
안녕하세요!
오늘은 종단 자료 모델링(Longitudinal Data Modeling)에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 들어가며: 스냅샷이 아닌 영화처럼
우리가 흔히 접하는 연구는 특정 시점에 학생들의 성적을 조사하는 횡단 연구(Cross-sectional Study)가 많습니다. 이건 마치 학생들의 달리기 시합 중 한 순간을 찍은 ‘사진’과 같습니다. 하지만 교육은 변화의 과정입니다. 우리가 정말 알고 싶은 건 “철수가 지난 학기보다 얼마나 성장했는가?” 혹은 “새로운 독서 프로그램이 시간이 지날수록 효과가 커지는가?”입니다.
이처럼 한 개인(subject)에 대해 시간을 두고 반복적으로 측정한 데이터를 종단 자료(Longitudinal Data)라고 합니다.
왜 다층모형인가요?
종단 자료는 2수준 다층 구조의 특수한 형태입니다.
- 1수준 (Level 1): 시간(Time) 혹은 측정 시점 (예: 1학기, 2학기, 3학기…)
- 2수준 (Level 2): 개인 (Subject, 예: 학생)
일반적인 회귀분석을 쓰면 안 되나요? 안 됩니다. 한 학생이 여러 번 시험을 봤다면, 그 점수들끼리는 서로 관련(상관)이 있겠죠? “내 점수는 서로 독립적이지 않다”는 사실 때문에 일반 회귀분석의 가정(독립성)이 위배됩니다. 그래서 우리는 다층모형을 사용해야 합니다.
2. 시나리오 및 데이터 생성: “독서 자신감 프로젝트”
이론만 보면 지루하니 가상의 학교 데이터를 만들어보겠습니다.
[시나리오]
A 초등학교에서는 200명의 학생을 대상으로 ‘독서 효능감(Reading Self-Efficacy)’이 4학기 동안 어떻게 변하는지 추적했습니다.
- Time (시간): 0(사전), 1(1학기 후), 2(2학기 후), 3(3학기 후)
- Group (집단): 실험군(새로운 독서 프로그램), 대조군(기존 수업)
- Outcome (종속변수): 독서 효능감 점수 (0~100점)
이제 R을 사용하여 이 시나리오에 맞는 데이터를 생성하겠습니다. (jamovi의 R Editor 모듈이나 RStudio에서 실행 가능합니다.)
R
# 데이터 생성 R 코드
set.seed(1234)
library(MASS)
library(lme4)
library(ggplot2)
# 1. 기본 설정
n_subjects <- 200
n_timepoints <- 4
time <- 0:3
# 2. 2수준(학생) 변수 생성
ids <- 1:n_subjects
group <- sample(c("Control", "Treatment"), n_subjects, replace = TRUE)
# 실험군은 초기치는 낮으나 성장률이 더 가파르도록 설정
intercept_mean <- ifelse(group == "Treatment", 40, 45)
slope_mean <- ifelse(group == "Treatment", 5, 2)
# 랜덤 효과 (개인별 차이): 절편과 기울기의 상관관계 설정
# 절편 분산=25, 기울기 분산=4, 상관계수=0.3
Sigma <- matrix(c(25, 3, 3, 4), 2, 2)
random_effects <- mvrnorm(n_subjects, mu = c(0, 0), Sigma = Sigma)
# 3. 데이터 프레임 만들기
data_long <- data.frame()
for(i in 1:n_subjects) {
# 개인별 고유한 절편과 기울기
b0i <- intercept_mean[i] + random_effects[i, 1]
b1i <- slope_mean[i] + random_effects[i, 2]
# 오차항 (1수준)
epsilon <- rnorm(n_timepoints, mean = 0, sd = 3)
# 종속변수 생성 (선형 성장 모형)
y <- b0i + b1i * time + epsilon
temp_df <- data.frame(
ID = factor(i),
Time = time,
Group = factor(group[i]),
Score = y
)
data_long <- rbind(data_long, temp_df)
}
# CSV로 저장 (jamovi에서 불러오기 위함)
# write.csv(data_long, "reading_growth.csv", row.names = FALSE)
# 데이터 확인
head(data_long)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data_long, "chap09.csv", row.names = FALSE)
3. 선형 혼합 모형 (Linear Mixed Model) 분석
교재에서는 일반적인 다층모형 표기(가 상위 수준)와 달리, 종단 자료에서는 관습적으로 를 개인(2수준), 를 시간(1수준)으로 표기한다고 강조합니다.
기본 식은 다음과 같습니다:
- : 고정 효과 (Fixed Effects) – 전체 평균적인 변화 패턴
- : 랜덤 효과 (Random Effects) – 개인별 편차
- : 잔차 (Residuals) – 측정 오차
분석 단계 (jamovi & R)
1단계: 시각화 (스파게티 플롯)
데이터를 받으면 가장 먼저 그려봐야 합니다. 학생 개개인의 성장 곡선이 어떻게 생겼는지 확인합니다.
R
# 스파게티 플롯 생성
ggplot(data_long, aes(x = Time, y = Score, group = ID, color = Group)) +
geom_line(alpha = 0.3) +
stat_summary(aes(group = Group, color = Group), fun = mean, geom = "line", size = 1.5) +
theme_minimal() +
labs(title = "학생별 독서 효능감 변화 곡선")
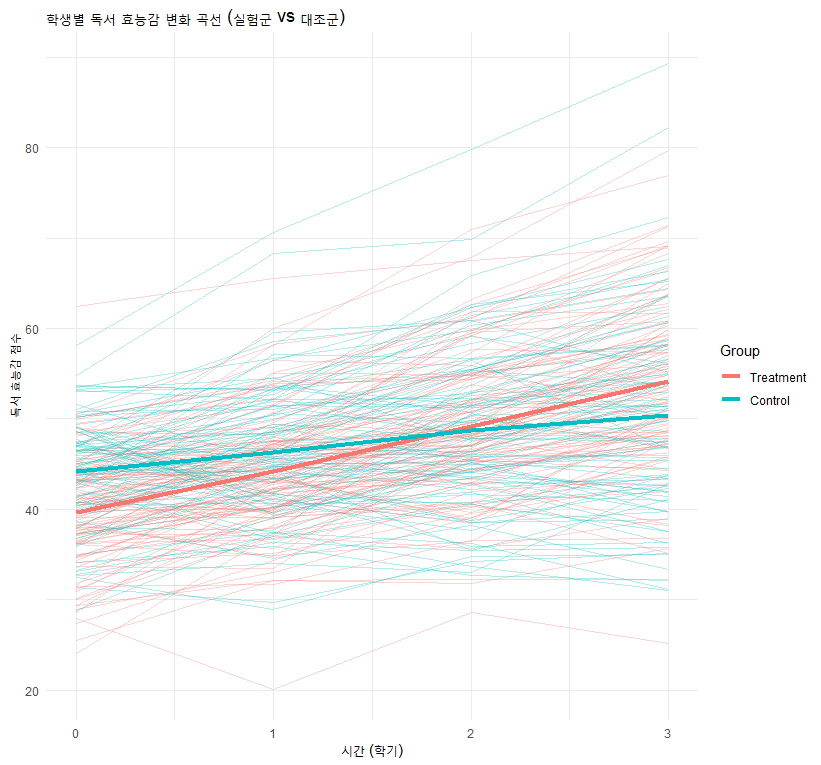
해석: 얇은 선들은 학생 개개인이고, 굵은 선은 집단별 평균입니다. 실험군(Treatment)이 초기에는 낮지만 시간이 지날수록 빠르게 성장하는 패턴이 보이나요?
2단계: 비조건부 성장 모형 (Unconditional Growth Model)
시간에 따른 변화가 선형(직선)인지 확인하고, 개인별 성장 속도에 차이가 있는지 검증합니다.
- jamovi 절차:
Analyses>Linear Models>Linear Mixed Model선택- Dependent Variable:
Score - Cluster:
ID(2수준 단위) - Covariates:
Time - Fixed Effects:
Time(전체 평균 기울기 확인) - Random Effects:
Intercept | ID: 초기치(출발점)가 학생마다 다른가?Time | ID: 변화율(기울기)이 학생마다 다른가?
이때 랜덤 효과의 분산-공분산 행렬 는 다음과 같이 설정됩니다.
여기서 (기울기의 분산)이 유의하다는 것은 “학생마다 성장 속도가 다르다”는 뜻입니다.
3단계: 조건부 성장 모형 (Conditional Growth Model)
이제 “왜 성장 속도가 다를까?”를 설명하기 위해 설명변수(Group)를 투입합니다.
- jamovi 절차:
- 위 설정에서 Factors에
Group을 추가합니다. - Fixed Effects에
Group,Time, 그리고Group * Time(상호작용항)을 넣습니다.
- 위 설정에서 Factors에
- 결과 해석의 핵심 (교재 기반):
Time효과: 대조군의 평균 성장률.Group * Time효과: 가장 중요! 실험군이 대조군보다 시간이 지날수록 얼마나 더(또는 덜) 성장하는지를 나타냅니다. 이 값이 유의하면 “프로그램의 효과가 있다”고 말할 수 있습니다.
4. 이산형 종단 자료 (Discrete Longitudinal Data)
만약 종속변수가 점수(연속형)가 아니라, “독서 습관 형성 여부 (성공=1, 실패=0)”와 같은 이항(Binary) 변수라면 어떻게 해야 할까요? 일반적으로 두 가지 접근법이 있습니다.
4.1. 주변 모형 (Marginal Models) – GEE
- 개념: 개인별 변화보다는 “전체 집단의 평균적인 변화”에 관심이 있을 때 사용합니다.
- 해석: “우리 학교 전체 학생들의 독서 습관 성공률이 시간이 지남에 따라 증가했는가?” (Population-averaged interpretation).
- 방법: GEE (Generalized Estimating Equations)를 사용합니다. 데이터의 분포 가정을 엄격하게 하지 않아도 되어 강건(Robust)합니다.
- Jamovi 구현: Jamovi의 기본 메뉴에는 없으나,
GAMLj모듈을 설치하면 GEE와 유사한 GLM 분석이 가능하며, R의geepack패키지를 사용하는 것이 가장 정확합니다.
4.2. 일반화 선형 혼합 모형 (GLMM)
- 개념: “개별 학생의 변화”와 그 안에서의 관계를 모델링합니다.
- 해석: “철수라는 학생이 이 프로그램을 들었을 때 성공할 확률이 어떻게 변하는가?” (Subject-specific interpretation).
- 수식: 연결 함수(Link function, 예: 로짓)를 사용하여 선형 결합을 변환합니다.
- Jamovi 구현:
Linear Models>Generalized Mixed Models선택- Dependent Variable: 성공 여부 (0, 1)
- Distribution: Binomial
- Link: Logit
- 나머지 설정은 LMM과 동일.
[WaurimaL의 팁]
교육 현장 연구에서는 보통 GLMM을 더 선호합니다. 우리는 학생 개개인의 특성과 성장에 관심이 많으니까요. 하지만 정책 입안자에게 보고서를 쓸 때는 Marginal Model의 결과가 더 직관적일 수 있습니다.
5. 결측치 (Missing Data): 피할 수 없는 골칫거리
종단 연구의 숙명은 “학생이 전학 가거나 아파서 검사를 못 받는 경우”입니다. 이를 불완전 자료(Incomplete Data)라고 합니다.
결측 메커니즘 3가지
- MCAR (완전 무작위): 선생님이 실수로 시험지를 잃어버림. 데이터 분석에 큰 문제 없음.
- MAR (무작위): 지난 시험 점수가 낮은 학생들이 이번 시험에 결석함. (관측된 데이터로 설명 가능). 다층모형(Likelihood-based)은 이를 어느 정도 보정해 줍니다.
- NMAR (비무작위): 공부를 안 해서(측정하지 못한 값 때문에) 시험을 안 봄. 가장 위험함. 분석 결과가 편향(Bias)될 수 있음.
대처법: 다층모형은 기본적으로 MAR 가정하에 분석을 수행하므로, 단순 반복측정 분산분석(RM-ANOVA)보다 결측치 처리에 훨씬 강력합니다. jamovi는 결측치가 있는 행을 무조건 삭제하지 않고, 가능한 정보를 최대한 활용합니다.
6. 나가며: 정리 및 다음 단계
오늘 우리는 시간을 품은 데이터, 종단 자료를 다층모형으로 분석하는 법을 배웠습니다.
- 종단 자료는 시간(1수준)이 개인(2수준)에 내재된 구조입니다.
- LMM을 통해 개인별 초기치와 성장 속도의 차이를 추정할 수 있습니다.
- 종속변수가 범주형일 때는 GLMM을 사용합니다.
- 다층모형은 결측치가 존재하는 교육 현장 데이터에 매우 유용합니다.
참고문헌 (References)
- Fitzmaurice, G. M., Laird, N. M., & Ware, J. H. (2011). Applied longitudinal analysis (2nd ed.). Wiley.
- Heck, R. H., Thomas, S. L., & Tabata, L. N. (2013). Multilevel and longitudinal modeling with IBM SPSS. Routledge.
- Laird, N. M., & Fitzmaurice, G. M. (2013). Longitudinal Data Modeling. In The SAGE Handbook of Multilevel Modeling (Chap. 9). SAGE Publications.
- Singer, J. D., & Willett, J. B. (2003). Applied longitudinal data analysis: Modeling change and event occurrence. Oxford University Press.