안녕하세요!
이번에는 “구조방정식(SEM)과 잠재 변수 모델링을 활용한 심리측정 척도 평가”에 관한 내용을 여러분이 이해하기 쉽게 교육 현장의 사례를 곁들여 살펴보겠습니다.
이 내용은 척도를 개발하거나 평가하려는 연구자들에게 필수적인 기초부터 고급 기법(잠재 혼합 모델 등)까지를 다룹니다.
1. 왜 척도 평가가 중요한가?
교육 및 사회과학 연구에서 우리가 측정하려는 대상(예: 학습 동기, 수학 불안, 지능)은 눈에 직접 보이지 않는 잠재 변수(Latent Variables)인 경우가 많습니다. 이러한 잠재 변수는 직접 잴 수 없기 때문에, 우리는 여러 개의 설문 문항이나 과제(지표, Indicators)를 통해 간접적으로 그 수준을 추론합니다.
이때 핵심은 “우리가 사용한 문항들이 정말로 그 잠재 특성을 잘 반영하고 있는가?”를 평가하는 것입니다. 이를 위해 구조방정식 모델링(SEM)과 잠재 변수 모델링(LVM)이 활용됩니다.
2. 고전검사이론(CTT)과 요인분석(FA): 기초 다지기
척도 평가의 가장 기본이 되는 수식은 고전검사이론의 관찰점수 분해입니다.
(1) 기본 방정식
- : 학생이 설문지에서 얻은 실제 점수(관찰점수)
- : 학생의 진정한 능력이나 특성(진점수, 잠재 변수)
- : 측정 과정에서 발생하는 오차(측정 오차)
(2) 동질적 검사 모델 (Congeneric Model)
단일 요인 모델과 실질적으로 동일하게 취급되는 이 모델은 각 문항이 하나의 공통 요인에 서로 다른 가중치(부하량)로 연결되어 있다고 가정합니다. 교육 현장에서는 한 시험의 여러 문항이 하나의 수학적 사고력을 측정한다고 볼 때 이 모델을 적용합니다.
3. 척도의 잠재 구조 확인: EFA에서 CFA로
척도가 의도한 대로 구성되어 있는지 확인하기 위해 두 단계의 과정을 거칩니다.
1단계: 탐색적 요인분석 (EFA)
- 목적: 문항들이 몇 개의 요인으로 묶이는지 가설을 생성합니다.
- 절차: 전체 데이터의 일부(예: 1/2)를 사용하여 요인의 수()를 변화시켜가며 최적의 구조를 찾습니다.
2단계: 확인적 요인분석 (CFA)
- 목적: EFA에서 세운 가설이 새로운 데이터에서도 맞는지 검증합니다.
- 절차: 나머지 데이터(Hold-out sample)를 사용하여 모델의 적합도(AIC, BIC 등)를 평가합니다.
[WaurimaL의 팁] 군집 효과(Clustering Effects)를 주의하세요!
학교 교육 연구에서는 학생들이 ‘학급’이나 ‘학교’에 속해 있습니다. 같은 반 학생들은 경험을 공유하므로 독립성 가정이 위배될 수 있습니다. 이를 무시하면 오차가 과소 추정되어 잘못된 결론을 내릴 수 있으므로 다층 모델링(Multilevel Modeling) 접근이 필요합니다.
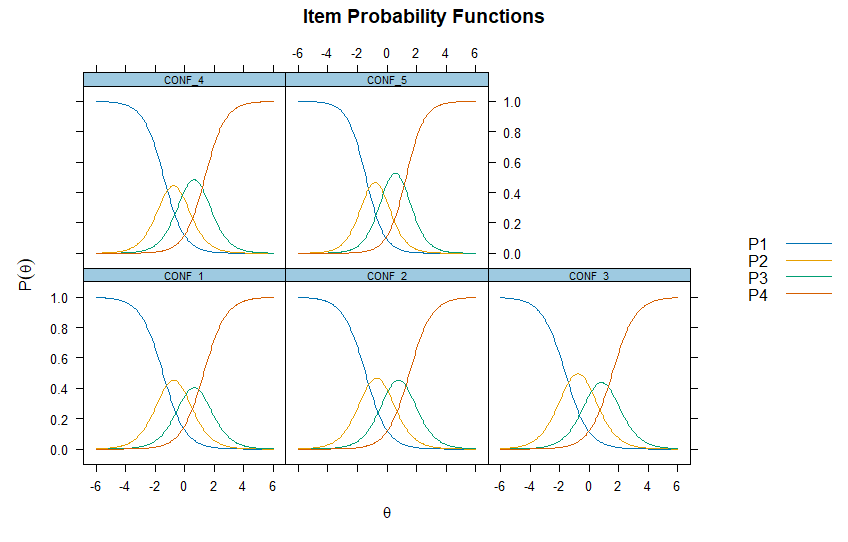
4. 문항 반응 이론(IRT): 문항 하나하나를 현미경으로 보기
척도 전체의 신뢰도를 넘어, 개별 문항이 얼마나 어려운지, 얼마나 변별력이 있는지를 평가할 때 IRT를 사용합니다.
- 변별도(): 능력이 높은 학생과 낮은 학생을 얼마나 잘 구분하는가?
- 난이도(): 정답을 맞힐 확률(또는 긍정 응답 확률)이 50%가 되는 지점은 어디인가?
5. 고급 주제: 관찰되지 않은 이질성(Unobserved Heterogeneity)
최근 연구에서 가장 강조되는 부분입니다. 전체 집단이 하나라고 가정하고 분석하면 심각한 오류에 빠질 수 있습니다.
(1) 잠재 혼합 모델 (Latent Mixture Modeling)
우리 눈에는 보이지 않지만, 모집단 안에 성격이 다른 여러 잠재 계층(Latent Classes)이 존재할 수 있습니다. 예를 들어, ‘수학 효능감’ 척도를 분석할 때 ‘일반 학생 집단’과 ‘수포자 집단’은 문항에 반응하는 방식 자체가 다를 수 있습니다.
(2) 혼합 모델을 무시할 때의 위험성
- 허위적 Bifactor 구조: 실제로는 집단이 두 개인데 하나로 합쳐 분석하면, 존재하지 않는 요인이 있는 것처럼 보일 수 있습니다.
- 잘못된 문항 교정: 집단별로 문항의 난이도가 다른데 이를 평균 내버리면, 어느 집단에도 맞지 않는 잘못된 문항 특성치가 산출됩니다.
6. 실습: 학교 소속감 척도 평가 (가상 데이터 사례)
전문가로서 ‘학교 소속감(School Belongingness)’을 측정하는 5개 문항을 예로 들어 보겠습니다.
[스토리 설정]
행복중학교 교사들은 학생들의 학교 소속감을 측정하기 위해 5개 문항(5점 리커트 척도)을 개발했습니다.
- 나는 학교에 오는 것이 즐겁다.
- 우리 학교 선생님들은 나를 존중해 주신다.
- 나는 우리 학교의 일원이라는 것이 자랑스럽다.
- 학교에서 친구들과 함께 있을 때 편안하다.
- 우리 학교는 나에게 중요한 장소다.
조사 결과, 전체 학생은 약 500명이며, 내부적으로는 ‘교우관계 중심 집단’과 ‘학업 중심 집단’이라는 두 개의 잠재 계층이 존재한다고 가정합니다.
jamovi 및 R 구현 방법
1) jamovi 활용 (CFA 분석)
- Factor 탭 -> Confirmatory Factor Analysis 선택.
- 문항 1~5를 ‘Factor 1’에 투입.
- Model Fit에서 RMSEA, CFI, TLI 확인.
- Reliability Analysis에서 Cronbach’s 와 McDonald’s 확인.
2) R 활용 (잠재 혼합 모델링 – tidyLPA 패키지 예시)
잠재 계층이 존재하는지 확인하기 위해 R 코드를 작성해 보겠습니다.
R
# 필요한 패키지 로드
library(tidyLPA)
library(dplyr)
# 가상 데이터 생성 (전문가적 식견을 바탕으로 한 모의 데이터)
set.seed(123)
# 집단 1: 소속감이 높은 집단 (250명)
group1 <- matrix(rnorm(250 * 5, mean = 4.2, sd = 0.5), ncol = 5)
# 집단 2: 소속감이 낮은 집단 (250명)
group2 <- matrix(rnorm(250 * 5, mean = 2.5, sd = 0.8), ncol = 5)
df <- as.data.frame(rbind(group1, group2))
colnames(df) <- paste0("item", 1:5)
# 잠재 프로파일 분석(LPA) 수행 - 집단 수 결정 (1개 vs 2개)
results <- df %>%
estimate_profiles(1:3) # 1개부터 3개 집단까지 비교
# 결과 비교 (BIC가 가장 낮은 모델 선택)
get_fit(results)
7. 결론 및 제언
척도 평가를 단순히 신뢰도 계수() 하나 확인하는 것으로 끝내서는 안 됩니다.
- 구조 확인: EFA/CFA를 통해 잠재 구조를 탄탄히 검증하십시오.
- 집단 특성 고려: 데이터 뒤에 숨겨진 이질적인 집단(잠재 계층)이 있는지 혼합 모델링으로 확인하십시오.
- 표본 크기: 복잡한 잠재 변수 모델을 사용할 때는 충분한 표본 크기가 확보되어야 결과가 안정적입니다.
참고문헌
- Raykov, T. (2025). Psychometric scale evaluation using structural equation modeling and latent variable modeling. In R. Hoyle (Ed.), Handbook of structural equation modeling (2nd ed., pp. 462-480). Guilford Press.
- Bollen, K. A. (1989). Structural equations with latent variables. Wiley.
- Crocker, L., & Algina, J. (2006). Introduction to classical and modern test theory. Harcourt College Publishers.
- Muthén, L. K., & Muthén, B. (2021). Mplus user’s guide. Authors.
- Raykov, T., & Marcoulides, G. A. (2011). Introduction to psychometric theory. Taylor & Francis.
- Reckase, M. (2009). Multidimensional item response theory. Springer.