 최적해(Local Optima)
혼합 모형은 보통 EM(Expectation-Maximization) 알고리즘을 통해 추정됩니다. 이 과정에서 주의할 점은 ‘가장 좋은 해’라고 생각한 결과가 사실은 특정 조건에서만 나타나는 지역 최적해(Local Optima)일 수 있다는 점입니다.
WaurimaL의 팁: 이를 방지하기 위해 무작위 시작값(Random Starts)을 충분히(예: 1,000 ~ 5,000개) 설정하는 것이 필수적입니다. 시작값이 적으면 데이터의 실제 구조를 놓칠 위험이 큽니다.
2.2. 공분산 구조의 결정
데이터의 형태(부피, 모양, 방향)를 어떻게 가정하느냐에 따라 14가지 이상의 모델이 존재합니다.
모델 유형
부피 (Volume)
모양 (Shape)
방향 (Orientation)
특징
EII
동일
구형
해당 없음
가장 제약이 많은 형태 (K-means와 유사)
VII
가변
구형
해당 없음
집단별 크기는 다르지만 모양은 동그라미
VVV
가변
가변
가변
가장 유연하며 데이터에 최적화됨
2.3. 집단 수 선정 (BIC와 ICL)
“우리 반 학생들은 몇 개의 유형으로 나뉘는가?”를 결정할 때 가장 널리 쓰이는 지표는 BIC(Bayesian Information Criterion)입니다. 일반적으로 BIC 값이 가장 작은 모델을 선택합니다. 만약 집단 간 구분이 명확한 모델을 원한다면 ICL(Integrated Completed Likelihood) 지표를 함께 고려하는 것이 좋습니다.
3. 교육 현장의 사례: “학습 동기 프로파일 분석”
이해를 돕기 위해 가상의 고등학생 200명의 데이터를 생성하여 분석해 보겠습니다.
3.1. 모의 데이터 시나리오
변수: 내재적 동기(IM), 외재적 동기(EM), 학습 불안(ANX), 자기효능감(SE)
잠재된 스토리: 1. 고동기형: 모든 점수가 높음. 2. 불안형: 동기는 있으나 불안도가 매우 높음. 3. 무기력형: 모든 점수가 전반적으로 낮음.
3.2. R을 이용한 분석 코드
Jamovi의 snowRMM 모듈로도 가능하지만, 보다 정밀한 제어를 위해 R의 mclust 혹은 mixture 패키지를 권장합니다.
R
# 필요한 패키지 로드
library(mclust)
library(tidyverse)
# 1. 모의 데이터 생성 (교수 재량)
set.seed(2026)
n <- 200
# 세 개의 집단 생성 (고동기, 불안, 무기력)
g1 <- matrix(rnorm(n*0.4*4, mean=4, sd=0.5), ncol=4) # 고동기
g2 <- matrix(rnorm(n*0.3*4, mean=c(3,4,4,3), sd=0.6), ncol=4) # 불안형
g3 <- matrix(rnorm(n*0.3*4, mean=2, sd=0.7), ncol=4) # 무기력
data <- rbind(g1, g2, g3)
colnames(data) <- c("IM", "EM", "ANX", "SE")
write.csv(data,"chap29.csv",row.names = F)
# 2. 혼합 모형 적합 (집단 수 1~5개 테스트)
fit <- Mclust(data, G=1:5)
# 3. 결과 요약 및 집단 수 확인
summary(fit)
# 최적 모델과 집단 수(G) 출력
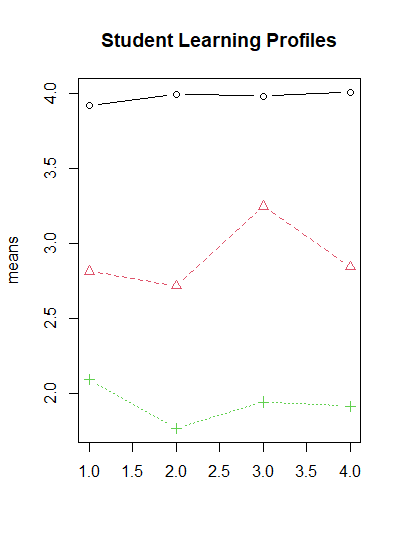
# 4. 시각화: 프로파일 플롯
means <- fit$parameters$mean
matplot(means, type="b", pch=1:fit$G, main="Student Learning Profiles")
# 5. 모형 적합 (예: mclust 사용)
fit1 <- Mclust(data, G=3)
# 6. 1번 집단 80개, 2번 집단 60개, 3번 집단 60개를 하나의 벡터로 만듭니다.
actual_classes <- c(rep(1, 80), rep(2, 60), rep(3, 60))
# 7. 예측된 집단 할당 (MAP 분류)
# 각 관측치를 가장 높은 사후 확률을 가진 집단에 할당합니다.
predicted_classes <- fit1$classification
# 8. 실제 집단 정보와 비교하여 ARI 계산
# actual_classes는 데이터 세트에 포함된 실제 집단 레이블입니다.
final_ari <- adjustedRandIndex(actual_classes, predicted_classes)
# 9. 결과 해석
# 결과 출력
cat("분석 결과 ARI 수치:", final_ari, "\n")
직접적 적용: 실제로 데이터 안에 질적으로 다른 ‘진짜 집단’이 존재한다고 믿는 경우입니다.
간접적 적용: 데이터가 단순히 비정규분포(기울어짐 등)를 띠고 있어서, 이를 설명하기 위해 여러 개의 정규분포를 빌려 쓰는 경우입니다.
대부분의 사회과학 데이터는 후자인 경우가 많습니다. 따라서 ‘집단 분류’ 자체에 매몰되기보다는, 전체적인 데이터의 이질성을 이해하는 수단으로 혼합 모형을 활용해야 합니다.
4.2. 분류 정확도 (ARI)
분석 결과로 나온 집단 분류가 얼마나 정확한지 판단하기 위해 ARI(Adjusted Rand Index)를 확인합니다. ARI가 0.8 이상이면 ‘우수’, 0.65 이상이면 ‘수용 가능’한 수준으로 봅니다.
5. 결론: 연구자를 위한 제언
혼합 모형은 매우 유연하지만, 그만큼 오용하기 쉽습니다.
시각화가 우선입니다: 분석 전 산점도나 요인 점수 분포를 통해 실제로 집단이 나뉠 만한 구조인지 먼저 확인하세요.
이론적 근거를 가지세요: 통계 지표(BIC)가 4개를 추천하더라도, 교육학적 이론으로 설명되지 않는 집단이라면 모형을 재검토해야 합니다.
복제 가능성을 염두에 두세요: 혼합 모형은 과적합(Overfitting)의 위험이 크므로, 다른 샘플에서도 동일한 구조가 나타나는지 확인하는 과정이 필요합니다.
참고문헌 (APA Style)
Bauer, D. J., & Curran, P. J. (2003). Distributional assumptions of growth mixture models: Implications for overextraction of latent trajectory classes. Psychological Methods, 8(3), 338–363.
Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society: Series B (Methodological), 39(1), 1–22.
McLachlan, G. J., & Peel, D. (2000). Finite mixture models. Wiley.
Steinley, D. (2026). Mixture Models. In The SAGE Handbook of Quantitative Methods in Psychology. SAGE. (Original work published 2023)
Steinley, D., & Brusco, M. J. (2011). Evaluating the performance of model-based clustering: Recommendations and cautions. Psychological Methods, 16(1), 63–79.
안녕하세요? 이번에는 ‘표본은 작고 변수는 많은(Small , Large )’ 상황에서의 구조방정식 모델링(Structural Equation Modeling, SEM)입니다. 현장에서 교육 연구를 진행하다 보면 설문 문항(변수)은 수백 개에 달하는데, 특정 소수 집단이나 특수 학교 학생들을 대상으로 하여 표본을 충분히 확보하지 못하는 경우가 비일비재하죠.
이런 고차원적 문제(High-dimensional problems) 상황에서 기존의 통계적 방법론을 그대로 적용하면 어떤 오류가 발생하는지, 그리고 이를 해결하기 위한 최신 기법들은 무엇인지 함께 알아보겠습니다.
1. 작은 표본과 많은 변수의 딜레마
구조방정식(SEM)의 핵심 강점은 측정 오차를 분리하고 잠재 변수 간의 관계를 명확히 추정하는 것입니다. 하지만 본래 SEM은 대표본()과 상대적으로 적은 변수()를 가정하고 개발된 점근적(Asymptotic) 방법론입니다.
교육 연구 현장에서 흔히 발생하는 문제는 다음과 같습니다.
수렴 실패 및 불안정성: 표본이 적으면 표본 공분산 행렬()이 ‘full rank’가 되지 않아 수렴에 수천 번의 반복 계산이 필요하거나 아예 수렴하지 않을 수 있습니다.
다중공선성: 변수가 많아지면 변수 간 상관관계가 지나치게 높아져 행렬이 근사 특이(Near-singular) 상태에 빠지기 쉽습니다.
부적절한 적합도: 점근적 이론에 기반한 카이제곱() 통계량은 변수가 많고 표본이 작을 때 모델을 과도하게 기각하는 경향(Type I error 인플레이션)이 있습니다.
[사례 연구: 학업 스트레스와 학교 적응]
어느 중학교의 학습 지원 대상 학생 50명을 대상으로 ‘학업 스트레스 지표(150문항)’를 조사했다고 가정해 봅시다. 150개의 문항(변수)에 대해 표본이 50명뿐이라면, 기존의 최대우도법(ML)은 거의 확실하게 오류를 뱉어낼 것입니다.
2. 모델 매개변수 추정의 해결책
표본 공분산 행렬 가 특이 행렬(Singular matrix)이 되어 계산이 불가능할 때, 우리는 릿지(Ridge) 방법을 고려할 수 있습니다.
2.1 릿지 최대우도법 (Ridge ML)
전통적인 방법은 의 대각선에 일정한 상수를 더해 양의 정구조(Positive definite) 행렬로 만드는 것입니다.
Yuan & Chan (2008) 제안: 대신 (여기서 )를 사용하여 추정의 속도와 수렴율을 획기적으로 높였습니다.
2.2 릿지 일반화최소자승법 (Ridge GLS)
일반적인 GLS는 표본이 작고 변수가 많을 때 매우 불안정합니다. 이를 보완하기 위해 가중치 행렬 를 조정한 릿지 GLS가 제안되었습니다.
Yang & Yuan (2019): 비정규 분포 데이터에서 릿지 GLS가 NML(정규분포 기반 ML)보다 효율적인 추정치를 제공함을 입증했습니다.
2.3 베이지안(Bayesian) 접근법
베이지안 방식은 점근적 이론에 의존하지 않기 때문에 소표본 연구에서 강력한 대안이 됩니다.
사전 정보(Priors)의 활용: 과거 연구나 전문가 견해를 바탕으로 사전 분포를 설정하면, 데이터가 부족하더라도 안정적인 추정이 가능합니다.
주의사항: 잘못된 사전 정보를 설정할 경우 편향된 결과를 초래할 수 있으므로 신중해야 합니다.
3. 모델 적합도 평가의 교정
전통적인 통계량은 소표본에서 믿을 수 없습니다. 이를 교정하기 위한 다양한 ‘휴리스틱’ 및 ‘통계적 교정’ 방법들이 제안되었습니다.
교정 방법
주요 특징
추천 상황
Swain 교정
을 으로 대체하여 교정
일반적인 소표본
Yuan & Bentler (2017)
경험적 결과에 기반한 평균 및 분산 교정
비정규 분포 및 소표본
Tian & Yuan (2019)
2,000개 이상의 조건에서 캘리브레이션된 최신 통계량
변수가 매우 많은 경우()
4. 실전 가이드: R을 활용한 소표본 SEM 분석
많은 교육학도가 사용하는 jamovi의 기본 SEMLj 모듈은 이러한 고차원 교정 기능을 모두 제공하지는 못합니다. 따라서 R의 lavaan 패키지를 활용한 분석이 권장됩니다.
[모의 데이터 시나리오]
스토리: ‘교사 효능감’과 ‘직무 만족도’의 관계 모델링.
상황: 특수 교사 80명 대상(), 문항 수는 총 60개().
R
# 필요한 라이브러리 로드
library(lavaan)
# 1. 모의 데이터 생성 (N=80, p=60인 고차원 데이터)
set.seed(2026)
data <- matrix(rnorm(80 * 60), 80, 60)
colnames(data) <- paste0("v", 1:60)
df <- as.data.frame(data)
# 2. 모델 정의 (간략화된 예시)
model <- '
F1 =~ v1 + v2 + v3 + v4 + v5 + v6 + v7 + v8 + v9 + v10
F2 =~ v11 + v12 + v13 + v14 + v15 + v16 + v17 + v18 + v19 + v20
F2 ~ F1
'
# 3. Satorra-Bentler 교정 적용 분석 (소표본/비정규성 대비)
fit_sb <- sem(model, data = df, test = "Satorra.Bentler")
# 4. 결과 출력
summary(fit_sb, fit.measures = TRUE, standardized=TRUE)
소표본과 다변수 상황에서의 SEM은 “불가능한 작업”이 아니라 “세심한 교정이 필요한 작업”입니다. 분석 시 다음 원칙을 기억하세요.
릿지 추정법을 통해 수렴 불안정성을 해결하세요.
단순 카이제곱 대신 경험적으로 교정된 통계량(, )을 확인하세요.
표준 오차의 정확성을 위해 부트스트랩(Bootstrap) 기법 활용을 검토하세요.
가능하다면 강력한 사전 정보를 바탕으로 한 베이지안 SEM을 고려해 보시기 바랍니다.
참고문헌
Marcoulides, K. M., Yuan, K.-H., & Deng, L. (2022). Structural equation modeling with small samples and many variables. In Handbook of Structural Equation Modeling.
Yuan, K.-H., & Chan, W. (2008). Structural equation modeling with near singular covariance matrices. Computational Statistics & Data Analysis, 52, 4842-4858.
Tian, Y., & Yuan, K.-H. (2019). Mean and variance corrected test statistics for structural equation modeling with many variables. Structural Equation Modeling, 26, 827-846.
WaurimaL의 한 마디:
이 내용이 여러분의 학위 논문이나 연구 설계에 실질적인 도움이 되길 바랍니다. 혹시 여러분의 연구 데이터에서 “표본이 너무 적어 분석이 안 된다”는 경고 메시지가 뜬다면, 제가 제안한 릿지(Ridge) 옵션을 먼저 검토해 보시는 건 어떨까요?