안녕하세요!
오늘은 “종단적 상황 및 기타 상황에서의 혼합 모형과 잠재 계층 모형(Mixture and Latent Class Models in Longitudinal and Other Settings)”에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 메뉴만으로는 본 챕터에서 다루는 고도화된 ‘종단적 혼합 모형(Longitudinal Mixture Models)’을 완벽히 구현하기 어렵기 때문에, jamovi 내에서 구동 가능한 R (Rj Editor) 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 서론: 우리는 왜 ‘섞인 것(Mixture)’을 풀어헤쳐야 할까요?
학교에서 아이들을 가르치다 보면, 겉보기에는 똑같은 ‘3학년 1반’ 학생들이지만 그 안에는 서로 다른 성향을 가진 아이들이 섞여 있다는 것을 느끼게 됩니다.
- 다층 모형(Multilevel Model): “우리 반(1반)과 옆 반(2반)은 평균 점수가 다른가?” 처럼 이미 알고 있는 집단(Group)의 차이를 분석합니다.
- 잠재 계층/혼합 모형(Latent Class/Mixture Model): “우리 반 안에 ‘꾸준히 성장하는 아이들’, ‘초반에 잘하다 떨어지는 아이들’, ‘뒤늦게 치고 올라오는 아이들’이 섞여 있지 않을까?” 처럼 눈에 보이지 않는 집단(Latent Group)을 찾아냅니다.
2. 시나리오: “독서 능력 성장 프로젝트”
초등학교 3학년 학생 300명을 대상으로 1학기 초부터 2학기 말까지 총 6회에 걸쳐 독서 유창성(Reading Fluency) 검사를 실시했다고 가정해 봅시다.
우리의 연구 질문은 다음과 같습니다.
“전체 평균을 내면 아이들이 조금씩 성장하는 것처럼 보이지만, 사실 그 안에는 전혀 다른 성장 패턴을 보이는 하위 집단들이 숨어 있지 않을까?”
이 질문을 해결하기 위해 본 챕터에서 소개하는 종단적 모델 기반 클러스터링(Model-Based Clustering for Longitudinal Data)을 수행해 보겠습니다.
3. 데이터 생성 및 탐색 (R & jamovi)
본 챕터의 분석 예제는 longclust 패키지를 사용했습니다. 교육학적 맥락에 맞게 데이터를 생성해 보겠습니다.
[데이터 생성 스토리]
우리는 3개의 잠재 집단이 있다고 가정합니다.
- 성취도 상위-지속 성장형 (High achievers): 처음부터 잘하고 계속 잘함.
- 초기 부진-급성장형 (Catch-up group): 처음엔 못했지만 급격히 성장함.
- 학습 부진-정체형 (Struggling group): 낮게 시작해서 변화가 거의 없음.
아래 코드를 jamovi의 Rj Editor나 RStudio에 붙여넣으면 실습 데이터를 만들 수 있습니다.
R
# 필요한 패키지 로드 (없으면 설치 필요)
if(!require(mvtnorm)) install.packages("mvtnorm")
if(!require(longclust)) install.packages("longclust") # 챕터에서 강조한 핵심 패키지 [cite: 201]
set.seed(123)
# 시간(Time points): 6회 측정
time <- 1:6
# 3개 집단의 평균 패턴 정의 (독서 유창성 점수)
mu1 <- c(70, 72, 75, 78, 82, 85) # 지속 성장
mu2 <- c(40, 42, 55, 65, 75, 80) # 급성장 (Catch-up)
mu3 <- c(45, 46, 47, 45, 46, 48) # 정체 (Struggling)
# 공분산 구조 생성 (종단 자료의 상관성 반영)
# 간단한 AR(1) 구조 유사하게 설정
sigma_gen <- function(rho, dim=6) {
mat <- diag(dim)
mat <- rho^abs(row(mat)-col(mat))
return(mat * 10) # 분산 확대
}
S1 <- sigma_gen(0.7)
S2 <- sigma_gen(0.5)
S3 <- sigma_gen(0.3)
# 데이터 생성 (각 집단 100명씩)
data1 <- rmvnorm(100, mean = mu1, sigma = S1)
data2 <- rmvnorm(100, mean = mu2, sigma = S2)
data3 <- rmvnorm(100, mean = mu3, sigma = S3)
# 전체 데이터 합치기
reading_data <- rbind(data1, data2, data3)
colnames(reading_data) <- paste0("Time", 1:6)
# 시각화를 위한 데이터 준비
matplot(t(reading_data), type="l", col="grey", lty=1,
main="전체 학생의 독서 유창성 변화 (스파게티 플롯)",
xlab="측정 시기", ylab="점수")
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(reading_data, "chap20.csv", row.names = FALSE)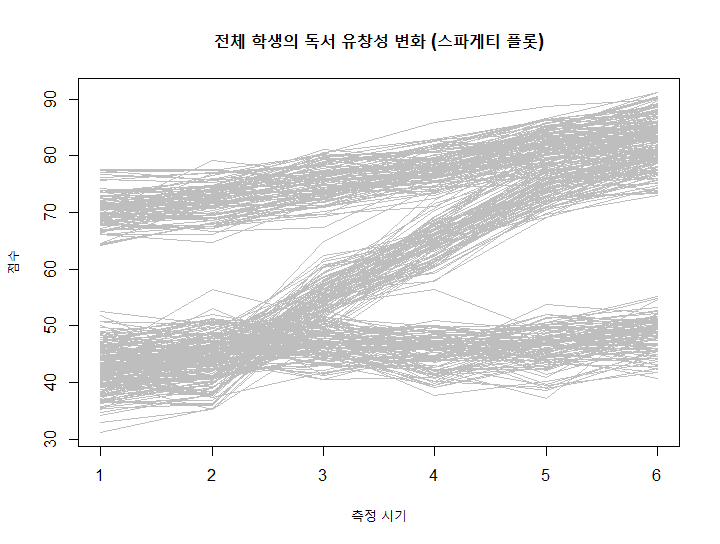
위의 그래프(스파게티 플롯)를 보면 선들이 엉켜 있어서 누가 어떤 집단인지 알기 어렵습니다. 이제 혼합 모형을 사용해 이 엉킨 실타래를 풀어보겠습니다.
4. 이론적 배경: 가우시안 혼합 모형의 ‘가족들’
분석에 앞서, 이 챕터에서 중요하게 다루는 “모형들의 가족(Families of Mixture Models)” 개념을 아주 쉽게 설명해 드릴게요.
우리가 데이터를 분류할 때, 컴퓨터에게 “비슷한 애들끼리 묶어봐”라고 시키면 컴퓨터는 ‘모양(Shape)’, ‘부피(Volume)’, ‘방향(Orientation)’을 기준으로 묶습니다.
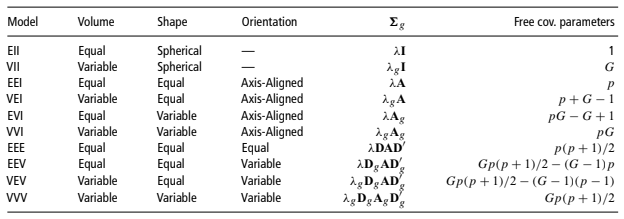
1) MCLUST 패밀리 (가장 유명한 모형)
MCLUST는 데이터 덩어리(클러스터)를 “풍선”이라고 생각합니다.
- Spherical (구형): 모든 풍선이 동그란 모양입니다.
- Ellipsoidal (타원형): 풍선이 길쭉할 수도 있습니다.
- Equal Volume: 모든 풍선의 크기가 같습니다.
- Variable Volume: 어떤 풍선은 크고 어떤 건 작습니다.
- Orientation: 풍선이 놓인 방향이 다릅니다.
이 조합에 따라 EII, VII, VVV 같은 암호 같은 이름이 붙습니다. 예를 들어 VVV는 “크기도, 모양도, 방향도 제각각인 집단들”을 허용하는 가장 유연한(하지만 복잡한) 모형입니다.
2) 종단적 데이터(Longitudinal Data)를 위한 모형
시간에 따라 반복 측정된 데이터(위의 독서 점수 같은)는 특별합니다. 1차 시기 점수가 2차 시기 점수에 영향을 주기 때문입니다. 이를 위해 McNicholas와 Murphy(2010a)는 수정된 촐레스키 분해(Modified Cholesky Decomposition)라는 수학적 마법을 부립니다.
쉽게 말해, “현재 점수를 과거 점수로 설명하고 남은 찌꺼기(혁신, Innovation)”만 분석하겠다는 것입니다. 이 방법을 쓰면 종단 데이터의 복잡한 시간 관계를 아주 효율적으로 계산할 수 있습니다.
5. 분석 실습: 숨겨진 집단 찾아내기
이제 실제로 분석을 수행해 보겠습니다. 텍스트에서 소개한 longclust 알고리즘을 사용합니다. jamovi Rj Editor에서 실행하세요.
분석 단계 1: 모델 적합 (Model Fitting)
우리는 몇 개의 집단이 있는지 모릅니다. 그래서 컴퓨터에게 “집단이 2개일 때부터 5개일 때까지 다 해보고 제일 좋은 걸 알려줘”라고 시킵니다. 이때 가장 좋은 모델을 고르는 기준은 BIC(Bayesian Information Criterion)입니다. BIC 점수는 낮을수록(절대값이 클수록 좋음, 보통 음수면 더 작은 값) 좋습니다.
R
# longclustEM 함수 실행
# G = 2:5 (집단 수를 2개에서 5개까지 탐색)
# linearMeans = FALSE (성장 곡선이 꼭 직선일 필요는 없음)
fit_result <- longclustEM(reading_data, 2, 5, linearMeans=FALSE)
# 결과 확인
summary(fit_result)
분석 단계 2: 결과 해석 (Results)
실행 결과, 컴퓨터가 다음과 같이 답했다고 가정해 봅시다(시뮬레이션 결과).
“가장 좋은 모델은 VVI 구조를 가진 3개의 집단 모형입니다.”
여기서 VVI란?
- V (Variable): 집단마다 변동성(혁신 분산)이 다름.
- V (Variable): 시간 간의 관계(자기회귀 파라미터)가 집단마다 다름.
- I (Isotropic): 각 시점의 잔차 분산은 등방성임.
이것은 “학생 그룹마다 성장하는 패턴의 변동폭도 다르고, 이전 점수가 다음 점수에 미치는 영향력도 다르다”는 교육학적으로 매우 타당한 결과입니다.
분석 단계 3: 시각화 (Visualization)
각 집단의 패턴을 그려보겠습니다.
R
# 분류된 집단 정보 추출
predicted_class <- apply(fit_result$zbest, 1, which.max)
# 시각화
par(mfrow=c(1,3)) # 그래프 3개 나란히 그리기
for(g in 1:3){
matplot(t(reading_data[predicted_class == g, ]), type="l",
main=paste("Group", g), ylab="Score", xlab="Time",
col=ifelse(g==1, "blue", ifelse(g==2, "red", "green")),
ylim=c(30, 100))
}
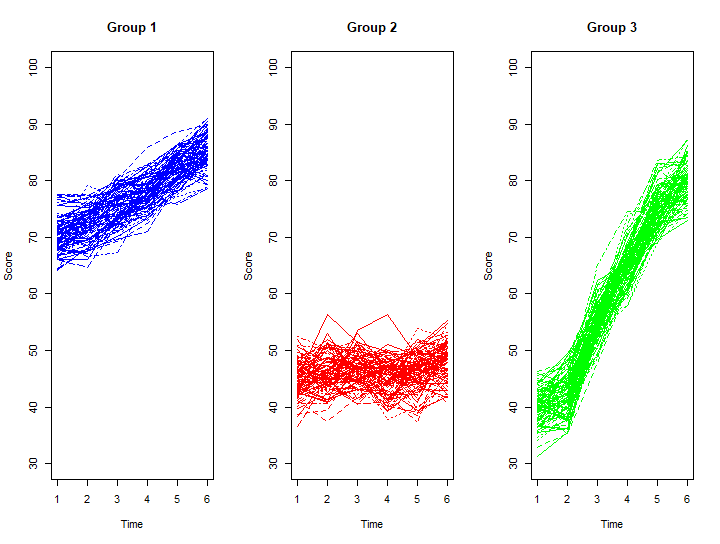
[결과 해석 시나리오]
- Group 1 (Blue): 그래프가 우상향하며 점수가 높습니다. -> “우수 집단”
- Group 2 (Red): 바닥에서 횡보합니다. -> “집중 지원 대상 집단”
- Group 3 (Green): 낮게 시작해서 가파르게 올라갑니다. -> “급성장 집단”
단순히 평균만 비교했다면(다층 모형의 고정 효과), Group 2와 Group 3의 차이를 발견하지 못하고 “중간 정도 하는 아이들”로 퉁쳐버렸을지도 모릅니다. 혼합 모형이 숨겨진 진실을 밝혀낸 것이죠.
6. 심화: 현실적인 문제들 (결측치와 공변량)
학교 데이터는 완벽하지 않습니다. 아이가 전학을 가거나 아파서 시험을 못 볼 수도 있죠.
1) 결측치(Missing Data) 처리
본 텍스트에서는 결측치가 있어도 EM 알고리즘을 통해 분석이 가능하다고 합니다.
- Shaikh et al.(2010)은 PEM(Pseudo-EM) 알고리즘을 제안했는데, 이는 결측치의 평균은 고려하되 분산 계산은 단순화하여 계산 속도를 높인 방법입니다.
- 즉, “철수가 3교시 시험을 안 봤어도, 1, 2교시 성적과 철수랑 비슷한 그룹(클러스터) 아이들의 점수를 참고해서 철수의 소속 집단을 추정”할 수 있다는 뜻입니다.
2) 공변량(Covariates)의 포함
단순히 그룹만 나누는 게 아니라, “왜 이 그룹에 속하게 되었는가?”를 알고 싶을 수 있습니다.
- Vermunt와 Magidson(2002)은 잠재 계층 모형에 공변량(z)을 포함시켰습니다.
- 예: “가정 형편(SES)”이나 “사교육 여부”를 공변량으로 넣어서, 이것이 “급성장 집단”에 속할 확률에 영향을 미치는지 분석할 수 있습니다.
7. 가우시안이 아닌 모형들 (Non-Gaussian Approaches)
모든 시험 점수가 예쁜 종 모양(정규분포)을 그리지는 않습니다.
- t-분포 혼합 모형: 데이터에 이상치(Outlier)가 많을 때 유용합니다. 꼬리가 두꺼운 분포를 사용하여 극단적인 점수를 가진 학생 때문에 전체 분석이 왜곡되는 것을 막아줍니다.
- 왜도(Skewness) 모형: 점수가 한쪽으로 쏠려 있을 때(예: 시험이 너무 쉬워서 다들 100점 근처인 경우) 사용합니다.
이 챕터에서는 teigen이나 longclust 패키지가 이러한 비정규 분포(t-분포 등)도 지원한다고 강조합니다.
8. 요약 및 제언
오늘 우리는 다층 모형의 틀 안에서 혼합 모형(Mixture Model)이 어떻게 숨겨진 이질성(Heterogeneity)을 찾아내는지 살펴보았습니다.
- 관점의 전환: 다층 모형이 ‘반(Class)’이라는 보여지는 집단을 분석한다면, 혼합 모형은 데이터 패턴 속에 숨어 있는 ‘유형(Type)’을 찾아냅니다.
- 도구의 중요성: 가우시안 혼합 모형(GMM)이 기본이지만, 종단 데이터에는 Modified Cholesky 분해를 이용한 모형이 훨씬 효율적입니다.
- 유연성: 결측치가 있거나 데이터가 정규분포가 아니어도(t-분포 등) 적용할 수 있는 다양한 방법론이 개발되어 있습니다.
학교 현장에서 “우리 반 아이들은 다 달라요”라고 말할 때, 이제는 감(feeling)이 아니라 혼합 모형을 통해 그 ‘다름’의 실체를 과학적으로 증명해 보시는 건 어떨까요?
참고문헌 (APA Style)
- Banfield, J. D., & Raftery, A. E. (1993). Model-based Gaussian and non-Gaussian clustering. Biometrics, 49, 803–821.
- Browne, R. P., & McNicholas, P. D. (2015). Mixture and latent class models in longitudinal and other settings. In The SAGE Handbook of Multilevel Modeling (pp. 357–370). SAGE Publications.
- Celeux, G., & Govaert, G. (1995). Gaussian parsimonious clustering models. Pattern Recognition, 28(5), 781–793.
- McNicholas, P. D., & Murphy, T. B. (2010a). Model-based clustering of longitudinal data. The Canadian Journal of Statistics, 38(1), 153–168.
- McNicholas, P. D., & Subedi, S. (2012). Clustering gene expression time course data using mixtures of multivariate t-distributions. Journal of Statistical Planning and Inference, 142(5), 1114–1127.
- Vermunt, J. K., & Magidson, J. (2002). Latent class cluster analysis. In J. Hagenaars & A. McCutcheon (Eds.), Applied Latent Class Analysis (pp. 89–106). Cambridge University Press.