Chap12. 다층모형과 인과추론(Multilevel Models and Causal Inference)
안녕하세요!
오늘은 “다층모형과 인과추론(Multilevel Models and Causal Inference)”에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 들어가며: 왜 다층모형인가?
전통적인 회귀분석은 모든 학생이 서로 독립적이라고 가정합니다. 하지만 교육 현장은 그렇지 않습니다. 같은 학교, 같은 반 학생들은 급훈, 담임 선생님, 학교 분위기 등을 공유합니다. 이를 위계적 구조(Hierarchical Structure) 또는 집단 의존성(Group Dependencies)이라고 합니다.
인과추론(Causal Inference)의 관점에서, 데이터가 이러한 계층 구조를 가질 때 다층모형(Multilevel Model)을 사용하는 것은 단순한 통계적 선호가 아니라, 편향(Bias)을 줄이고 정확한 표준오차를 추정하기 위한 필수 전략입니다.
2. 인과추론의 기초 개념과 교육적 예시
본격적인 분석에 앞서, 인과추론의 핵심 개념을 학교 상황에 빗대어 정의해 봅시다.
2.1 잠재적 결과 (Potential Outcomes)
어떤 학생 철수()가 있습니다.
: 철수가 ‘방과후 보충수업()’을 들었을 때의 성적
: 철수가 ‘방과후 보충수업()’을 듣지 않았을 때의 성적
인과 효과(Causal Effect)는 이 둘의 차이 입니다. 하지만 현실에서 우리는 철수가 수업을 듣거나, 듣지 않거나 둘 중 하나의 결과만 볼 수 있습니다. 이를 “인과추론의 근본적인 문제(Missing Data Problem)”라고 합니다.
2.2 SUTVA (Stable Unit Treatment Value Assumption)
이 가정은 “철수가 보충수업을 받았는지 여부가, 옆 짝꿍 영희의 성적에 영향을 주지 않아야 한다(상호간섭 없음)”는 것입니다.
문제점: 학교에서는 이 가정이 자주 깨집니다. 철수가 보충수업에서 배운 내용을 영희에게 알려줄 수 있기 때문입니다. 이를 해결하기 위해 집단(학교/학급) 단위 무선화가 권장되기도 합니다.
3. 연구 설계에 따른 다층모형 적용
3.1 무선화 실험 (Randomized Experiments)
가장 이상적인 상황입니다. 처치(Treatment)가 무작위로 배정되면, 평균적으로 두 집단은 성향이 비슷해집니다().
A. 개인 단위 무선배정 (학생별 제비뽑기)
학생들에게 무작위로 새로운 ‘독서 프로그램’을 배정했습니다. 하지만 학생들은 학교()라는 집단에 속해 있습니다. 학교마다 평균 독서 능력이 다를 수 있으므로, 이를 반영한 다층모형(Random Intercept Model)이 필요합니다.
: 번째 학교의 고유한 특성(학교 효과, 랜덤 절편)
: 독서 프로그램의 효과 (우리가 알고 싶은 값)
이 모형을 쓰면 학교 간 차이()를 통제하고 순수한 프로그램 효과()를 더 정밀하게 추정할 수 있습니다.
B. 집단 단위 무선배정 (학교별 제비뽑기)
교육 정책 연구에서는 흔히 “A학교는 실험군, B학교는 대조군”으로 배정합니다. 이를 군집 무선화(Cluster Randomized Experiments)라고 합니다.
이유: ‘학교 폭력 예방 캠페인’처럼 학교 전체 분위기를 바꾸는 처치는 학생 개인별로 쪼개서 적용할 수 없기 때문입니다.
분석: 처치 변수()가 학생 수준()이 아닌 학교 수준()에 들어갑니다.
3.2 관찰 연구 (Observational Studies)
현실적으로 무선 배정이 불가능할 때(예: 사립학교 진학 효과), 우리는 무시가능성(Ignorability) 가정을 도입합니다. 즉, “부모의 소득, 지능 등 공변량()이 같다면, 사립학교와 공립학교 학생은 비교 가능하다”고 가정하는 것입니다.
성향점수(Propensity Score) 활용: 다층 구조에서는 성향점수를 추정할 때도 다층모형을 사용하는 것이 좋습니다.
4. [실습] jamovi & R을 활용한 다층 인과 분석
이제 가상의 시나리오를 통해 실제 데이터를 생성하고 분석해 보겠습니다.
4.1 시나리오: “아침 독서 마라톤” 효과 분석
연구 배경: 경기도 교육청은 초등학생의 어휘력 향상을 위해 매일 아침 20분간 책을 읽는 ‘아침 독서 마라톤’ 프로그램을 개발했습니다.
연구 설계:
총 20개 학교, 학교당 30명의 학생(총 600명).
군집 무선화(Cluster RCT): 학교 단위로 제비뽑기를 하여 10개 학교는 ‘프로그램 시행(Treatment)’, 10개 학교는 ‘기존 자습(Control)’을 하도록 했습니다.
데이터 구조:
Level 1: 학생 (사후 어휘력 점수 score)
Level 2: 학교 (school_id)
처치: program (1=시행, 0=미시행)
4.2 R을 이용한 모의 데이터 생성
jamovi는 R 기반이므로, 아래 코드로 데이터를 생성하여 CSV로 저장한 뒤 jamovi에서 불러오면 됩니다.
R
# 필수 라이브러리 로드
library(lme4)
library(tidyverse)
set.seed(2026) # 재현성을 위한 시드 설정
# 1. 파라미터 설정
n_schools <- 20 # 학교 수
n_students <- 30 # 학교당 학생 수
n_total <- n_schools * n_students
# 2. 학교 수준 효과 (Level 2)
# 학교마다 평균 어휘력이 다름 (표준편차 5)
school_intercept <- rnorm(n_schools, mean = 0, sd = 5)
# 처치 배정 (학교 단위 무선화)
# 1~10번 학교: 통제군(0), 11~20번 학교: 실험군(1)
school_treatment <- c(rep(0, 10), rep(1, 10))
# 학교 데이터 프레임
school_data <- data.frame(
school_id = 1:n_schools,
school_eff = school_intercept,
program = school_treatment
)
# 3. 학생 수준 데이터 생성 (Level 1)
data <- data.frame(
student_id = 1:n_total,
school_id = rep(1:n_schools, each = n_students)
)
# 학교 정보 병합
data <- left_join(data, school_data, by = "school_id")
# 4. 결과 변수 생성 (어휘력 점수)
# 기본 점수 70점 + 프로그램 효과 8점 + 학교 효과 + 개인 오차(sd=8)
# y_ij = 70 + 8 * z_j + u_j + e_ij
data <- data %>%
mutate(
error = rnorm(n_total, mean = 0, sd = 8),
score = 70 + 8 * program + school_eff + error
)
# 팩터 변환
data$school_id <- as.factor(data$school_id)
data$program <- factor(data$program, levels = c(0, 1), labels = c("Control", "Treatment"))
# 데이터 확인
head(data)
이 데이터는 학교 간 차이(School Effect)가 존재하고, 처치가 학교 단위로 부여되었으므로 다층모형(Linear Mixed Model)을 사용해야 정확합니다.
Step 1: 데이터 탐색 및 시각화
분석 전에 데이터의 구조를 눈으로 확인해야 합니다.
jamovi 메뉴:Exploration > Descriptives
Variables에 score를 넣고, Split by에 program을 넣습니다.
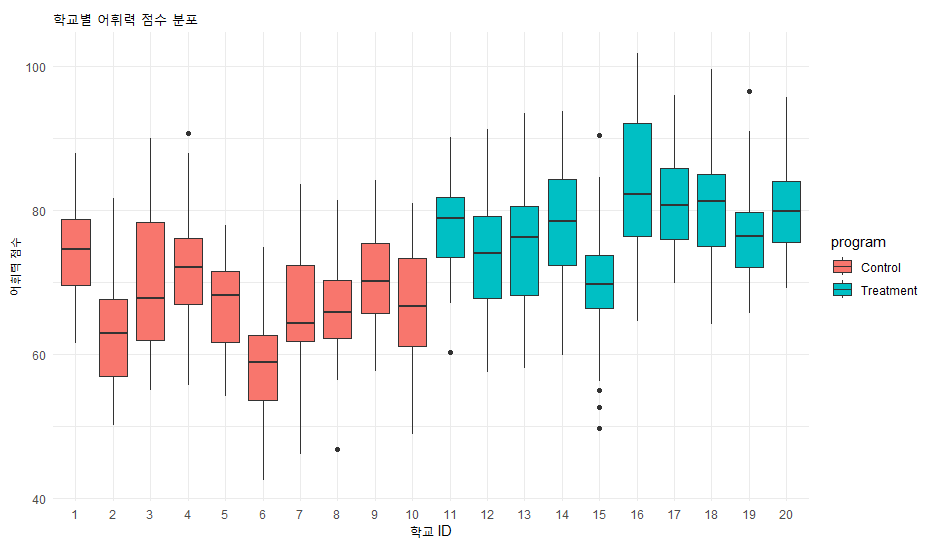
Box Plot: 학교별 차이를 보기 위해 Box plot을 체크하고, X축에 program을 둡니다. (※ jamovi 기본 기능으로는 학교별 boxplot을 한 번에 그리기 어려우므로 R 모듈인 seolmatrix나 scatr 모듈을 설치하여 시각화하면 좋습니다.)
[R 시각화 코드]
R
# 학교별 점수 분포 시각화
ggplot(data, aes(x = school_id, y = score, fill = program)) +
geom_boxplot() +
theme_minimal() +
labs(title = "학교별 어휘력 점수 분포", y = "어휘력 점수", x = "학교 ID")
해석: 상자 그림을 보면 같은 처치 집단 내에서도 학교마다 점수의 높낮이가 다름을 알 수 있습니다. 이것이 바로 (학교 효과)입니다.
Step 2: 다층모형 분석 (Linear Mixed Models)
모듈 선택: 상단 메뉴에서 Linear Models > Mixed Model을 클릭합니다. (보이지 않으면 jamovi Library에서 GAMLj 모듈을 설치하는 것을 강력 추천합니다. 여기서는 기본 Mixed Model 기준으로 설명합니다.)
변수 설정:
Dependent Variable (종속변수):score
Covariates (공변량) 또는 Factors:program (처치 변수)
Cluster (군집 변수):school_id
Random Effects (랜덤 효과) 설정:
왼쪽의 program을 오른쪽으로 옮기지 않고, Intercept만 Random Coefficients에 둡니다. (기본적으로 (Intercept | school_id)로 설정됨)
이는 학교마다 평균 점수(절편)가 다름을 허용하는 것입니다.
Fixed Effects (고정 효과) 설정:
program을 Model Terms에 넣습니다. 이것이 우리가 알고 싶은 ‘독서 마라톤 효과’입니다.
Step 3: 결과 해석
jamovi의 결과표(Estimates)는 다음과 유사하게 나옵니다.
Effect
Estimate
SE
t
p
Intercept
72.574
0.972
74.681
< .001
program (Treatment)
10.162
1.944
5.228
< .001
Fixed Effects:program의 Estimate가 약 10.162입니다. 즉, 독서 마라톤을 한 학교 학생들이 하지 않은 학교보다 평균적으로 약 10.162점 더 높은 어휘력을 보입니다. 이므로 통계적으로 유의합니다.
Random Components (Variance):
(School Intercept): 학교 간 분산. 이 값이 0보다 크다면 학교 효과가 존재한다는 뜻입니다.
ICC (Intraclass Correlation Coefficient): 전체 분산 중 학교가 설명하는 비율입니다.
5. 심화: 불응(Noncompliance)과 도구변수(IV)
실험을 했는데, 독서 프로그램을 하라고 배정받은 학교의 일부 학생이 땡땡이를 쳤다면(Noncompliance) 어떻게 될까요? 이때는 “배정된 상태()”를 도구변수(Instrument)로 사용하여, 실제 “참여한 상태()”의 효과를 추정해야 합니다.
jamovi/R 구현 (2단계 최소자승법 개념)
1단계: 실제 참여 여부()를 배정 여부()로 예측합니다.
2단계: 1단계에서 예측된 참여값()을 사용하여 점수()를 예측합니다.
이 분석은 jamovi의 sem (구조방정식) 모듈이나 R의 AER 패키지(ivreg)를 통해 수행할 수 있습니다. 중요한 건 배정()은 오직 참여()를 통해서만 결과()에 영향을 미쳐야 한다(배제 제한)는 가정입니다.
6. 결론
다층모형을 활용한 인과추론은 교육 현장과 같이 “집단 속에 개인이 속한 데이터”를 분석할 때 가장 강력한 도구입니다.
설계: 가능하다면 학교 단위 무선화(Cluster RCT)가 상호간섭(SUTVA 위배) 문제를 피하는 데 유리합니다.
분석: 단순히 평균을 비교하는 t-test 대신, 학교의 무선 절편(Random Intercept)을 포함한 혼합 모형을 사용해야 표준오차의 과소추정을 막을 수 있습니다.
해석: 결과는 “개인 수준의 효과”인지 “학교 수준의 효과”인지 명확히 구분하여 해석해야 합니다.
이 장의 내용이 여러분의 연구에 튼튼한 방법론적 기초가 되기를 바랍니다.
참고문헌 (APA Style)
Almond, D., Chay, K., & Lee, D. (2005). The costs of low birth weight. The Quarterly Journal of Economics, 120(3), 1031-1083.
Angrist, J. D., Imbens, G. W., & Rubin, D. B. (1996). Identification of causal effects using instrumental variables. Journal of the American Statistical Association, 91(434), 444-472.
Cornfield, J. (1978). Randomization by group: A formal analysis. American Journal of Epidemiology, 108(2), 100-102.
Gelman, A., & Hill, J. (2007). Data analysis using regression and multilevel/hierarchical models. Cambridge University Press.
Hill, J. (2013). Multilevel models and causal inference. In The SAGE Handbook of Multilevel Modeling (Chapter 12, pp. 201-219).
Hong, G., & Raudenbush, S. W. (2006). Evaluating kindergarten retention policy: A case study of causal inference for multilevel observational data. Journal of the American Statistical Association, 101(475), 901-910.
Kim, J., & Seltzer, M. (2007). Causal inference in multilevel settings in which selection processes vary across schools (Tech. Rep.). CRESST, UCLA.
Rubin, D. B. (1978). Bayesian inference for causal effects: The role of randomization. The Annals of Statistics, 6(1), 34-58.
Rubin, D. B. (1990). Formal modes of statistical inference for causal effects. Journal of Statistical Planning and Inference, 25(3), 279-292.
Slavin, R. E., Madden, N. A., Dolan, L. J., & Wasik, B. A. (1996). Every child, every school: Success for all. Corwin Press.