
안녕하세요!
오늘은 다층모형을 활용한 메타분석(Meta-Analysis)에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 메타분석이란 무엇일까요?
우리가 어떤 교육적 질문, 예를 들어 “선생님의 칭찬이 학생의 수학 성적을 올려줄까?”라는 궁금증이 생겼다고 해봅시다. 어떤 연구에서는 “엄청나게 효과가 있다”고 하고, 어떤 연구에서는 “별로 효과가 없다”고 합니다. 경험적 연구가 축적됨에 따라, 무엇이 알려져 있고 어떤 부분의 연구가 불충분하거나 모순되는지 명확히 파악하기 위해 연구 결과들을 체계화하고 종합해야 할 필요성이 생겼습니다. 메타분석은 여러 연구들의 분석 결과를 결합하여 일반적인 결론을 도출하기 위해 통계적 방법을 사용하는 활동을 뜻합니다.
- 1976년, Glass는 교육 심리학 분야의 연구 결과들을 결합하는 맥락에서 ‘메타분석’이라는 용어를 처음 만들었습니다.
- 이후 이 방법은 교육학, 심리학 및 기타 사회과학 분야에서 폭넓게 사용되고 있습니다.
- 메타분석은 여러 연구에서 나온 추정치들을 모아서 하나의 요약된 결과를 얻어내는 과정입니다.
초등학생에게 설명하자면, 메타분석은 “여러 명의 요리사가 만든 떡볶이 레시피(개별 연구)를 다 모아서, 세상에서 가장 평균적이고 맛있는 궁극의 떡볶이 황금 레시피(통합된 결과)를 찾는 과정”이라고 할 수 있습니다!
2. 효과크기(Effect Size): 과일의 맛을 통일하기
연구마다 학생들의 성적을 측정하는 시험지가 다르고 만점도 다릅니다. 이럴 때 결과를 하나로 합치려면 ‘효과크기’라는 공통의 단위로 변환해야 합니다. 효과크기는 메타분석에 포함된 연구들의 결과를 요약하는 데 사용되는 수치적 지수입니다. 연구들은 각자 효과크기의 추정치와 그 추정치의 불확실성(표준오차)을 제공하게 됩니다. 이상적으로, 효과크기는 모든 연구의 결과를 “공통의 미터법(common metric)”으로 표현하여 쉽게 해석하고 결합할 수 있게 해야 합니다.
사회과학에서 가장 많이 쓰이는 세 가지 효과크기는 다음과 같습니다:
- 표준화된 평균 차이 (Standardized Mean Difference, 또는 )
- 연속형 척도로 결과를 측정하는 처치나 개입의 효과를 연구할 때 자연스러운 효과크기입니다.
- 처치 집단의 평균 결과와 통제 집단의 평균 결과의 차이를 집단 내 표준편차로 나눈 값입니다.
- 모수 의 공식은 다음과 같습니다: .
- 여기서 는 처치 집단의 모평균, 는 통제 집단의 모평균, 는 집단 내 모표준편차입니다.
- 로그 오즈비 (Log Odds Ratio)
- 이분형 척도(예: 합격/불합격)로 측정하는 연구에서 자연스러운 효과크기입니다.
- 상관계수 (Correlation Coefficient)
- 두 연속형 변수 사이의 관계를 나타낼 때 쓰이며, 피셔의 -변환(Fisher z-transform)을 통해 분석이 진행되곤 합니다.
3. 다층모형을 이용한 메타분석 (다층분석의 세계)
메타분석 데이터를 설명하는 가장 자연스러운 방법은 2수준(two-level) 위계적 모형(다층모형)을 사용하는 것입니다.
- 1수준 (연구 내 모형): 연구 내의 추정 오차 분산을 다룹니다.
- 2수준 (연구 간 모형): 효과크기가 연구들 사이에서 어떻게 달라지는지(연구 간 변산)를 다룹니다.
수식으로 보면 이렇습니다. 개의 연구가 있다고 할 때:
- 1수준: . 여기서 는 관찰된 효과크기, 는 진짜 효과크기 모수, 는 오차입니다.
- 2수준: . 여기서 는 평균 효과크기(고정 효과)이고, 는 연구별 무선 효과입니다.
고정효과 vs 무선효과 모형
- 고정효과 모형 (Fixed effects model): 모든 연구의 진짜 효과크기가 똑같다고 가정합니다().
- 무선효과 모형 (Random effects model): 연구마다 진짜 효과크기가 다를 수 있다고 인정합니다. 여기서 (타우 제곱)이라는 값이 등장하는데, 이는 연구 간 무선 효과의 변산 정도를 나타내는 ‘연구 간 분산 성분’입니다.
4. 이질성(Heterogeneity): 연구마다 결과가 왜 다를까?
연구들끼리 결과가 얼마나 들쭉날쭉한지를 ‘이질성’이라고 합니다.
- 분산 성분 의 추정치는 연구 간 효과크기 이질성의 “양”을 나타내는 순수한 척도입니다.
- 이질성을 검증하기 위해 통계량을 사용하는데, 이는 이라는 가설을 검증하는 데 쓰입니다. 만약 값이 크면 연구들 사이에 차이가 크다는 뜻입니다.
- 사용자들이 를 직관적으로 이해하기 어려워, 추정 분산과 비교하여 그 크기를 특징짓는 지수가 널리 사용됩니다.
5. 메타 회귀분석(Meta-Regression): 다름의 원인 찾기
만약 연구들마다 효과가 다르게 나타난다면(), 그 이유를 찾아야 합니다. 메타분석 연구자들이 직면하는 근본적인 문제 중 하나는 연구의 특성과 효과크기 간의 연관성을 어떻게 모델링할 것인가입니다. 예를 들어, Raudenbush(1984)는 교사의 기대가 학생의 IQ에 미치는 영향을 다룬 19개의 연구를 리뷰했습니다. 여기서 효과의 차이를 설명하기 위해 ‘교사와 학생의 사전 접촉 기간(주 단위)’이라는 공변량을 추가하여 2수준 모형을 만들었습니다.
- 모형: .
- 분석 결과, 교사가 학생과 사전 접촉이 없었을 때는 교사 기대 효과가 통계적으로 신뢰할 만하게 나타났지만, 사전 접촉 기간이 길어질수록 그 효과는 실질적으로 감소했습니다.
6. 현실의 복잡한 문제들: 데이터의 종속성과 출판 편향
- 위계적 종속성 모형 (Hierarchical Dependence Model): 때로는 여러 연구가 같은 연구실에서 나왔거나 같은 연구자에 의해 진행되어 효과크기들이 독립적이지 않을 수 있습니다. 메타분석에서는 이러한 현상을 위계적 종속성이라고 부르며, 이를 해결하기 위해 3수준 다층모형(3-level hierarchical model)을 고려하는 것이 자연스럽습니다.
- 출판 편향 (Publication Bias): 통계적으로나 임상적으로 유의미한 결과를 찾은 연구가 출판될 확률이 더 높다는 증거가 있습니다. 이렇게 되면 우리가 보는 결과가 실제보다 훨씬 부풀려져 보일 수 있으므로(심지어 실제 값의 200% 이상을 초과할 수도 있음), 주의 깊은 해석과 보정이 필요합니다.
7. 스토리텔링 모의 데이터 및 실습 (jamovi & R)
📖 연구 스토리: “선생님의 폭풍 칭찬은 학생의 수학 자신감을 올려줄까?”
우리는 지난 10년간 진행된 15개의 학교 현장 연구 데이터를 모았습니다. 어떤 학교(연구)에서는 칭찬의 효과가 엄청났고, 어떤 학교에서는 미미했습니다. 우리는 그 원인이 “교사의 칭찬 연수 이수 시간(Training_Hours)”에 있다고 생각하여 메타 회귀분석을 돌려보기로 했습니다.
💻 R 코드 (데이터 생성 및 분석)
jamovi의 메타분석 모듈인 MAJOR는 내부적으로 R의 metafor 패키지를 사용합니다. 아래 코드를 R에서 실행하면 모의 데이터를 생성하고 분석할 수 있습니다.
R
# 필요한 패키지 설치 및 로드
# install.packages("metafor")
library(metafor)
# 1. 모의 데이터 생성 (15개의 학교 연구)
set.seed(2026)
k <- 15 # 연구 수
Study_ID <- paste("School", 1:k)
Training_Hours <- sample(0:20, k, replace=TRUE) # 교사 연수 시간(공변량)
# 진짜 효과크기(theta) 생성: 연수 시간이 길수록 효과가 커지도록 설정
true_effect <- 0.2 + 0.05 * Training_Hours + rnorm(k, 0, 0.1)
# 실험군(칭찬)과 대조군(일반)의 표본크기 및 요약통계량 무작위 생성
N_T <- round(runif(k, 30, 100))
N_C <- round(runif(k, 30, 100))
Mean_T <- rnorm(k, mean = 50 + true_effect * 10, sd = 2)
Mean_C <- rnorm(k, mean = 50, sd = 2)
SD_T <- runif(k, 8, 12)
SD_C <- runif(k, 8, 12)
# 데이터프레임 만들기
dat <- data.frame(Study_ID, N_T, Mean_T, SD_T, N_C, Mean_C, SD_C, Training_Hours)
# 2. 효과크기(Standardized Mean Difference, Hedges' g) 계산
dat_es <- escalc(measure="SMD",
n1i=N_T, m1i=Mean_T, sd1i=SD_T,
n2i=N_C, m2i=Mean_C, sd2i=SD_C,
data=dat)
# 3. 무선효과 모형 메타분석 (Random Effects Model)
res_re <- rma(yi, vi, data=dat_es)
print(res_re)
# 4. 메타 회귀분석 (Meta-Regression): 연수 시간(Training_Hours) 투입
res_reg <- rma(yi, vi, mods = ~ Training_Hours, data=dat_es)
print(res_reg)
# 5. Forest Plot 시각화
forest(res_re, slab=dat_es$Study_ID, main="Forest Plot: Praise Effect on Math")
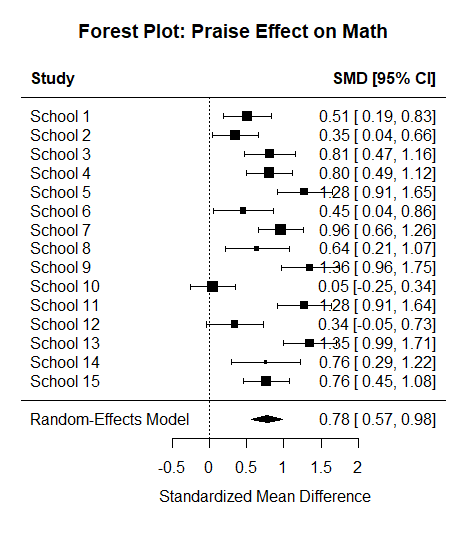
📊 jamovi에서 똑같이 분석하는 방법
- 모듈 설치: jamovi 우측 상단의
+ 모듈(Modules)탭을 클릭하고 MAJOR (Meta-Analysis for JAMOVI)를 설치합니다. - 데이터 입력: 위 R 코드에서 생성된 데이터(효과크기
yi와 분산vi혹은 평균/표준편차 원데이터)를 jamovi 스프레드시트에 불러옵니다. - 메석 실행:
MAJOR->Meta-Analysis클릭.Effect Size모델을 선택하고 (ex. Correlation, SMD 등), 데이터를 알맞은 칸에 넣습니다.- 메타 회귀분석을 원한다면,
Moderator(s)칸에Training_Hours를 넣습니다. - 옵션에서 Forest Plot을 체크하면 각 연구의 결과와 통합된 다이아몬드(평균 효과크기)를 시각적으로 확인할 수 있습니다.
결론 해석: jamovi(또는 R) 결과창에서 Training_Hours의 -값이 0.05보다 작게 나온다면, “선생님이 칭찬 연수를 많이 받을수록 학생 수학 자신감 향상 효과가 유의미하게 커진다”라고 결론 내릴 수 있습니다!
8. 참고문헌
- Birge, R. T. (1932). The Calculation of Errors by the Method of Least Squares. Physical Review, 40, 207-227.
- Borenstein, M. (2009). Effect Sizes for Continuous Data. In H. Cooper, L. V. Hedges, & J. C. Valentine (Eds.), The Handbook of Research Synthesis and Meta-analysis (2nd ed., pp. 221-236). Russell Sage Foundation.
- Cooper, H. M. (2010). Research Synthesis and Meta-analysis: A Step By Step Approach. Sage Publications.
- Glass, G. V. (1976). Primary, Secondary, and Meta-analysis of Research. Educational Researcher, 5, 3-8.
- Higgins, J. P. T., & Thompson, S. G. (2002). Quantifying Heterogeneity in a Meta-analysis. Statistics in Medicine, 21, 1539-1558.
- Raudenbush, S. W. (1984). Magnitude of Teacher Expectancy Effects on Pupil IQ as a Function of the Credibility of Expectancy Induction: A Synthesis Of Findings From 18 Experiments. Journal of Educational Psychology, 76, 85-97.
- Raudenbush, S. W., & Bryk, A. S. (2002). Hierarchical Linear Models: Applications and Data Analysis Methods. Sage.