
안녕하세요? 구조방정식 연구실에 오신 것을 환영합니다.
저는 여러분과 함께 구조방정식 모형(Structural Equation Modeling, SEM)의 기초부터 실제 적용까지 깊이 있게, 하지만 아주 쉽게 풀어갈 예정입니다.
많은 대학원생이 SEM을 “복잡한 수식이 난무하는 어려운 통계”라고 생각합니다. 하지만 걱정 마세요. SEM은 우리가 교육 현장에서 늘 고민하는 “눈에 보이지 않는 잠재적 능력(Latent Variable)과 그들 간의 인과관계”를 증명해 주는 아주 강력하고 매력적인 도구입니다.
리크 H. 호일(Rick H. Hoyle) 교수의 저서인 “Handbook of Structural Equation Modeling”을 기반으로 하되, 여러분이 이해하기 쉽도록 학교 현장의 예를 들어 재구성할 예정입니다.
1. 구조방정식 모형(SEM)이란 무엇인가?
1.1. SEM의 정의: 눈에 보이지 않는 것을 그리기
구조방정식(SEM)은 관찰된 데이터의 패턴, 분산, 공분산을 일으킨다고 가정되는 메커니즘을 모델링하는 일반적인 통계적 접근법입니다.
교육학에서 우리는 종종 ‘학업 동기’, ‘지능’, ‘교사 효능감’ 같은 개념을 다룹니다. 이것들은 키나 몸무게처럼 자로 잴 수 있나요? 아닙니다. 이것들은 잠재 변수(Latent Variable)입니다. 우리는 설문지 문항이나 시험 점수 같은 관측 변수(Observed Variable)를 통해 이 잠재 변수를 추론합니다. 그래서 SEM을 잠재 변수 모델링(Latent Variable Modeling)이라고도 부릅니다.
1.2. SEM은 ‘종합 선물 세트’
SEM은 기존의 통계 방법들(ANOVA, 회귀분석, 요인분석)을 하나로 통합하고 확장한 것입니다.
- 요인분석(Factor Analysis)의 기능: 여러 설문 문항(관측 변수)이 하나의 개념(잠재 변수)을 얼마나 잘 측정하는지 확인합니다.
- 회귀분석(Regression)의 기능: 변수들 간의 인과관계를 파악합니다.
SEM의 가장 큰 장점은 이 두 가지를 동시에(Simultaneously) 수행한다는 점입니다.
🎓 교육분야 예시:
여러분이 “가정 배경(X)이 학생의 자아효능감(M)을 통해 학업 성취(Y)에 미치는 영향”을 연구한다고 합시다.
- 기존 방법: 자아효능감 설문지 점수를 다 더해서 평균을 낸 뒤(측정오차 무시), 회귀분석을 돌립니다.
- SEM: 자아효능감이라는 ‘잠재 변수’를 설정하여 측정 오차를 제거하고, 동시에 변수 간의 구조적 관계를 파악합니다. 훨씬 정확하겠죠?
2. SEM의 핵심 논리: 공분산의 마법
2.1. 데이터는 공분산이다
일반적인 회귀분석은 개별 학생의 점수(Case-level data)와 회귀선 간의 차이(잔차)를 최소화하는 방식(OLS)을 씁니다. 하지만 SEM은 다릅니다. SEM의 데이터는 공분산(Covariance) 그 자체입니다.
- 목표: 연구자가 설정한 모형이 만들어내는 ‘모형 함의 공분산 행렬(Implied Covariance Matrix)’이 실제 데이터의 ‘관측된 공분산 행렬(Observed Covariance Matrix)’과 얼마나 비슷한지를 봅니다.
- 이 두 행렬의 차이가 0에 가까울수록 “모형이 데이터에 적합하다(Fit)”라고 말합니다.
2.2. 경로도(Path Diagram) 이해하기
SEM은 수식 대신 그림(경로도)으로 표현할 때 가장 직관적입니다.
위의 개념을 바탕으로 그림 1.1에 나온 기호들을 설명해 드리겠습니다.
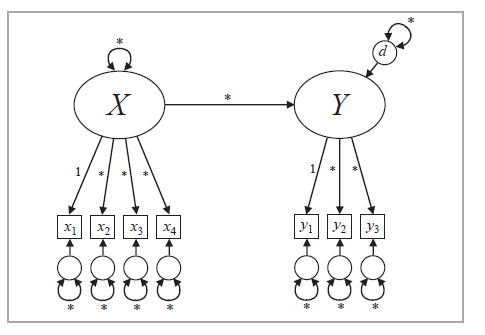
Note. From Handbook of structural equation modeling (p. 5), by R. H. Hoyle (Ed.), 2023, Guilford Press. Copyright 2023 by Guilford Press.
- 타원 (Ovals): 잠재 변수 (예: 수리 능력).
- 사각형 (Squares): 관측 변수 (예: 수학 시험 1, 2, 3번 문항).
- 작은 원 (Small Circles): 오차(Error) 또는 고유 분산(Uniqueness).
- 화살표 (Arrows): 영향력의 방향 (인과관계).
3. SEM 실행 프레임워크 (Implementation Framework)
Hoyle 교수는 SEM 실행을 4단계의 필수 과정과 4단계의 관련 과정으로 정리했습니다. 이를 실제 연구 시나리오에 대입해 봅시다.
🎓 시나리오: 교사 지지가 학업 성취에 미치는 영향
- 가설: 교사의 정서적 지지가 학생의 학습 동기를 높이고, 이것이 결국 학업 성취를 향상시킬 것이다 (매개효과).
1단계: 모형 명세화 (Specification)
연구 가설을 수식이나 그림으로 표현하는 단계입니다.
- 변수 설정: 잠재 변수(교사 지지, 동기, 성취)와 이를 측정할 관측 변수를 정합니다.
- 파라미터 설정: 어떤 경로를 추정할지(Free), 어떤 값을 고정할지(Fixed) 정합니다. 보통 잠재 변수의 척도를 맞추기 위해 관측 변수 중 하나의 경로계수를 1로 고정합니다.
- 식별(Identification) 확인: 해를 구할 수 있는지 확인합니다. 미지수의 개수가 정보의 개수보다 많으면 계산이 불가능합니다.
2단계: 추정 (Estimation)
데이터를 수집하고, 모수(Parameter)의 값을 찾아내는 단계입니다.
- 가장 많이 쓰이는 방법은 최대우도법(Maximum Likelihood, ML)입니다.
- 반복 계산(Iterative process): 컴퓨터는 임의의 값에서 시작하여, 실제 공분산 행렬과 모형이 예측한 행렬의 차이가 최소화될 때까지 값을 계속 수정합니다. 이 과정이 끝나면 “수렴(Converged)했다”고 합니다.
3단계: 적합도 평가 (Evaluation of Fit)
모형이 데이터를 얼마나 잘 설명하는지 성적표를 받는 시간입니다.
- (Chi-square): 전통적인 지표지만, 표본 크기에 민감하여 “모형이 완벽히 일치한다”는 비현실적인 가설을 검정하므로 이것만으로 판단하지 않습니다.
- 대안적 적합도 지수: CFI, TLI (0.90 이상이면 좋음), RMSEA (0.08 이하, 0.05 이하면 매우 좋음), SRMR 등을 종합적으로 봅니다.
4단계: 해석 및 보고 (Interpretation and Reporting)
- 계수 해석: 경로 계수가 통계적으로 유의한지 확인합니다 (t값 또는 z값).
- 보고: 모형 명세, 추정 방법, 적합도 지수, 결측치 처리 방법 등을 투명하게 보고해야 합니다.
4. 실습: jamovi와 R을 이용한 분석
이제 이론은 충분합니다. 실제로 어떻게 분석하는지 보여드리겠습니다.
jamovi는 클릭만으로 복잡한 통계를 수행할 수 있는 훌륭한 도구이며, 그 안에는 SEMLj (혹은 jmv)라는 강력한 모듈이 있습니다. 이것은 R의 lavaan 패키지를 기반으로 작동합니다.
4.1. 모의 데이터 생성 (Backstory)
우리는 서울 소재 중학교 2학년 학생 300명의 데이터를 수집했다고 가정합니다.
- Teacher_Support (교사 지지): 3문항 (TS1, TS2, TS3)
- Motivation (학습 동기): 3문항 (Mot1, Mot2, Mot3)
- Achievement (학업 성취): 3과목 점수 (Math, Eng, Sci)
이 데이터를 생성하고 분석하는 R 코드를 작성해 드리겠습니다. jamovi의 ‘R Editor’ 모듈을 사용하거나 R Studio에서 실행할 수 있습니다.
# 필요한 패키지 로드
if (!require(lavaan)) install.packages("lavaan")
if (!require(semPlot)) install.packages("semPlot")
library(lavaan)
# 1. 모의 데이터 생성 (Data Generation)
set.seed(1225) # 재현성을 위해 시드 설정
N <- 300
# 진점수(True Score) 생성 구조
# 교사지지 -> 동기 -> 성취
Teacher_Support_True <- rnorm(N, 0, 1)
Motivation_True <- 0.6 * Teacher_Support_True + rnorm(N, 0, 0.8)
Achievement_True <- 0.7 * Motivation_True + rnorm(N, 0, 0.8)
# 관측 변수 생성 (잠재변수 + 측정오차)
Data <- data.frame(
# 교사 지지 문항 (1~5점 척도 가정)
TS1 = round(Teacher_Support_True * 0.8 + rnorm(N, 0, 0.5) + 3),
TS2 = round(Teacher_Support_True * 0.9 + rnorm(N, 0, 0.5) + 3),
TS3 = round(Teacher_Support_True * 0.7 + rnorm(N, 0, 0.6) + 3),
# 학습 동기 문항
Mot1 = round(Motivation_True * 0.8 + rnorm(N, 0, 0.5) + 3),
Mot2 = round(Motivation_True * 0.85 + rnorm(N, 0, 0.5) + 3),
Mot3 = round(Motivation_True * 0.75 + rnorm(N, 0, 0.6) + 3),
# 학업 성취 (점수)
Math = round(Achievement_True * 10 + rnorm(N, 0, 5) + 70),
Eng = round(Achievement_True * 9 + rnorm(N, 0, 6) + 72),
Sci = round(Achievement_True * 8 + rnorm(N, 0, 5) + 68)
)
# 2. 모형 명세 (Specification)
# lavaan 문법:
# =~ : 측정 모형 (Latent variable defined by indicators)
# ~ : 구조 모형 (Regression)
model <- '
# 측정 모형 (Measurement Model)
Teacher_Support =~ TS1 + TS2 + TS3
Motivation =~ Mot1 + Mot2 + Mot3
Achievement =~ Math + Eng + Sci
# 구조 모형 (Structural Model)
Motivation ~ Teacher_Support
Achievement ~ Motivation
'
# 3. 추정 (Estimation)
fit <- sem(model, data = Data)
# 4. 결과 요약 (Evaluation & Interpretation)
summary(fit, fit.measures = TRUE, standardized = TRUE, rsquare = TRUE)
# 5. 경로도 그리기 (선택사항)
# library(semPlot)
# semPaths(fit, whatLabels = "std", layout = "tree")
생성된 예제 파일: chap01
4.2. jamovi에서의 분석 절차 (SEMLj 모듈 사용 시)
R 코드가 어렵다면 jamovi의 SEMLj 모듈을 설치하고 다음 순서로 진행하세요.
- 데이터 불러오기: 위에서 생성된 CSV 데이터를 엽니다.
- SEMLj > Structural Equation Models 선택.
- Endogenous Models (내생변수 설정):
Motivation을 Latent Variable로 정의하고TS1,TS2,TS3를 할당.Achievement를 Latent Variable로 정의하고Math,Eng,Sci를 할당.
- Exogenous Models (외생변수 설정):
Teacher_Support를 Latent Variable로 정의하고TS1,TS2,TS3할당.
- Path 설정:
Teacher_Support->MotivationMotivation->Achievement
- Options:
Standardized estimates,Fit measures(CFI, RMSEA 등) 체크.
5. 다양한 모형의 종류 (Types of Models)
SEM은 유연성이 매우 뛰어나 다양한 형태의 모형을 만들 수 있습니다.
5.1. 잠재 구조에 초점을 둔 모형
- 확인적 요인분석 (CFA): 연구자가 설정한 요인 구조가 맞는지 확인합니다. 예: “지능은 언어, 수리, 공간 지각의 3요인으로 구성된다”.
- 고차 요인 모형 (Second-order Factor Model): 여러 개의 1차 요인(예: 대수, 기하, 확률)이 더 높은 수준의 2차 요인(예: 수학적 능력)으로 묶이는 경우입니다.
5.2. 방향성 효과에 초점을 둔 모형
- 경로 분석 (Path Analysis): 잠재 변수 없이 관측 변수들만으로 인과관계를 봅니다.
- 매개효과 모형: 위 실습 예제처럼 X가 M을 거쳐 Y로 가는 경로를 분석합니다.
- 다집단 분석 (Multigroup Modeling): 남학생 집단과 여학생 집단에서 모형이 동일하게 적용되는지(형태 동일성, 측정 동일성 등) 비교합니다.
5.3. 평균과 성장을 다루는 모형
- 잠재 성장 모형 (Latent Growth Models): 시간이 지남에 따라 학생들의 성적이 어떻게 변하는지(초기치와 변화율)를 모델링합니다. 종단 연구의 꽃이라 할 수 있습니다.
6. 결론
SEM은 단순한 통계 기법을 넘어, 연구자의 이론적 아이디어를 현실의 데이터와 연결해 주는 강력한 가교입니다. 오늘 배운 내용을 정리하면 다음과 같습니다.
- SEM은 이론 검증 도구다: 막연한 탐색보다는 확고한 이론적 가설이 있을 때 가장 빛납니다.
- 과정은 체계적이어야 한다: 명세 -> 추정 -> 평가 -> 해석의 단계를 엄격히 따르십시오.
- 해석은 신중하게: 통계적으로 유의하다고 해서 무조건 인과관계가 증명된 것은 아닙니다.
이제 여러분은 자신의 데이터를 가지고 “보이지 않는 마음의 구조”를 그려낼 준비가 되었습니다.
참고문헌 (APA Style)
- Bollen, K. A., & Hoyle, R. H. (2012). Latent variables in structural equation modeling. In R. H. Hoyle (Ed.), Handbook of structural equation modeling (pp. 56–67). Guilford Press.
- Brown, T. A. (2012). Confirmatory factor analysis. In R. H. Hoyle (Ed.), Handbook of structural equation modeling (pp. 361–379). Guilford Press.
- Hoyle, R. H. (2012). Structural equation modeling: An overview. In R. H. Hoyle (Ed.), Handbook of structural equation modeling (pp. 3–16). Guilford Press.
- Kline, R. B. (2012). Assumptions in structural equation modeling. In R. H. Hoyle (Ed.), Handbook of structural equation modeling (pp. 111–125). Guilford Press.
- Pek, J., Davisson, E. K., & Hoyle, R. H. (2012). Visualizing structural equation models. In R. H. Hoyle (Ed.), Handbook of structural equation modeling (pp. 43-55). Guilford Press.
- Preacher, K. J., & Yaremych, H. E. (2012). Model selection in structural equation modeling. In R. H. Hoyle (Ed.), Handbook of structural equation modeling (pp. 207-216). Guilford Press.
- West, S. G., Wu, W., McNeish, D., & Savord, A. (2012). Model fit and model selection. In R. H. Hoyle (Ed.), Handbook of structural equation modeling (pp. 209-231). Guilford Press.