
1. 서론: SEM은 단순히 통계적 적합도 놀이인가?
교육학이나 심리학 연구를 하다 보면 우리는 늘 이런 경고를 듣습니다. “상관관계는 인과관계를 증명하지 않는다(Correlation does not prove causation).”
하지만 아이러니하게도 우리는 구조방정식(SEM)을 사용하여 경로 모형을 그리고, 화살표를 그으며 내심 “이 변수가 저 변수의 원인이야”라고 해석하고 싶어 합니다. 실제로 SEM의 초기 개척자들(Sewall Wright, Haavelmo 등)은 SEM을 데이터와 이론적 가정을 결합하여 인과적 결론을 도출하는 강력한 도구로 여겼습니다.
그러나 시간이 지나며 통계학자들의 비판(예: Freedman, Holland) 속에 SEM 연구자들은 자신감을 잃었습니다. “이 파라미터는 인과 효과가 아니다”라며 방어적인 태도를 취하게 되었죠. 이 챕터의 목적은 SEM이 어떻게 다시 강력한 인과추론의 도구가 될 수 있는지, 그 논리적 기반을 명확히 하는 것입니다.
2. SEM의 논리적 구조: 가정, 질의, 그리고 데이터
SEM이 인과관계를 주장할 수 있는 이유는 데이터가 마법을 부려서가 아닙니다. 바로 연구자가 투입하는 ‘가정(Assumptions)’ 때문입니다.
Judea Pearl은 SEM을 하나의 추론 엔진(Inference Engine)으로 봅니다.
- 입력 (Input):
- 가정(): 연구자가 이론적으로 정당화할 수 있는 인과적 가정들입니다. (예: “지능은 학업성취에 영향을 주지만, 학업성취가 지능을 바꾸지는 않는다.”)
- 질의(): 우리가 알고자 하는 질문입니다. (예: “방과 후 수업()을 들으면 성적()이 얼마나 오를까?”)
- 데이터(): 우리가 수집한 관찰 데이터입니다.
- 출력 (Output):
- 논리적 함의(): 데이터와 무관하게, 가정만으로 도출되는 논리적 결론입니다.
- 조건부 주장(): “가정 가 맞다면, 효과는 이다”라는 형태의 주장입니다.
- 검증 가능한 함의(): 데이터로 우리 모형의 가정이 틀렸는지 확인할 수 있는 부분입니다(적합도 검증).
WaurimaL의 팁: SEM 결과표에 있는 숫자가 “진짜 인과 효과”가 되려면, 여러분이 그린 화살표(가정 )가 이론적으로 탄탄해야 합니다. 통계 프로그램은 여러분의 가정이 참이라고 믿고 계산만 해줄 뿐입니다.
3. 구조방정식의 본질: ‘본다(Seeing)’와 ‘한다(Doing)’의 차이
가장 중요한 개념 중 하나는 연산자입니다.
- : 가 인 학생들을 관찰했을 때(Seeing), 의 확률입니다. (예: 학원을 다니는 학생들의 성적)
- : 모든 학생에게 강제로 X를 하게 했을 때(Doing/Intervention), 의 확률입니다. (예: 교육청이 모든 학생을 학원에 보내는 정책을 폈을 때의 성적).
구조방정식 는 단순한 회귀식이 아닙니다. 이것은 자연이 의 값을 결정하는 메커니즘을 표현한 것입니다. 여기서 는 다른 모든 변수를 고정하고 만 1단위 증가시켰을 때 의 변화량을 의미하며, 이는 인과적 해석을 담고 있습니다.
4. 반사실적 사고(Counterfactuals): “만약 그랬다면?”
우리가 교육 연구에서 진짜 궁금한 것은 이런 것입니다.
“철수가 보충수업을 안 들었는데 성적이 70점이다. 만약 철수가 보충수업을 들었더라면() 몇 점을 받았을까?”
이것이 바로 반사실(Counterfactuals)입니다. SEM은 이를 수학적으로 계산할 수 있는 도구를 제공합니다.
[예시] 철수의 성적 예측
다음과 같은 모형이 있다고 합시다 (Figure 3.4 참고).
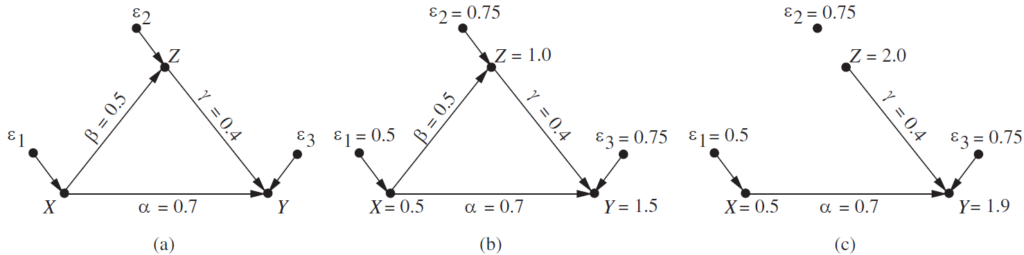
Note. From Handbook of structural equation modeling (p. 57), by R. H. Hoyle (Ed.), 2023, Guilford Press. Copyright 2023 by Guilford Press.
- : 보충수업 시간 (0.5시간)
- : 자습 시간 (1시간)
- : 시험 성적 (1.5점)
우리는 철수의 잠재적 특성(오차항 )을 계산한 뒤, 철수가 자습 시간을 2배로 늘렸다면() 성적이 어떻게 되었을지 계산할 수 있습니다. 이것은 단순한 회귀분석으로는 불가능하며, 구조적 모형이 있어야만 가능합니다.
5. 모의 데이터 생성 및 분석 (R & Jamovi)
이론만으로는 어려우니, 구체적인 교육학 시나리오를 만들어 R과 Jamovi(매개분석)를 통해 인과 효과를 추정해 보겠습니다. Pearl이 강조한 매개 공식(Mediation Formula)의 개념을 적용해 봅니다.
시나리오: ‘메타인지 훈련 프로그램’의 효과
- 독립변수 (): 메타인지 훈련 프로그램 참여 여부 (0: 미참여, 1: 참여)
- 매개변수 (): 자기주도학습 시간 (연속형)
- 종속변수 (): 기말고사 수학 성적 (연속형)
- 교란변수 (): 사전 수학 능력 (기초학습능력)
이 시나리오에서 우리는 프로그램이 성적을 직접 올리는지(직접 효과), 아니면 학습 시간을 늘려서 성적을 올리는지(간접 효과) 알고 싶습니다.
1) 데이터 생성 (R Code)
먼저, 인과적 구조를 반영하여 데이터를 생성합니다.
R
# 필요한 패키지 로드
if(!require(MASS)) install.packages("MASS")
set.seed(1234) # 재현성을 위해 시드 설정
# 샘플 수
N <- 1000
# 1. 교란변수 (C): 사전 수학 능력 (평균 50, 표준편차 10)
C <- rnorm(N, mean = 50, sd = 10)
# 2. 독립변수 (X): 메타인지 훈련 (랜덤 배정이지만, 사전 능력이 높으면 참여 확률이 약간 높게 설정 - 현실 반영)
# 로지스틱 함수를 이용해 확률 생성
prob_X <- 1 / (1 + exp(-(-2 + 0.05 * C)))
X <- rbinom(N, 1, prob_X)
# 3. 매개변수 (M): 자기주도학습 시간
# 훈련(X)과 사전능력(C)이 학습 시간에 영향을 줌
# M = 10 + 2*X + 0.1*C + error
M <- 10 + 2 * X + 0.1 * C + rnorm(N, mean = 0, sd = 2)
# 4. 종속변수 (Y): 기말고사 성적
# 훈련(X), 학습시간(M), 사전능력(C)이 모두 성적에 영향을 줌
# Y = 20 + 3*X + 1.5*M + 0.5*C + error
# 진정한 인과 효과(True Parameters):
# - X -> M (a path): 2
# - M -> Y (b path): 1.5
# - X -> Y (c' path, 직접효과): 3
# - 간접효과 (a*b): 2 * 1.5 = 3
# - 총효과: 3 + 3 = 6
Y <- 20 + 3 * X + 1.5 * M + 0.5 * C + rnorm(N, mean = 0, sd = 5)
# 데이터 프레임 생성
data <- data.frame(
Pre_Math = C,
Program = factor(X, levels = c(0, 1), labels = c("Control", "Treatment")),
Study_Time = M,
Final_Score = Y
)
# CSV 파일로 저장 (Jamovi에서 불러오기 위함)
write.csv(data, "meta_cognition_data.csv", row.names = FALSE)
# 데이터 확인
head(data)
생성된 예제 파일: chap032) Jamovi를 이용한 분석 가이드
Jamovi에서는 jmv 모듈(GLM)이나 medmod (Mediation) 모듈을 사용하여 분석할 수 있습니다. Pearl이 제안한 매개 공식은 비선형 모델에서도 작동하지만, 여기서는 이해를 돕기 위해 선형 모델을 가정하고 분석합니다.
- 데이터 불러오기: 위에서 생성한
meta_cognition_data.csv를 엽니다. - 분석 모듈:
Analyses>Mediation>Mediation(jamovi library에서medmod설치 필요). - 변수 설정:
- Dependent Variable: Final_Score ()
- Predictor: Program ()
- Mediator: Study_Time ()
- Covariates: Pre_Math () – 중요! 교란변수를 통제해야 정확한 인과 효과 추정이 가능합니다(Back-door criterion).
- 결과 해석:
- Indirect Effect (간접 효과):
Study_Time을 경유하는 효과입니다. R 코드에서 설정한 참값은 입니다. Jamovi 결과가 이와 유사하게 나오는지 확인합니다. - Direct Effect (직접 효과):
Program이Final_Score에 미치는 직접적인 영향입니다. 참값은 입니다. - Total Effect (총 효과): 직접효과 + 간접효과 .
- Indirect Effect (간접 효과):
Pearl의 관점에서의 해석:
전통적인 Baron & Kenny 방법이나 단순 회귀분석은 비선형성이나 상호작용이 있을 때 인과 효과를 오해할 수 있습니다. Pearl의 Mediation Formula 20는 어떤 형태의 함수(비선형 포함)라도 반사실적 정의(Counterfactual definition)를 통해 정확한 직접/간접 효과를 정의합니다. Jamovi의 결과는 선형 가정 하에 Pearl의 공식과 일치하는 결과를 줍니다.
6. 식별(Identification): 언제 인과관계를 주장할 수 있는가?
데이터만 있다고 무조건 인과관계를 찾을 수 있는 것은 아닙니다. 모델이 식별 가능(Identifiable)해야 합니다.
d-분리(d-separation)와 검증
우리가 그린 화살표가 맞는지 어떻게 알 수 있을까요? 그래프 이론의 d-separation을 사용합니다.
- 만약 경로만 있고 직접 경로가 없다면, 을 통제했을 때 와 는 통계적으로 독립이어야 합니다.
- 데이터에서 실제로 와 가 통제 하에 독립이라면, 우리 모델은 데이터와 일치(Fit)하는 것입니다. 이것이 적합도 검증의 원리입니다.
뒷문 기준(Back-Door Criterion)
관찰 데이터에서 인과 효과()를 구하기 위해 어떤 변수를 통제해야 할까요? Pearl은 뒷문 기준이라는 명확한 규칙을 제시합니다.
- 의 결과(후손)인 변수는 통제하지 마십시오.
- 로 들어오는 화살표(뒷문)를 막는 변수 집합을 통제하십시오.
위의 모의 데이터 예시에서 Pre_Math(사전 능력)는 Program()과 Final_Score() 모두에 영향을 주는 공통 원인이므로, 뒷문을 열어두고 있습니다. 따라서 이 변수를 통제해야만 편향 없는 인과 효과를 얻을 수 있습니다.
7. 결론
구조방정식모델링(SEM)은 단순한 통계 기법이 아니라, 인과적 가정을 수학적으로 표현하고 검증하는 언어입니다.
- SEM의 파라미터는 적절한 가정 하에서 인과적 효과로 해석될 수 있습니다.
- 반사실적 사고(-calculus)를 통해 우리는 “실험하지 않은 상황”에 대한 예측을 할 수 있습니다.
- 연구자는 자신의 가정을 그래프(Path Diagram)로 명확히 표현하고, d-separation과 같은 도구로 이를 검증해야 합니다.
교육 연구자로서 우리는 이제 “상관관계는 인과관계가 아니다”라는 말 뒤에 숨지 말고, “어떤 가정 하에서 이 상관관계를 인과관계로 해석할 수 있는가?”를 묻고 답해야 합니다.
참고문헌 (References)
- Bareinboim, E., & Pearl, J. (2016). Causal inference and the data-fusion problem. Proceedings of the National Academy of Sciences, 113, 7345-7352.
- Bollen, K. A. (1989). Structural equations with latent variables. New York: Wiley.
- Freedman, D. A. (1987). As others see us: A case study in path analysis. Journal of Educational Statistics, 12, 101-223.
- Muthén, B. (1987). Response to Freedman’s critique of path analysis: Improve credibility by better methodological training. Journal of Educational Statistics, 12, 178-184.
- Pearl, J. (2000). Causality: Models, reasoning, and inference. New York: Cambridge University Press.
- Pearl, J. (2009). Causality: Models, reasoning, and inference (2nd ed.). New York: Cambridge University Press.
- Pearl, J. (2012). The mediation formula: A guide to the assessment of causal pathways in non-linear models. In C. Berzuini, P. Dawid, & L. Bernardinelli (Eds.), Causality: Statistical perspectives and applications (pp. 151-179). Hoboken, NJ: Wiley.
- Pearl, J. (This Chapter). The Causal Foundations of Structural Equation Modeling.
- Wilkinson, L., Task Force on Statistical Inference, & APA Board of Scientific Affairs. (1999). Statistical methods in psychology journals: Guidelines and explanations. American Psychologist, 54, 594-604.
- Wright, S. (1921). Correlation and causation. Journal of Agricultural Research, 20, 557-585.
")
