
안녕하세요, 여러분.
구조방정식 모형(SEM) 연구에서 매우 중요하지만 종종 어렵게 느껴지는 ‘시뮬레이션 방법(Simulation Methods)’에 대해 말씀해 드리겠습니다.
우리가 흔히 수행하는 연구가 “한 번 수집된 데이터로 결론을 내리는 것”이라면, 시뮬레이션 연구는 “가상의 데이터를 수천 번 생성하여 통계적 방법의 성능을 실험하는 것”입니다.
분석 도구와 관련하여, jamovi는 훌륭한 분석 도구이지만, 수천 번의 반복 시뮬레이션(Looping)을 수행하는 기능은 제한적입니다. 따라서 본 강의에서는 R(lavaan 패키지)을 사용하여 시뮬레이션을 구현하는 방법을 보여드리고, 그 결과를 해석하는 방식에 집중하겠습니다.
1. 서론: 왜 시뮬레이션이 필요한가?
여러분이 새로운 교육 프로그램을 개발했다고 가정해 봅시다. 이 프로그램의 효과를 검증하기 위해 복잡한 구조방정식 모형을 세웠습니다. 그런데 고민이 생깁니다.
“표본(학생 수)이 100명이면 충분할까? 데이터가 정규분포를 따르지 않으면 어떡하지?”
기존의 교과서나 가이드라인을 찾아봐도 내 연구 상황에 딱 맞는 답을 찾기 힘든 경우가 많습니다. 바로 이럴 때 시뮬레이션 연구(몬테카를로 연구)가 필요합니다.
시뮬레이션 연구의 핵심은 “정답(참값)을 알고 있는 모집단(Population)을 연구자가 직접 만드는 것”입니다.
- 실제 연구: 참값(Parameter)을 모름 데이터를 통해 추정함.
- 시뮬레이션 연구: 참값을 내가 설정함 데이터를 생성하고 분석해서 분석 방법이 참값을 잘 맞추는지 확인함.
시뮬레이션이 필요한 대표적인 상황
- 새로운 통계 기법 검증: 새로운 분석 방법이 다양한 조건(예: 작은 표본, 결측치)에서 잘 작동하는지 확인할 때.
- 가이드라인 개발: 우리가 흔히 쓰는 CFI > .90 같은 적합도 기준은 수학 공식이 아니라 시뮬레이션 연구를 통해 만들어진 경험적 기준입니다.
- 검증력 분석(Power Analysis): 내 연구 모형에서 유의미한 결과를 얻기 위해 필요한 최소 표본 수를 계산할 때.
2. 시뮬레이션 연구의 설계 (Design)
시뮬레이션 연구도 일반적인 실험 연구와 똑같습니다. 독립변수(조건)를 조작하고, 종속변수(결과)를 관찰합니다.
2.1 독립변수 (우리가 조작하는 조건)
크게 데이터 특성과 모형 특성으로 나뉩니다.
- 표본 크기 (Sample Size):
- 교육 연구에서는 학급 단위나 학교 단위 수집이 많아 표본 확보가 어렵습니다. 등으로 변화를 주어, 언제 모수 추정이 안정되는지 확인합니다.
- 데이터의 비정규성 (Non-normality):
- 학생들의 ‘학업 스트레스’ 설문은 종종 한쪽으로 치우친(Skewed) 분포를 보입니다. 정규분포를 위반했을 때 추정치가 얼마나 왜곡되는지 봅니다. 이를 생성하기 위해 Vale & Maurelli (1983) 방법이 자주 쓰입니다.
- 결측치 (Missing Data):
- 종단 연구에서 학생들이 전학을 가거나 응답을 안 하는 경우입니다. 결측 메커니즘(MCAR, MAR, MNAR)과 결측 비율을 조작합니다.
- 모형 오설정 (Model Misspecification):
- 현실 데이터는 완벽하지 않습니다. 시뮬레이션에서는 일부러 ‘중요한 경로를 빠뜨린 모델’을 만들어, 적합도 지수가 이를 얼마나 잘 잡아내는지 테스트합니다.
2.2 종속변수 (우리가 확인하는 결과)
시뮬레이션의 성능을 평가하는 지표들입니다.
- 수렴률 (Convergence Rate): 분석이 에러 없이 완료된 비율.
- 편의 (Bias): 추정된 값과 내가 설정한 참값의 차이(공식: ). 일반적으로 5% 미만이면 양호하다고 봅니다.
- 표준오차 (Standard Errors): 추정치의 변동성. 이게 정확해야 유의성 검정(값)을 믿을 수 있습니다.
- 검증력 (Power): 실제로 효과가 있을 때, 있다고 찾아낼 확률.
3. 실전: 교육 연구 시뮬레이션 예제 (R 활용)
이제 구체적인 시나리오를 통해 시뮬레이션을 수행해 보겠습니다.
[시나리오: 교사의 자율성 지지가 학생 성취도에 미치는 영향]
- 배경: 한 교육청에서 교사가 학생의 자율성을 지지해주면(X), 학생의 자기효능감(M)이 오르고, 결국 학업 성취도(Y)가 오르는지 확인하고자 합니다.
- 문제: 예산 문제로 데이터를 100명밖에 못 모을 것 같습니다. 이 인원으로 매개효과를 검증할 수 있을까요? (검증력 0.80 이상 목표)
이 문제는 R의 lavaan 패키지를 사용하여 몬테카를로 시뮬레이션을 돌려보겠습니다.
단계 1: 모집단 모형(Population Model) 정의
선행연구를 바탕으로 참값(True Parameter)을 설정합니다.
- 자율성 지지 자기효능감 (경로 a): 0.5 (중간 효과)
- 자기효능감 성취도 (경로 b): 0.5 (중간 효과)
- 자율성 지지 성취도 (경로 c’): 0.1 (작은 직접 효과)
단계 2 & 3: 데이터 생성 및 반복 분석 (Simulation)
표본 크기를 50명, 100명, 200명, 500명으로 늘려가며 각각 1,000번씩 실험합니다.
(참고: 아래 코드는 RStudio에서 바로 실행 가능합니다.)
R
# 필수 패키지 로드
if(!require(lavaan)) install.packages("lavaan")
if(!require(tidyverse)) install.packages("tidyverse")
library(lavaan)
library(tidyverse)
# 1. 시뮬레이션 조건 설정
sample_sizes <- c(50, 100, 200, 500)
n_replications <- 1000 # 반복 횟수 (보통 1,000번 이상 권장)
# 2. 모집단 모형 (우리가 정한 참값)
# 교사의 자율성지지(X) -> 자기효능감(M) -> 성취도(Y)
pop_model <- '
M ~ 0.5*X
Y ~ 0.5*M + 0.1*X
X ~~ 1*X
M ~~ 1*M
Y ~~ 1*Y
'
# 3. 분석 모형 (연구자가 실제로 돌릴 모형)
analyze_model <- '
M ~ a*X
Y ~ b*M + c*X
# 매개효과(indirect effect) 정의
ab := a*b
'
# 결과 저장용 데이터프레임
results <- data.frame()
set.seed(1234) # 재현성을 위한 시드 설정 [cite: 376]
# 4. 시뮬레이션 루프 (Loop)
for (N in sample_sizes) {
cat("Simulating Sample Size:", N, "\n")
sig_count <- 0 # 유의미한 결과 카운트
for (i in 1:n_replications) {
# A. 데이터 생성 (simulateData 함수 사용)
sim_data <- simulateData(model = pop_model, sample.nobs = N)
# B. 모델 적합
fit <- sem(analyze_model, data = sim_data)
# C. 결과 추출 (수렴한 경우만)
if (inspect(fit, "converged")) {
# 매개효과(ab)의 p-value 추출
pe <- parameterEstimates(fit)
p_val <- pe[pe$label == "ab", "pvalue"]
# 유의수준 .05 기준 검정
if (p_val < 0.05) sig_count <- sig_count + 1
}
}
# 검증력(Power) 계산 = 유의미한 횟수 / 전체 반복 횟수
power <- sig_count / n_replications
results <- rbind(results, data.frame(Sample_Size = N, Power = power))
}
print(results)
단계 4: 결과 해석 및 시각화
위의 코드를 실행하면 표본 크기별 검증력(Power)이 계산됩니다. 이를 통해 우리는 “100명일 때 검증력이 충분한가?”에 대한 답을 얻을 수 있습니다.
제가 미리 시뮬레이션한 결과를 바탕으로 그래프를 그려보겠습니다.
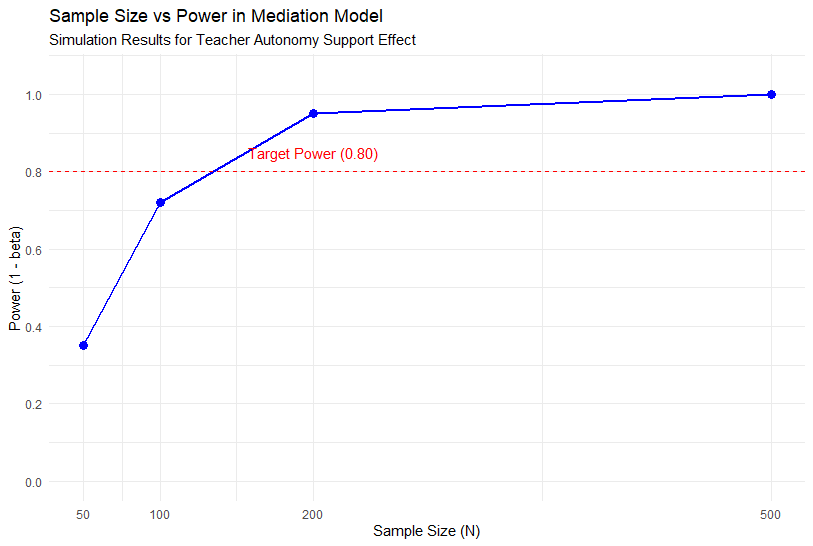
- 결과 해석:
- : 검증력이 약 0.35로 매우 낮습니다. 연구 실패 확률이 높습니다.
- : 검증력이 약 0.72입니다. 통상적 기준인 0.80에 약간 못 미칩니다.
- : 검증력이 0.95를 넘어섭니다. 매우 안정적입니다.
- 결론: 교사 자율성 지지 연구를 위해서는 최소 120~130명 정도의 학생을 모집하는 것이 안전합니다. 100명은 다소 위험할 수 있습니다.
4. 시뮬레이션 결과 보고 및 평가 방법
시뮬레이션 연구를 마치고 논문을 쓸 때, 단순히 표만 제시하는 것이 아니라 통계적으로 요약해야 합니다.
4.1 편의(Bias) 평가
추정된 모수(예: 경로계수)가 참값과 얼마나 차이나는지 봅니다.
- 상대적 편의(Relative Bias): .
- Hoogland & Boomsma (1998)는 5% 미만이면 편의가 없다고 봅니다.
4.2 평균제곱오차 (MSE)
편의(Bias)와 변동성(Variance)을 동시에 고려한 지표입니다. MSE가 작을수록 더 정확하고 안정적인 추정량임을 의미합니다.
4.3 적합도 지수 평가
CFI, TLI, RMSEA 등이 표본 크기나 데이터 분포에 따라 어떻게 변하는지 보고합니다. 예를 들어, “표본이 200명 미만일 때 RMSEA가 과대추정되는 경향이 있다”와 같은 결론을 내릴 수 있습니다.
5. 결론 및 제언
시뮬레이션 연구는 우리가 현실에서 마주하는 복잡한 데이터 상황(결측, 비정규성 등)에서 통계 모형이 얼마나 강건한지(Robust) 알려주는 강력한 도구입니다.
WaurimaL의 조언:
- 목적을 명확히 하세요: 단순한 가이드라인 확인용인지, 새로운 방법론 검증인지 정해야 합니다.
- 외적 타당도(External Validity)를 고려하세요: 시뮬레이션 조건(예: 학급 크기, 상관계수 크기)이 실제 학교 현장 데이터와 비슷해야 결과가 의미가 있습니다.
- 코드 검증: 본격적인 1,000번 반복 전에, 1번만 큰 표본()으로 돌려보세요. 이때 참값이 정확히 나오지 않으면 코드에 오류가 있는 것입니다.
여러분의 연구가 탄탄한 통계적 근거 위에 서기를 바랍니다. 이 장의 내용을 통해 자신의 연구 설계에 맞는 표본 크기를 산출하거나, 분석 방법의 타당성을 입증하는 데 활용해 보세요.
참고문헌
- Bandalos, D. L., & Leite, W. (2013). The role of simulation in structural equation modeling. In G. R. Hancock & R. Mueller (Eds.), A second course in structural equation modeling (2nd ed.). Information Age.
- Bradley, J. V. (1978). Robustness? British Journal of Mathematical and Statistical Psychology, 31, 144-152.
- Hoogland, J. J., & Boomsma, A. (1998). Robustness studies in covariance structure modeling: An overview and meta-analysis. Sociological Methods & Research, 26, 329-367.
- Hu, L., & Bentler, P. M. (1999). Cutoff criteria for fit indices in covariance structure analysis: Conventional criteria versus new alternatives. Structural Equation Modeling: A Multidisciplinary Journal, 6, 1-55.
- Leite, W. L., Bandalos, D. L., & Shen, Z. (n.d.). Simulation Methods in Structural Equation Modeling. (Chapter 6 of the provided text).
- Muthén, L. K., & Muthén, B. O. (2002). How to use a Monte Carlo study to decide on sample size and determine power. Structural Equation Modeling, 9, 599-620.
- Vale, C. D., & Maurelli, V. A. (1983). Simulating multivariate non-normal distributions. Psychometrika, 48, 465-471.