
안녕하세요?
이번에는 교육 연구에서 집단의 이질성을 파악하는 아주 강력한 도구인 혼합 모형(Mixture Models)에 대해 깊이 있게 다루어 보겠습니다.
과거 아리스토텔레스 시대부터 과학의 기초는 사물을 유사성에 따라 분류하는 것이었습니다. 교육 현장에서도 우리는 학생들을 단순히 ‘전체 평균’으로 보는 것이 아니라, 서로 다른 학습 양식이나 심리적 특성을 가진 여러 잠재적 집단(Latent Groups)으로 이해할 필요가 있습니다.
1. 혼합 모형의 개념과 기초
혼합 모형은 데이터가 여러 개의 하위 분포(Components)가 합쳐진 형태라고 가정하는 통계적 접근법입니다.
1.1. 왜 혼합 모형인가?
전통적인 군집 분석(K-means 등)은 학생을 특정 집단에 ‘딱’ 잘라 배정합니다(Crisp membership). 반면, 혼합 모형은 확률적 소속(Probabilistic membership)을 제공합니다. 예를 들어, 한 학생이 ‘자기주도형’ 집단에 속할 확률이 85%, ‘교사의존형’ 집단에 속할 확률이 15%라고 알려주는 식이죠. 이는 분류의 불확실성을 과학적으로 다룰 수 있게 해줍니다.
1.2. 주요 모델의 유형
심리학과 교육학에서 가장 많이 쓰이는 형태는 다음과 같습니다.
- 잠재 프로파일 분석 (LPA): 연속형 변수(예: 시험 점수, 자아존중감 척도)를 사용하여 집단을 구분합니다.
- 잠재 계층 분석 (LCA): 범주형/이분형 변수(예: 예/아니오 설문 응답)를 사용하여 집단을 구분합니다.
2. 모형의 추정과 의사결정
혼합 모형을 성공적으로 구현하기 위해서는 몇 가지 중요한 통계적 결정을 내려야 합니다.
2.1. EM 알고리즘과 지역 최적해(Local Optima)
혼합 모형은 보통 EM(Expectation-Maximization) 알고리즘을 통해 추정됩니다. 이 과정에서 주의할 점은 ‘가장 좋은 해’라고 생각한 결과가 사실은 특정 조건에서만 나타나는 지역 최적해(Local Optima)일 수 있다는 점입니다.
WaurimaL의 팁: 이를 방지하기 위해 무작위 시작값(Random Starts)을 충분히(예: 1,000 ~ 5,000개) 설정하는 것이 필수적입니다. 시작값이 적으면 데이터의 실제 구조를 놓칠 위험이 큽니다.
2.2. 공분산 구조의 결정
데이터의 형태(부피, 모양, 방향)를 어떻게 가정하느냐에 따라 14가지 이상의 모델이 존재합니다.
| 모델 유형 | 부피 (Volume) | 모양 (Shape) | 방향 (Orientation) | 특징 |
| EII | 동일 | 구형 | 해당 없음 | 가장 제약이 많은 형태 (K-means와 유사) |
| VII | 가변 | 구형 | 해당 없음 | 집단별 크기는 다르지만 모양은 동그라미 |
| VVV | 가변 | 가변 | 가변 | 가장 유연하며 데이터에 최적화됨 |
2.3. 집단 수 선정 (BIC와 ICL)
“우리 반 학생들은 몇 개의 유형으로 나뉘는가?”를 결정할 때 가장 널리 쓰이는 지표는 BIC(Bayesian Information Criterion)입니다. 일반적으로 BIC 값이 가장 작은 모델을 선택합니다. 만약 집단 간 구분이 명확한 모델을 원한다면 ICL(Integrated Completed Likelihood) 지표를 함께 고려하는 것이 좋습니다.
3. 교육 현장의 사례: “학습 동기 프로파일 분석”
이해를 돕기 위해 가상의 고등학생 200명의 데이터를 생성하여 분석해 보겠습니다.
3.1. 모의 데이터 시나리오
- 변수: 내재적 동기(IM), 외재적 동기(EM), 학습 불안(ANX), 자기효능감(SE)
- 잠재된 스토리: 1. 고동기형: 모든 점수가 높음. 2. 불안형: 동기는 있으나 불안도가 매우 높음. 3. 무기력형: 모든 점수가 전반적으로 낮음.
3.2. R을 이용한 분석 코드
Jamovi의 snowRMM 모듈로도 가능하지만, 보다 정밀한 제어를 위해 R의 mclust 혹은 mixture 패키지를 권장합니다.
R
# 필요한 패키지 로드
library(mclust)
library(tidyverse)
# 1. 모의 데이터 생성 (교수 재량)
set.seed(2026)
n <- 200
# 세 개의 집단 생성 (고동기, 불안, 무기력)
g1 <- matrix(rnorm(n*0.4*4, mean=4, sd=0.5), ncol=4) # 고동기
g2 <- matrix(rnorm(n*0.3*4, mean=c(3,4,4,3), sd=0.6), ncol=4) # 불안형
g3 <- matrix(rnorm(n*0.3*4, mean=2, sd=0.7), ncol=4) # 무기력
data <- rbind(g1, g2, g3)
colnames(data) <- c("IM", "EM", "ANX", "SE")
write.csv(data,"chap29.csv",row.names = F)
# 2. 혼합 모형 적합 (집단 수 1~5개 테스트)
fit <- Mclust(data, G=1:5)
# 3. 결과 요약 및 집단 수 확인
summary(fit)
# 최적 모델과 집단 수(G) 출력
# 4. 시각화: 프로파일 플롯
means <- fit$parameters$mean
matplot(means, type="b", pch=1:fit$G, main="Student Learning Profiles")
# 5. 모형 적합 (예: mclust 사용)
fit1 <- Mclust(data, G=3)
# 6. 1번 집단 80개, 2번 집단 60개, 3번 집단 60개를 하나의 벡터로 만듭니다.
actual_classes <- c(rep(1, 80), rep(2, 60), rep(3, 60))
# 7. 예측된 집단 할당 (MAP 분류)
# 각 관측치를 가장 높은 사후 확률을 가진 집단에 할당합니다.
predicted_classes <- fit1$classification
# 8. 실제 집단 정보와 비교하여 ARI 계산
# actual_classes는 데이터 세트에 포함된 실제 집단 레이블입니다.
final_ari <- adjustedRandIndex(actual_classes, predicted_classes)
# 9. 결과 해석
# 결과 출력
cat("분석 결과 ARI 수치:", final_ari, "\n")
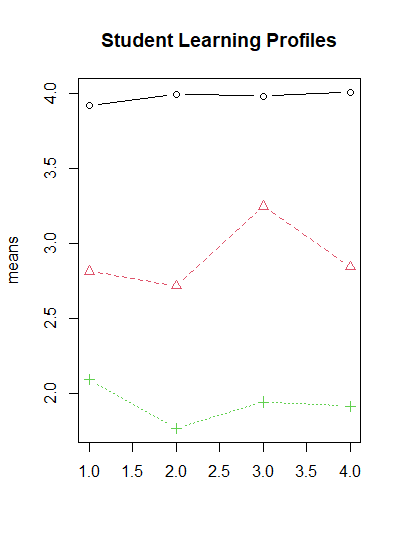
4. 분석 결과의 해석과 주의사항
분석이 끝났다고 해서 바로 “우리 학생들은 3개 집단이다!”라고 결론지어서는 안 됩니다.
4.1. 직접적 vs 간접적 적용
- 직접적 적용: 실제로 데이터 안에 질적으로 다른 ‘진짜 집단’이 존재한다고 믿는 경우입니다.
- 간접적 적용: 데이터가 단순히 비정규분포(기울어짐 등)를 띠고 있어서, 이를 설명하기 위해 여러 개의 정규분포를 빌려 쓰는 경우입니다.
대부분의 사회과학 데이터는 후자인 경우가 많습니다. 따라서 ‘집단 분류’ 자체에 매몰되기보다는, 전체적인 데이터의 이질성을 이해하는 수단으로 혼합 모형을 활용해야 합니다.
4.2. 분류 정확도 (ARI)
분석 결과로 나온 집단 분류가 얼마나 정확한지 판단하기 위해 ARI(Adjusted Rand Index)를 확인합니다. ARI가 0.8 이상이면 ‘우수’, 0.65 이상이면 ‘수용 가능’한 수준으로 봅니다.
5. 결론: 연구자를 위한 제언
혼합 모형은 매우 유연하지만, 그만큼 오용하기 쉽습니다.
- 시각화가 우선입니다: 분석 전 산점도나 요인 점수 분포를 통해 실제로 집단이 나뉠 만한 구조인지 먼저 확인하세요.
- 이론적 근거를 가지세요: 통계 지표(BIC)가 4개를 추천하더라도, 교육학적 이론으로 설명되지 않는 집단이라면 모형을 재검토해야 합니다.
- 복제 가능성을 염두에 두세요: 혼합 모형은 과적합(Overfitting)의 위험이 크므로, 다른 샘플에서도 동일한 구조가 나타나는지 확인하는 과정이 필요합니다.
참고문헌 (APA Style)
- Bauer, D. J., & Curran, P. J. (2003). Distributional assumptions of growth mixture models: Implications for overextraction of latent trajectory classes. Psychological Methods, 8(3), 338–363.
- Celeux, G., & Govaert, G. (1995). Gaussian parsimonious clustering models. Pattern Recognition, 28(5), 781–793.
- Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society: Series B (Methodological), 39(1), 1–22.
- McLachlan, G. J., & Peel, D. (2000). Finite mixture models. Wiley.
- Steinley, D. (2026). Mixture Models. In The SAGE Handbook of Quantitative Methods in Psychology. SAGE. (Original work published 2023)
- Steinley, D., & Brusco, M. J. (2011). Evaluating the performance of model-based clustering: Recommendations and cautions. Psychological Methods, 16(1), 63–79.