안녕하세요!
오늘은 사회연결망 및 관계형 데이터의 다층모형(Multilevel Modeling of Social Network and Relational Data)에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 사회연결망 데이터란 무엇일까요?
초등학생 친구들이 교실에서 서로 친하게 지내는 모습을 상상해 볼까요? 어떤 친구는 많은 친구들에게 인기가 있고, 어떤 친구는 단짝 친구 한 명과 아주 깊은 관계를 맺습니다.
사회연결망 분석(Social Network Analysis)은 바로 이러한 사회적 연결망의 구조를 설명하고 시각화하며, 수학적 및 통계적으로 분석하여 이해하는 것을 목표로 합니다. 여기서 학생 한 명 한 명을 노드(node, vertex, actor)라고 부르고 , 학생들 사이의 관계(예: “나는 지훈이를 좋아해”)를 연결선(edge, link, tie)이라고 부릅니다.
- 방향성 유무: 연결선은 단순히 두 노드 사이의 연결만 기록하는 무방향(undirected)일 수도 있고, 누가 누구에게 관계를 보고했는지(송신자와 수신자) 알 수 있는 방향성(directed)을 가질 수도 있습니다.
- 인접 행렬(Adjacency matrix): 이러한 네트워크 데이터는 정방행렬인 로 표현할 수 있으며, 여기서 는 행위자 i로부터 행위자 j로 향하는 관계를 나타냅니다. 무방향 네트워크 데이터의 경우 이 행렬은 대칭을 이룹니다.
데이터를 수집하는 방식에 따라 크게 세 가지로 나눌 수 있습니다.
- 개인 중심 연결망(Personal or Egocentric Network): 표본으로 추출된 개인이 하나 이상의 타인(alter)과의 관계에 대해 보고하는 데이터입니다. (예: “지훈아, 네 친한 친구들을 다 적어볼래?”)
- 양자 데이터(Dyadic Data): 두 명의 행위자와 그들 사이의 관계인 양자(dyad), 즉 를 의미합니다.
- 전체 연결망(Complete or Whole-network): 닫힌 집단(예: 한 학급 전체) 내의 모든 개인들 사이의 관계를 라운드 로빈(round robin) 방식으로 수집한 데이터입니다.
2. 햇살 초등학교 5학년 1반의 모의 데이터 스토리
Lotte Vermeij(2006)가 수집한 실제 네덜란드 교실 소셜 네트워크 데이터를 바탕으로, 우리만의 모의 데이터를 상상해 봅시다.
- 목적: 학생들의 성별, 학업 성취도(marks), 학급 소속감(classroom identification)이 학생들 간의 관계(tie strength)에 어떤 영향을 미치는지 알아봅니다.
- 결과 변수: 친구를 얼마나 지지하고 소통하는지를 합산하여 만든 ‘관계 강도(tie strength)’ 변수를 사용합니다.
3. 단계별 다층모형 분석 (점점 복잡해지는 친구 관계 모델링)
단계 1: 개인 중심 연결망 데이터의 다층모형 (나와 내 친구들)
이 모델에서는 응답자인 ‘자아(ego)’ 안에 그들이 지목한 ‘타인(alter)’들이 내재(nested)되어 있다고 봅니다. 즉, 1수준은 ‘타인(친척, 친구 등)’, 2수준은 ‘자아(응답자 본인)’가 됩니다.
1수준(타인 수준)의 회귀 방정식은 다음과 같습니다.
- 여기서 는 무선 절편, 는 무선 기울기를 의미하며, 는 평균이 0이고 분산이 인 1수준 오차항입니다.
이를 2수준 방정식과 결합한 혼합 모형(Composite model)은 다음과 같습니다.
- 개인 중심 연결망 데이터에서 1수준 변수와 2수준 변수의 곱으로 이루어진 교차 수준 상호작용 항(cross-level interaction term)은 자아와 타인의 결합, 즉 양자간의 상호작용을 나타내므로 매우 중요합니다.
단계 2: 양자 데이터의 다층모형 (너와 나의 연결 고리)
만약 지훈이가 민수에게 느끼는 친밀감()뿐만 아니라, 민수가 지훈이에게 느끼는 친밀감()도 함께 본다면 어떨까요?. 두 개의 관계(tie)가 하나의 양자(dyad) 안에 내재되어 있다고 보는 것입니다.
- 이러한 접근법은 심리학에서 커플 등을 연구할 때 사용하는 행위자-파트너 상호의존 모형(Actor-Partner Interdependence Model, APIM)으로 잘 알려져 있습니다.
- 이 모형에서는 두 결과 간의 강한 상관관계인 급내 상관계수(intraclass correlation)를 ‘상호성(reciprocity)’으로 해석할 수 있습니다. (예: 내가 널 좋아하는 만큼, 너도 날 좋아하니?)
단계 3: 전체 연결망 데이터의 다층모형 (우리 반 전체의 인싸력과 인기도)
이제 학급 전체를 봅니다. 모든 학생이 모든 학생을 평가하는 상황이므로, 양자(dyads)들은 행위자(actors)들 내에 교차 내재(cross-nested)된 것으로 취급합니다.
- 이러한 교차 내재 구조를 다루기 위해 사회적 관계 모형(Social Relations Model, SRM)을 사용합니다.
- 이 모형은 행위자의 두 가지 역할(송신자와 수신자)을 모두 고려하기 위해 과 라는 무선 효과 벡터를 추가합니다.
- 여기서 무선 송신자 효과(sender effect)는 외향성(outgoingness, “내가 얼마나 다른 친구들에게 잘 다가가는가?”)을 의미합니다.
- 무선 수신자 효과(receiver effect)는 인기도(popularity, “다른 친구들이 나를 얼마나 좋아하는가?”)를 의미합니다.
단계 4: 이분형 사회연결망 데이터 (싫어해? 예/아니오)
항상 점수로만 관계를 측정하는 것은 아닙니다. “같이 있기 싫은 사람인가요?”처럼 결과 변수가 이분형(binary)일 때도 있습니다.
- 이 경우 일반화 선형 혼합 모형(GLMM)인 다층 로지스틱 모형을 사용할 수 있습니다.
- 양자 데이터의 상호성을 반영하기 위해 고정된 송신자/수신자 매개변수와 명시적인 상호성 매개변수를 사용하는 모형이나 , 이를 확장하여 정규 분포를 가정하는 상관된 무선 송신자/수신자 매개변수를 갖는 모형을 사용합니다.
4. R과 jamovi를 활용한 실습 가이드
사회연결망 다층분석 중 개인중심/양자 데이터 모형(APIM 형태)은 jamovi의 GAMLj 모듈(Mixed Model)을 통해 쉽게 구현할 수 있습니다. 데이터를 “Long format” (한 줄에 하나의 tie가 들어가도록)으로 구성하는 것이 핵심입니다. 하지만 SRM이나 교차 내재된 구조는 R의 lme4 또는 특화된 네트워크 패키지를 사용하는 것이 정확합니다.
여기서는 GAMLj의 기반이 되는 R 코드를 통해 데이터를 생성하고 분석하는 방법을 보여드리겠습니다. (이 코드는 jamovi의 Rj Editor에서도 바로 실행 가능합니다.)
R
# 1. 패키지 불러오기
library(lme4)
library(dplyr)
library(ggplot2)
# 2. 모의 데이터 생성 (햇살초 5학년 1반, 30명 기준)
set.seed(2026)
n_students <- 30
students <- data.frame(
id = 1:n_students,
gender = sample(c("Boy", "Girl"), n_students, replace = TRUE),
mark = rnorm(n_students, mean = 7, sd = 1), # 성적
class_id = rnorm(n_students, mean = 3.5, sd = 0.8) # 학급 소속감
)
# 가능한 모든 양자 조합 만들기 (자기 자신 제외)
network_data <- expand.grid(ego_id = students$id, alter_id = students$id) %>%
filter(ego_id != alter_id)
# 공변량 병합 (Ego와 Alter 특성)
network_data <- network_data %>%
left_join(students, by = c("ego_id" = "id")) %>%
rename(ego_gender = gender, ego_mark = mark, ego_classid = class_id) %>%
left_join(students, by = c("alter_id" = "id")) %>%
rename(alter_gender = gender, alter_mark = mark, alter_classid = class_id)
# 결과 변수 생성 (Tie strength): 동성끼리 친하고, 학급 소속감이 비슷할수록 친함
network_data <- network_data %>%
mutate(
same_gender = ifelse(ego_gender == alter_gender, 1, 0),
classid_diff = abs(ego_classid - alter_classid),
# 간단한 선형 결합 + 오차 + 송신자 무선효과 + 수신자 무선효과
ego_random = rep(rnorm(n_students, 0, 0.5), each = n_students - 1),
tie_strength = 2.0 + 1.2 * same_gender - 0.5 * classid_diff + ego_random + rnorm(n(), 0, 0.8)
)
# 3. 데이터 탐색적 시각화 (성별 동질성에 따른 관계 강도)
ggplot(network_data, aes(x = factor(same_gender, labels=c("Different", "Same")), y = tie_strength, fill=factor(same_gender))) +
geom_boxplot() +
labs(title = "Tie Strength by Gender Similarity", x = "Gender Similarity", y = "Tie Strength") +
theme_minimal()
# 4. 혼합 모형(다층 모형) 적합 (Egocentric base)
# jamovi의 GAMLj 모듈에서:
# - Dependent Variable: tie_strength
# - Factors: same_gender
# - Covariates: classid_diff
# - Random Effects: Intercept | ego_id
model_ego <- lmer(tie_strength ~ same_gender + classid_diff + (1 | ego_id), data = network_data)
summary(model_ego)
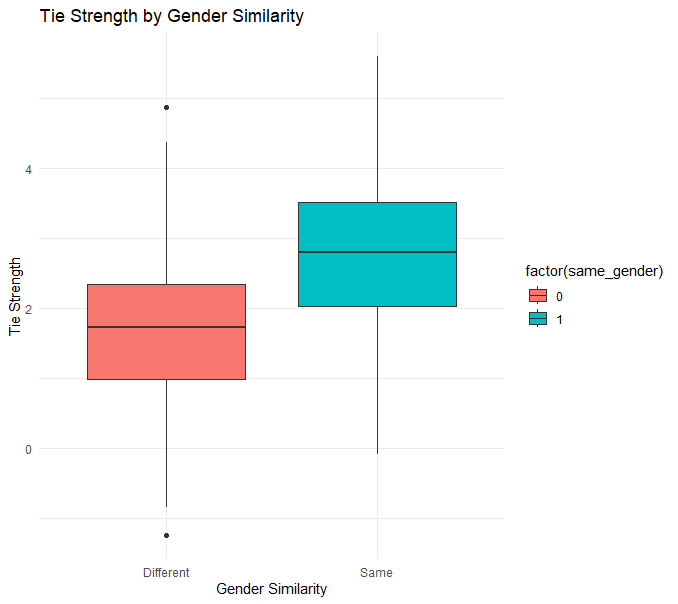
jamovi에서 분석하는 팁:
- 위에서 만든 데이터셋을
.csv로 저장하여 jamovi에서 엽니다. Modules->jamovi library에서GAMLj를 설치합니다.Linear Models->Mixed Model을 클릭합니다.tie_strength를 Dependent Variable에 넣고,ego_id를 Cluster Variables에 넣습니다.- Random Effects 탭에서
ego_id하위의 Intercept를 추가하면, 각 학생(ego)마다 기본적으로 타인에게 부여하는 점수(outgoingness)가 얼마나 다른지 그 분산을 확인할 수 있습니다!
5. 참고문헌 (APA Style)
- Cook, W. L., & Kenny, D. A. (2005). The Actor-Partner Interdependence Model: A model of bidirectional effects in developmental studies. International Journal of Behavioral Development, 29, 101-109.
- Holland, P. W., & Leinhardt, S. (1981). An exponential family of probability distributions for directed graphs. Journal of the American Statistical Association, 76, 33-50.
- Scott, J. (2000). Social network analysis: A handbook. London: Sage.
- Snijders, T. A. B., & Kenny, D. A. (1999). The social relations model for family data: A multilevel approach. Personal Relationships, 6, 471-486.
- Van Duijn, M. A. J., Snijders, T. A. B., & Zijlstra, B. J. H. (2004). : A random effects model with covariates for directed graphs. Statistica Neerlandica, 58, 234-254.
- Vermeij, L. (2006). What’s cooking? Cultural boundaries among Dutch teenagers of different ethnic origins in the context of school (Unpublished doctoral dissertation). ICS/University of Utrecht.