
안녕하세요. 이번에는 통계학의 새로운 지평인 베이지안 구조방정식 모형(Bayesian Structural Equation Modeling, BSEM)의 세계로 들어가는 것을 돕고자 합니다. 2012년 초판 이후, 베이지안 추론은 사회과학 및 행동과학 분야에서 빈도주의(Frequentist) 방법론의 강력한 대안으로 자리 잡았습니다.
특히 이번 내용에서는 Hamiltonian Monte Carlo (HMC) 알고리즘과 Stan 같은 오픈 소스 소프트웨어의 발전에 힘입어 더욱 정교해진 BSEM의 기초와 확장에 대해 다룰 것입니다. 다소 복잡할 수 있는 내용이지만, 학교 현장의 예시를 통해 알기 쉽게 풀어보겠습니다.
분석 도구로는 우리가 수업 시간에 자주 다루는 jamovi를 기본으로 하되, 본문에서 강조하는 blavaan 패키지의 고급 기능을 구현하기 위해 jamovi 내의 Rj Editor (또는 R 환경)를 활용하는 코드를 함께 제시하겠습니다.
1. 왜 베이지안인가?
우리는 그동안 “p-value가 .05보다 작은가?”에 집착해 왔습니다. 하지만 빈도주의 통계는 “모수(parameter)는 고정되어 있고 데이터가 확률적”이라고 봅니다. 반면, 베이지안 통계는 “데이터는 고정되어 있고, 모수 자체가 확률 분포를 가진다”고 봅니다.
베이지안 접근의 핵심 장점은 다음과 같습니다.
- 불확실성의 정량화: 모수 추정치 주변의 구간(신용구간, Credible Interval)이 빈도주의의 신뢰구간보다 더 직관적이고 솔직합니다.
- 사전 정보의 활용: 이전 연구 결과나 전문가의 의견을 ‘사전 분포(Prior)’로 모형에 반영할 수 있습니다.
- 복잡한 모형 해결: 빈도주의 방식(최대우도법 등)으로 수렴하지 않는 복잡한 모형도 MCMC 샘플링을 통해 추정해 낼 수 있습니다.
2. 베이지안 추론의 핵심 요소
2.1 베이즈 정리 (Bayes’ Theorem)
베이지안 추론의 심장은 다음 식입니다.
- : 사후 분포(Posterior). 데이터를 관측한 후의 모수(지식).
- : 우도(Likelihood). 데이터가 관측될 확률(모형).
- : 사전 분포(Prior). 데이터를 보기 전의 믿음.
- : 정규화 상수.
즉, “사후 지식 = (데이터의 증거 × 사전 지식) / 상수” 입니다.
2.2 사전 분포(Prior)의 종류
교육학 예시로 설명해 봅시다. “영재 학급 학생들의 평균 IQ()”를 추정한다고 가정합니다.
- 무정보 사전 분포 (Noninformative Prior): “나는 아무것도 모른다.”
- 균등 분포(Uniform Distribution) 등을 사용합니다. 0에서 200 사이의 모든 값이 동등한 확률을 가집니다.
- 데이터가 스스로 말하게 내버려 두는 방식입니다.
- 약한 정보 사전 분포 (Weakly Informative Prior): “정확히는 모르지만, 터무니없는 값은 아닐 것이다.”
- 완전한 무정보보다는 낫고, 특정 이론에 너무 치우치지 않도록 합니다. 표본 크기가 작을 때 유용합니다.
- 정보적 사전 분포 (Informative Prior): “기존 연구에 따르면 평균 130 정도일 것이다.”
- 정규분포 처럼 구체적인 평균과 분산을 지정합니다.
3. MCMC 샘플링과 HMC
베이지안 추정은 복잡한 적분 계산이 필요합니다. 이를 해결하기 위해 MCMC(Markov Chain Monte Carlo) 시뮬레이션을 사용합니다.
3.1 기존 방법: MH와 Gibbs
과거에는 Metropolis-Hastings (MH)나 Gibbs 샘플러를 썼습니다. 하지만 모형이 복잡해지면(차원이 높아지면) 이 알고리즘들은 “랜덤 워크(Random Walk)” 방식이라 효율이 떨어지고 시간이 오래 걸립니다.
3.2 현대적 방법: Hamiltonian Monte Carlo (HMC)와 NUTS
이 챕터에서 강조하는 것은 HMC입니다.
- 비유: MH가 눈 가리고 산을 더듬어 내려가는 등산객이라면, HMC는 물리학의 원리를 이용해 썰매를 타고 등고선(전형적 집합, Typical Set)을 미끄러지듯 이동하는 것과 같습니다.
- NUTS (No-U-Turn Sampler): HMC는 설정해야 할 파라미터가 많은데, NUTS는 이를 자동으로 조정하여 사용자가 쓰기 쉽게 만든 알고리즘입니다.
Stan과blavaan이 이 방식을 씁니다.
4. 실습: BSEM 분석 시나리오 및 데이터 생성
이제 실제 교육 데이터를 가정하여 분석해 봅시다.
4.1 시나리오: 교사의 자율성 지지가 학생의 학업 성취에 미치는 영향
- 연구 문제: 과학 교사의 자율성 지지(Support)가 학생의 과학 흥미(Interest)를 매개로 학업 성취(Achievement)에 영향을 미치는가?
- 분석 도구: R (jamovi Rj Editor 활용 가능) 및
blavaan패키지.
4.2 데이터 생성 (R Code)
먼저 모의 데이터를 생성하겠습니다.
R
# 필요한 패키지 로드 (jamovi Rj Editor에서 실행 시 install.packages는 생략 가능할 수 있음)
if (!require("lavaan")) install.packages("lavaan")
if (!require("blavaan")) install.packages("blavaan")
if (!require("semTools")) install.packages("semTools")
set.seed(2026)
# 표본 크기
n <- 300
# 잠재변수 생성
# Support (교사 지지), Interest (흥미), Achieve (성취)
# 구조: Support -> Interest -> Achieve
Support <- rnorm(n, 0, 1)
Interest <- 0.6 * Support + rnorm(n, 0, 0.8) # 매개변수 (경로계수 0.6)
Achieve <- 0.5 * Interest + 0.3 * Support + rnorm(n, 0, 0.8) # 종속변수
# 관측변수 생성 (측정모형)
# 각 잠재변수당 3개의 문항
y_data <- data.frame(
S1 = 1.0*Support + rnorm(n, 0, 0.5),
S2 = 0.9*Support + rnorm(n, 0, 0.5),
S3 = 1.1*Support + rnorm(n, 0, 0.5),
I1 = 1.0*Interest + rnorm(n, 0, 0.5),
I2 = 0.8*Interest + rnorm(n, 0, 0.5),
I3 = 1.2*Interest + rnorm(n, 0, 0.5),
A1 = 1.0*Achieve + rnorm(n, 0, 0.5),
A2 = 0.9*Achieve + rnorm(n, 0, 0.5),
A3 = 1.0*Achieve + rnorm(n, 0, 0.5)
)
head(y_data)
4.3 BSEM 모형 명세 및 추정 (blavaan)
blavaan은 R의 lavaan 문법을 그대로 쓰면서 베이지안 추정을 수행합니다.
R
# 모형 명세 (lavaan 문법)
model_syntax <- '
# 측정 모형
Support =~ S1 + S2 + S3
Interest =~ I1 + I2 + I3
Achieve =~ A1 + A2 + A3
# 구조 모형
Interest ~ a*Support
Achieve ~ b*Interest + c*Support
# 간접 효과
ab := a*b
'
# 베이지안 추정 (Default priors 사용)
# mcmcfile=TRUE로 설정하면 Stan 코드 확인 가능
fit_bayes <- bsem(model_syntax, data = y_data,
n.chains = 3, burnin = 500, sample = 1000,
target = "stan")
summary(fit_bayes)
WaurimaL의 팁: jamovi의
semlj모듈을 사용하면 메뉴 방식으로 SEM을 돌릴 수 있지만, 본문에서 다루는 세밀한 베이지안 설정(HMC, NUTS)을 위해서는 위와 같이 R 코드를Rj Editor에 붙여넣어 실행하는 것이 가장 정확합니다.
5. 수렴 진단 (Convergence Diagnostics)
베이지안 분석에서는 결과가 하나의 점(point)으로 수렴하는 것이 아니라, 분포로 수렴해야 합니다. 분석이 잘 되었는지 확인하는 방법입니다.
- Trace Plots (이력 도표): 애벌레(caterpillar)처럼 뚱뚱하고 털이 난 모양이어야 합니다. 사슬(chain)들이 서로 잘 섞여 있어야 합니다.
- Posterior Density Plots (사후 밀도 도표): 매끄러운 정규분포 모양이면 좋습니다. 봉우리가 두 개(bimodality)라면 수렴에 문제가 있는 것입니다.
- Autocorrelation (자기상관): 시차(lag)가 늘어날수록 상관이 빨리 0으로 떨어져야 합니다.
- (Potential Scale Reduction Factor): 사슬 간 분산과 사슬 내 분산의 비율입니다. 1.0에 가까워야 하며, 1.01보다 크면 수렴하지 않은 것으로 봅니다. 최근 Stan에서는 Split 을 사용하여 더 민감하게 진단합니다.
R
# 수렴 진단 그래프 (blavaan 기능)
plot(fit_bayes, type = "trace")
plot(fit_bayes, type = "acf")
blavInspect(fit_bayes, "neff") # 유효 표본 크기 확인
blavInspect(fit_bayes, "psrf") # R-hat 확인
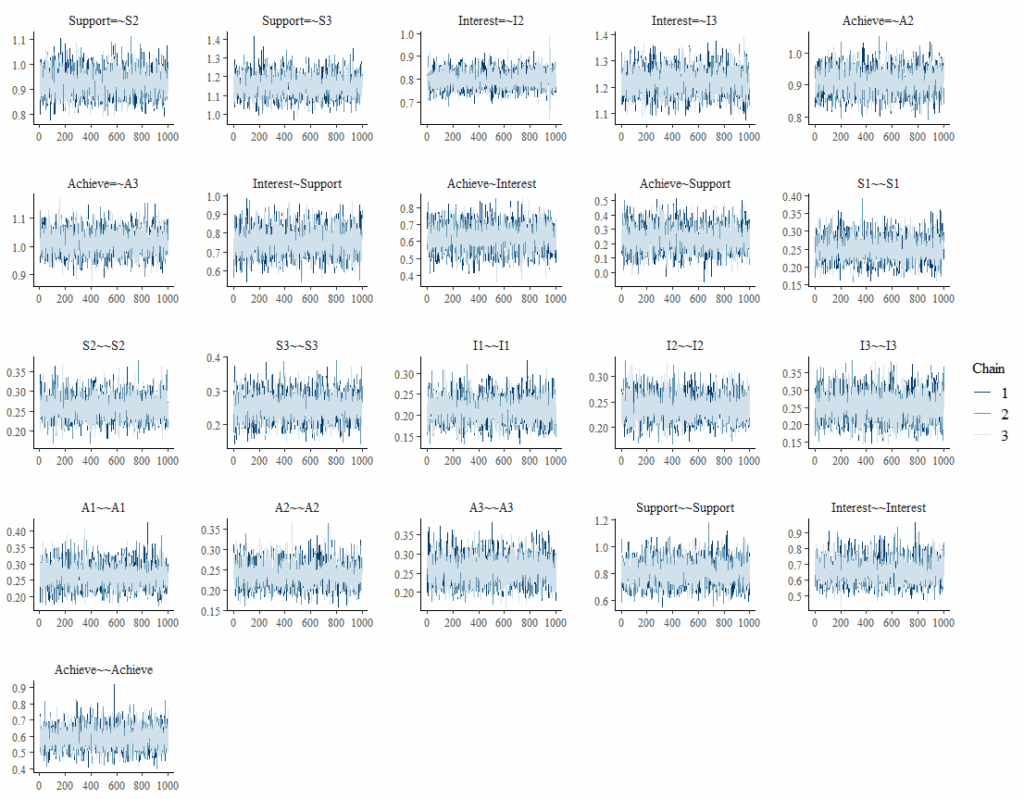
6. 모형 평가 및 선택
6.1 사후 예측 점검 (Posterior Predictive Checking, PPC)
내 모형이 생성한 가상의 데이터()가 실제 데이터()와 얼마나 비슷한지 봅니다.
- Bayesian p-value: 가상 데이터가 실제 데이터보다 극단적인 비율입니다. 0.5 근처면 모형이 데이터를 잘 설명하는 것이고, 0.05 미만이나 0.95 초과면 적합도에 문제가 있습니다.
6.2 모형 비교 지수
어떤 모형이 좋은 모형일까요?
- BIC: 전통적인 지수이지만 베이지안에서는 한계가 있습니다.
- DIC: 베이지안 편차 정보 기준. 작을수록 좋습니다.
- LOOIC (Leave-One-Out Information Criterion): 최근 가장 권장되는 방법입니다. 데이터 하나를 빼고 예측해 보는 교차타당도(LOOCV) 개념을 근사한 것입니다.
R
# 적합도 지수 확인
fitMeasures(fit_bayes, c("bic", "dic", "looic"))
6.3 베이지안 모형 평균화 (Bayesian Model Averaging, BMA)
하나의 모형만 선택하는 것은 위험할 수 있습니다. BMA는 여러 가능한 모형들의 결과를 그 모형이 맞을 확률(Posterior Model Probability)로 가중 평균하여 예측력을 높입니다. 교육 현장처럼 불확실성이 큰 경우 유용합니다.
7. 고급 확장: 사전 분포를 통한 유연성
BSEM의 진정한 힘은 ‘유연성’에 있습니다.
7.1 근사 0 사전 분포 (Near-Zero Priors)와 CFA
전통적 CFA에서는 교차 적재량(cross-loading)을 무조건 0으로 고정합니다. 이는 현실적이지 않습니다. BSEM에서는 이를 “정확히 0은 아니지만 0에 아주 가까운(Approximately Zero)” 정규분포 로 설정할 수 있습니다.
이렇게 하면 모형 적합도를 개선하면서도 이론적 구조를 유지할 수 있습니다.
7.2 근사 측정 불변성 (Approximate Measurement Invariance)
남녀 집단 간 비교를 할 때, 절편이나 적재량이 ‘완벽히’ 같을 필요는 없습니다. 그 차이가 근사적으로 0 ()이라고 가정함으로써, 엄격한 불변성 기각 문제를 해결할 수 있습니다.
7.3 베이지안 정규화 (Regularization): Ridge & Lasso
표본은 적은데 변수가 많을 때(과적합 위험), 계수를 0으로 수축(shrinkage)시키는 사전 분포를 사용합니다.
- Ridge: 정규분포 사전 분포 사용 (L2-norm).
- Lasso: 이중 지수(Double Exponential) 또는 라플라스 분포 사용 (L1-norm). 계수를 0으로 더 강하게 보냅니다.
R
# 예: Lasso 패널티를 적용한 모형 (blavaan syntax 예시)
# dp는 double exponential(Lasso)의 파라미터
# prior("double_exp(0, 1)", coefficients) 와 같은 형태로 설정 가능
8. 결론
베이지안 SEM은 단순한 ‘또 다른 추정 방법’이 아닙니다. 이것은 연구자가 가진 사전 지식을 모형에 명시적으로 포함하고, 불확실성을 정직하게 다루며, 엄격한 빈도주의 제약을 유연하게 풀어주는 실용적인 도구입니다.
이 글에서 배운 HMC 알고리즘, 수렴 진단, LOOIC, 그리고 정보적 사전 분포의 활용은 여러분이 교육 현장의 복잡한 데이터를 더 깊이 이해하는 데 큰 도움이 될 것입니다.
참고문헌
- Betancourt, M. (2018). A conceptual introduction to Hamiltonian Monte Carlo. arXiv preprint arXiv:1701.02434.
- Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., & Rubin, D. B. (2014). Bayesian data analysis (3rd ed.). Chapman and Hall/CRC.
- Kaplan, D., & Depaoli, S. (2012). Bayesian structural equation modeling. In R. H. Hoyle (Ed.), Handbook of structural equation modeling (pp. 650-673). Guilford Press.
- Muthén, B. O., & Asparouhov, T. (2012). Bayesian structural equation modeling: A more flexible representation of substantive theory. Psychological Methods, 17(3), 313–335.
- Vehtari, A., Gelman, A., & Gabry, J. (2017). Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC. Statistics and Computing, 27(5), 1413–1432.
- van de Schoot, R., Winter, S. D., Zondervan-Zwijnenburg, M., Ryan, O., & Depaoli, S. (2017). A systematic review of Bayesian applications in psychology: The last 25 years. Psychological Methods, 22(2), 217–239.