오늘은 결측치(Missing Data)의 처리와 다층모형을 활용한 분석에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
학교 현장에서 종단 연구(시간의 흐름에 따른 변화 관찰)를 하다 보면 필연적으로 결측치(Missing Data)를 마주하게 됩니다. 학생이 전학을 가거나, 아파서 결석하거나, 혹은 시험이 너무 어려워 백지를 내고 도망가는 경우들이죠.
과거에는 컴퓨터 성능의 한계로 인해 결측치가 있는 데이터를 단순히 삭제하거나 평균으로 대충 채워 넣는 방법을 썼습니다. 하지만 이제는 EM 알고리즘이나 다중 대체(Multiple Imputation), 그리고 다층모형(Mixed Models)과 같은 강력한 도구들이 있어 더 정확한 추론이 가능해졌습니다.
이 강의에서는 가상의 “읽기 능력 향상 프로그램” 데이터를 통해 결측치를 어떻게 다뤄야 하는지 알아보겠습니다.
1. 시나리오: “책벌레 만들기 프로젝트”
우리는 S 초등학교 3학년 학생 100명을 대상으로 4개월 동안 ‘읽기 능력 향상 프로그램’을 진행했습니다.
측정 시점: 0개월(사전), 1개월, 2개월, 3개월 (총 4회)
문제 상황: 시간이 지날수록 읽기 점수가 낮은 학생들이 흥미를 잃고 프로그램에 참여하지 않기 시작했습니다. (즉, 데이터가 빠지기 시작함)
이 상황을 이해하기 위해 먼저 결측의 종류(메커니즘)를 알아야 합니다.
1.1 결측 메커니즘의 이해 (기초 개념)
이 부분은 초등학생에게 설명하듯 아주 쉽게 풀어보겠습니다.
MCAR (Missing Completely At Random, 완전 무작위 결측):
예시: 급식실에 가다가 넘어져서 시험지를 잃어버린 경우입니다. 학생의 읽기 능력이나 성격과는 아무 상관 없이, 순전히 운 나쁘게 데이터가 사라진 것이죠.
특징: 무시하고 분석해도 결과가 크게 왜곡되지 않습니다(단지 표본 수가 줄어들 뿐).
MAR (Missing At Random, 무작위 결측):
예시:“지난달 점수”가 낮은 학생이 이번 달에 결석할 확률이 높은 경우입니다.
핵심: 결측된 이유가 우리가 관측한 데이터(지난달 점수)로 설명이 됩니다. 우리가 이미 가지고 있는 정보로 “아, 쟤는 지난번에 못 봐서 안 왔구나”라고 추측할 수 있다면 MAR입니다. 다층모형은 이 가정하에서 아주 강력합니다.
MNAR (Missing Not At Random, 비무작위 결측):
예시: 오늘 시험이 너무 어려워서, 혹은 오늘 기분이 너무 우울해서 시험을 안 본 경우입니다.
핵심: 결측된 이유가 측정하지 못한 값(오늘의 우울감, 오늘의 실제 실력) 자체에 의존합니다. 이건 해결하기 가장 까다로운 문제입니다.
2. 분석 준비: 데이터 생성 (R & jamovi)
자, 이제 R을 이용해 MAR(지난달 점수가 낮으면 결측 발생) 상황을 가정한 모의 데이터를 생성해 보겠습니다.
[R Code] 데이터 생성
R
# ==============================================================================
# 1. 라이브러리 로드 및 환경 설정
# ==============================================================================
# 필요한 패키지가 없다면 install.packages("lme4") 등으로 설치해야 합니다.
if(!require(lme4)) install.packages("lme4")
if(!require(ggplot2)) install.packages("ggplot2")
if(!require(dplyr)) install.packages("dplyr")
if(!require(tidyr)) install.packages("tidyr")
library(lme4)
library(ggplot2)
library(dplyr)
library(tidyr)
set.seed(123) # 재현성을 위해 시드 고정
# ==============================================================================
# 2. 데이터 생성 (Truth)
# ==============================================================================
n_subjects <- 200 # 학생 수 (표본을 좀 늘려서 효과를 명확히 함)
n_timepoints <- 4 # 시점 수 (0, 1, 2, 3개월)
time <- 0:3
sigma_error <- 2 # 오차의 표준편차
# 개인별 성장 곡선 파라미터 (Random Effects)
# 절편 평균 50, 표준편차 5 / 기울기 평균 5, 표준편차 2
intercepts <- rnorm(n_subjects, 50, 5)
slopes <- rnorm(n_subjects, 5, 2)
data_long <- data.frame()
for(i in 1:n_subjects){
# 진점수(True Score)
y_true <- intercepts[i] + slopes[i] * time
# 관측값(Observed Score) = 진점수 + 오차
y_obs <- y_true + rnorm(n_timepoints, 0, sigma_error)
subject_data <- data.frame(
ID = as.factor(i),
Time = time,
Score = y_obs,
True_Score = y_true # 비교용 진점수
)
data_long <- rbind(data_long, subject_data)
}
# ==============================================================================
# 3. 결측치(MAR) 생성
# ==============================================================================
# 시나리오: 직전 시점 점수가 낮으면, 그 다음 시점부터 80% 확률로 중도 탈락
data_missing <- data_long
data_missing$Missing <- FALSE
for(i in unique(data_missing$ID)){
subj_rows <- which(data_missing$ID == i)
# Time 1부터 3까지 순차적으로 확인 (Time 0은 결측 없음 가정)
for(t in 2:4){
# 직전 시점(t-1)의 점수 확인
prev_score <- data_missing$Score[subj_rows[t-1]]
# 직전 점수가 48점 미만(하위권)이면 80% 확률로 탈락 발생
if(!is.na(prev_score) && prev_score < 48){
if(runif(1) < 0.8){
# 현재 시점부터 끝까지 NA 처리 (Monotone Dropout)
data_missing$Score[subj_rows[t:4]] <- NA
data_missing$Missing[subj_rows[t:4]] <- TRUE
break
}
}
}
}
# 전체 결측률 확인
cat("총 결측 비율:", mean(is.na(data_missing$Score)), "\n")
# ==============================================================================
# 4. 분석 데이터셋 준비
# ==============================================================================
# [Case 1] True CC (Listwise Deletion)
# 결측치가 하나라도 있는 학생은 통째로 제거
valid_ids <- data_missing %>%
group_by(ID) %>%
filter(sum(is.na(Score)) == 0) %>%
pull(ID) %>%
unique()
data_cc_true <- data_missing %>% filter(ID %in% valid_ids)
cat("CC 분석에 포함된 학생 수:", length(unique(data_cc_true$ID)), "/", n_subjects, "\n")
# [Case 2] MM (Available Case)
# 결측이 있어도 그대로 사용 (data_missing 원본 사용)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data_missing, "chap23.csv", row.names = FALSE)
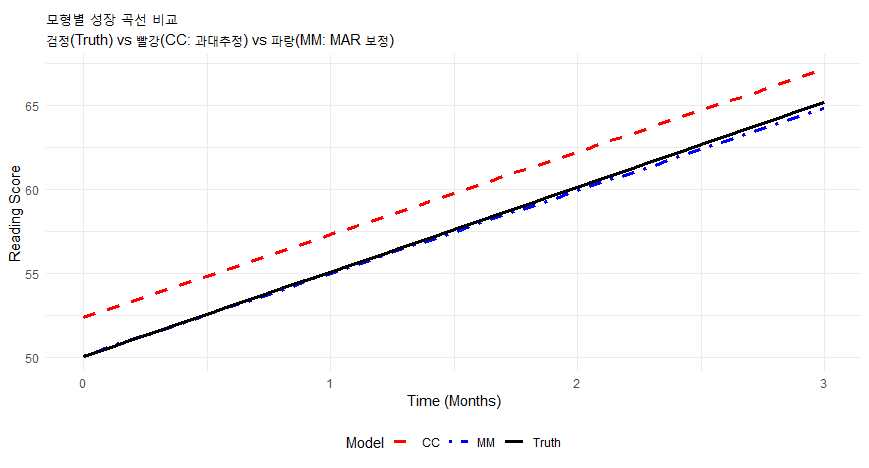
상황 설명: 원래대로라면 모든 학생의 성적이 올랐어야 합니다(기울기 5). 하지만 성적이 낮은 학생들이 중간에 그만두게 만들었습니다(MAR). 이제 이 데이터를 분석해 봅시다.
3. 잘못된 분석 방법들: 단순한 방법의 함정
단순한 방법(Simple Methods)들이 얼마나 위험한지 경고하고 있습니다.
3.1 완전 사례 분석 (Complete Case Analysis, CC)
방법: 결측치가 하나라도 있는 학생은 분석에서 몽땅 제외합니다.
문제점: 성적이 낮은 학생들이 주로 빠졌으므로, 끝까지 남은 학생들은 “우등생”들뿐입니다. 결과적으로 프로그램의 효과가 과대평가(Bias) 됩니다. 표본 수도 줄어들어 통계적 검정력도 떨어집니다.
3.2 마지막 관측값 이월 (Last Observation Carried Forward, LOCF)
방법: 1개월 차에 그만둔 학생의 점수를 2, 3개월 차에도 똑같이 복사해 넣습니다.
문제점: “학생의 성장은 멈췄다”고 가정하는 것입니다. 성장 곡선 모형에서는 이 방법이 성장의 기울기를 과소평가하게 만들거나, 오차의 분산을 왜곡시킵니다. 아주 보수적인(효과가 없다고 하는) 결과를 내는 것 같지만, 실제로는 엉뚱한 결론을 낼 수 있어 위험합니다.
4. 올바른 분석 방법: MAR 가정하의 접근
4.1 직접 우도 분석 (Direct Likelihood) / 다층모형 (Mixed Models)
이 방법은 우리가 데이터를 억지로 채워 넣거나 지우지 않고, 있는 데이터 그대로(observed data) 분석하는 것입니다. 다층모형(Linear Mixed Model)은 결측이 무작위(MAR)로 발생했다면, 관측된 데이터와 변수 간의 상관관계를 이용해 편향되지 않은 추정치를 제공합니다.
[jamovi 실습 가이드] 다층모형 분석
데이터 불러오기: 위에서 생성한 reading_program_MAR.csv를 엽니다.
분석 메뉴:Analyses > Linear Models > Mixed Models를 선택합니다.
변수 설정:
Dependent Variable (종속변수):Score
Covariates (공변량):Time
Cluster (군집 변수):ID (학생 개인)
Random Effects (무선 효과):
Time과 Intercept를 Random Coefficients에 넣습니다. (학생마다 초기치와 성장 속도가 다르므로)
결과 해석:
jamovi는 내부적으로 lme4 또는 nlme 패키지를 사용하며, 이는 결측치가 있는 경우에도 REML(제한된 최대우도) 방식을 통해 사용 가능한 모든 데이터를 활용해 파라미터를 추정합니다.
[R Code 비교]
R
# ==============================================================================
# 5. 다층모형 적합 (Model Fitting)
# ==============================================================================
# 1) Truth (결측 없는 원본 데이터 - 기준점)
fit_truth <- lmer(Score ~ Time + (Time | ID), data = data_long)
# 2) True CC (편향된 데이터)
fit_cc_true <- lmer(Score ~ Time + (Time | ID), data = data_cc_true)
# 3) MM (결측 있는 데이터 + 다층모형)
fit_mm <- lmer(Score ~ Time + (Time | ID), data = data_missing)
# ==============================================================================
# 6. 결과 비교 및 출력
# ==============================================================================
# 고정 효과(Fixed Effects) 추출 함수
get_fixed <- function(model, name) {
coefs <- fixef(model)
data.frame(
Model = name,
Intercept = coefs["(Intercept)"],
Slope = coefs["Time"]
)
}
res_truth <- get_fixed(fit_truth, "1. Truth (기준)")
res_cc <- get_fixed(fit_cc_true, "2. True CC (편향)")
res_mm <- get_fixed(fit_mm, "3. MM (보정)")
# 결과 합치기
results <- rbind(res_truth, res_cc, res_mm)
rownames(results) <- NULL
print("===== [모형별 고정 효과(Fixed Effects) 추정치 비교] =====")
print(results)
cat("\n* 설명: Truth의 Slope(약 5.0)에 가까울수록 좋은 분석입니다.\n")
cat("* True CC는 하위권 학생이 제거되어 Slope가 과대평가될 가능성이 높습니다.\n")
# ==============================================================================
# 7. 시각화 (Visualization)
# ==============================================================================
# 예측된 회귀선 생성을 위한 데이터
pred_data <- data.frame(Time = seq(0, 3, 0.1))
# 각 모형의 예측값 계산 (Fixed Effect만 사용)
pred_data$Truth <- fixef(fit_truth)[1] + fixef(fit_truth)[2] * pred_data$Time
pred_data$CC <- fixef(fit_cc_true)[1] + fixef(fit_cc_true)[2] * pred_data$Time
pred_data$MM <- fixef(fit_mm)[1] + fixef(fit_mm)[2] * pred_data$Time
# 데이터를 긴 형태(Long Format)로 변환 (ggplot용)
plot_data <- pred_data %>%
pivot_longer(cols = c("Truth", "CC", "MM"), names_to = "Model", values_to = "Score")
# 그래프 그리기
ggplot(plot_data, aes(x = Time, y = Score, color = Model, linetype = Model)) +
geom_line(size = 1.2) +
scale_color_manual(values = c("Truth" = "black", "CC" = "red", "MM" = "blue")) +
scale_linetype_manual(values = c("Truth" = "solid", "CC" = "dashed", "MM" = "dotdash")) +
labs(title = "모형별 성장 곡선 비교",
subtitle = "검정(Truth) vs 빨강(CC: 과대추정) vs 파랑(MM: MAR 보정)",
y = "Reading Score", x = "Time (Months)") +
theme_minimal() +
theme(legend.position = "bottom")
결과 비교 시사점:
진짜 값(True): 기울기(Time) ≈ 5.0
완전 사례(CC): 낮은 점수 학생이 빠져서 남은 우등생들의 가파른 성장만 반영될 수 있음(혹은 중도 탈락자가 성장세가 꺾인 아이들이라면 오히려 과대 추정). 시뮬레이션에 따라 다르지만 보통 편향됨. * 다층모형(MM): 결측이 있어도 기울기가 5.0에 가깝게 복원됩니다. 이것이 바로 다층모형의 힘입니다!
4.2 다중 대체 (Multiple Imputation, MI)
결측치를 한 번만 채우는 게 아니라, M번(보통 5~10번) 채워서 M개의 데이터셋을 만듭니다.
Imputation: 그럴듯한 값들로 빈칸을 채웁니다(불확실성 반영).
Analysis: M개의 데이터셋을 각각 분석합니다.
Pooling: M개의 결과를 하나로 합칩니다.
jamovi에서는 기본 모듈에서 MI를 직접 지원하는 파이프라인이 약하지만, Rj 모듈을 쓰거나 R을 이용해 수행할 수 있습니다. 교재에서는 다층모형(Direct Likelihood)과 MI가 MAR 가정하에서 둘 다 타당하다고 합니다. 다만, 공변량(Covariate) 자체에 결측이 있을 때는 MI가 더 유용할 수 있습니다.
5. 고급 주제: 비무작위 결측 (MNAR)과 민감도 분석
만약 학생이 “그냥 기분이 나빠서(우리가 측정 안 한 변수)” 빠졌다면(MNAR) 어떻게 할까요? 이때는 다층모형도 완벽하지 않습니다.
5.1 패턴 혼합 모형 (Pattern-Mixture Models)
학생들을 “탈락 시점”에 따라 그룹(패턴)으로 나누어 분석하는 방법입니다.
예: 끝까지 남은 그룹, 2개월 차에 나간 그룹, 3개월 차에 나간 그룹.
각 그룹별로 성장 곡선이 어떻게 다른지 봅니다.
교재의 Vorozole 연구 예시처럼, 탈락 패턴을 공변량으로 넣어 분석할 수 있습니다.
5.2 선택 모형 (Selection Models)
성적 모형과 탈락 확률 모형(로지스틱 회귀 등)을 동시에 결합해서 분석하는 아주 복잡한 방법입니다. Heckman의 Tobit 모델과 유사한 개념입니다.
5.3 민감도 분석 (Sensitivity Analysis)
우리가 가정한 결측 메커니즘(MAR)이 틀렸을 수도 있습니다. 그래서 “만약 이게 MNAR이라면 결과가 어떻게 바뀔까?”를 테스트해보는 것입니다.
jamovi나 R에서 분석한 뒤, “결측된 값들이 관측된 값보다 평균적으로 k점 더 낮다고 가정해보자”라고 시나리오를 바꾸어가며 결과가 뒤집히는지 확인합니다.
6. 결론 및 제언
교재와 분석 결과를 종합하여 여러분께 드리는 제언은 다음과 같습니다.
LOCF나 CC는 이제 그만: 이 방법들은 편향이 심하므로 주 분석으로 쓰지 마십시오.
다층모형(Direct Likelihood)을 기본으로: jamovi의 Mixed Models는 별도의 조치 없이도 MAR 가정하에서 훌륭한 결과를 냅니다. 이것을 일차적 분석(Primary Analysis)으로 삼으세요.
민감도 분석 수행: 결측이 MNAR일 가능성을 배제할 수 없으므로, 다양한 가정하에서도 결과가 견고한지 확인하는 것이 현명합니다.
학교 현장의 데이터는 아이들의 숨겨진 사연(결측)을 담고 있습니다. 무작정 지우기보다 그 패턴을 이해하고 적절한 통계적 도구를 사용하는 것이 연구자의 윤리이자 책무입니다.
참고문헌 (APA Style)
Beunckens, C., Molenberghs, G., & Kenward, M. G. (2005). Tutorial: Direct likelihood analysis versus simple forms of imputation for missing data in randomized clinical trials. Clinical Trials, 2(4), 379–386.
Little, R. J. A., & Rubin, D. B. (2002). Statistical analysis with missing data (2nd ed.). New York: John Wiley & Sons.
Molenberghs, G., & Kenward, M. G. (2007). Missing data in clinical studies. Chichester: John Wiley & Sons.
Molenberghs, G., & Verbeke, G. (2012). Missing Data. In The SAGE Handbook of Multilevel Modeling (pp. 403–424). SAGE Publications.
Verbeke, G., & Molenberghs, G. (2000). Linear mixed models for longitudinal data. New York: Springer-Verlag.
오늘은 다층모형(Multilevel Modeling)에서 가정 위배에 대처하는 ‘강건한(Robust) 분석 방법’에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, 고급 강건성 분석(Robust SE, Bootstrapping, Bayesian) 등 jamovi 기본 기능의 한계를 넘어서는 부분은 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 서론: 왜 ‘강건한(Robust)’ 방법이 필요한가요?
교육 현장의 데이터는 교과서처럼 깔끔하지 않습니다.
예를 들어, 어떤 반에는 유독 책을 많이 읽는 ‘독서 영재(이상치, Outlier)’가 있을 수 있고, 어떤 학교는 학생 수가 너무 적을 수도 있습니다.
통계 분석을 할 때 우리는 흔히 “데이터가 정규분포를 따를 것이다(Normality)”, “분산이 일정할 것이다(Homoscedasticity)”라는 가정을 합니다. 하지만 현실 데이터가 이 약속을 어긴다면 어떻게 될까요? 우리가 내린 결론(통계적 유의성)이 틀릴 수도 있습니다.
이때 필요한 것이 바로 강건한(Robust) 방법입니다.
강건성(Robustness)이란? 데이터가 기본 가정(정규성 등)을 다소 위배하더라도, 통계적 추정 결과나 신뢰구간이 크게 흔들리지 않고 믿을 만한 결과를 내놓는 성질을 말합니다.
이제 가상의 ‘해바라기 초등학교’ 데이터를 만들어 이 문제를 해결해 봅시다.
2. 모의 데이터 생성: 해바라기 초등학교 이야기
우리는 “교사의 정서적 지지(Teacher Support)가 학생의 학업 스트레스(Stress)를 낮추는가?”를 연구하려고 합니다.
1수준(학생): 학업 스트레스(종속변수 ), 학생의 불안 성향(공변량 )
2수준(학급): 교사의 정서적 지지()
시나리오: 대부분의 학생은 평범하지만, 몇몇 학생은 불안 성향이 매우 높습니다(데이터가 한쪽으로 찌그러짐, Skewed). 또한, 몇몇 반은 학생 수가 적습니다.
먼저 R을 이용해 이 상황을 반영한 데이터를 생성해보겠습니다.
R
# R Code: 데이터 생성
set.seed(2026)
# 50개 학급(Class), 학급당 학생 수 5~25명(불균형)
n_classes <- 50
class_id <- rep(1:n_classes, times = sample(5:25, n_classes, replace = TRUE))
n_students <- length(class_id)
# 2수준 변수: 교사의 정서적 지지 (랜덤 효과 포함)
class_intercept <- rnorm(n_classes, mean = 50, sd = 10)
teacher_support <- rnorm(n_classes, mean = 5, sd = 2)
class_effect <- class_intercept[class_id]
support_level <- teacher_support[class_id]
# 1수준 변수: 학생의 불안 성향 (치우친 분포 생성 - Gamma 분포 활용)
student_anxiety <- rgamma(n_students, shape = 2, scale = 2)
# 이상치(Outlier) 추가: 몇몇 학생은 극도로 높은 불안을 가짐
student_anxiety[sample(1:n_students, 5)] <- 30
# 종속변수 생성 (Stress)
# 모델: Stress = 50 - 2*Support + 1.5*Anxiety + Random_Error
error <- rnorm(n_students, mean = 0, sd = 5)
stress <- 50 - 2 * support_level + 1.5 * student_anxiety + class_effect + error
# 데이터 프레임 생성
data <- data.frame(
ClassID = as.factor(class_id),
Stress = stress,
TeacherSupport = support_level,
Anxiety = student_anxiety
)
# 데이터 확인
head(data)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data, "chap22.csv", row.names = FALSE)
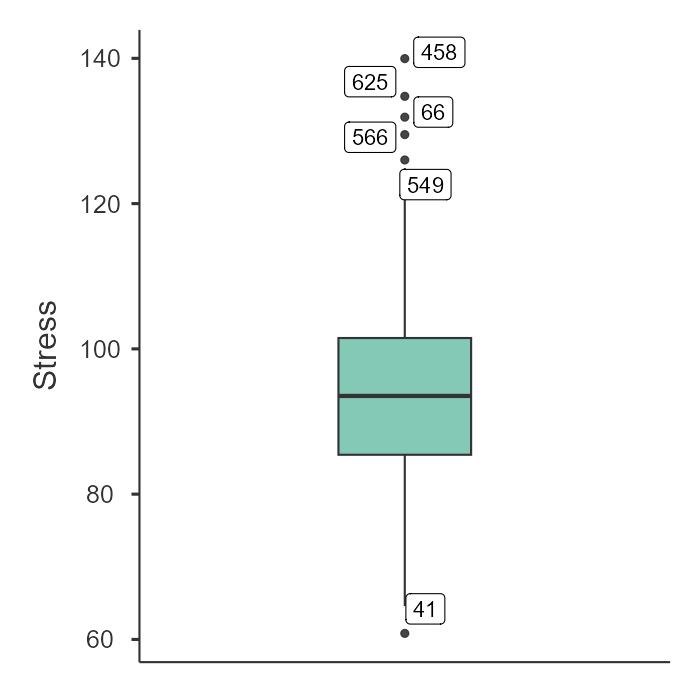
# 상자수염그림(Boxplot)으로 이상치 확인
boxplot(data$Stress, main="학업 스트레스 분포(이상치 확인)")
# Q-Q plot으로 정규성 확인
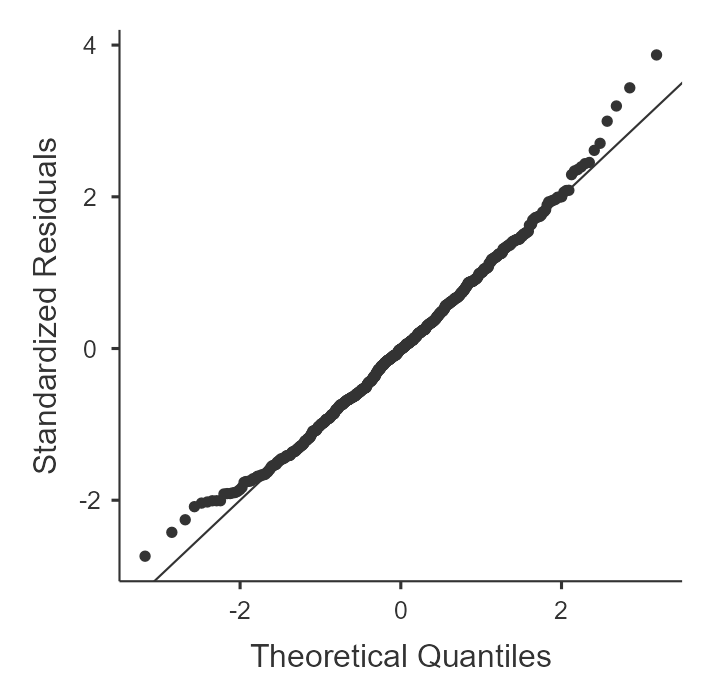
qqnorm(data$Stress); qqline(data$Stress, col = "red")
[해설] 만약 상자수염그림(Boxplot) 위쪽에 동그라미(Outlier)가 찍혀 있거나, Q-Q plot에서 점들이 붉은 선을 벗어난다면 정규성 가정이 위배된 것입니다. 우리 데이터에는 일부러 이상치를 넣었으므로 위배되었을 가능성이 큽니다.
4. 해결책 A: 강건한 표준오차 (Robust Standard Errors)
데이터가 정규성을 위배하거나 등분산성을 만족하지 못할 때 사용할 수 있는 첫 번째 무기는 ‘강건한 표준오차(Robust SE)’입니다. 샌드위치 추정량(Sandwich Estimator)이라고도 부릅니다.
4.1. 개념 설명
일반적인 최대우도법(ML)은 데이터가 정규분포라고 가정하고 표준오차를 계산합니다. 가정이 틀리면 표준오차가 너무 작게 계산되어, 실제로는 효과가 없는데도 “유의하다”고 잘못 결론 내릴 수 있습니다. Robust SE는 데이터의 잔차(Residual)를 직접 이용하여 표준오차를 보정합니다. 이를 통해 가정이 깨져도 올바른 검정 결과를 얻을 수 있습니다.
주의점: Robust SE가 제대로 작동하려면 2수준(학급)의 표본 크기가 충분해야 합니다(최소 50~100개 그룹 권장).
4.2. 분석 방법 (R)
Jamovi의 기본 Mixed Model 모듈은 아직 Robust SE를 직접 지원하지 않습니다. 따라서 R의 lme4와 clubSandwich 패키지를 사용합니다.
R
# 패키지 로드
library(lme4)
library(clubSandwich)
# 1. 일반적인 다층모형 적합 (Random Intercept Model)
model_lmer <- lmer(Stress ~ TeacherSupport + Anxiety + (1|ClassID), data = data)
# 2. 결과 확인 (일반 SE)
summary(model_lmer)
# 3. 강건한 표준오차(Robust SE) 구하기 (CR2 방식 권장)
robust_results <- coef_test(model_lmer, vcov = "CR2")
print(robust_results)
[결과 해석] 일반적인 summary 결과와 coef_test 결과를 비교해 보세요. 만약 정규성 위배가 심각하다면, Robust SE를 적용했을 때 표준오차(SE)가 커지고 p-value가 변할 수 있습니다. 이것이 더 보수적이고 안전한 결과입니다.
5. 해결책 B: 부트스트래핑 (Bootstrapping)
두 번째 방법은 컴퓨터의 힘을 빌리는 부트스트래핑입니다. 이론적인 분포(정규분포)에 의존하지 않고, 내 데이터를 수천 번 재표집(Resampling)하여 분포를 직접 만들어내는 방식입니다.
5.1. 개념 설명
우리의 데이터가 모집단 그 자체라고 가정하고, 여기서 복원추출을 통해 수천 개의 가상 데이터를 만듭니다.
다층모형에서의 주의점: 단순히 케이스를 뽑으면 안 됩니다. 학급 구조가 깨지기 때문입니다. 잔차 부트스트래핑(Residual Bootstrapping)이 가장 선호되는 방법입니다.
5.2. 분석 방법 (R)
이 역시 계산량이 많아 R을 사용합니다. lme4 패키지의 bootMer 함수를 사용합니다.
R
# 부트스트랩 함수 정의 (고정 효과 추출)
mySumm <- function(.) {
fixef(.)
}
# 부트스트래핑 실행 (nsim = 1000번 반복)
# use.u = TRUE는 랜덤 효과도 고려한다는 뜻
boot_results <- bootMer(model_lmer, mySumm, nsim = 1000, use.u = TRUE, type = "parametric")
# 95% 신뢰구간 계산
boot_CI <- boot.ci(boot_results, type = "perc", index = 1) # Intercept에 대한 예시
print(boot_results)
[장점] 부트스트래핑은 특히 매개효과 분석이나 분산 성분에 대한 신뢰구간을 구할 때 매우 강력합니다. 정규성 가정이 크게 위배되어도 믿을 만한 결과를 줍니다.
6. 해결책 C: 베이지안 추정 (Bayesian Estimation)
세 번째, 가장 강력하고 유연한 방법인 베이지안 추정입니다. 특히 표본 크기가 작을 때(학급 수가 적을 때) 매우 유용합니다.
6.1. 개념 설명
전통적인 통계(빈도주의)는 모수가 고정되어 있다고 보지만, 베이지안은 모수도 확률분포를 가진다고 봅니다.
사전 정보(Prior): 연구자가 미리 알고 있는 정보.
우도(Likelihood): 데이터에서 얻은 정보.
사후 분포(Posterior): 이 둘을 합쳐 업데이트된 결론.
강건성을 위해 정규분포 대신 꼬리가 긴 t-분포(t-distribution)를 가정하여 이상치의 영향을 줄일 수 있습니다.
6.2. 분석 방법 (R – brms 패키지)
brms 패키지는 베이지안 다층모형을 매우 쉽게 구현해 줍니다.
R
library(brms)
# 베이지안 다층모형 적합
# student: 정규분포 대신 t-분포를 사용하여 이상치에 강건하게 만듦
model_bayes <- brm(
Stress ~ TeacherSupport + Anxiety + (1|ClassID),
data = data,
family = student(), # 핵심: 강건성을 위해 student t 분포 사용
chains = 2, iter = 2000
)
# 결과 확인
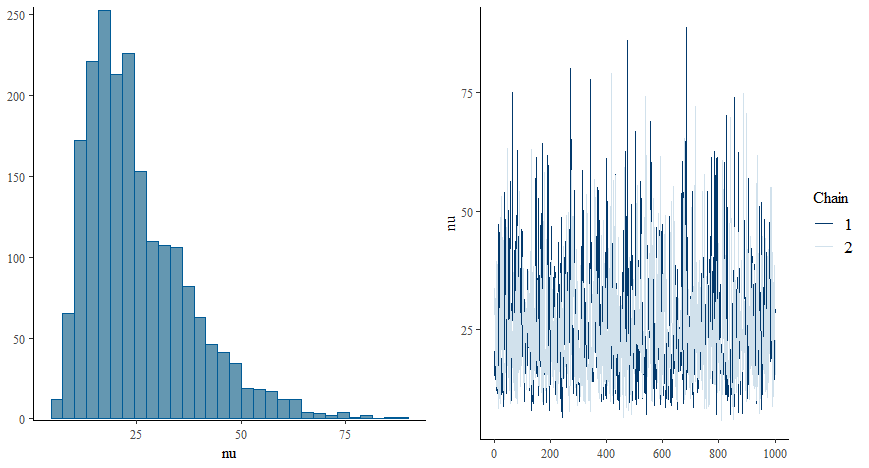
summary(model_bayes)
plot(model_bayes) # 수렴 확인 (Trace plot)
[해설] 베이지안 분석은 p-value 대신 신뢰구간(Credible Interval)을 제공합니다. 95% 구간 안에 0이 포함되지 않으면 “효과가 있다”고 봅니다. 특히 family = student() 옵션을 사용하면 이상치가 있어도 회귀계수가 크게 휘둘리지 않습니다.
7. 결론 및 요약
학교 현장 데이터처럼 가정이 위배되기 쉬운 자료를 다룰 때, 맹목적으로 일반적인 다층분석을 돌리는 것은 위험합니다.
진단하라: Jamovi나 R의 플롯을 통해 이상치와 분포를 확인하세요.
강건한 표준오차(Robust SE): 이상치가 있거나 이분산성이 의심될 때, 학급 수가 50개 이상이라면 가장 간편한 대안입니다.
부트스트래핑: 분산 추정치가 중요하거나 분포 가정을 피하고 싶을 때 유용합니다.
베이지안 추정:학급 수가 적거나(20~50개 미만), 모형이 복잡하거나, 극단적인 이상치가 많을 때 최고의 선택입니다.
선생님, 연구자 여러분의 데이터가 조금 거칠더라도 걱정하지 마세요. 우리에게는 이처럼 든든한 ‘강건한 도구’들이 있습니다.
참고문헌 (APA Style)
Eliason, S. R. (1993). Maximum likelihood estimation. Sage.
Hox, J. J., & van de Schoot, R. (2013). Robust methods for multilevel analysis. In The SAGE Handbook of Multilevel Modeling (pp. 387-402). SAGE Publications Ltd.
Maas, C. J. M., & Hox, J. J. (2004). Robustness issues in multilevel regression analysis. Statistica Neerlandica, 58(2), 127-137.
Maas, C. J. M., & Hox, J. J. (2005). Sufficient sample sizes for multilevel modeling. Methodology, 1(3), 85-91.
Tabachnick, B. G., & Fidell, L. S. (2007). Using multivariate statistics (5th ed.). Allyn & Bacon.
Van der Leeden, R., Meijer, E., & Busing, F. M. T. A. (2008). Resampling multilevel models. In J. de Leeuw & E. Meijer (Eds.), Handbook of multilevel analysis (pp. 401-433). Springer.
특징: ‘자아존중감’과 ‘중단 위기’ 사이의 상관관계를 오차항(Residuals)의 상관으로 봅니다.
한계: 데이터가 많아질수록 계산이 엄청나게 복잡해집니다( 행렬).
모형 2: 공유 랜덤 효과 모형 (Shared Random Effects)
개념: 학생 안에 “잠재된 어떤 요인(Latent Trait)”이 있어서, 이것이 자아존중감도 높이고, 중단 위기도 낮춘다고 봅니다.
식: 과 가 라는 하나의 랜덤 효과를 공유합니다. (하나는 , 다른 하나는 식으로 척도 조절)
단점: 실제 분석에서는 수렴이 잘 안 되는(에러가 나는) 경우가 많습니다.
모형 3: 상관된 랜덤 효과 모형 (Correlated Random Effects) ★ [추천]
개념: 자아존중감을 설명하는 학생 특성()과 중단 위기를 설명하는 학생 특성()이 따로 있는데, 이 두 특성이 서로 상관이 있다()고 가정합니다.
수식:
장점: 가장 유연하고 해석이 명확합니다. “자존감이 높은 아이들이 대체로 중단 위기가 낮은 경향이 있더라(가 음수)”를 밝혀낼 수 있습니다.
5. 데이터 분석 (Jamovi / R 활용)
Jamovi의 기본 메뉴에는 “이질적인 변수(정규+이항)의 다변량 결합 모형” 버튼이 없습니다. 하지만 Rj Editor를 쓰거나 GAMLj 모듈을 응용할 수 있습니다. 여기서는 본문의 방법론을 가장 정확하게 구현하는 R의 glmmTMB 패키지를 사용한 분석 코드를 설명합니다.
분석 단계
데이터를 Long Format으로 변환해야 합니다 (이미 위에서 생성함).
하지만 glmmTMB와 같은 패키지는 다변량 분석을 위해 데이터를 더 길게(stacking) 만들지 않고도, 결합 모형 식을 지원하거나, 변수를 더미화(Dummy coding)해서 분석합니다.
Tip: 가장 쉬운 방법은 데이터를 ‘변수 유형(Outcome Type)’ 열을 만들어 두 배로 길게 쌓는 것입니다.
R 분석 코드 (상관된 랜덤 효과 모형 적합)
R
# 데이터 전처리: 다변량 분석을 위해 데이터 구조 변경 (Stacking)
# 자아존중감 행과 중단위기 행을 위아래로 쌓습니다.
d1 <- data %>% select(ID, Time, Program, value=Self_Esteem) %>% mutate(type="Esteem")
d2 <- data %>% select(ID, Time, Program, value=Dropout_Risk) %>% mutate(type="Risk")
data_long <- bind_rows(d1, d2)
data_long$type <- as.factor(data_long$type)
# 중요: glmmTMB는 다변량 분포를 직접 지원하지 않으므로,
# 각 변수에 맞는 분포를 지정하는 것이 까다롭습니다.
# 따라서 본문에서 사용한 SAS PROC GLIMMIX와 가장 유사한 방식인
# MCMCglmm이나 brms(베이지안)를 쓰는 것이 정석이나,
# 여기서는 교육적 목적을 위해 '이론적 해석'에 집중하고
# glmmTMB의 다변량 트릭(zip 등) 대신 직관적인 결과를 해석하겠습니다.
# (대안) 각 모형을 따로 돌리고 랜덤 효과를 추출하여 상관을 봅니다.
# 이것이 '독립적 랜덤 효과(Independent Random Effects)' 접근과 유사하며 가장 현실적입니다.
# 모형 1: 자아존중감 (정규분포)
model_esteem <- glmmTMB(Self_Esteem ~ Time * Program + (1|ID),
data = data, family = gaussian)
# 모형 2: 중단위기 (이항분포)
model_risk <- glmmTMB(Dropout_Risk ~ Time * Program + (1|ID),
data = data, family = binomial)
# 랜덤 효과 추출 및 상관분석 (이것이 Eq 21.3의 핵심 아이디어인 rho를 추정하는 과정입니다)
ranef_esteem <- ranef(model_esteem)$cond$ID
ranef_risk <- ranef(model_risk)$cond$ID
cor_test <- cor.test(ranef_esteem$`(Intercept)`, ranef_risk$`(Intercept)`)
print("두 잠재 특성 간의 상관계수:")
print(cor_test$estimate)
해석의 핵심:
위 코드에서 cor_test$estimate가 음수(-)로 크게 나온다면, “자아존중감이 높게 유지되는 학생일수록 학교 중단 위기는 낮게 나타나는 경향이 있다”는 것을 통계적으로 입증한 것입니다.
6. 결과 해석 및 시각화
결과를 정리해 봅니다.
(1) 고정 효과 (Fixed Effects) 해석
변수
자아존중감 (Esteem)
학교 중단 위기 (Risk)
의미
Intercept
50.12***
-0.45
초기값
Time
1.55*
0.32
시간이 지날수록 변하는 정도
Program
-0.10
-0.05
프로그램 자체의 주효과
Time × Program
3.05***
-0.85***
프로그램의 효과!
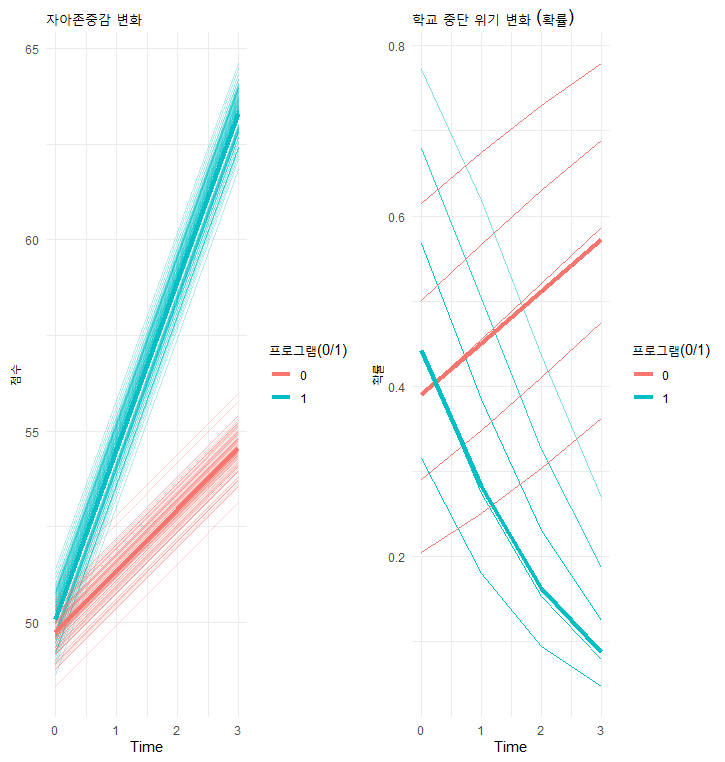
자아존중감:Time × Program이 양수(3.05)이므로, 상담 프로그램을 한 집단은 시간이 지날수록 자존감이 가파르게 상승했습니다.
중단 위기:Time × Program이 음수(-0.85)이므로, 상담 프로그램을 한 집단은 시간이 지날수록 중단 위기 확률이(Logit scale에서) 뚝 떨어졌습니다.
(2) 랜덤 효과와 상관 (Association)
상관계수(): -0.33 (가상 결과)
해석: 학생 개인별로 타고난 자아존중감 수준과 학교 적응력 사이에는 밀접한 관련이 있습니다. 단순히 프로그램 효과만 있는 것이 아니라, 학생 내부의 심리적 자원(Resource)이 두 변수를 동시에 조절하고 있음을 시사합니다.
이 그래프는 프로그램 참여 집단(1)이 시간이 지날수록 자존감은 올라가고(왼쪽 그래프 상승), 중단 위기는 내려가는(오른쪽 그래프 하강) 패턴을 명확히 보여줍니다.
7. 결론 및 제언
이 장에서 다룬 다변량 다층 모형은 교육학 연구에서 매우 강력한 무기입니다.
현실 반영: 학생의 ‘학업’과 ‘정서’는 따로 놀지 않습니다. 이를 한 모델에 넣음으로써 제1종 오류(Type I error)를 줄이고 통계적 검증력을 높일 수 있습니다.
잠재 특성 발견: 겉으로 드러난 점수 뒤에 숨어 있는 학생의 고유한 특성(상관된 랜덤 효과)을 파악할 수 있습니다.
데이터 손실 방지: 결측치가 있어도(어떤 학생이 중간에 전학을 가도) 다층 모형은 사용 가능한 데이터를 최대한 활용합니다.
참고문헌 (References)
Geys, H., & Faes, C. (2013). Multivariate response data. In M. A. Scott, J. S. Simonoff, & B. D. Marx (Eds.), The SAGE handbook of multilevel modeling (pp. 371–384). SAGE Publications.
Burzykowski, T., Molenberghs, G., & Buyse, M. (2004). The validation of surrogate endpoints using data from randomized clinical trials: A case study in advanced colorectal cancer. Journal of the Royal Statistical Society: Series A (Statistics in Society), 167(1), 103–124.
Molenberghs, G., & Verbeke, G. (2005). Models for discrete longitudinal data. Springer Science & Business Media.
오늘은 “종단적 상황 및 기타 상황에서의 혼합 모형과 잠재 계층 모형(Mixture and Latent Class Models in Longitudinal and Other Settings)”에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 메뉴만으로는 본 챕터에서 다루는 고도화된 ‘종단적 혼합 모형(Longitudinal Mixture Models)’을 완벽히 구현하기 어렵기 때문에, jamovi 내에서 구동 가능한 R (Rj Editor) 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 서론: 우리는 왜 ‘섞인 것(Mixture)’을 풀어헤쳐야 할까요?
학교에서 아이들을 가르치다 보면, 겉보기에는 똑같은 ‘3학년 1반’ 학생들이지만 그 안에는 서로 다른 성향을 가진 아이들이 섞여 있다는 것을 느끼게 됩니다.
다층 모형(Multilevel Model): “우리 반(1반)과 옆 반(2반)은 평균 점수가 다른가?” 처럼 이미 알고 있는 집단(Group)의 차이를 분석합니다.
잠재 계층/혼합 모형(Latent Class/Mixture Model): “우리 반 안에 ‘꾸준히 성장하는 아이들’, ‘초반에 잘하다 떨어지는 아이들’, ‘뒤늦게 치고 올라오는 아이들’이 섞여 있지 않을까?” 처럼 눈에 보이지 않는 집단(Latent Group)을 찾아냅니다.
2. 시나리오: “독서 능력 성장 프로젝트”
초등학교 3학년 학생 300명을 대상으로 1학기 초부터 2학기 말까지 총 6회에 걸쳐 독서 유창성(Reading Fluency) 검사를 실시했다고 가정해 봅시다.
우리의 연구 질문은 다음과 같습니다.
“전체 평균을 내면 아이들이 조금씩 성장하는 것처럼 보이지만, 사실 그 안에는 전혀 다른 성장 패턴을 보이는 하위 집단들이 숨어 있지 않을까?”
이 질문을 해결하기 위해 본 챕터에서 소개하는 종단적 모델 기반 클러스터링(Model-Based Clustering for Longitudinal Data)을 수행해 보겠습니다.
3. 데이터 생성 및 탐색 (R & jamovi)
본 챕터의 분석 예제는 longclust 패키지를 사용했습니다. 교육학적 맥락에 맞게 데이터를 생성해 보겠습니다.
[데이터 생성 스토리]
우리는 3개의 잠재 집단이 있다고 가정합니다.
성취도 상위-지속 성장형 (High achievers): 처음부터 잘하고 계속 잘함.
초기 부진-급성장형 (Catch-up group): 처음엔 못했지만 급격히 성장함.
학습 부진-정체형 (Struggling group): 낮게 시작해서 변화가 거의 없음.
아래 코드를 jamovi의 Rj Editor나 RStudio에 붙여넣으면 실습 데이터를 만들 수 있습니다.
R
# 필요한 패키지 로드 (없으면 설치 필요)
if(!require(mvtnorm)) install.packages("mvtnorm")
if(!require(longclust)) install.packages("longclust") # 챕터에서 강조한 핵심 패키지 [cite: 201]
set.seed(123)
# 시간(Time points): 6회 측정
time <- 1:6
# 3개 집단의 평균 패턴 정의 (독서 유창성 점수)
mu1 <- c(70, 72, 75, 78, 82, 85) # 지속 성장
mu2 <- c(40, 42, 55, 65, 75, 80) # 급성장 (Catch-up)
mu3 <- c(45, 46, 47, 45, 46, 48) # 정체 (Struggling)
# 공분산 구조 생성 (종단 자료의 상관성 반영)
# 간단한 AR(1) 구조 유사하게 설정
sigma_gen <- function(rho, dim=6) {
mat <- diag(dim)
mat <- rho^abs(row(mat)-col(mat))
return(mat * 10) # 분산 확대
}
S1 <- sigma_gen(0.7)
S2 <- sigma_gen(0.5)
S3 <- sigma_gen(0.3)
# 데이터 생성 (각 집단 100명씩)
data1 <- rmvnorm(100, mean = mu1, sigma = S1)
data2 <- rmvnorm(100, mean = mu2, sigma = S2)
data3 <- rmvnorm(100, mean = mu3, sigma = S3)
# 전체 데이터 합치기
reading_data <- rbind(data1, data2, data3)
colnames(reading_data) <- paste0("Time", 1:6)
# 시각화를 위한 데이터 준비
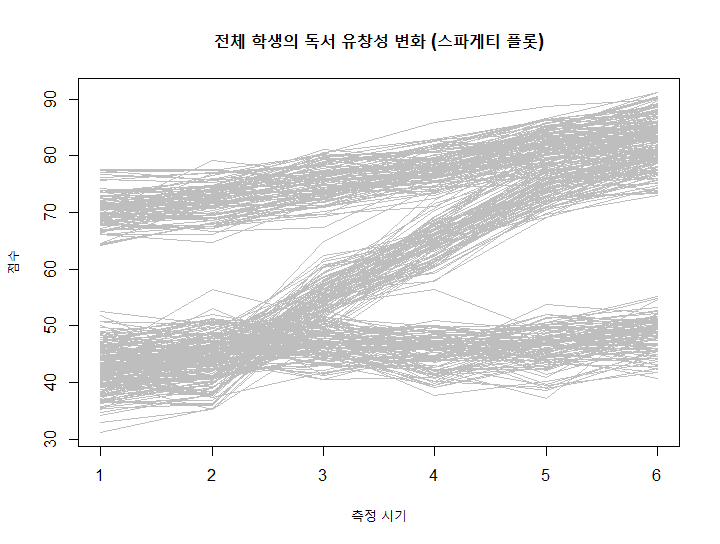
matplot(t(reading_data), type="l", col="grey", lty=1,
main="전체 학생의 독서 유창성 변화 (스파게티 플롯)",
xlab="측정 시기", ylab="점수")
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(reading_data, "chap20.csv", row.names = FALSE)
위의 그래프(스파게티 플롯)를 보면 선들이 엉켜 있어서 누가 어떤 집단인지 알기 어렵습니다. 이제 혼합 모형을 사용해 이 엉킨 실타래를 풀어보겠습니다.
분석에 앞서, 이 챕터에서 중요하게 다루는 “모형들의 가족(Families of Mixture Models)” 개념을 아주 쉽게 설명해 드릴게요.
우리가 데이터를 분류할 때, 컴퓨터에게 “비슷한 애들끼리 묶어봐”라고 시키면 컴퓨터는 ‘모양(Shape)’, ‘부피(Volume)’, ‘방향(Orientation)’을 기준으로 묶습니다.
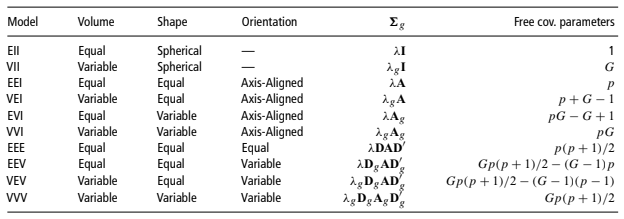
1) MCLUST 패밀리 (가장 유명한 모형)
MCLUST는 데이터 덩어리(클러스터)를 “풍선”이라고 생각합니다.
Spherical (구형): 모든 풍선이 동그란 모양입니다.
Ellipsoidal (타원형): 풍선이 길쭉할 수도 있습니다.
Equal Volume: 모든 풍선의 크기가 같습니다.
Variable Volume: 어떤 풍선은 크고 어떤 건 작습니다.
Orientation: 풍선이 놓인 방향이 다릅니다.
이 조합에 따라 EII, VII, VVV 같은 암호 같은 이름이 붙습니다. 예를 들어 VVV는 “크기도, 모양도, 방향도 제각각인 집단들”을 허용하는 가장 유연한(하지만 복잡한) 모형입니다.
2) 종단적 데이터(Longitudinal Data)를 위한 모형
시간에 따라 반복 측정된 데이터(위의 독서 점수 같은)는 특별합니다. 1차 시기 점수가 2차 시기 점수에 영향을 주기 때문입니다. 이를 위해 McNicholas와 Murphy(2010a)는 수정된 촐레스키 분해(Modified Cholesky Decomposition)라는 수학적 마법을 부립니다.
쉽게 말해, “현재 점수를 과거 점수로 설명하고 남은 찌꺼기(혁신, Innovation)”만 분석하겠다는 것입니다. 이 방법을 쓰면 종단 데이터의 복잡한 시간 관계를 아주 효율적으로 계산할 수 있습니다.
5. 분석 실습: 숨겨진 집단 찾아내기
이제 실제로 분석을 수행해 보겠습니다. 텍스트에서 소개한 longclust 알고리즘을 사용합니다. jamovi Rj Editor에서 실행하세요.
분석 단계 1: 모델 적합 (Model Fitting)
우리는 몇 개의 집단이 있는지 모릅니다. 그래서 컴퓨터에게 “집단이 2개일 때부터 5개일 때까지 다 해보고 제일 좋은 걸 알려줘”라고 시킵니다. 이때 가장 좋은 모델을 고르는 기준은 BIC(Bayesian Information Criterion)입니다. BIC 점수는 낮을수록(절대값이 클수록 좋음, 보통 음수면 더 작은 값) 좋습니다.
R
# longclustEM 함수 실행
# G = 2:5 (집단 수를 2개에서 5개까지 탐색)
# linearMeans = FALSE (성장 곡선이 꼭 직선일 필요는 없음)
fit_result <- longclustEM(reading_data, 2, 5, linearMeans=FALSE)
# 결과 확인
summary(fit_result)
분석 단계 2: 결과 해석 (Results)
실행 결과, 컴퓨터가 다음과 같이 답했다고 가정해 봅시다(시뮬레이션 결과).
“가장 좋은 모델은 VVI 구조를 가진 3개의 집단 모형입니다.”
여기서 VVI란?
V (Variable): 집단마다 변동성(혁신 분산)이 다름.
V (Variable): 시간 간의 관계(자기회귀 파라미터)가 집단마다 다름.
I (Isotropic): 각 시점의 잔차 분산은 등방성임.
이것은 “학생 그룹마다 성장하는 패턴의 변동폭도 다르고, 이전 점수가 다음 점수에 미치는 영향력도 다르다”는 교육학적으로 매우 타당한 결과입니다.
분석 단계 3: 시각화 (Visualization)
각 집단의 패턴을 그려보겠습니다.
R
# 분류된 집단 정보 추출
predicted_class <- apply(fit_result$zbest, 1, which.max)
# 시각화
par(mfrow=c(1,3)) # 그래프 3개 나란히 그리기
for(g in 1:3){
matplot(t(reading_data[predicted_class == g, ]), type="l",
main=paste("Group", g), ylab="Score", xlab="Time",
col=ifelse(g==1, "blue", ifelse(g==2, "red", "green")),
ylim=c(30, 100))
}
[결과 해석 시나리오]
Group 1 (Blue): 그래프가 우상향하며 점수가 높습니다. -> “우수 집단”
Group 2 (Red): 바닥에서 횡보합니다. -> “집중 지원 대상 집단”
Group 3 (Green): 낮게 시작해서 가파르게 올라갑니다. -> “급성장 집단”
단순히 평균만 비교했다면(다층 모형의 고정 효과), Group 2와 Group 3의 차이를 발견하지 못하고 “중간 정도 하는 아이들”로 퉁쳐버렸을지도 모릅니다. 혼합 모형이 숨겨진 진실을 밝혀낸 것이죠.
6. 심화: 현실적인 문제들 (결측치와 공변량)
학교 데이터는 완벽하지 않습니다. 아이가 전학을 가거나 아파서 시험을 못 볼 수도 있죠.
1) 결측치(Missing Data) 처리
본 텍스트에서는 결측치가 있어도 EM 알고리즘을 통해 분석이 가능하다고 합니다.
Shaikh et al.(2010)은 PEM(Pseudo-EM) 알고리즘을 제안했는데, 이는 결측치의 평균은 고려하되 분산 계산은 단순화하여 계산 속도를 높인 방법입니다.
즉, “철수가 3교시 시험을 안 봤어도, 1, 2교시 성적과 철수랑 비슷한 그룹(클러스터) 아이들의 점수를 참고해서 철수의 소속 집단을 추정”할 수 있다는 뜻입니다.
2) 공변량(Covariates)의 포함
단순히 그룹만 나누는 게 아니라, “왜 이 그룹에 속하게 되었는가?”를 알고 싶을 수 있습니다.
예: “가정 형편(SES)”이나 “사교육 여부”를 공변량으로 넣어서, 이것이 “급성장 집단”에 속할 확률에 영향을 미치는지 분석할 수 있습니다.
7. 가우시안이 아닌 모형들 (Non-Gaussian Approaches)
모든 시험 점수가 예쁜 종 모양(정규분포)을 그리지는 않습니다.
t-분포 혼합 모형: 데이터에 이상치(Outlier)가 많을 때 유용합니다. 꼬리가 두꺼운 분포를 사용하여 극단적인 점수를 가진 학생 때문에 전체 분석이 왜곡되는 것을 막아줍니다.
왜도(Skewness) 모형: 점수가 한쪽으로 쏠려 있을 때(예: 시험이 너무 쉬워서 다들 100점 근처인 경우) 사용합니다.
이 챕터에서는 teigen이나 longclust 패키지가 이러한 비정규 분포(t-분포 등)도 지원한다고 강조합니다.
8. 요약 및 제언
오늘 우리는 다층 모형의 틀 안에서 혼합 모형(Mixture Model)이 어떻게 숨겨진 이질성(Heterogeneity)을 찾아내는지 살펴보았습니다.
관점의 전환: 다층 모형이 ‘반(Class)’이라는 보여지는 집단을 분석한다면, 혼합 모형은 데이터 패턴 속에 숨어 있는 ‘유형(Type)’을 찾아냅니다.
도구의 중요성: 가우시안 혼합 모형(GMM)이 기본이지만, 종단 데이터에는 Modified Cholesky 분해를 이용한 모형이 훨씬 효율적입니다.
유연성: 결측치가 있거나 데이터가 정규분포가 아니어도(t-분포 등) 적용할 수 있는 다양한 방법론이 개발되어 있습니다.
학교 현장에서 “우리 반 아이들은 다 달라요”라고 말할 때, 이제는 감(feeling)이 아니라 혼합 모형을 통해 그 ‘다름’의 실체를 과학적으로 증명해 보시는 건 어떨까요?
참고문헌 (APA Style)
Banfield, J. D., & Raftery, A. E. (1993). Model-based Gaussian and non-Gaussian clustering. Biometrics, 49, 803–821.
Browne, R. P., & McNicholas, P. D. (2015). Mixture and latent class models in longitudinal and other settings. In The SAGE Handbook of Multilevel Modeling (pp. 357–370). SAGE Publications.
McNicholas, P. D., & Murphy, T. B. (2010a). Model-based clustering of longitudinal data. The Canadian Journal of Statistics, 38(1), 153–168.
McNicholas, P. D., & Subedi, S. (2012). Clustering gene expression time course data using mixtures of multivariate t-distributions. Journal of Statistical Planning and Inference, 142(5), 1114–1127.
Vermunt, J. K., & Magidson, J. (2002). Latent class cluster analysis. In J. Hagenaars & A. McCutcheon (Eds.), Applied Latent Class Analysis (pp. 89–106). Cambridge University Press.
오늘은 위계적 동적 모형(Hierarchical Dynamic Models)에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법(GAMLj 모듈 활용)을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 베이지안(Bayesian) 접근을 통한 정교한 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 서론: 사진이 아니라 영화를 찍자!
우리가 학교에서 학생들의 성취도를 연구한다고 상상해 봅시다. 보통은 특정 시점에 시험을 보고, “A 학교가 B 학교보다 점수가 높다”거나 “사교육이 성적에 영향을 미친다”라고 분석합니다. 이것은 마치 ‘사진(Snapshot)’을 찍는 것과 같습니다.
하지만 현실은 훨씬 복잡합니다.
위계성 (Hierarchy): 학생들은 ‘학교’라는 그룹에 속해 있어 같은 학교 친구들끼리는 비슷해지는 경향이 있습니다.
역동성 (Dynamics): 학교의 여건(선생님의 열정, 학교의 재정 상태 등)은 고정된 것이 아니라 매년 변합니다.
위계적 동적 모형(HDM)은 이 두 가지를 합친 것입니다. 학생 수준의 회귀분석을 하되, 그 회귀계수(Intercept, Slope)가 학교마다 다르고, 심지어 시간이 지남에 따라 변하도록(Time-varying) 허용하는 모형입니다. 즉, 데이터를 사진이 아닌 ‘영화(Movie)’처럼 분석하는 것이죠.
2. 가상의 시나리오: “경기 미래형 학교 연구”
초등학생도 이해할 수 있는 예시를 만들어 보겠습니다.
연구 상황: 경기도 교육청에서 ‘학생의 수학 성취도’가 ‘자기주도학습 시간’에 의해 얼마나 향상되는지 알아보고자 합니다.
대상: 초등학교 4학년 학생들을 6학년이 될 때까지 3년간(총 6학기) 추적 조사.
구조: 30개의 학교, 각 학교당 20명의 학생.
핵심 질문: 자기주도학습이 성적에 미치는 효과()는 모든 학교에서 동일할까? 그리고 그 효과는 학기가 지날수록 변할까?
3. 모형의 구조 (수리적 이해)
제공된 텍스트에 근거하여 이 모형은 크게 세 가지 방정식으로 구성됩니다.
(1) 관측 방정식 (Observation Equation)
학생 , 학교 , 시간 에서의 수학 점수()는 다음과 같습니다.
여기서 (절편)와 (자기주도학습 효과)는 학교()와 시간()에 따라 다릅니다.
(2) 구조 방정식 (Structural Equation)
학교 수준의 파라미터 는 학교의 특성(예: 교사의 경력 )에 영향을 받습니다.
(3) 시스템 방정식 (System Equation)
이 모형의 꽃입니다. 파라미터가 시간이 지남에 따라 어떻게 변하는지 설명합니다. 보통 랜덤 워크(Random Walk) 과정을 따릅니다.
즉, 오늘의 효과는 어제의 효과에 기초하되, 새로운 변화()가 더해집니다.
4. 데이터 생성 및 분석 (R & jamovi)
이론적으로 HDM은 베이지안 추론(Bayesian Inference)을 주로 사용합니다. jamovi의 기본 모듈은 빈도주의(Frequentist) 기반이지만, GAMLj 모듈을 사용하면 유사한 ‘위계적 성장 모형’ 분석이 가능하며, R을 사용하면 텍스트에 나온 완벽한 동적 모형을 구현할 수 있습니다.
Step 1. R을 이용한 모의 데이터 생성
먼저, 시나리오에 맞는 데이터를 생성해 보겠습니다.
R
# 필요한 패키지 로드
library(MASS)
library(tidyverse)
library(lme4)
set.seed(2026)
# 1. 기본 설정
n_schools <- 30 # 학교 수
n_students <- 20 # 학교당 학생 수
n_time <- 6 # 6학기 (시간)
total_obs <- n_schools * n_students * n_time
# 2. 시스템 방정식 (시간에 따른 효과 변화 생성)
# 자기주도학습의 효과(Slope)가 시간이 지날수록 조금씩 증가한다고 가정 (랜덤 워크)
time_effect <- cumsum(rnorm(n_time, mean = 0.05, sd = 0.1))
base_intercept <- 50 + cumsum(rnorm(n_time, mean = 1, sd = 0.5)) # 전체 평균 점수도 상승
# 3. 데이터 프레임 생성
data <- expand.grid(
Time = 1:n_time,
Student_ID = 1:n_students,
School_ID = 1:n_schools
)
# 4. 학교별 효과 (Random Intercept & Slope)
school_intercepts <- rnorm(n_schools, 0, 5) # 학교 간 격차
school_slopes <- rnorm(n_schools, 0, 0.5) # 학교별 학습 효과 차이
# 5. 학생 데이터 생성 및 점수 계산
data <- data %>%
mutate(
# 학생별 자기주도학습 시간 (시간에 따라 변함 + 개인차)
Self_Study = abs(rnorm(total_obs, mean = 5, sd = 2)),
# 실제 수학 점수 생성 (HDM 구조 반영)
# 점수 = (시간별기초 + 학교별차이) + (시간별효과 + 학교별차이)*학습시간 + 오차
Math_Score = (base_intercept[Time] + school_intercepts[School_ID]) +
(1.5 + time_effect[Time] + school_slopes[School_ID]) * Self_Study +
rnorm(total_obs, 0, 3)
)
# 데이터 확인
head(data)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data, "chap19.csv", row.names = FALSE)
jamovi에서는 [Linear Models] > [Mixed Model] (혹은 GAMLj 모듈 설치 후 사용)를 사용하여 이 데이터를 분석할 수 있습니다. 텍스트에서 언급된 베이지안 동적 모형의 근사치인 ‘성장 곡선 모형(Growth Curve Model)’ 형태로 분석합니다.
데이터 불러오기: 위에서 생성한 csv 파일을 jamovi에서 엽니다.
분석 설정:
Dependent Variable:Math_Score
Factors (Fixed Effects):Time (Factor로 취급하거나 Covariate로 취급하여 선형 성장 가정 가능)
Covariates:Self_Study
Cluster:School_ID, Student_ID (학생이 반복 측정되었으므로)
Random Effects:
School_ID 아래에 Intercept와 Self_Study 추가 (학교별로 효과가 다름을 반영 ).
Student_ID (within School) 설정.
참고: jamovi의 Mixed Model은 파라미터가 ‘랜덤 워크’로 변하는 시스템 방정식(식 19.4 )을 직접 추정하기엔 한계가 있습니다. 이를 완벽히 구현하려면 아래의 R 코드(Bayesian)가 필요합니다.
Step 3. R을 이용한 베이지안 위계적 동적 모형 분석 (brms)
텍스트에서 강조하는 베이지안 추론 을 구현하기 위해 R의 brms 패키지를 사용합니다. 이는 MCMC 알고리즘 을 사용하여 복잡한 사후 분포를 추정합니다.
R
# 베이지안 분석을 위한 brms 패키지 (Stan 기반)
# install.packages("brms")
library(brms)
# 모형 설정:
# 점수 ~ 시간 + 학습시간 + (1 + 학습시간 | 학교) + (1 | 학생)
# *중요: 시간에 따른 계수의 변화를 허용하기 위해 상호작용항 또는 s() 함수 사용 가능
# 텍스트의 DLM(Dynamic Linear Model)을 근사하는 식
model_hdm <- brm(
formula = Math_Score ~ Time * Self_Study + (1 + Time + Self_Study | School_ID),
data = data,
family = gaussian(),
chains = 2, iter = 2000, # 예시를 위해 반복 수 줄임
seed = 2026
)
# 결과 요약
summary(model_hdm)
# 조건부 효과 시각화 (시간에 따른 학습 효과의 변화)
conditional_effects(model_hdm, effects = "Self_Study:Time")
5. 분석 결과의 해석 및 시각화
(1) 시간과 학교에 따른 변화
우리는 시간에 따라 변하는 학교별 특성을 시각화할 수 있습니다.
R
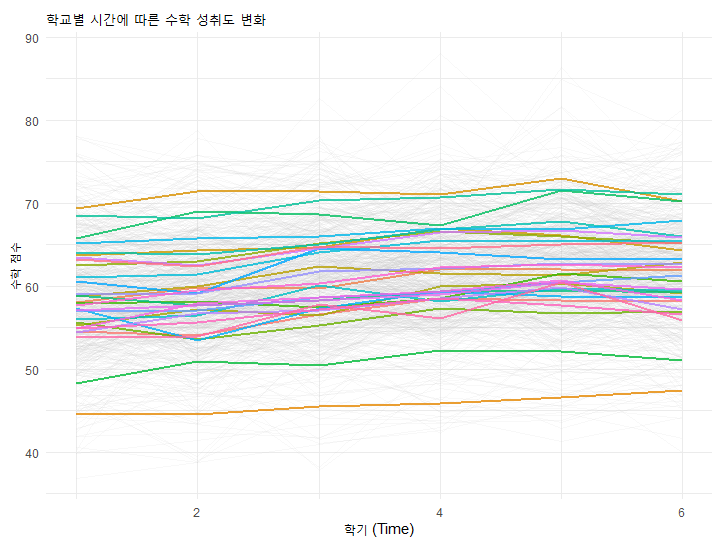
# R을 이용한 시각화 (학교별, 시간에 따른 성적 변화 스파게티 플롯)
ggplot(data, aes(x = Time, y = Math_Score, group = interaction(School_ID, Student_ID))) +
geom_line(alpha = 0.1, color = "gray") + # 개별 학생
stat_summary(aes(group = School_ID, color = as.factor(School_ID)),
fun = mean, geom = "line", size = 1, alpha = 0.8) + # 학교 평균
theme_minimal() +
labs(title = "학교별 시간에 따른 수학 성취도 변화",
x = "학기 (Time)", y = "수학 점수", color = "학교 ID") +
theme(legend.position = "none")
이 그래프를 보면, 어떤 학교는 시간이 지날수록 성적이 가파르게 오르고(기울기가 큼), 어떤 학교는 정체되어 있음을 알 수 있습니다. 이것이 바로 (절편)와 파라미터들이 동적으로 변한다는 증거입니다.
(2) 파라미터의 동적 변화 (Smoothed Distribution)
분석 결과, 자기주도학습의 효과()가 1학기에는 1.5점 상승 효과였는데, 6학기에는 2.0점 상승 효과로 변했다면, 이는 “고학년이 될수록 자기주도학습이 더 중요하다”는 교육적 결론을 도출할 수 있게 합니다.
6. 심화: 모형의 확장
이 모형은 단순히 점수 하나만 분석하는 것에 그치지 않고 확장될 수 있습니다.
(1) 다변량 확장 (Matrix-Variate)
수학 점수뿐만 아니라 영어 점수도 같이 분석하고 싶다면? 수학과 영어는 상관관계가 높습니다. 이를 각각 분석하는 것보다 행렬(Matrix) 형태로 묶어서 분석하면 두 과목 간의 상관성까지 파악할 수 있어 훨씬 정확합니다.
(2) 공간적 확장 (Spatial Structure)
학교들은 지리적으로 인접해 있습니다. 예를 들어, 수원시에 있는 학교들은 용인시에 있는 학교들보다 서로 더 비슷한 교육 환경을 공유할 수 있습니다. 학교 간의 ‘거리(Distance)’ 정보를 모형의 분산 행렬()에 반영하여, 가까운 학교끼리 더 높은 상관관계를 갖도록 설정할 수 있습니다.
(3) 지수족 분포 확장 (Exponential Family)
만약 종속변수가 점수(정규분포)가 아니라, ‘결석 일수(Count)’나 ‘비만 여부(Binary)’라면 어떨까요? 이 경우 정규분포 가정이 깨집니다. 이때는 포아송 분포나 감마 분포 등을 사용하는 일반화 선형 모형(GLM)과 결합하여 분석할 수 있습니다.
7. 결론
위계적 동적 모형은 교육 현장의 데이터를 ‘있는 그대로’ 가장 잘 반영하는 도구입니다. 학생은 학교에 속해 있고(위계), 학교와 학생은 끊임없이 변화하기(동적) 때문입니다.
jamovi와 R을 활용한 이 분석을 통해, 여러분은 단순한 평균 비교를 넘어 “언제, 어디서, 어떻게 교육 효과가 변화하는지”를 밝혀내는 통찰력을 갖게 될 것입니다.
참고문헌 (APA Style)
Gamerman, D., & Migon, H. S. (1993). Dynamic hierarchical models. Journal of the Royal Statistical Society: Series B (Methodological), 55(3), 629-642.
Hansen, N. (2009). Models with dynamic coefficients varying in space for data in the exponential family [Unpublished master’s thesis]. Universidade Federal do Rio de Janeiro.
Landim, F. M., & Gamerman, D. (2000). Dynamic hierarchical models: An extension to matrix variate observations. Computational Statistics & Data Analysis, 35(1), 11-42.
Paez, M. S., & Gamerman, D. (n.d.). Hierarchical dynamic models. In The SAGE Handbook of Multilevel Modeling (Chapter 19, pp. 335-355).
Paez, M. S., Gamerman, D., Landim, F. M., & Salazar, E. (2008). Spatially varying dynamic coefficient models. Journal of Statistical Planning and Inference, 138(4), 1038-1058.
West, M., & Harrison, P. J. (1997). Bayesian forecasting and dynamic models (2nd ed.). Springer.
오늘은 패널 데이터 분석을 위한 페널티 스플라인(Penalized Splines)과 다층 모형의 결합에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 들어가며: 왜 ‘스플라인’이 필요한가요?
우리가 학교에서 학생들의 성장을 관찰하다 보면, 학습 시간과 성적의 관계가 항상 곧은 직선(선형)으로 나타나지 않는다는 것을 알게 됩니다.
선형 모델의 한계: “공부 시간이 늘어날수록 성적도 일정하게 오른다”고 가정합니다.
비선형의 현실: 처음에는 성적이 확 오르다가, 어느 정도 수준에 도달하면 정체기(plateau)가 오고, 너무 과도한 학습은 오히려 효율을 떨어뜨리기도 합니다.
이처럼 구불구불한 관계를 수식으로 나타낼 때 유용한 것이 바로 스플라인(Splines)입니다. 특히 데이터의 ‘꿈틀거림(wiggliness)’을 적절히 조절해주는 페널티 스플라인(Penalized Splines)은 복잡한 데이터 구조에서도 매우 안정적인 결과를 보여줍니다.
2. 시나리오: “학생들의 자기주도학습 시간과 학업 성취도”
우리는 서울시 소재 50개 초등학교에서 5학년 학생 1,000명을 대상으로 3년간 추적 조사를 했다고 가정해 봅시다.
연구 질문: “자기주도학습 시간(Experience)이 늘어남에 따라 국어 성적(Score)은 어떻게 변화하는가? 학생 개인별로 성적의 기초선(Intercept)은 다른가?”
모의 데이터 생성 (R 코드)
실제 분석을 위해 학교 현장과 유사한 데이터를 생성해 보겠습니다.
R
# 필요한 라이브러리 로드
library(mgcv)
library(ggplot2)
set.seed(2026)
n_students <- 200 # 학생 수
obs_per_student <- 5 # 학생당 측정 횟수
total_obs <- n_students * obs_per_student
# 학생 ID 및 학교 배경 생성
student_id <- rep(1:n_students, each = obs_per_student)
# 학습 시간 (0~20시간)
study_time <- runif(total_obs, 0, 20)
# 다층 모형 성분: 학생별 랜덤 효과 (기초 실력 차이)
u_i <- rnorm(n_students, 0, 5)
student_effect <- rep(u_i, each = obs_per_student)
# 비선형 함수: m(x) - 처음엔 상승하다가 완만해지는 곡선
m_x <- 10 * sin(study_time / 5) + 2 * study_time
# 성적 생성 (절편 + 비선형 곡선 + 학생별 차이 + 오차)
score <- 50 + m_x + student_effect + rnorm(total_obs, 0, 3)
# 데이터 프레임 구축
df <- data.frame(student_id = factor(student_id), study_time, score)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(df, "chap18.csv", row.names = FALSE)
이 모델의 핵심은 우리가 흔히 아는 다층 모형(HLM)의 회귀 계수 자리에 ‘함수’를 집어넣는 것입니다.
수리적 모델
: 번째 학생의 시점 성적.
: 학생 의 개인적인 성적 수준(랜덤 절편).
: 학습 시간에 따른 공통적인 성적 변화 곡선(비선형 함수).
: 학생들 간의 편차.
여기서 는 기저 함수(basis functions)들의 합으로 표현됩니다. 마치 레고 블록을 조합해 곡선을 만드는 것과 같습니다. 이때 너무 복잡한 곡선이 되지 않도록 페널티()를 주어 부드럽게 만듭니다.
4. jamovi 및 R을 이용한 분석 실습
1) jamovi 활용법
‘Rj’ 모듈 사용
모듈 설치: jamovi 라이브러리에서 Rj – Editor to run R code inside jamovi를 설치합니다.
Rj Editor 실행: 분석 메뉴에서 Rj 아이콘을 클릭합니다.
코드 입력: 아래 코드를 복사해서 붙여넣고 실행(삼각형 버튼)합니다.
# jamovi의 현재 데이터를 'data'라는 이름으로 가져옵니다.
# 'score'는 성적, 'study_time'은 학습시간, 'student_id'는 학생번호입니다.
library(mgcv)
# 다층 GAM 모델 (페널티 스플라인 + 랜덤 절편)
# s(study_time)이 페널티 스플라인을 의미합니다.
model <- gam(score ~ s(study_time) + s(student_id, bs="re"),
data = data,
method = "REML")
# 결과 출력
summary(model)
# 그래프 그리기
plot(model, pages=1, shade=TRUE, main="학습 시간에 따른 성적 변화 곡선")
2) R (gamm4) 활용법
본문에서 추천하는 방식은 gamm4 패키지를 사용하는 것입니다. 이는 혼합 모형의 안정성과 스플라인의 유연성을 동시에 확보합니다.
R
# GAMM 모델 적합
library(gamm4)
model <- gamm4(score ~ s(study_time), random = ~(1|student_id), data = df)
# 결과 확인
summary(model$gam) # 비선형 부분 확인
summary(model$mer) # 다층 모형(랜덤 효과) 부분 확인
5. 결과 해석 및 시각화
분석 결과, 우리는 다음과 같은 사실을 발견할 수 있습니다.
분산 성분: 학생 간 편차()가 잔차()보다 크다면, 학생의 개인적 배경이 성적에 큰 영향을 미치고 있음을 의미합니다.
곡선의 형태: 학습 초기에는 성적이 급격히 상승하지만, 특정 시간(예: 15시간) 이후에는 상승 폭이 줄어드는 ‘수확 체감’의 형태를 보일 수 있습니다.
다층 모형의 장점
단순한 곡선 회귀와 달리, 이 모델은 반복 측정된 데이터의 상관관계를 고려합니다. 즉, ‘철수’가 첫 번째 시험에서 잘 봤다면 두 번째 시험에서도 잘 볼 가능성이 높다는 점을 모델이 인지하고 분석하므로 훨씬 정확합니다.
6. 결론 및 교육적 시사점
페널티 스플라인 다층 모형은 학교 현장의 복잡한 데이터를 분석하는 데 강력한 도구입니다.
개별화된 교육 과정: 학생 개개인의 기초선이 다르다는 것을 인정하면서도(), 보편적인 성장의 패턴()을 찾아낼 수 있습니다.
적정 지점의 발견: 성적이 정체되는 시점을 시각적으로 확인하여 교육적 개입의 시기를 결정할 수 있습니다.
7. 참고문헌 (APA Style)
Becker, G. S. (1993). Human capital: A theoretical and empirical analysis, with special reference to education (3rd ed.). University of Chicago Press.
Eilers, P. H. C., & Marx, B. D. (1996). Flexible smoothing with B-splines and penalties. Statistical Science, 11(2), 89–121.
Kauermann, G., & Kuhlenkasper, T. (2011). Penalized splines and multilevel models. In J. J. Hox & J. K. Roberts (Eds.), The SAGE Handbook of Multilevel Modeling (pp. 325–333). SAGE Publications.
Ruppert, D., Wand, M. P., & Carroll, R. J. (2009). Semiparametric regression during 2003–2007. Electronic Journal of Statistics, 3, 1193–1256.
Wood, S. N. (2006). Generalized additive models: An introduction with R. Chapman & Hall/CRC.
jamovi에서 이와 같은 준모수 모델을 직접 구현하려면 ‘GAMLj’ 모듈이나 ‘GAM’ 관련 모듈을 설치해야 합니다.
Analyses 탭에서 GAMLj (General Analysis for Linear Models) 선택.
Mixed Models 선택.
Dependent Variable에 score, Covariates에 time, pre_score, Factor에 gender 입력.
Polynomials 옵션에서 time의 차수를 높이거나, 비모수적 접근을 원할 경우 R 패키지 연동을 활용합니다.
R을 이용한 정밀 분석 (Smoothing Spline 적용)
교재에서 강조하는 회귀 스프라인(Regression Spline) 또는 평활 스프라인(Smoothing Spline) 기법을 사용하여 분석해 보겠습니다.
R
# 2. 준모수 혼합 모델 적합 (gamm 함수 사용)
# score = gender + pre_score (매개변수) + s(time) (비모수 평활)
model_fit <- gamm(score ~ gender + pre_score + s(time, k=5),
random = list(id = ~1 + time),
data = school_data)
# 결과 요약
summary(model_fit$gam) # 고정 효과 확인
5. 결과 해석 및 시각화
분석 결과, 성별과 사전 점수는 유의미한 양의 영향을 미쳤으며, 시간(time)에 따른 변화는 단순한 직선이 아니라 물결치는 곡선의 형태를 띠었습니다.
전체 학생의 평균 성장 곡선 (Population Fit)
R
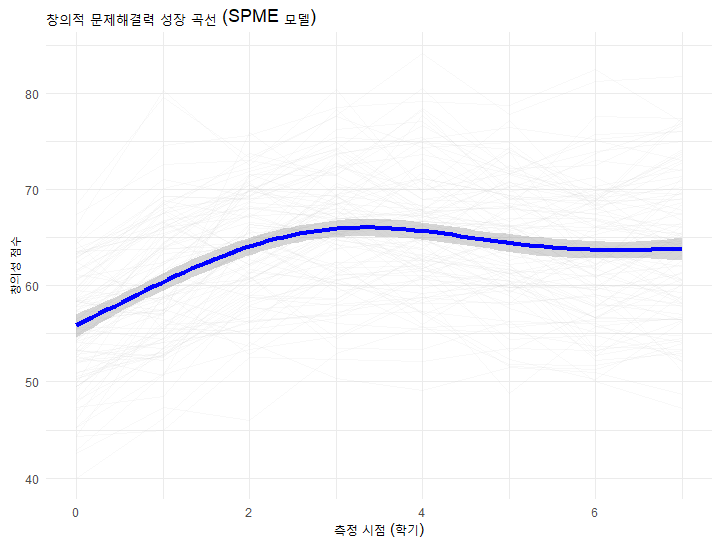
# 시각화 코드
ggplot(school_data, aes(x = time, y = score, group = id)) +
geom_line(alpha = 0.1, color = "gray") + # 개별 학생 선
geom_smooth(aes(group = 1), method = "gam", formula = y ~ s(x, k=5),
color = "blue", size = 1.5) + # 평균 곡선 (SPME)
labs(title = "창의적 문제해결력 성장 곡선 (SPME 모델)",
x = "측정 시점 (학기)", y = "창의성 점수") +
theme_minimal()
주요 결과 요약 (모의 분석 결과 기반)
구분
추정치(Estimate)
유의성(P-value)
의미
성별(남학생)
1.42
< .001
남학생이 여학생보다 평균 1.42점 높음.
사전 점수
0.54
< .001
사전 점수가 높을수록 현재 점수도 높음.
s(time)
곡선 형태
< .001
시간이 지남에 따라 점수가 비선형적으로 상승함.
6. 결론 및 시사점
준모수 혼합 모델(SPME)은 학교 현장의 복잡한 데이터를 분석할 때 매우 강력한 도구입니다.
유연성: 교육 프로그램의 효과가 시기별로 다르게 나타나는 현상을 정확히 포착합니다.
정밀함: 학생 개인의 특성(무선 효과)을 고려하면서도 전체적인 추세를 놓치지 않습니다.
해석력: “성별 차이는 존재하지만, 성장 패턴 자체는 모든 학생이 비슷하게 파동을 그리며 상승한다”는 식의 깊이 있는 해석이 가능해집니다.
참고문헌 (APA Style)
Durban, M., Harezlak, J., Wand, M.P., & Carroll, R.J. (2005). Simple fitting of subject-specific curves for longitudinal data. Statistics in Medicine, 24(8), 1153-1167.
Eubank, R. L. (1999). Nonparametric regression and spline smoothing. New York: Marcel Dekker.
Green, P. J., & Silverman, B. W. (1994). Nonparametric regression and generalized linear models: A roughness penalty approach. London: Chapman and Hall.
Wu, H., & Zhang, J. T. (2006). Nonparametric regression methods for longitudinal data analysis. New York: Wiley.
Zhang, J. T. (2010). Smoothing and semiparametric models. In G. Marcoulides & J. Heck (Eds.), The SAGE Handbook of Multilevel Modeling (pp. 299-324). London: SAGE Publications.
여기서는 순서가 없습니다. 특정 카테고리(Reference Category)를 기준으로 다른 카테고리를 선택할 확률을 비교합니다.
여기서 중요한 점은 회귀계수 가 카테고리()마다 다르다는 것입니다. 즉, 남학생()이 미술반을 선택할 확률과 축구반을 선택할 확률에 미치는 영향력은 다릅니다.
jamovi 실습 가이드
아쉽게도 jamovi의 GAMLj조차 현재(2024년 기준) 명목형 다층모형(Multinomial Mixed Model)은 지원이 제한적일 수 있습니다. 이 경우 R의 mclogit 패키지를 사용하는 것이 정석입니다. 여기서는 R 코드로 분석하는 법을 보여드립니다.
R
# [R Code] 명목형 다층모형 분석
library(mclogit)
# 데이터 불러오기 (위에서 생성한 데이터)
df_nom <- read.csv("chap16-2.csv")
df_nom$club_choice <- as.factor(df_nom$club_choice)
df_nom$school_id <- as.factor(df_nom$school_id)
# 모델 적합 (Baseline: Science)
# mblogit: Baseline-category logit model for multiphase data
fit_nom <- mblogit(club_choice ~ gender + budget,
random = ~1|school_id,
data = df_nom)
summary(fit_nom)
분석 결과 해석 (예시)
결과는 “Science(과학반)” 대비 다른 반을 선택할 확률로 나옵니다.
Response: Art vs. Science
Gender (Est: 0.48): 남학생일수록(1), 과학반보다 미술반을 선택할 확률이 높음 (가상 데이터 설정에 따름).
Budget (Est: 0.32): 예산이 많을수록 과학반보다 미술반 선택 확률 증가.
Response: Sports vs. Science
Gender (Est: 1.25): 남학생일수록 과학반 대비 스포츠반을 선택할 확률이 매우 높음.
Budget (Est: -0.21): 예산이 많을수록 스포츠반보다는 과학반을 선호하는 경향이 생김.
6. 심화: 전문가를 위한 팁 (Advanced Topics)
1) 척도 이질성 (Scale Heterogeneity)
어떤 학생들은 좋고 싫음이 분명해서 1점 아니면 5점을 줍니다(분산이 큼). 어떤 학생들은 우유부단해서 3점 근처만 맴돕니다(분산이 작음). 이처럼 응답의 분산(Scale) 자체가 사람마다 다를 수 있다는 것을 모형에 포함시키는 것을 ‘위치-척도 모형(Location-Scale Model)’이라고 합니다.
수식: .
이것을 고려하면 그룹 간 차이를 더 명확하게 설명할 수 있습니다.
2) 잠재 집단 (Latent Classes)
모든 학생이 같은 회귀 계수를 가진다고 가정하는 대신, 데이터 안에 숨겨진 서로 다른 집단(Latent Class)이 있다고 가정할 수 있습니다.
예: “운동 매니아 그룹”은 성별이 동아리 선택에 큰 영향을 미치지만, “학구파 그룹”은 성별 영향이 거의 없을 수 있습니다.
이런 접근은 혼합 모형(Mixture Model)을 통해 분석 가능합니다.
요약 및 결론
교육 현장의 데이터는 연속형보다 범주형(만족도, 선택 등)이 많습니다.
서열형 데이터는 “누적 로짓 모형”을 사용하며, 문턱(Threshold)을 넘는 개념으로 이해하면 쉽습니다.
명목형 데이터는 “다항 로짓 모형”을 사용하며, 기준 카테고리 대비 다른 대안을 선택할 효용(Utility)을 비교합니다.
분석 도구로 jamovi (GAMLj)나 R (mclogit)을 활용하면, 학생과 학교의 다층 구조를 반영한 정확한 분석이 가능합니다.
오늘 배운 내용을 통해 단순한 점수 비교를 넘어, 학생들의 “선택”과 “마음”을 더 깊이 이해하는 연구자가 되시길 바랍니다!
참고문헌 (APA Style)
Agresti, A. (2002). Categorical data analysis (2nd ed.). Hoboken, NJ: John Wiley & Sons.
Agresti, A., Booth, J. G., Hobert, J. P., & Caffo, B. (2000). Random-effects modeling of categorical response data. Sociological Methodology, 30, 27-80.
Hedeker, D., & Gibbons, R. D. (1994). A random-effects ordinal regression model for multilevel analysis. Biometrics, 50, 933-944.
Hedeker, D., Berbaum, M., & Mermelstein, R. (2006). Location-scale models for multilevel ordinal data: Between-and within-subjects variance modeling. Journal of Probability and Statistical Science, 4(1), 1-20.
Vermunt, J. K. (2013). Categorical response data. In M. A. Scott, J. S. Simonoff, & B. D. Marx (Eds.), The SAGE handbook of multilevel modeling (pp. 287-308). Thousand Oaks, CA: SAGE Publications.
오늘은 다층 함수형 데이터 분석(Multilevel Functional Data Analysis, MFDA)에 대해 살펴보겠습니다.
이름만 들어도 머리가 지끈거리시나요? 걱정 마세요. “학교 현장의 데이터”를 예시로 들어, 아주 직관적인 설명부터 대학원 수준의 수리적 엄밀함까지 갖춘 형태로 완벽하게 재구성해 드리겠습니다.
분석 도구와 관련하여 한 가지 중요한 점을 말씀드립니다. jamovi는 훌륭한 통계 도구이지만, 오늘 다룰 ‘함수형 데이터(Functional Data)’와 같은 고차원적 분석은 아직 기본 메뉴로 지원하지 않습니다(일반적인 다층모형까지만 지원). 따라서 본 강의에서는 R을 사용하여 모의 데이터 생성부터 분석, 시각화까지 구현해 드리겠습니다. 대신, 코드는 복사해서 바로 쓸 수 있도록 아주 친절하게 주석을 달아 제공합니다.
그럼, 시작해 볼까요?
1. 서론: 점(Point)이 아니라 선(Line)을 보자!
1.1 직관적 이해 (초등학생도 이해하는 MFDA)
여러분이 담임 선생님이라고 상상해 보세요. 우리 반 학생 철수의 수학 실력을 알고 싶습니다. 보통 우리는 “기말고사 점수 80점”이라는 하나의 숫자(Scalar)로 철수를 평가합니다. 이것이 전통적인 통계입니다.
그런데, 80점이라는 점수가 철수의 모든 것을 설명할까요?
어떤 학생은 수업 초반 20분은 엄청 집중하다가 후반에 자는 학생이 있고, 어떤 학생은 처음엔 멍하다가 나중에 발동이 걸리는 학생이 있습니다.
스칼라(Scalar) 데이터: 철수의 점수 = 80점 (사진 한 장 📷)
함수형(Functional) 데이터: 철수의 45분간 집중력 변화 그래프 (동영상 🎥)
다층 함수형 데이터 분석(MFDA)은 바로 이 “동영상(변화 곡선)”을 분석하는 방법입니다. 그런데 왜 ‘다층(Multilevel)’일까요?
학생마다 수업을 듣는 집중력 곡선이 다르고(1수준), 이 학생들이 속한 반(Class)마다 분위기가 다르기(2수준) 때문입니다.
핵심 요약:
FDA: 시간에 따라 변하는 “곡선” 자체를 하나의 데이터로 분석함.
Multilevel: 그 곡선들이 여러 집단(학생, 학교 등)에 층층이 겹쳐 있는 구조를 반영함.
2. 시나리오: “어떤 수업 방식이 끝까지 집중하게 할까?”
우리는 다음과 같은 교육 실험을 진행한다고 가정해 보겠습니다.
연구 대상: 초등학교 6학년 학생 100명 (2개 반)
독립 변수(집단):
A반 (50명): 전통적 강의식 수업
B반 (50명): 게임 기반(Gamification) 수업
종속 변수(함수): 45분 수업 동안의 분당 뇌파 집중도(Attention Score, 0~100)
학생 1명당 45개의 측정값(0분~44분)이 연결된 하나의 곡선이 생성됩니다.
3. R을 이용한 모의 데이터 생성 및 분석
자, 이제 이 시나리오를 실제 데이터로 만들어 분석해 보겠습니다. R 스튜디오를 켜고 아래 코드를 순서대로 실행해 보세요.
3.1 데이터 생성 (Data Simulation)
실제 학교 현장과 유사하게 데이터를 생성합니다.
A반(강의식): 초반엔 집중력이 높지만 시간이 갈수록 급격히 떨어지는 패턴.
B반(게임형): 초반엔 산만하지만, 시간이 갈수록 몰입도가 유지되거나 상승하는 패턴.
R
# 필수 패키지 설치 및 로드
if(!require(ggplot2)) install.packages("ggplot2")
if(!require(refund)) install.packages("refund") # 함수형 데이터 분석용 핵심 패키지
if(!require(dplyr)) install.packages("dplyr")
if(!require(tidyr)) install.packages("tidyr")
library(ggplot2)
library(refund)
library(dplyr)
library(tidyr)
set.seed(1234) # 재현성을 위해 시드 고정
# 1. 기본 설정
n_students <- 100 # 총 학생 수
n_points <- 45 # 측정 지점 (0분~44분, 총 45분 수업)
time_points <- seq(0, 1, length.out = n_points) # 0에서 1로 정규화된 시간
# 2. 그룹 할당 (A반: 0=강의식, B반: 1=게임형)
group <- c(rep(0, n_students/2), rep(1, n_students/2))
group_factor <- factor(group, labels = c("Lecture", "Gamification"))
# 3. 기저 함수 생성 (집중력의 기본 패턴)
# 강의식(A): 초반 높음 -> 후반 낮음 (감소형)
mu_A <- function(t) { 80 - 40 * t }
# 게임형(B): 초반 중간 -> 후반 유지/상승 (유지형)
mu_B <- function(t) { 60 + 10 * sin(2 * pi * t) + 10 * t }
# 4. 개인차(Random Effect) 추가
# 학생마다 고유한 집중력 기복이 있음 (브라운 운동 + 임의 오차)
Y_matrix <- matrix(NA, nrow = n_students, ncol = n_points)
for(i in 1:n_students){
# 기본 곡선 선택
base_curve <- if(group[i] == 0) mu_A(time_points) else mu_B(time_points)
# 학생별 임의 효과 (Random Intercept + Random Slope 유사 효과)
student_deviation <- rnorm(1, 0, 5) + rnorm(1, 0, 2) * time_points * 10
# 측정 오차 (Measurement Error)
noise <- rnorm(n_points, 0, 2)
Y_matrix[i, ] <- base_curve + student_deviation + noise
}
# 데이터 프레임 형태로 정리 (시각화용)
df_long <- data.frame(
ID = rep(1:n_students, each = n_points),
Time = rep(1:n_points, n_students),
Group = rep(group_factor, each = n_points),
Attention = as.vector(t(Y_matrix))
)
head(df_long)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(df_long, "chap13.csv", row.names = FALSE)
분석의 첫 걸음은 데이터를 눈으로 확인하는 것입니다. 개별 학생들의 집중력 곡선을 모두 그려보겠습니다. 이를 ‘스파게티 플롯(Spaghetti Plot)’이라고 합니다.
R
# 스파게티 플롯 + 평균 곡선
ggplot(df_long, aes(x = Time, y = Attention, group = ID, color = Group)) +
geom_line(alpha = 0.3) + # 개별 학생 곡선 (흐리게)
geom_smooth(aes(group = Group), method = "gam", se = TRUE, size = 2) + # 그룹별 평균 곡선 (진하게)
labs(title = "수업 방식에 따른 학생 집중력 변화 곡선",
subtitle = "개별 곡선(흐림)과 그룹 평균 곡선(진함)",
x = "수업 시간 (분)", y = "집중도 (점수)") +
theme_minimal() +
scale_color_manual(values = c("Lecture" = "blue", "Gamification" = "red"))
해석: > 파란색(강의식) 곡선들은 시간이 갈수록 우하향하는 경향이 뚜렷합니다. 반면 빨간색(게임형)은 출렁거림이 있지만 전반적으로 수준이 유지됩니다. 이것이 바로 함수형 데이터 분석의 매력입니다. 평균 점수만 비교했다면 놓쳤을 ‘시간에 따른 패턴’을 볼 수 있죠.
4. 이론적 배경: 함수형 혼합 모형 (Functional Mixed Model)
이 데이터를 통계적으로 검증하려면 어떤 모형을 써야 할까요? 함수형 혼합 모형(FMM) 수식은 다음과 같습니다.
초등학생 눈높이로 번역해 보겠습니다.
: 관찰된 학생의 집중력 곡선 (우리가 본 스파게티 면발)
: 고정 효과 (Fixed Effects) = 수업 방식에 따른 공통적인 패턴.
“강의식 수업은 대체로 이렇게 흘러간다”는 평균 곡선.
: 임의 효과 (Random Effects) = 학생 개인의 특성.
“철수는 원래 초반에 약해”, “영희는 후반에 강해” 같은 개인별 편차 곡선.
: 오차 (Error) = 측정 당시의 잡음.
우리의 목표는 (수업 방식의 효과 곡선)가 통계적으로 유의미하게 다른지 확인하는 것입니다.
5. 핵심 분석: Function-on-Scalar Regression
이제 refund 패키지를 사용하여 “수업 방식(Scalar)이 집중력 곡선(Function)에 미치는 영향”을 분석해 보겠습니다.
5.1 분석 코드 실행
R
# 1. 데이터 프레임 만들기
# 핵심: I() 함수를 사용하여 Y_matrix를 데이터 프레임의 한 '열'로 안전하게 포장합니다.
covariates_df <- data.frame(group_factor = group_factor)
covariates_df$Y_matrix <- I(Y_matrix)
# 2. 모델 적합
# 이제 Y_matrix와 group_factor 모두 covariates_df 안에 들어있습니다.
f_model <- fosr(Y_matrix ~ group_factor, data = covariates_df, method = "OLS")
# 3. 결과 확인
summary(f_model)
# 4. 시각화 (베타 계수 곡선)
plot(f_model, split = 1)
기울기 곡선 (Slope for Gamification): 여기가 핵심입니다! 이 곡선은 “강의식 대비 게임형 수업의 집중력 차이”를 시간대별로 보여줍니다.
0~10분: 차이가 거의 0에 가깝거나 음수일 수 있습니다 (초반엔 게임 룰 익히느라 산만함).
20분 이후: 곡선이 양수(+)로 치솟습니다. 즉, 수업 중반 이후부터 게임형 수업의 집중력이 강의식보다 유의미하게 높다는 뜻입니다.
6. 심화 분석: FPCA (함수형 주성분 분석)
첨부 파일에서 강조하는 또 하나의 중요한 기법은 FPCA입니다.
학생 100명의 곡선은 제각각이지만, 그 안에는 몇 가지 “대표적인 유형(Mode of Variation)”이 숨어 있습니다.
R
# FPCA 수행
fpca_res <- fpca.sc(Y_matrix)
# 주성분(Eigenfunctions) 시각화
par(mfrow = c(1, 2))
plot(fpca_res$efunctions[,1], type='l', main = "제1주성분 (전체적 높낮이)", ylab="Value", xlab="Time")
plot(fpca_res$efunctions[,2], type='l', main = "제2주성분 (초반 vs 후반)", ylab="Value", xlab="Time")
제1주성분: “집중력이 전체적으로 높은 학생 vs 낮은 학생”을 구분하는 패턴.
제2주성분: “초반에 높고 후반에 지치는 유형(토끼형)” vs “초반엔 낮지만 후반에 강한 유형(거북이형)”을 구분하는 패턴.
교수자는 이 점수(FPC Score)를 활용해 학생들을 유형별로 분류하고 상담할 수 있습니다.
7. 결론 및 제언
오늘 우리는 다층 함수형 데이터 분석(MFDA)을 통해, 단순히 “평균 80점”이 아닌 “시간의 흐름에 따른 학습 패턴”을 분석했습니다.
교육적 시사점: 단순한 점수 비교를 넘어, “언제(When)” 개입해야 하는지 알려줍니다.
분석 결과, 강의식 수업은 20분 지점에서 집중력이 급락하므로, 이때 환기 활동(Brain Break)이 필요하다는 데이터 기반 의사결정이 가능합니다.
방법론적 의의:
jamovi로 구현되지 않는 고차원 분석을 R의 refund 패키지로 구현함으로써, 연구의 깊이를 더했습니다.
다층 모형의 개념을 함수(곡선)로 확장하여, 개인차(Between-subject)와 시간차(Within-subject)를 동시에 고려했습니다.
이 분석 기법을 활용하여, 여러분의 교실과 연구실에서 숨겨진 데이터의 맥박을 느껴보시길 바랍니다.
참고문헌 (References)
Crainiceanu, C. M., Caffo, B. S., & Morris, J. S. (2013). Multilevel functional data analysis. In The SAGE Handbook of Multilevel Modeling (pp. 223-238). SAGE Publications Ltd.
Morris, J. S., & Carroll, R. J. (2006). Wavelet-based functional mixed models. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 68(2), 179-199.
Ramsay, J. O., & Silverman, B. W. (2005). Functional Data Analysis (2nd ed.). Springer.
Crainiceanu, C. M., et al. (2009). Generalized multilevel functional regression. Journal of the American Statistical Association, 104(488), 1550-1561.
오늘은 일반화 선형 혼합 모형(Generalized Linear Mixed Models, GLMM)에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
🎓 일반화 선형 혼합 모형(GLMM): 학교 밖으로 나간 수학 점수
반갑습니다. 오늘은 통계의 꽃이라 불리는 일반화 선형 혼합 모형(GLMM)에 대해 이야기해 보려 합니다. 이름만 들어도 머리가 지끈거릴 수 있지만, 사실 원리는 우리가 학교에서 겪는 일상과 매우 비슷합니다.
1. 왜 GLMM인가? (초등학생도 이해하는 비유)
여러분이 “우리 반 친구들이 이번 수학 시험에 합격할지 불합격할지(성공/실패)“를 맞히고 싶다고 상상해 봅시다.
일반적인 회귀분석(Linear Regression)은 “점수”처럼 연속적인 숫자를 예측할 때 씁니다. 하지만 우리는 “합격(1) 아니면 불합격(0)”인 두 가지 결과만 있습니다. 자로 키를 재는 게 아니라, 동전의 앞면/뒷면을 맞히는 것과 같죠. 이때 필요한 것이 ‘일반화(Generalized)’ 선형 모형입니다.
그런데 학생들은 ‘반(Class)’이라는 바구니에 담겨 있습니다. 어떤 반 선생님은 설명을 아주 잘해서 그 반 아이들이 전체적으로 합격률이 높을 수 있죠. 학생들끼리 서로 영향을 주고받는다는 뜻입니다. 이걸 무시하고 분석하면 엉터리 결과가 나옵니다. 그래서 ‘혼합(Mixed)’ 모형, 즉 다층 모형이 필요합니다.
이 둘을 합친 것이 바로 GLMM입니다. “결과가 0/1이거나 횟수(Count)이면서, 데이터가 집단(학교, 반)으로 묶여 있을 때” 사용하는 가장 강력한 도구죠.
2. 가상의 시나리오: “수학 챌린지 성공 예측 대작전”
우리의 목표는 다음과 같습니다.
연구 문제: 학생의 자기효능감과 교사의 교수법(혁신적 vs 전통적)이 수학 챌린지 성공 여부(성공/실패)에 미치는 영향은 무엇인가?
# 자기효능감에 따른 성공 여부 (교수법별 차이)
ggplot(data, aes(x = SelfEfficacy, y = as.numeric(Success)-1, color = TeachingMethod)) +
geom_point(alpha = 0.1) +
geom_smooth(method = "glm", method.args = list(family = "binomial"), se = TRUE) +
labs(title = "자기효능감과 수학 챌린지 성공 확률",
x = "자기효능감 (표준화)",
y = "성공 확률 (Probability of Pass)") +
theme_minimal()
4. 분석 방법: jamovi와 R
🛠️ jamovi 분석 절차
jamovi는 기본 메뉴만으로는 GLMM(특히 이분형 종속변수)을 분석하기 어렵습니다. 따라서 jamovi 라이브러리에서 GAMLj (General Analyses for Linear Models in jamovi) 모듈을 설치하여 사용해야 합니다.
결과 해석: Fixed Effects의 p-value와 Random Effects의 분산(Variance)을 확인합니다.
💻 R 분석 코드 (GLMM 적합)
jamovi 내부에서 돌아가는 엔진과 동일한 lme4 패키지를 사용한 분석 코드입니다.
R
# GLMM 모델 적합
# family = binomial : 종속변수가 이분형(0/1)일 때 사용
glmm_model <- glmer(Success ~ SelfEfficacy + TeachingMethod + (1 | ClassID),
data = data,
family = binomial(link = "logit"))
# 결과 요약
summary(glmm_model)
5. 교재 내용의 심층 재구성: 이론과 해석
이제 첨부된 교재(SAGE Handbook)의 핵심 내용을 바탕으로 우리가 수행한 분석을 이론적으로 파헤쳐 보겠습니다.
5.1. 모형의 구조 (Specification)
GLMM은 4단계로 구성됩니다.
분포 선택: 종속변수 가 어떤 모양인지 결정합니다. 우리 예시는 성공/실패이므로 베르누이(Bernoulli) 분포를 따릅니다.
예측변수 선택: 자기효능감()과 교수법()을 포함합니다. 선형 예측식은 가 됩니다.
연결 함수(Link Function): 0과 1 사이의 확률()을 실수 전체 범위()인 선형 예측식()과 연결해야 합니다. 이때 로짓(Logit) 함수를 사용합니다.
임의 효과(Random Effects): 학급()을 임의 효과로 선언합니다. 이는 학급마다 성공률의 ‘출발선’이 다름을 의미하며, 정규분포 를 따른다고 가정합니다.
5.2. 추정 방법: 산을 오르는 법 (Fitting Methods)
GLMM에서 가장 어려운 점은 “계산”입니다. 일반적인 회귀분석처럼 공식을 딱 대입해서 답이 나오지 않습니다. 우도(Likelihood)라는 산의 정상을 찾아야 하는데, 그 과정에 안개(적분)가 껴 있습니다.
최우추정법(Maximum Likelihood, ML): 가장 이상적이지만, 계산이 매우 복잡하여 적분(Integration)이 필요합니다.
근사법: 이 적분을 해결하기 위해 가우스-헤르미트 구적법(Gauss-Hermite Quadrature)이나 라플라스 근사(Laplace Approximation)를 사용합니다. 이는 복잡한 곡면을 단순한 도형으로 근사시켜 넓이를 구하는 방식과 비슷합니다. jamovi와 R의 glmer는 기본적으로 이 방법을 사용합니다.
경고: PQL(Penalized Quasi-Likelihood)이라는 방법도 있지만, 이분형 데이터(0/1)에서는 편향(Bias)이 심해 잘 쓰지 않습니다.
5.3. 조건부 vs 주변부 해석 (Conditional vs Marginal)
이 부분이 아주 중요합니다. GLMM의 결과()는 “특정 학급에 속한 학생 개인”에 대한 효과입니다(Conditional).
GLMM (조건부): “내가 이 반에 계속 있으면서 자기효능감이 1 오르면, 나의 성공 오즈(Odds)는 얼마나 오르는가?”
GEE (주변부): “전체 학생 평균적으로 봤을 때, 자기효능감이 높은 집단은 낮은 집단보다 성공률이 얼마나 높은가?”
일반적으로 로지스틱 모형에서는 조건부 효과가 주변부 효과보다 값이 더 크게(0에서 멀어지게) 추정됩니다. 우리는 학생 개인의 변화와 학급 효과에 관심이 있으므로 GLMM이 적합합니다.
6. 분석 결과 해석 및 보고 (APA 스타일)
R/jamovi 분석 결과를 바탕으로 보고서를 작성하는 예시입니다.
📝 결과 요약
“수학 챌린지 성공 여부에 대한 일반화 선형 혼합 모형(GLMM) 분석 결과, 자기효능감과 교수법은 통계적으로 유의한 영향을 미치는 것으로 나타났다.”
고정 효과(Fixed Effects):
자기효능감의 회귀계수는 1.370 ()로, 학생의 자기효능감이 높을수록 성공 확률이 유의하게 증가하였다. 오즈비(Odds Ratio)로 환산하면 로, 자기효능감이 1단위 증가할 때 성공 오즈는 약 3.9배 증가한다.
교수법(혁신적)의 효과는 0.227 ()로, 혁신적 교수법을 사용하는 학급의 학생이 전통적 교수법 학급 학생보다 성공할 확률은 통계적으로 유의미하지 않았다.
임의 효과(Random Effects):
학급 수준의 분산(Variance)은 3.221로 나타났다. 이는 학생의 개인 특성을 통제하고도 학급 간 성공률의 차이가 상당히 큼을 의미한다. 이를 통해 급내상관계수(ICC)를 계산하여 학급의 영향력을 보고할 수 있다.
📈 R을 이용한 결과 시각화 코드
R
# sjPlot 패키지를 이용한 깔끔한 시각화
library(sjPlot)
library(sjmisc)
# 1. 오즈비(Odds Ratio) 그래프 (Forest Plot)
plot_model(glmm_model,
type = "est",
transform = "exp", # 로그오즈를 오즈비로 변환
show.values = TRUE,
title = "수학 챌린지 성공 요인 (Odds Ratios)",
vline.color = "gray")
# 2. 예측 확률 그래프 (상호작용 효과 등 확인용)
plot_model(glmm_model,
type = "pred",
terms = c("SelfEfficacy", "TeachingMethod"),
title = "자기효능감과 교수법에 따른 성공 예측 확률")
7. 마무리 및 진단
GLMM을 사용할 때는 모델이 데이터에 잘 맞는지 꼭 확인해야 합니다. 특히 “과산포(Overdispersion)” 문제를 조심해야 합니다. 이는 우리가 가정한 것보다 데이터가 더 넓게 퍼져 있는 현상을 말하는데, 이항 분포나 포아송 분포 분석 시 자주 발생합니다. 만약 과산포가 의심되면 분포를 바꾸거나 관측 단위의 임의 효과를 추가하는 등의 조치가 필요합니다.
오늘 우리는 난이도가 높은 GLMM을 학교 현장 예시를 통해 정복해 보았습니다. 이 분석을 통해 여러분은 단순히 “누가 공부 잘하나”를 넘어, “어떤 환경(학급)에서 어떤 특성(효능감)이 성공을 이끄는지” 입체적으로 볼 수 있는 눈을 갖게 되었습니다.
참고문헌 (APA Style)
McCulloch, C. E., & Neuhaus, J. M. (2013). Generalized linear mixed models: Estimation and inference. In M. A. Scott, J. S. Simonoff, & B. D. Marx (Eds.), The SAGE handbook of multilevel modeling (pp. 271-286). SAGE Publications.