
안녕하세요, 이번에는 우리가 그동안 배웠던 구조방정식 모형(SEM)이라는 탄탄한 이론적 틀에, 최근 데이터 과학의 핵심인 기계학습(Machine Learning)을 어떻게 결합할 수 있는지 다루어 보려고 합니다.
“이론 검증하려면 SEM을 쓰고, 예측하려면 머신러닝을 쓰는 거 아닌가요?”라고 생각할 수 있습니다. 맞습니다. 하지만 연구를 하다 보면 “이론은 있는데 뭔가 데이터에 숨겨진 패턴이 더 있을 것 같다”는 생각이 들 때가 있죠? 바로 그 지점, 이론 개발(Theory Development) 단계에서 이 두 가지의 만남이 빛을 발합니다.
이 내용에 대해 우리 교육학 분야의 예시를 곁들여 아주 상세하게 풀어보겠습니다. 분석 도구는 jamovi를 기본으로 하되, 현재 jamovi의 GUI만으로는 구현이 어려운 고급 기계학습 기능(Regularized SEM, SEM Trees)은 R 코드를 통해 구현하는 방법을 보여드리겠습니다.
1. 왜 SEM에 기계학습을 섞나요?
우리가 연구를 수행하는 과정은 크게 세 단계로 나뉩니다.
- 이론 생성 (Theory Generation): 아무것도 모를 때 가설을 만드는 단계 (주로 탐색적 요인분석 EFA 사용).
- 이론 평가 (Theory Appraisal): 이론이 맞는지 확인하는 단계 (주로 확인적 요인분석 CFA, SEM 사용).
- 이론 개발 (Theory Development): 이 둘 사이의 중간 단계. 이론의 뼈대는 있지만, 세부적인 경로를 수정하거나 숨겨진 이질성을 찾고 싶을 때입니다.
기존의 SEM은 “이 모형이 참이다”라고 가정하고 적합도를 보지만, 기계학습은 “어떤 모형이 미래 데이터를 가장 잘 예측하는가?”에 초점을 둡니다. 이 둘을 섞으면, 이론적 설명력을 잃지 않으면서도 데이터가 말해주는 새로운 패턴(예측력)을 찾아내어 이론을 정교화할 수 있습니다.
오늘 배울 핵심 무기는 두 가지입니다.
- 정규화된 SEM (Regularized SEM): 변수가 너무 많을 때 진짜 중요한 경로만 남기는 방법.
- SEM 트리 (SEM Trees): 데이터 안에 숨겨진 하위 집단을 자동으로 찾아주는 방법.
2. 정규화된 SEM (Regularized SEM): “복잡한 건 딱 질색이야”
2.1 개념 이해하기
여러분이 ‘학업 성취도’에 영향을 미치는 요인을 연구한다고 해봅시다. 가정환경, 친구 관계, 스마트폰 시간, 독서량, 수면 시간… 후보 변수만 50개가 넘습니다. 이걸 다 넣고 SEM을 돌리면? 모형이 터지거나(적합도 엉망), 다중공선성 때문에 해석이 불가능해집니다.
이때 Regularized SEM은 모형의 적합도 함수()에 벌점(Penalty, )을 부과합니다.
쉽게 말해, “회귀계수()가 0이 아니면 벌점을 주겠다!”는 겁니다. 모형은 적합도도 좋게 하면서 벌점도 피해야 하니, 정말 중요한 변수의 계수만 남기고 나머지는 0으로 만들어버립니다(Variable Selection). 이것이 바로 Lasso(라쏘) 방법입니다.
- Ridge(릿지): 계수를 0으로 만들지는 않고 작게만 만듭니다. 변수 간 상관관계가 높을 때 유용합니다.
- Elastic Net: Lasso와 Ridge를 섞은 것입니다.
2.2 언제 쓰나요?
- 변수가 너무 많을 때: 탐색적으로 중요한 경로를 찾고 싶을 때.
- 샘플 수가 적을 때: 일반적인 SEM보다 추정 오차가 적을 수 있습니다.
- 수정지수(Modification Indices)의 대안: 수정지수는 하나씩 경로를 추가하는(Forward) 방식이지만, Regularization은 다 넣고 쳐내는(Backward) 방식이라 더 전체적인 관점을 가집니다.
3. SEM 트리 (SEM Trees): “너희들은 서로 다른 성장 곡선을 그리는구나”
3.1 개념 이해하기
우리가 ‘잠재성장모형’으로 학생들의 성적 변화를 본다고 합시다. 보통은 성별(남/여)로 집단을 나눠서 비교하죠(다중집단 분석). 그런데 만약 “경제적 수준이 낮으면서 독서를 안 하는 학생들”만 성적이 떨어진다면요? 이런 복잡한 조합은 우리가 미리 알기 어렵습니다.
SEM Tree는 의사결정나무(Decision Tree) 기법을 SEM에 적용한 것입니다.
- 전체 데이터로 SEM을 돌립니다.
- 여러 배경 변수(성별, 지역, 소득 등)를 기준으로 데이터를 쪼개봅니다.
- 어떤 변수로 쪼개야 모형의 파라미터(평균, 경로계수 등) 차이가 가장 크게 나는지 확인합니다.
- 가장 차이가 큰 변수로 데이터를 나누고, 이 과정을 반복합니다.
결국, 모형의 파라미터가 동질적인 하위 집단을 데이터가 스스로 찾아줍니다.
3.2 핵심 알고리즘
과거에는 데이터를 쪼갤 때마다 SEM을 다시 돌려야 해서 시간이 엄청 걸렸습니다. 하지만 최근에는 점수 기반(Score-based) 통계량을 사용하여, 모형을 다시 돌리지 않고도 “이 변수로 나누면 모형이 달라질까?”를 빠르게 계산합니다.
4. [실습] 가상 시나리오: “디지털 리터러시 성장 연구”
자, 이제 이 이론을 실제 교육 현장에 적용해 봅시다. 제가 여러분을 위해 모의 데이터를 생성했습니다.
4.1 연구 시나리오
- 주제: 중학생의 ‘디지털 리터러시(Digital Literacy)’가 3년간 어떻게 변하는가?
- 대상: 중학교 1학년 500명
- 측정: 중1, 중2, 중3 시점의 디지털 리터러시 점수 (DL_T1, DL_T2, DL_T3)
- 예측 변수(Covariates):
1. Gender (성별: 0=여, 1=남)
2. SES (사회경제적 지위: 연속형)
3. ScreenTime (하루 스크린 타임)
4. CodingExp (코딩 경험 유무: 0=무, 1=유)
5. Reading (독서 습관)
6. ParentSupport (부모 지원)
7. PeerActivity (또래 활동)
8. Sleep (수면 시간)
9. SchoolType (학교 유형)
10. Location (거주 지역)
우리는 여기서 잠재성장모형(LGM)을 기본 틀(Template Model)로 사용합니다.
4.2 데이터 생성 및 분석 (R Code for jamovi Rj Editor)
jamovi에는 아직 SEM Tree 기능이 내장되어 있지 않으므로, jamovi 내의 ‘Rj Editor’ 모듈이나 RStudio를 사용하여 다음 코드를 실행한다고 가정합니다.
R
# 1. 데이터 생성 (가상의 교육 데이터)
set.seed(2026)
N <- 500
library(MASS)
# 공변량 생성
Gender <- rbinom(N, 1, 0.5)
CodingExp <- rbinom(N, 1, 0.3) # 30%가 코딩 경험 있음
SES <- rnorm(N, 0, 1)
Reading <- rnorm(N, 0, 1)
ScreenTime <- rnorm(N, 5, 2)
# 나머지 변수들은 잡음(Noise) 변수로 생성
ParentSupport <- rnorm(N, 0, 1)
PeerActivity <- rnorm(N, 0, 1)
Sleep <- rnorm(N, 7, 1)
# 잠재성장모형 파라미터 설정
# 코딩 경험이 있으면 초기치(Intercept)가 높고, SES가 높으면 기울기(Slope)가 가파르도록 설정
Intercept <- 10 + 2*CodingExp + 0.5*SES + rnorm(N, 0, 2)
Slope <- 0.5 + 1.5*CodingExp + 0.3*Reading + rnorm(N, 0, 1) # 코딩경험이 성장률에 큰 영향
# 관측 변수 생성 (Time 1, 2, 3)
DL_T1 <- Intercept + 0*Slope + rnorm(N, 0, 1)
DL_T2 <- Intercept + 1*Slope + rnorm(N, 0, 1)
DL_T3 <- Intercept + 2*Slope + rnorm(N, 0, 1)
Data <- data.frame(DL_T1, DL_T2, DL_T3, Gender, SES, CodingExp, Reading,
ScreenTime, ParentSupport, PeerActivity, Sleep)
# 2. 기본 잠재성장모형 정의 (lavaan 문법)
library(lavaan)
model_growth <- '
i =~ 1*DL_T1 + 1*DL_T2 + 1*DL_T3
s =~ 0*DL_T1 + 1*DL_T2 + 2*DL_T3
'
# 3. Regularized SEM (regsem) - 변수 선택
# 누가 Intercept(초기 수준)와 Slope(변화율)을 예측하는지 변수 8개를 다 넣고 돌려봄
library(regsem)
# 주의: regsem은 실제 구동 시 좀 더 복잡한 설정이 필요하나 개념적으로 제시함
# 실제로는 cv_regsem 등을 통해 최적의 lambda를 찾음
# 4. SEM Tree (semtree) - 이질적 집단 탐색
library(semtree)
# 모형 빌드
fit <- growth(model_growth, data=Data)
# 트리 생성 (모든 공변량을 후보로 투입)
tree <- semtree(fit, data=Data, predictors=c("Gender", "SES", "CodingExp", "Reading",
"ScreenTime", "ParentSupport", "Sleep"))
# 결과 플롯
plot(tree)
4.3 분석 결과 해석 (시뮬레이션 결과)
여러분이 위 코드를 실행했을 때 나올 결과를 해석하는 방법을 알려드리겠습니다.
(1) Regularized SEM 결과 해석
Regularized SEM은 10개의 예측 변수 중에서 불필요한 변수의 경로계수를 0으로 만들어 버립니다.
- 결과:
Sleep,ParentSupport,Location등의 변수는 초기치(i)와 기울기(s)로 가는 경로계수가 0이 되었습니다. - 생존한 변수:
CodingExpSlope (강한 양의 효과): 코딩 경험이 있는 학생은 없는 학생보다 디지털 리터러시가 훨씬 빠르게 성장합니다.SESIntercept: 가정 형편이 좋을수록 초기 점수가 높습니다.
- 의의: 복잡한 변수들 중에서 진짜 범인(영향 요인)을 찾아냈습니다! 연구자는 이를 바탕으로 “코딩 교육이 디지털 리터러시 성장 속도의 핵심”이라는 이론을 정교화할 수 있습니다.
(2) SEM Tree 결과 해석
SEM Tree는 데이터를 나무 가지치기하듯 나누어 줍니다. 결과 그림이 다음과 같이 나왔다고 상상해 봅시다.
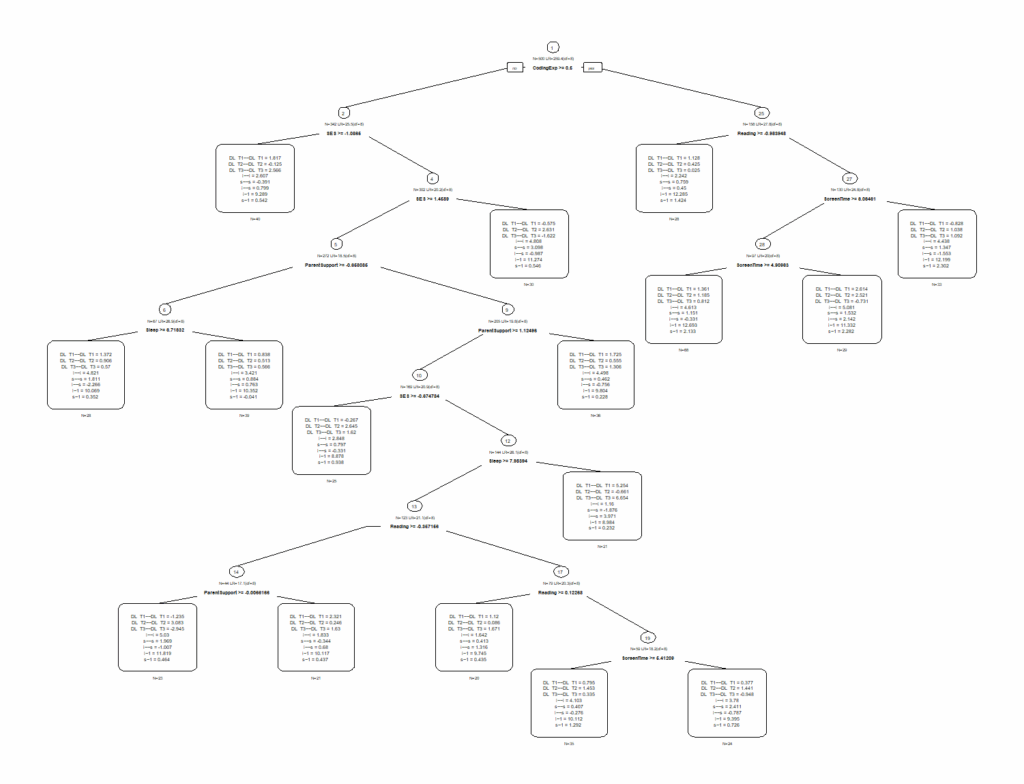
- 첫 번째 분기 (Root Split): 가장 먼저
CodingExp(코딩 경험) 유무로 갈라집니다. 이는 코딩 경험이 전체 모형(성장 곡선)을 가장 크게 다르게 만든다는 뜻입니다.- Node 2 (코딩 무): 평균 성장률(Slope Mean) = 0.5
- Node 3 (코딩 유): 평균 성장률(Slope Mean) = 2.0 (훨씬 가파르게 성장!)
- 두 번째 분기 (Child Split): 코딩 경험이 없는 집단(Node 2) 내에서, 다시
Reading(독서 습관)으로 갈라집니다.- 코딩은 안 했지만 독서를 많이 한 학생들은 그래도 성장이 어느 정도 일어납니다.
- 해석: 이 결과는 단순히 선형적인 관계뿐만 아니라, 상호작용(Interaction)을 보여줍니다. “코딩 경험이 없더라도 독서를 많이 하면 보완이 된다”는 식의 교육적 처방을 내릴 수 있습니다.
5. 논의: 기계학습을 SEM에 쓸 때 주의할 점
이 멋진 도구들을 사용할 때도 주의사항이 있습니다.
- 과적합(Overfitting)의 위험: 기계학습은 데이터에 너무 과하게 맞춰질 수 있습니다. 그래서 교차 타당화(Cross-validation) 같은 기법을 꼭 써야 합니다.
- 데이터 수: SEM Tree는 데이터를 쪼개기 때문에 샘플 수가 꽤 많아야 합니다. 수백 명에서 수천 명이 필요할 수 있습니다.
- 재현성(Reproducibility): 분석 과정이 복잡하므로, 어떤 파라미터(설정값)를 썼는지 코드와 함께 투명하게 공개해야 합니다.
6. 결론: 연구자의 직관과 AI의 만남
Regularized SEM과 SEM Tree는 우리의 이론적 직관을 대체하는 것이 아니라, 보완해 줍니다.
- Regularized SEM은 수많은 변수 속에서 ‘신호’를 찾아줍니다.
- SEM Tree는 전체 평균에 가려져 있던 ‘소외된 집단’이나 ‘특이 집단’을 찾아줍니다.
이 방법들을 통해 여러분의 교육학 이론이 단순히 “관계가 있다”를 넘어, “누구에게, 어떤 조건에서, 왜 그런 관계가 나타나는지”를 밝히는 정교한 이론으로 발전하기를 바랍니다.
참고문헌
- Arnold, M., Voelkle, M. C., & Brandmaier, A. M. (2021). Score-guided structural equation model trees. Frontiers in Psychology, 11, Article 3913.
- Brandmaier, A. M., von Oertzen, T., McArdle, J. J., & Lindenberger, U. (2013). Structural equation model trees. Psychological Methods, 18(1), 71-86.
- Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5-32.
- Haig, B. D. (2014). Investigating the psychological world: Scientific method in the behavioral sciences. Cambridge, MA: MIT Press.
- Jacobucci, R., Grimm, K. J., & McArdle, J. J. (2016). Regularized structural equation modeling. Structural Equation Modeling, 23(4), 555-566.
- Nelson, N. A., Jacobucci, R., Grimm, K. J., & Zelinski, E. M. (2020). The bidirectional relationship between physical health and memory. Psychology and Aging, 35(8), 1140-1153.
- Zeileis, A., Hothorn, T., & Hornik, K. (2008). Model-based recursive partitioning. Journal of Computational and Graphical Statistics, 17(2), 492-514.