
안녕하세요!
오늘은 일반화 선형 혼합 모형(Generalized Linear Mixed Models, GLMM)에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법(GAMLj 모듈 활용)을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 서론: 왜 ‘일반화’인가요?
우리가 지금까지 배운 ‘선형 혼합 모형(LMM)’은 데이터가 정규분포(Normal Distribution)를 따른다고 가정했습니다. 예를 들어, 학생들의 ‘키’, ‘국어 점수’, ‘지능 지수’ 같은 연속형 변수들이죠.
하지만 학교 현장의 데이터가 항상 예쁜 종 모양(정규분포)을 그릴까요? 다음의 예를 봅시다.
[상황 A] 선생님이 한 학기 동안 학생이 과제를 제출했는지(1), 안 했는지(0)를 매주 기록합니다. (이항 데이터, Binary)
[상황 B] 상담 선생님이 학급 내에서 발생하는 ‘따돌림 행동 횟수’를 관찰합니다. 0회, 1회, 2회… (카운트 데이터, Count)
이런 데이터는 정규분포를 따르지 않습니다.
- 상황 A는 이항분포(Binomial Distribution)를 따르며, 결과가 0 아니면 1로 딱 떨어집니다.
- 상황 B는 포아송분포(Poisson Distribution)를 따르며, 음수(-)가 나올 수 없고 오른쪽으로 긴 꼬리를 가질 확률이 높습니다.
이처럼 정규분포가 아닌 종속변수를 다루면서, 동시에 반복측정이나 학급 내 학생처럼 데이터가 위계적(Hierarchical)일 때 사용하는 분석 방법이 바로 일반화 선형 혼합 모형(GLMM)입니다.
2. 모형의 구조: 연결 고리 만들기 (Link Function)
일반적인 선형 회귀식은 형태입니다. 하지만 결과값 가 0과 1 사이의 확률(시험 통과 여부)이어야 하는데, 우변의 가 에서 까지 값을 가진다면 말이 안 되겠죠?
그래서 우리는 연결 함수(Link Function)라는 특수한 장치를 사용합니다.
(1) 로지스틱 혼합 모형 (Binary Data)
시험 통과 여부(Pass/Fail)와 같은 이항 데이터를 분석할 때는 로짓(Logit) 연결 함수를 씁니다.
여기서 는 학생 고유의 능력(Random Intercept)을 의미합니다.
(2) 포아송 혼합 모형 (Count Data)
행동 빈도와 같은 가산 데이터를 분석할 때는 로그(Log) 연결 함수를 씁니다.
여기서 는 해당 시점에서의 평균 발생 횟수입니다.
3. 실습 1: 이항 결과변수 (Binary Outcome) 분석
시나리오: “기초학력 평가 통과 여부 추적”
어느 교육청에서 방과 후 보충수업 프로그램이 학생들의 기초학력 평가 통과(Pass=1, Fail=0)에 미치는 영향을 알아보기 위해, 100명의 학생을 대상으로 4학기 동안 추적 조사를 했습니다.
- 집단: 실험군(보충수업 O), 대조군(보충수업 X)
- 종속변수: 평가 통과 여부 (0, 1)
[Step 1] R을 이용한 모의 데이터 생성
Jamovi의 Rj Editor나 R Studio에서 다음 코드를 실행하여 데이터를 생성합니다.
R
set.seed(1234)
n_subjects <- 100 # 학생 수
n_timepoints <- 4 # 4학기 측정
# 데이터 프레임 생성
data_binary <- data.frame(
student_id = rep(1:n_subjects, each = n_timepoints),
time = rep(0:3, n_subjects), # 0(기초선) ~ 3학기
group = rep(sample(c("Control", "Treatment"), n_subjects, replace = T), each = n_timepoints)
)
# 랜덤 효과 (학생 고유의 기초 학력 수준)
random_intercept <- rep(rnorm(n_subjects, mean = 0, sd = 1.5), each = n_timepoints)
# 고정 효과 설정
# Intercept: -1 (초기엔 통과 확률 낮음)
# Time: 0.2 (시간이 지날수록 조금씩 향상)
# GroupTreatment: 0.5 (실험군이 조금 더 높음)
# Time*Group: 0.4 (실험군의 향상 속도가 더 빠름)
logit_p <- -1 + 0.2 * data_binary$time +
0.5 * (data_binary$group == "Treatment") +
0.4 * data_binary$time * (data_binary$group == "Treatment") +
random_intercept
# 확률 계산 및 이항 데이터 생성
prob <- exp(logit_p) / (1 + exp(logit_p))
data_binary$pass <- rbinom(n = nrow(data_binary), size = 1, prob = prob)
head(data_binary)
[Step 2] Jamovi 분석 절차 (GAMLj 모듈)
Jamovi에서 GLMM을 분석하기 위해서는 GAMLj 모듈 설치가 필요합니다. (Jamovi Library -> GAMLj 추가)
- Analyses 탭 클릭 > GAMLj > Generalized Mixed Models 선택
- Dependent Variable:
pass(통과 여부) - Random Effect Grouping Factors:
student_id - Covariates:
time - Factors:
group - Model Definition:
- Distribution: Binomial
- Link Function: Logit
- Fixed Effects:
time,group,time * group(상호작용항) - Random Effects:
student_id(Intercept 체크)
[Step 3] 결과 해석 및 시각화
분석 결과, 상호작용항(time * group)이 유의하다면 보충수업 집단이 대조군보다 시간이 지날수록 통과 확률이 더 가파르게 증가한다고 해석할 수 있습니다.
이때 주의할 점은 계수()가 ‘확률’ 그 자체가 아니라 로그 오즈(Log Odds)의 변화량이라는 점입니다.
4. 실습 2: 가산 결과변수 (Count Outcome) 분석
시나리오: “수업 중 질문 횟수 변화”
토론식 수업(실험군)이 학생들의 자발적 질문 횟수를 늘리는지 확인하기 위해 10주간 데이터를 수집했습니다.
- 데이터 특성: 질문 횟수는 0 이상의 정수이며, 대부분 적은 횟수에 몰려 있음 (포아송 분포 가정).
[Step 1] R을 이용한 모의 데이터 생성
R
set.seed(5678)
# 데이터 프레임 생성 (구조는 위와 동일)
data_count <- data.frame(
student_id = rep(1:n_subjects, each = n_timepoints),
time = rep(0:3, n_subjects),
group = rep(sample(c("Lecture", "Discussion"), n_subjects, replace = T), each = n_timepoints)
)
# 랜덤 효과 (학생의 적극성)
random_intercept_c <- rep(rnorm(n_subjects, mean = 0, sd = 0.5), each = n_timepoints)
# 고정 효과 (로그 스케일)
# Discussion 그룹이 시간이 지날수록 질문이 급격히 늘어나도록 설정
log_lambda <- 0.5 + 0.1 * data_count$time +
0.2 * (data_count$group == "Discussion") +
0.3 * data_count$time * (data_count$group == "Discussion") +
random_intercept_c
# 포아송 데이터 생성
data_count$questions <- rpois(n = nrow(data_count), lambda = exp(log_lambda))
head(data_count)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data_count, "chap08_2.csv", row.names = FALSE)[Step 2] Jamovi 분석 절차
- GAMLj > Generalized Mixed Models
- Dependent Variable:
questions - Model Definition:
- Distribution: Poisson
- Link Function: Log
- 나머지 설정은 위와 동일.
5. 심화 분석: “개별 학생” vs “전체 평균”의 함정
GLMM에서 가장 중요한 개념이자 학생들이 가장 많이 헷갈리는 부분입니다.
“개별 학생들의 성장 곡선을 평균 낸 것”과 “전체 집단의 평균 성장 곡선”이 같을까요?
- 선형 혼합 모형(LMM): 같습니다. ()
- 일반화 선형 혼합 모형(GLMM): 다릅니다! ()
왜 다를까요?
비선형 함수(S자 곡선인 로지스틱 등)를 통과하기 때문입니다.
수식으로 보면 다음과 같은 관계가 성립합니다.
오히려, 주변(Marginal) 효과는 개별(Subject-specific) 효과보다 절댓값이 작게(완만하게) 나타납니다.
R로 시각화하여 이해하기
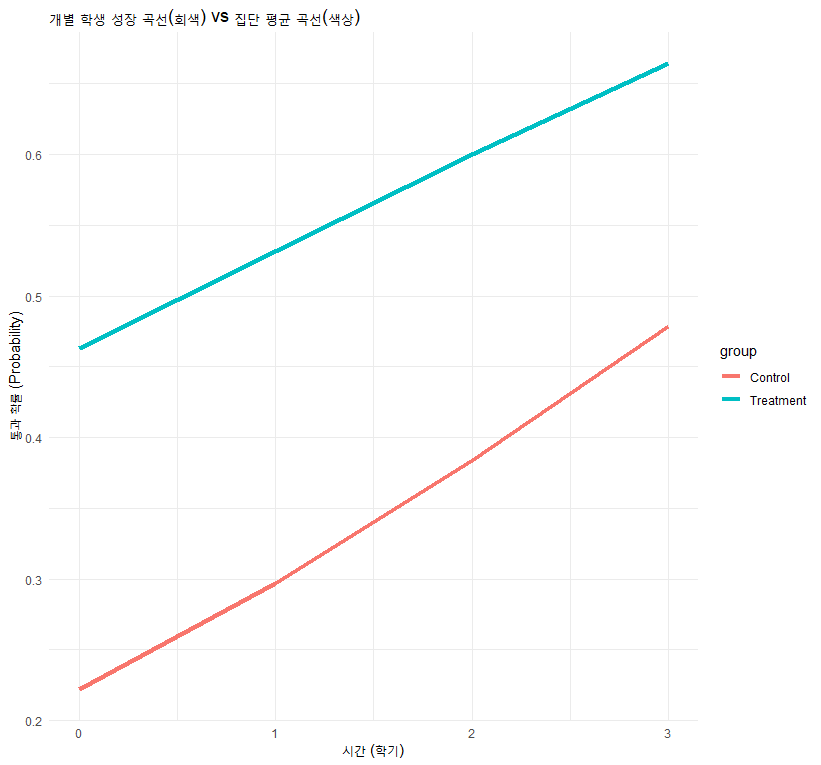
이 차이를 눈으로 확인해 봅시다. 개별 학생들의 곡선(회색)과 그 평균(빨간색, 파란색)을 그려보겠습니다.
R
# 시각화 코드
library(ggplot2)
# 예측값 생성 (개별 효과 포함)
# *주의: 실제 GLMM 예측은 복잡하지만, 여기서는 개념 설명을 위해 단순화하여 시각화합니다.
data_binary$pred_prob <- predict(glm(pass ~ time * group, data=data_binary, family=binomial), type="response")
# 그래프 그리기
ggplot(data_binary, aes(x = time, y = pred_prob, group = student_id)) +
# 개별 학생들의 성장 곡선 (회색, 얇게)
geom_line(alpha = 0.2, color = "gray") +
# 집단 평균 성장 곡선 (색상, 굵게)
# *변경사항: size = 1.5 -> linewidth = 1.5
stat_summary(aes(group = group, color = group), fun = mean, geom = "line", linewidth = 1.5) +
# 라벨 및 테마 설정
labs(title = "개별 학생 성장 곡선(회색) vs 집단 평균 곡선(색상)",
y = "통과 확률 (Probability)", x = "시간 (학기)") +
theme_minimal()
6. 결론
일반화 선형 혼합 모형(GLMM)은 현실 세계의 복잡한 데이터(O/X, 횟수 등)를 통계적으로 엄밀하게 다룰 수 있는 강력한 도구입니다.
- 데이터가 정규분포가 아닐 때(이항, 포아송 등) 사용합니다.
- 연결 함수(Link Function)를 통해 선형 예측식과 결과를 연결합니다.
- 개별 대상(Subject-specific)의 변화에 초점을 맞추므로, 전체 평균(Population-averaged) 해석 시 주의가 필요합니다.
학교 현장에서 “우리 반 아이들의 숙제 제출 여부”나 “문제 행동 횟수”를 종단적으로 연구하고 싶다면, GLMM이 가장 적합한 친구가 되어줄 것입니다.
참고문헌
- Breslow, N. E., & Clayton, D. G. (1993). Approximate inference in generalized linear mixed models. Journal of the American Statistical Association, 88(421), 9-25.
- Diggle, P. J., Heagerty, P., Liang, K. Y., & Zeger, S. L. (2002). Analysis of longitudinal data (2nd ed.). Oxford University Press.
- Faught, E., Wilder, B. J., Ramsay, R. E., Reife, R. A., Kramer, L. D., Pledger, G. W., & Karim, R. M. (1996). Topiramate placebo-controlled dose-ranging trial in refractory partial epilepsy using 200-, 400-, and 600-mg daily dosages. Neurology, 46(6), 1684-1690.
- Liang, K. Y., & Zeger, S. L. (1986). Longitudinal data analysis using generalized linear models. Biometrika, 73(1), 13-22.
- Molenberghs, G., & Verbeke, G. (2005). Models for discrete longitudinal data. Springer.
- Verbeke, G., & Molenberghs, G. (2000). Linear mixed models for longitudinal data. Springer.
- Verbeke, G., & Molenberghs, G. (n.d.). Generalized Linear Mixed Models – Overview. In The SAGE Handbook of Multilevel Modeling (Chapter 8).