안녕하세요!
구조방정식은 단순히 변수 간의 관계를 보는 것을 넘어, 우리가 직접 관찰할 수 없는 ‘잠재적인 마음의 상태(잠재변수)’를 측정하고 그들 사이의 복잡한 인과관계를 모형화할 수 있게 해주는 아주 매력적인 방법론입니다.
이 장에서는 실제 교육 현장에서 만날 수 있는 시나리오를 통해 jamovi와 R(lavaan)을 활용하여 구조방정식을 어떻게 수행하는지 아주 상세히 다룹니다.
1. 들어가며: 왜 구조방정식인가?
우리가 교육 현장에서 마주하는 개념들—예를 들어 ‘학업 동기’, ‘교사 지지’, ‘자기효능감’—은 단 하나의 시험 점수나 설문 문항으로 완벽히 설명하기 어렵습니다. 구조방정식 모델링(Structural Equation Modeling, SEM)은 이러한 잠재변수(Latent Factor)를 여러 개의 측정지표(Indicator)를 통해 파악하고, 이들 간의 구조적 관계를 분석하는 통계 기법입니다.
전통적으로 SEM은 Mplus, Amos와 같은 고가의 상용 프로그램을 주로 사용해 왔으나, 최근에는 jamovi의 SEMLj 모듈이나 R의 lavaan 패키지와 같은 오픈소스 도구들이 발전하면서 누구나 정교한 분석을 수행할 수 있게 되었습니다.
2. 교육 현장 시나리오 및 모의 데이터 생성
이해를 돕기 위해 학교 현장의 이야기를 담은 데이터를 가정해 봅시다.
연구 시나리오: “교사의 정서적 지지가 학생의 학업 성취에 미치는 영향”
- 독립변수(X): 교사 지지(Teacher Support) – ‘정서적 지지(x1)’와 ‘학업적 지지(x2)’로 측정.
- 매개변수(M): 학업 참여(Engagement) – ‘행동적 참여(m1)’와 ‘정서적 참여(m2)’로 측정.
- 결과변수(Y): 학업 성취(Achievement) – ‘수학 점수(y1)’와 ‘국어 점수(y2)’로 측정.
연구자는 교사의 지지가 학생의 참여도를 높이고, 이것이 최종적으로 성취도 향상으로 이어지는지 확인하고자 합니다.
2.1. 모의 데이터 생성 (R 코드)
분석 실습을 위해 명의 데이터를 생성합니다. 실제 상황과 유사하게 일부 데이터는 무작위로 누락(MCAR)된 것으로 가정합니다.
R
# R을 활용한 모의 데이터 생성
set.seed(2025)
library(MASS)
# 상관 행렬 설정 (교사지지, 참여, 성취 간의 관계)
n <- 500
mu <- rep(0, 6)
sigma <- matrix(c(1.0, 0.6, 0.3, 0.3, 0.2, 0.2,
0.6, 1.0, 0.3, 0.3, 0.2, 0.2,
0.3, 0.3, 1.0, 0.7, 0.4, 0.4,
0.3, 0.3, 0.7, 1.0, 0.4, 0.4,
0.2, 0.2, 0.4, 0.4, 1.0, 0.7,
0.2, 0.2, 0.4, 0.4, 0.7, 1.0), 6, 6)
data <- mvrnorm(n, mu, sigma)
colnames(data) <- c("x1", "x2", "m1", "m2", "y1", "y2")
df <- as.data.frame(data)
# 결측치 주입 (MCAR 가정)
df$m1[sample(1:n, 50)] <- NA
df$y1[sample(1:n, 70)] <- NA
# 데이터 저장 (jamovi에서 불러오기 위함)
# write.csv(df, "school_sem_data.csv", row.names = FALSE)
3. 데이터 준비 및 기초 분석
3.1. 데이터 불러오기 및 결측치 처리
Mplus나 lavaan은 텍스트 형태의 데이터를 읽습니다. jamovi에서는 .csv 파일을 바로 불러올 수 있습니다.
- 결측치 코드: 데이터셋 내에 공백 대신
-999와 같은 특정 숫자를 사용할 수 있지만, jamovi와 lavaan은 시스템 결측치(NA)를 직접 처리하는 데 매우 능숙합니다. - FIML(Full-Information Maximum Likelihood): 결측치가 있을 때 케이스를 삭제(Listwise deletion)하지 않고, 사용 가능한 모든 정보를 활용하여 모수를 추정하는 방식입니다. jamovi와 lavaan 모두 이 방식을 기본 혹은 옵션으로 제공합니다.
3.2. 기초 통계(Descriptive Statistics) 확인
분석 전, 변수들의 평균, 표준편차, 그리고 상관관계를 확인해야 합니다. jamovi의 Exploration -> Descriptives 메뉴를 통해 데이터의 분포를 살핍니다.
| 변수 | 평균 | 표준편차 | 결측치 개수 |
| x1 (정서적 지지) | -0.01 | 0.99 | 0 |
| m1 (행동적 참여) | 0.02 | 1.01 | 50 |
| y1 (수학 점수) | -0.04 | 0.98 | 70 |
4. 관찰변수 경로분석 (Manifest Path Analysis)
가장 먼저, 요인으로 묶지 않고 개별 변수(x1, m1, y1) 간의 관계를 분석해 봅시다.
4.1. 분석 방법 (jamovi SEMLj)
- SEMLj -> Syntax Mode 혹은 Path Analysis 메뉴 선택.
- Model 설정:
m1 ~ x1(교사 지지가 참여를 예측)y1 ~ x1 + m1(교사 지지와 참여가 성취를 예측)
- 옵션:
Direct and indirect effects를 체크하여 매개효과를 확인합니다.
4.2. 주요 결과 해석
- 직접 효과(Direct Effect): 교사 지지()가 성취()에 직접 미치는 영향.
- 간접 효과(Indirect Effect): 로 이어지는 경로의 곱().
- 유의성 검정: 간접효과 검정 시 Bootstrapping(1000회 이상)을 권장합니다. 이는 곱해진 값의 분포가 정규분포를 따르지 않을 수 있기 때문입니다.
5. 확인적 요인분석 (Confirmatory Factor Analysis, CFA)
이제 측정 도구가 제대로 작동하는지 확인합니다. ‘교사 지지’라는 잠재변수(X)가 x1, x2에 의해 잘 설명되는지 보는 과정입니다.
5.1. 모델 식별 및 제약
- 식별(Identification): 잠재변수는 단위가 없으므로, 첫 번째 측정지표의 부하량을
1로 고정하거나 잠재변수의 분산을1로 고정하여 척도를 부여합니다. - 측정 모델 구성:
X =~ x1 + x2M =~ m1 + m2Y =~ y1 + y2
5.2. 적합도 지수 (Fit Indices)
모델이 실제 데이터와 얼마나 일치하는지 평가합니다.
- 검정: 이면 좋으나 표본 크기에 민감합니다.
- CFI / TLI: .90 이상(가급적 .95 이상) 권장.
- RMSEA: .08 이하(가급적 .05 이하) 권장.
- SRMR: .08 이하 권장.
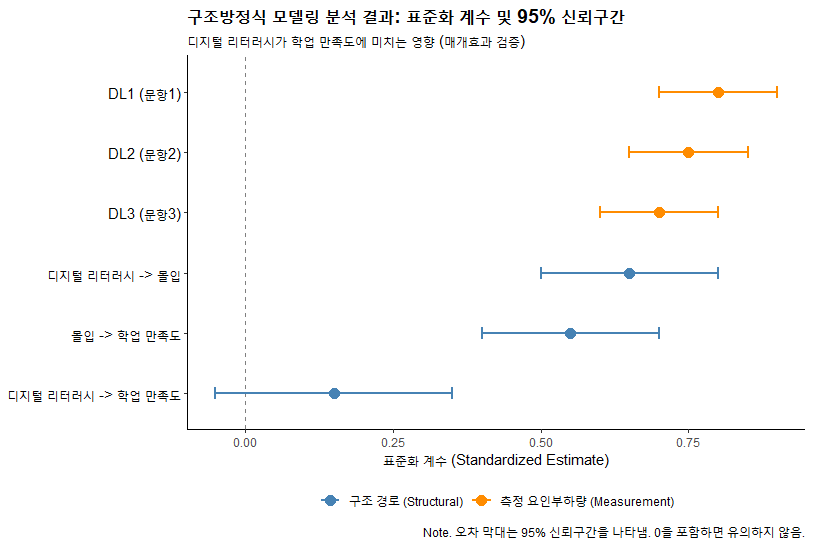
6. 잠재 경로 분석: 전체 구조모델 (Full SEM)
측정 모델(CFA)과 구조 모델(Path)을 결합합니다.
6.1. lavaan 문법 (R/jamovi 공용)
jamovi의 syntax 창이나 R에서 아래와 같이 입력합니다.
R
# 전체 SEM 모델 설정
model <- '
# 측정 모델 (CFA)
Teacher_Support =~ x1 + x2
Engagement =~ m1 + m2
Achievement =~ y1 + y2
# 구조 모델 (Path)
Engagement ~ a*Teacher_Support
Achievement ~ b*Engagement + c*Teacher_Support
# 간접효과 및 총효과 정의
indirect := a*b
total := c + (a*b)
'
# 모델 실행 (FIML 결측치 처리 포함)
fit <- sem(model, data = df, missing = "fiml")
summary(fit, fit.measures = TRUE, standardized = TRUE)
7. 고급 분석 주제 (Mplus 및 R 역량)
7.1. 잠재성장곡선 모델 (Latent Growth Curve Model, LGM)
시간에 따른 학생의 성취도 변화(초기치와 변화율)를 분석할 때 사용합니다.
i(Intercept): 모든 시점의 부하량을 1로 고정.s(Slope): 시간의 흐름(0, 1, 2, 3 등)에 따라 부하량 설정.
7.2. 다집단 분석 (Multigroup Analysis)
성별이나 학교 유형에 따라 모델의 경로가 다른지 확인합니다. ‘형태 동일성’, ‘측정 동일성’ 등을 단계별로 검증해야 합니다.
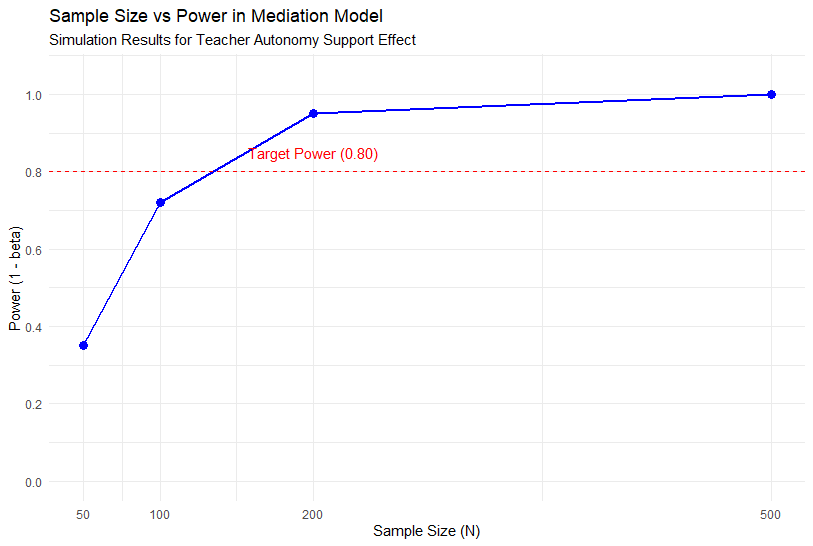
7.3. 몬테카를로 시뮬레이션 (Monte Carlo Simulation)
특정 표본 크기에서 내 모델이 얼마나 정확한 파워(통계적 검정력)를 갖는지 미리 시뮬레이션해 볼 수 있습니다. 주로 R과 Mplus에서 강력한 기능을 제공합니다.
8. 결론 및 제언
구조방정식은 단순한 통계 기법을 넘어 연구자의 이론적 가설을 검증하는 강력한 논리 도구입니다. jamovi와 lavaan을 활용하면 복잡한 수식 없이도 직관적으로 모델을 구성할 수 있습니다. 여러분의 교육 연구가 이 도구를 통해 더욱 깊이 있고 정교해지기를 기대합니다.
참고문헌 (APA Style)
- Arbuckle, J. L. (2014). Amos 23.0 User’s Guide. Chicago: IBM SPSS.
- Byrne, B. M. (2012). Structural equation modeling with Mplus: Basic concepts, applications, and programming. New York: Routledge.
- Enders, C. K. (2022). Applied missing data analysis (2nd ed.). New York: Guilford Press.
- Geiser, C. (2021). Longitudinal structural equation modeling with Mplus: A latent state-trait perspective. New York: Guilford Press.
- Muthén, L. K., & Muthén, B. O. (1998-2017). Mplus user’s guide (8th ed.). Los Angeles, CA: Authors.
- Rosseel, Y. (2012). lavaan: An R package for structural equation modeling. Journal of Statistical Software, 48(2), 1-36.