
안녕하십니까,
우리가 교육 현장에서 흔히 마주하는 범주형 데이터(Categorical Data)를 어떻게 과학적으로 측정하고 분석할 것인지에 대해 심도 있게 다뤄보겠습니다.
우리가 흔히 사용하는 ‘기초학력 진단평가(정답/오답)’나 ‘학교생활 만족도(리커트 척도)’는 일반적인 확인적 요인분석(CFA)이 가정하는 ‘연속성’과 ‘정규성’을 충족하지 못하는 경우가 많습니다. 이를 무시하고 분석할 경우, 결과가 왜곡될 수 있죠. 이 장에서는 이러한 한계를 극복하기 위한 이분형 및 서열형 문항에 대한 확인적 측정 모델을 살펴보겠습니다.
1. 전통적 확인적 요인분석(CFA)의 한계와 도전
전통적인 CFA 모델은 요인 지표가 연속적이며 기저 요인과 선형 관계를 맺고 있다고 가정합니다. 하지만 교육 현장의 데이터는 다음과 같은 특성을 보입니다.
- 이분형 지표: 수학 문제의 정답(1)과 오답(0)
- 서열형 지표: “전혀 그렇지 않다”에서 “매우 그렇다”까지의 리커트형 설문
이러한 데이터를 연속형으로 간주하고 최대우도법(ML)을 적용하면, 문항 간의 연관성이 저평가되거나 부적절한 표준오차가 산출될 위험이 있습니다. 특히 응답 범주가 5개 미만인 경우 이러한 문제는 더욱 심각해집니다.
2. 가상의 시나리오: “김 교사의 수학 학습 태도 및 성취도 연구”
이론적 이해를 돕기 위해, 고등학교 수학교사인 ‘김 교사’의 데이터를 가정해 봅시다.
시나리오: 김 교사는 학생들의 ‘수학적 자신감(정의적 영역)’과 ‘기초 대수 능력(인지적 영역)’을 측정하고자 합니다.
- 기초 대수 능력 (MATH_SKILL): 5개의 이분항 문항 (정답 1, 오답 0).
- 수학적 자신감 (MATH_CONF): 5개의 리커트 4점 척도 문항 (1=전혀 그렇지 않다 ~ 4=매우 그렇다).
3. 범주형 지표를 위한 두 가지 틀 (Frameworks)
범주형 지표를 모델링하는 데는 두 가지 주요 접근 방식이 있습니다.
3.1 잠재 응답 공식화 (Latent Response Formulation)
이 방식은 관찰된 범주형 변수 이면에는 정규분포를 따르는 연속적인 잠재 변수 가 존재한다고 가정합니다.
여기서가 특정 임계치(Threshold, )를 넘을 때 응답 범주가 바뀐다고 봅니다. 이 방식은 주로 범주형 CFA(CCFA)에서 사용됩니다.
3.2 일반화 선형 혼합 모델 (GLMM)
문항 반응 이론(IRT)에서 주로 사용하는 방식으로, 비선형 관계를 직접 모델링합니다. 예를 들어, 이분형 데이터에서는 로짓(Logit) 혹은 프로빗(Probit) 링크 함수를 사용하여 성공 확률을 예측합니다.
4. 추정 방법: 제한 정보 vs. 전체 정보
어떤 추정치를 사용할지는 분석의 정확도와 복잡도에 큰 영향을 미칩니다.
| 구분 | 제한 정보 추정 (Limited-Information) | 전체 정보 추정 (Full-Information) |
| 대표 추정치 | WLSMV (Weighted Least Squares Mean and Variance adjusted) | MML (Marginal Maximum Likelihood) / FIML |
| 입력 데이터 | 요약 통계량 (Polychoric correlation matrix 등) | 원시 응답 데이터 |
| 장점 | 표본 크기가 클 때 빠르고 적합도 지수(CFI, RMSEA) 제공 | 더 정밀한 파라미터 추정 가능, 결측치 처리(MAR)에 강함 |
| 단점 | 결측치 처리에 취약(MCAR 가정) | 잠재 요인이 많아질수록 계산 복잡도 급증 |
5. 이분형 문항 모델 (Dichotomous Indicators)
수학 문제 정답 여부를 분석할 때 사용되는 모델들입니다.
5.1 1모수 모델 (1PL / Rasch)
모든 문항의 변별도()가 동일하다고 가정하고 난이도()만 추정합니다.
5.2 2모수 모델 (2PL)
문항마다 변별도()와 난이도()를 모두 다르게 추정합니다. 김 교사의 데이터에서 특정 수학 문제가 우등생과 열등생을 더 잘 구분한다면 이 모델이 적합합니다.
5.3 3모수 및 4모수 모델 (3PL, 4PL)
- 3PL: ‘추측 파라미터()’를 추가하여, 능력이 낮아도 맞출 확률을 고려합니다.
- 4PL: ‘실수 파라미터()’를 추가하여, 능력이 높아도 틀릴 확률(상한 점근선)을 모델링합니다.
6. 서열형(리커트) 문항 모델 (Ordinal Indicators)
‘수학 자신감’ 설문과 같은 데이터에 적합한 모델입니다.
6.1 등급 반응 모델 (Graded Response Model, GRM)
응답 범주가 순서대로 나열되어 있을 때, “k 범주 이상에 응답할 확률”을 모델링합니다.
여기서 는 범주 간의 경계 지점을 의미합니다.
6.2 일반화 부분 점수 모델 (Generalized Partial Credit Model, GPCM)
각 범주 간의 전이(transition)를 일련의 2PL 모델처럼 다룹니다. 문항마다 부분 점수의 부여 방식이 다를 때 유용합니다.
7. jamovi 및 R을 활용한 실무 가이드
jamovi에서의 분석 (기본)
- IRT 모듈 설치: ‘Library’에서 ‘snowIRT’ 모듈을 설치합니다.
- 분석 수행:
- 이분형: ‘IRT’ -> ‘Dichotomous’ -> 문항 선택.
- 서열형: ‘IRT’ -> ‘Polytomous’ -> ‘Rating Scale Model’ 또는 ‘Partial Credit Model’ 선택.
- 결과 확인: 난이도, 문항 특성 곡선(ICC)을 확인합니다.
R을 활용한 정밀 분석 (mirt 패키지 활용)
jamovi에서 제공하지 않는 세부 모델(4PL 등)이나 복잡한 CCFA는 R의 mirt 또는 lavaan 패키지를 사용합니다.
R
# 1. 필요한 패키지 로드
if(!require(mirt)) install.packages("mirt")
library(mirt)
# 2. 가상 데이터 생성 (N=500)
set.seed(123)
N <- 500
theta <- rnorm(N) # 잠재 능력 (평균 0, 표준편차 1) [cite: 154, 176]
# 기초 대수 능력 (이분형: 2PL 모델 기반 생성)
# a: 변별도, b: 난이도
a_skill <- c(1.5, 2.0, 1.2, 1.8, 2.5)
b_skill <- c(-1.0, -0.5, 0, 0.5, 1.0)
data_skill <- matrix(NA, N, 5)
for(i in 1:5) {
prob <- 1 / (1 + exp(-a_skill[i] * (theta - b_skill[i])))
data_skill[,i] <- rbinom(N, 1, prob)
}
colnames(data_skill) <- paste0("SKILL_", 1:5)
# 수학적 자신감 (서열형: GRM 모델 기반 생성)
# data_conf 객체 생성
data_conf <- simdata(a = rep(1.5, 5), d = matrix(c(2, 0, -2), 5, 3, byrow=TRUE),
N = N, itemtype = 'graded', Theta = as.matrix(theta))
colnames(data_conf) <- paste0("CONF_", 1:5)
# 3. 분석 수행 (2PL 및 GRM)
# 이분형 분석
fit_skill <- mirt(as.data.frame(data_skill), 1, itemtype = '2PL')
coef(fit_skill, IRTpars = TRUE, simplify = TRUE)
# 서열형 분석 (GRM)
fit_conf <- mirt(as.data.frame(data_conf), 1, itemtype = 'graded')
plot(fit_conf, type = 'trace') # 카테고리 반응 곡선 (CRC) 확인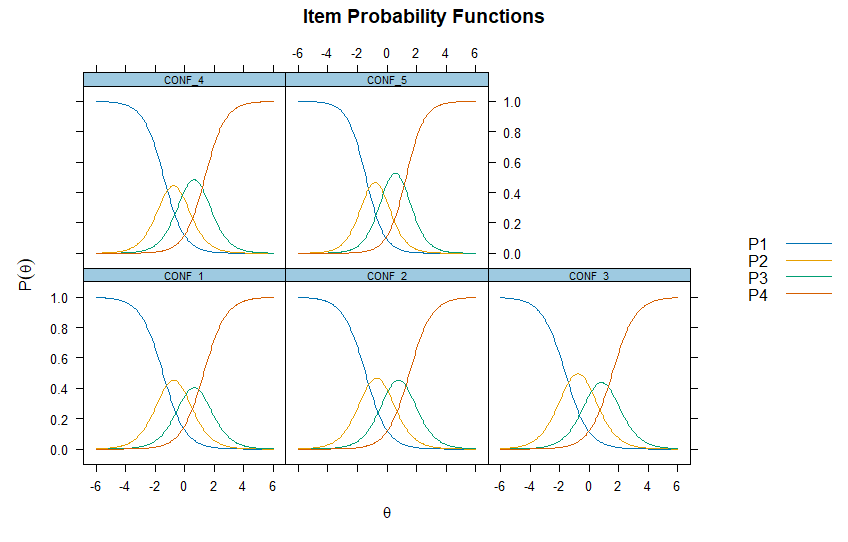
8. 결론 및 제언
범주형 지표를 활용한 측정 모델링은 단순히 통계 기법의 선택을 넘어, 우리가 측정하고자 하는 교육적 구인(Construct)의 본질을 얼마나 정확하게 반영하느냐의 문제입니다.
- 연속성 가정이 깨진다면: 지체 없이 범주형 CFA나 IRT 모델을 고려하십시오.
- 적합도 확인: WLSMV를 통해 CFI, TLI, RMSEA 등 익숙한 지표를 확인할 수 있지만, 범주형 데이터에서의 컷오프 기준은 주의해서 해석해야 합니다.
참고문헌
- Asparouhov, T., & Muthén, B. (2020). IRT in Mplus (Version 4). Mplus webnote. https://www.statmodel.com/download/mplusirt.pdf
- Brown, T. A. (2006). Confirmatory factor analysis for applied research. Guilford Press.
- de Ayala, R. J. (2009). The theory and practice of item response theory. Guilford Press.
- Embretson, S. E., & Reise, S. P. (2000). Item response theory for psychologists. Erlbaum.
- Koziol, N. A. (2025). Confirmatory measurement models for dichotomous and ordered polytomous indicators. In Handbook of Structural Equation Modeling (Chapter 15).
- Muthén, L. K., & Muthén, B. O. (1998-2020). Mplus user’s guide (8th ed.). Authors.
- Skrondal, A., & Rabe-Hesketh, S. (2004). Generalized latent variable modeling: Multilevel, longitudinal, and structural equation models. CRC Press.