
안녕하세요!
오늘은 위계적 동적 모형(Hierarchical Dynamic Models)에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법(GAMLj 모듈 활용)을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 베이지안(Bayesian) 접근을 통한 정교한 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 서론: 사진이 아니라 영화를 찍자!
우리가 학교에서 학생들의 성취도를 연구한다고 상상해 봅시다. 보통은 특정 시점에 시험을 보고, “A 학교가 B 학교보다 점수가 높다”거나 “사교육이 성적에 영향을 미친다”라고 분석합니다. 이것은 마치 ‘사진(Snapshot)’을 찍는 것과 같습니다.
하지만 현실은 훨씬 복잡합니다.
- 위계성 (Hierarchy): 학생들은 ‘학교’라는 그룹에 속해 있어 같은 학교 친구들끼리는 비슷해지는 경향이 있습니다.
- 역동성 (Dynamics): 학교의 여건(선생님의 열정, 학교의 재정 상태 등)은 고정된 것이 아니라 매년 변합니다.
위계적 동적 모형(HDM)은 이 두 가지를 합친 것입니다. 학생 수준의 회귀분석을 하되, 그 회귀계수(Intercept, Slope)가 학교마다 다르고, 심지어 시간이 지남에 따라 변하도록(Time-varying) 허용하는 모형입니다. 즉, 데이터를 사진이 아닌 ‘영화(Movie)’처럼 분석하는 것이죠.
2. 가상의 시나리오: “경기 미래형 학교 연구”
초등학생도 이해할 수 있는 예시를 만들어 보겠습니다.
연구 상황: 경기도 교육청에서 ‘학생의 수학 성취도’가 ‘자기주도학습 시간’에 의해 얼마나 향상되는지 알아보고자 합니다.
- 대상: 초등학교 4학년 학생들을 6학년이 될 때까지 3년간(총 6학기) 추적 조사.
- 구조: 30개의 학교, 각 학교당 20명의 학생.
- 핵심 질문: 자기주도학습이 성적에 미치는 효과()는 모든 학교에서 동일할까? 그리고 그 효과는 학기가 지날수록 변할까?
3. 모형의 구조 (수리적 이해)
제공된 텍스트에 근거하여 이 모형은 크게 세 가지 방정식으로 구성됩니다.
(1) 관측 방정식 (Observation Equation)
학생 , 학교 , 시간 에서의 수학 점수()는 다음과 같습니다.
- 여기서 (절편)와 (자기주도학습 효과)는 학교()와 시간()에 따라 다릅니다.
(2) 구조 방정식 (Structural Equation)
학교 수준의 파라미터 는 학교의 특성(예: 교사의 경력 )에 영향을 받습니다.
(3) 시스템 방정식 (System Equation)
이 모형의 꽃입니다. 파라미터가 시간이 지남에 따라 어떻게 변하는지 설명합니다. 보통 랜덤 워크(Random Walk) 과정을 따릅니다.
- 즉, 오늘의 효과는 어제의 효과에 기초하되, 새로운 변화()가 더해집니다.
4. 데이터 생성 및 분석 (R & jamovi)
이론적으로 HDM은 베이지안 추론(Bayesian Inference)을 주로 사용합니다. jamovi의 기본 모듈은 빈도주의(Frequentist) 기반이지만, GAMLj 모듈을 사용하면 유사한 ‘위계적 성장 모형’ 분석이 가능하며, R을 사용하면 텍스트에 나온 완벽한 동적 모형을 구현할 수 있습니다.
Step 1. R을 이용한 모의 데이터 생성
먼저, 시나리오에 맞는 데이터를 생성해 보겠습니다.
R
# 필요한 패키지 로드
library(MASS)
library(tidyverse)
library(lme4)
set.seed(2026)
# 1. 기본 설정
n_schools <- 30 # 학교 수
n_students <- 20 # 학교당 학생 수
n_time <- 6 # 6학기 (시간)
total_obs <- n_schools * n_students * n_time
# 2. 시스템 방정식 (시간에 따른 효과 변화 생성)
# 자기주도학습의 효과(Slope)가 시간이 지날수록 조금씩 증가한다고 가정 (랜덤 워크)
time_effect <- cumsum(rnorm(n_time, mean = 0.05, sd = 0.1))
base_intercept <- 50 + cumsum(rnorm(n_time, mean = 1, sd = 0.5)) # 전체 평균 점수도 상승
# 3. 데이터 프레임 생성
data <- expand.grid(
Time = 1:n_time,
Student_ID = 1:n_students,
School_ID = 1:n_schools
)
# 4. 학교별 효과 (Random Intercept & Slope)
school_intercepts <- rnorm(n_schools, 0, 5) # 학교 간 격차
school_slopes <- rnorm(n_schools, 0, 0.5) # 학교별 학습 효과 차이
# 5. 학생 데이터 생성 및 점수 계산
data <- data %>%
mutate(
# 학생별 자기주도학습 시간 (시간에 따라 변함 + 개인차)
Self_Study = abs(rnorm(total_obs, mean = 5, sd = 2)),
# 실제 수학 점수 생성 (HDM 구조 반영)
# 점수 = (시간별기초 + 학교별차이) + (시간별효과 + 학교별차이)*학습시간 + 오차
Math_Score = (base_intercept[Time] + school_intercepts[School_ID]) +
(1.5 + time_effect[Time] + school_slopes[School_ID]) * Self_Study +
rnorm(total_obs, 0, 3)
)
# 데이터 확인
head(data)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data, "chap19.csv", row.names = FALSE)
Step 2. jamovi를 이용한 분석 (GAMLj 모듈)
jamovi에서는 [Linear Models] > [Mixed Model] (혹은 GAMLj 모듈 설치 후 사용)를 사용하여 이 데이터를 분석할 수 있습니다. 텍스트에서 언급된 베이지안 동적 모형의 근사치인 ‘성장 곡선 모형(Growth Curve Model)’ 형태로 분석합니다.
- 데이터 불러오기: 위에서 생성한 csv 파일을 jamovi에서 엽니다.
- 분석 설정:
- Dependent Variable:
Math_Score - Factors (Fixed Effects):
Time(Factor로 취급하거나 Covariate로 취급하여 선형 성장 가정 가능) - Covariates:
Self_Study - Cluster:
School_ID,Student_ID(학생이 반복 측정되었으므로)
- Dependent Variable:
- Random Effects:
School_ID아래에Intercept와Self_Study추가 (학교별로 효과가 다름을 반영 ).Student_ID(within School) 설정.
참고: jamovi의 Mixed Model은 파라미터가 ‘랜덤 워크’로 변하는 시스템 방정식(식 19.4 )을 직접 추정하기엔 한계가 있습니다. 이를 완벽히 구현하려면 아래의 R 코드(Bayesian)가 필요합니다.
Step 3. R을 이용한 베이지안 위계적 동적 모형 분석 (brms)
텍스트에서 강조하는 베이지안 추론 을 구현하기 위해 R의 brms 패키지를 사용합니다. 이는 MCMC 알고리즘 을 사용하여 복잡한 사후 분포를 추정합니다.
R
# 베이지안 분석을 위한 brms 패키지 (Stan 기반)
# install.packages("brms")
library(brms)
# 모형 설정:
# 점수 ~ 시간 + 학습시간 + (1 + 학습시간 | 학교) + (1 | 학생)
# *중요: 시간에 따른 계수의 변화를 허용하기 위해 상호작용항 또는 s() 함수 사용 가능
# 텍스트의 DLM(Dynamic Linear Model)을 근사하는 식
model_hdm <- brm(
formula = Math_Score ~ Time * Self_Study + (1 + Time + Self_Study | School_ID),
data = data,
family = gaussian(),
chains = 2, iter = 2000, # 예시를 위해 반복 수 줄임
seed = 2026
)
# 결과 요약
summary(model_hdm)
# 조건부 효과 시각화 (시간에 따른 학습 효과의 변화)
conditional_effects(model_hdm, effects = "Self_Study:Time")
5. 분석 결과의 해석 및 시각화
(1) 시간과 학교에 따른 변화
우리는 시간에 따라 변하는 학교별 특성을 시각화할 수 있습니다.
R
# R을 이용한 시각화 (학교별, 시간에 따른 성적 변화 스파게티 플롯)
ggplot(data, aes(x = Time, y = Math_Score, group = interaction(School_ID, Student_ID))) +
geom_line(alpha = 0.1, color = "gray") + # 개별 학생
stat_summary(aes(group = School_ID, color = as.factor(School_ID)),
fun = mean, geom = "line", size = 1, alpha = 0.8) + # 학교 평균
theme_minimal() +
labs(title = "학교별 시간에 따른 수학 성취도 변화",
x = "학기 (Time)", y = "수학 점수", color = "학교 ID") +
theme(legend.position = "none")
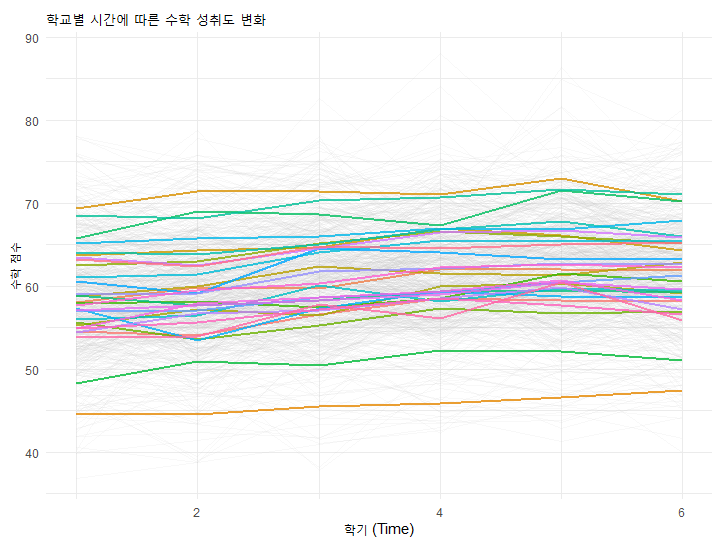
이 그래프를 보면, 어떤 학교는 시간이 지날수록 성적이 가파르게 오르고(기울기가 큼), 어떤 학교는 정체되어 있음을 알 수 있습니다. 이것이 바로 (절편)와 파라미터들이 동적으로 변한다는 증거입니다.
(2) 파라미터의 동적 변화 (Smoothed Distribution)
분석 결과, 자기주도학습의 효과()가 1학기에는 1.5점 상승 효과였는데, 6학기에는 2.0점 상승 효과로 변했다면, 이는 “고학년이 될수록 자기주도학습이 더 중요하다”는 교육적 결론을 도출할 수 있게 합니다.
6. 심화: 모형의 확장
이 모형은 단순히 점수 하나만 분석하는 것에 그치지 않고 확장될 수 있습니다.
(1) 다변량 확장 (Matrix-Variate)
수학 점수뿐만 아니라 영어 점수도 같이 분석하고 싶다면? 수학과 영어는 상관관계가 높습니다. 이를 각각 분석하는 것보다 행렬(Matrix) 형태로 묶어서 분석하면 두 과목 간의 상관성까지 파악할 수 있어 훨씬 정확합니다.
(2) 공간적 확장 (Spatial Structure)
학교들은 지리적으로 인접해 있습니다. 예를 들어, 수원시에 있는 학교들은 용인시에 있는 학교들보다 서로 더 비슷한 교육 환경을 공유할 수 있습니다. 학교 간의 ‘거리(Distance)’ 정보를 모형의 분산 행렬()에 반영하여, 가까운 학교끼리 더 높은 상관관계를 갖도록 설정할 수 있습니다.
(3) 지수족 분포 확장 (Exponential Family)
만약 종속변수가 점수(정규분포)가 아니라, ‘결석 일수(Count)’나 ‘비만 여부(Binary)’라면 어떨까요? 이 경우 정규분포 가정이 깨집니다. 이때는 포아송 분포나 감마 분포 등을 사용하는 일반화 선형 모형(GLM)과 결합하여 분석할 수 있습니다.
7. 결론
위계적 동적 모형은 교육 현장의 데이터를 ‘있는 그대로’ 가장 잘 반영하는 도구입니다. 학생은 학교에 속해 있고(위계), 학교와 학생은 끊임없이 변화하기(동적) 때문입니다.
jamovi와 R을 활용한 이 분석을 통해, 여러분은 단순한 평균 비교를 넘어 “언제, 어디서, 어떻게 교육 효과가 변화하는지”를 밝혀내는 통찰력을 갖게 될 것입니다.
참고문헌 (APA Style)
- Gamerman, D., & Migon, H. S. (1993). Dynamic hierarchical models. Journal of the Royal Statistical Society: Series B (Methodological), 55(3), 629-642.
- Hansen, N. (2009). Models with dynamic coefficients varying in space for data in the exponential family [Unpublished master’s thesis]. Universidade Federal do Rio de Janeiro.
- Landim, F. M., & Gamerman, D. (2000). Dynamic hierarchical models: An extension to matrix variate observations. Computational Statistics & Data Analysis, 35(1), 11-42.
- Paez, M. S., & Gamerman, D. (n.d.). Hierarchical dynamic models. In The SAGE Handbook of Multilevel Modeling (Chapter 19, pp. 335-355).
- Paez, M. S., Gamerman, D., Landim, F. M., & Salazar, E. (2008). Spatially varying dynamic coefficient models. Journal of Statistical Planning and Inference, 138(4), 1038-1058.
- West, M., & Harrison, P. J. (1997). Bayesian forecasting and dynamic models (2nd ed.). Springer.