안녕하세요, 여러분.
이번에는 구조방정식 모델링(SEM) 연구를 설계할 때 가장 많이 받는 질문 중 하나인 “샘플 사이즈를 얼마나 잡아야 하나요?”에 대해 심도 있게 다루어 보겠습니다. 단순히 “사람이 많을수록 좋다”는 식의 접근이 아니라, 우리가 세운 가설이 실제 효과가 있을 때 이를 통계적으로 유의하게 찾아낼 확률인 ‘통계적 검증력(Statistical Power)’ 관점에서 접근해 봅시다.
1. 검증력 분석의 기초: 왜 필요한가?
1.1. 사전 검증력 분석 (A priori Power Analysis)
연구를 시작하기 전, 즉 데이터를 수집하기 전에 필요한 표본 크기를 결정하는 과정을 말합니다. 이는 연구자의 소중한 자원과 시간을 낭비하지 않게 해주며, 특히 연구 재단에 연구비를 신청할 때 표본 크기의 타당성을 입증하는 근거로 필수적입니다.
1.2. 사후 검증력 분석 (Post hoc Power Analysis)의 함정
데이터 수집 후 결과가 유의하지 않게 나왔을 때 “혹시 검증력이 부족해서인가?”를 확인하는 과정입니다. 하지만 많은 학자들은 사후 검증력 분석이 이미 나온 p-값의 다른 표현일 뿐이며, 큰 의미를 갖기 어렵다고 비판합니다. 따라서 우리는 오직 사전 검증력 분석에 집중할 것입니다.
2. SEM 검증력의 결정 요인
전통적인 통계(ANOVA 등)보다 SEM에서의 검증력 분석은 훨씬 복잡합니다. 다음과 같은 수많은 ‘움직이는 과녁’들이 검증력에 영향을 미치기 때문입니다.
- 표본 크기 (Sample Size): 가장 핵심적인 요인입니다.
- 모델의 복잡성: 측정 변수와 잠재 변수의 개수.
- 데이터의 분포: 정규성 위반 여부.
- 결측치 패턴: 데이터가 얼마나 빠져 있는가.
- 모델 오지정(Misspecification)의 정도: 실제 모델과 가설 모델의 차이.
3. 분석 전략 (1): 전체 모델 적합도 중심 (RMSEA 방식)
SEM은 모델이 데이터에 얼마나 잘 맞는지를 평가하는 ‘전체 적합도’가 중요합니다. MacCallum 등(1996)은 RMSEA 지수를 활용한 검증력 분석법을 제안했습니다.
3.1. 영가설과 대립가설의 설정
보통 SEM에서는 “모델이 완벽하게 맞는다(Exact fit, )”를 영가설로 두지만, 현실적으로 모델은 복잡한 현실의 단순화이기에 어느 정도의 오차는 존재합니다. 따라서 우리는 다음과 같이 설정합니다.
- 영가설(): 모델 적합도가 좋지 않다 ().
- 대립가설(): 모델 적합도가 우수하다 ().
이때, 우리가 실제로 기대하는 모델의 적합도()를 설정(예: .02)하여 분석을 수행합니다.
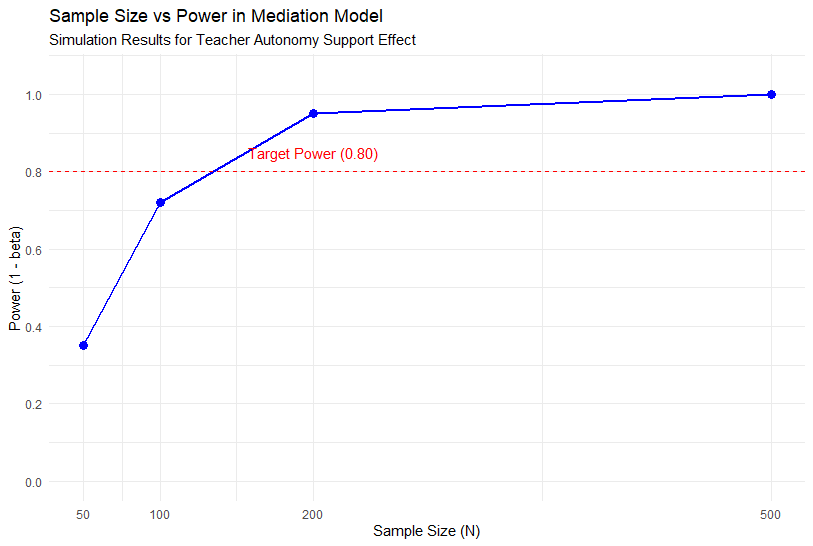
위 그림처럼, 표본 크기가 커질수록 영가설 분포와 대립가설 분포 사이의 거리가 멀어지며 검증력이 높아집니다.
4. 분석 전략 (2): 개별 파라미터 중심 (Satorra-Saris 방식)
모델 전체가 잘 맞는 것보다 특정 경로(예: 교사 지지가 학업 성취에 미치는 영향)의 유의성을 검증하는 것이 주 목적인 경우입니다.
4.1. 분석 단계
- 유의수준()과 목표 검증력() 설정: 보통 , 으로 설정합니다.
- 모수치 설정 (Population Values): 선행 연구를 바탕으로 기대되는 경로 계수값들을 정합니다.
- 모델 비교: 특정 경로가 ‘있는’ 모델(Full Model)과 ‘없는’ 모델(Reduced Model)의 카이스퀘어() 차이를 이용해 필요한 표본 크기를 계산합니다.
5. 교육 연구 사례를 통한 실습
5.1. 가상 시나리오: “중학생의 학업 성취 모델”
중학교 상담 교사인 김 박사는 다음과 같은 가설을 세웠습니다.
- 잠재변수: 수학 자기효능감(F1), 수학 불안(F2), 교사 지지(F3) 수학 성취도(F4)에 영향.
- 각 잠재변수는 여러 개의 설문 문항(관측변수)으로 측정됩니다.
5.2. 모의 자료 생성 (Story-based Simulation)
김 박사가 238명의 학생을 대상으로 설문했다고 가정하고, R을 이용해 실제와 유사한 데이터를 생성해 보겠습니다.
R
# R을 이용한 모의 데이터 생성 코드
library(lavaan)
# 1. 인구 모델 정의 (Population Parameter Values 기준) [cite: 421, 492]
pop_model <- '
F1 =~ 0.9*v1 + 0.8*v2 + 0.7*v3
F2 =~ 0.8*v4 + 0.7*v5 + 0.8*v6
F3 =~ 0.9*v7 + 0.8*v8 + 0.8*v9 + 0.7*v10
F4 =~ 0.95*v11 + 0.9*v12
# 경로 계수 설정 [cite: 492]
F4 ~ 0.2*F1 + (-0.25)*F2 + 0.3*F3
# 요인 간 상관 및 잔차 [cite: 492]
F1 ~~ -0.3*F2
F1 ~~ 0.4*F3
F2 ~~ -0.3*F3
'
# 2. 데이터 생성 (N=238)
set.seed(123)
sim_data <- simulateData(pop_model, sample.nobs = 238)
write.csv(sim_data, "school_achievement_data.csv", row.names = FALSE)
5.3. jamovi에서의 구현
현재 jamovi의 기본 SEM 모듈(jSEM)은 사후 적합도 평가는 우수하지만, ‘사전 검증력 분석’ 기능을 내장하고 있지는 않습니다. 따라서 jamovi에서 모델을 돌리기 전, WebPower 사이트나 R의 simsem 패키지를 활용해 계산해야 합니다.
실무 지침:
- WebPower(webpower.psychstat.org)에 접속합니다.
- ‘Statistical Power Analysis for Structural Equation Modeling’ 메뉴를 선택합니다.
- 앞서 설정한 자유도(df)와 기대하는 RMSEA 값을 입력하여 필요 샘플 수를 확인합니다.
- 확인된 샘플 수만큼 데이터를 수집한 후, jamovi의 jSEM 모듈에서 분석을 수행합니다.
6. 몬테카를로(Monte Carlo) 접근법의 활용
데이터가 정규분포를 따르지 않거나 결측치가 많을 것으로 예상될 때는 수식에 의존하는 분석보다 몬테카를로 시뮬레이션이 훨씬 정확합니다. 이는 컴퓨터가 가상의 데이터를 수천 번 생성하여 실제로 가설이 기각되는 비율을 직접 계산하는 방식입니다.
- 장점: 결측치 처리 방식(MAR, MNAR 등)을 미리 반영하여 검증력을 예측할 수 있습니다.
- 도구: R의
simsem패키지가 대표적입니다.
7. 결론 및 제언
구조방정식 연구에서 검증력 분석은 단순히 통과해야 할 관문이 아니라, 연구 결과의 재현성(Reproducibility)을 보장하는 장치입니다.
- 모델이 복잡할수록 더 많은 표본이 필요합니다.
- 표준적인 ‘경험 법칙'( 등)에 의존하기보다 자신의 모델에 맞춘 맞춤형 검증력 분석을 실시하십시오.
- 예산이 부족하다면 계획된 결측 설계(Planned Missing Design)를 통해 효율적으로 검증력을 확보하는 방법도 고려해 볼 수 있습니다.
참고문헌
- Bentler, P. M., & Chou, C.-P. (1987). Practical issues in structural modeling. Sociological Methods & Research, 16(1), 78–117.
- Browne, M. W., & Cudeck, R. (1992). Alternative ways of assessing model fit. Sociological Methods & Research, 21(2), 230–258.
- Feng, Y., & Hancock, G. R. (2025). Power analysis within a structural equation modeling framework. In Handbook of Structural Equation Modeling.
- Hancock, G. R., & French, B. F. (2013). Power analysis in structural equation modeling. In G. R. Hancock & R. O. Mueller (Eds.), Structural equation modeling: A second course (2nd ed., pp. 117–159). Information Age.
- MacCallum, R. C., Browne, M. W., & Sugawara, H. M. (1996). Power analysis and determination of sample size for covariance structure modeling. Psychological Methods, 1(2), 130–149.
- Muthén, L. K., & Muthén, B. O. (2002). How to use a Monte Carlo study to decide on sample size and determine power. Structural Equation Modeling, 9(4), 599–620.
- Satorra, A., & Saris, W. E. (1985). Power of the likelihood ratio test in covariance structure analysis. Psychometrika, 50(1), 83–90.