
안녕하세요!
오늘은 “다층모형의 표기법과 분석(Multilevel Model Notation and Analysis)”에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 들어가며: 다층모형, 도대체 왜 표기법이 중요한가?
다층모형(Multilevel Models, MLM)은 교육학, 생물학, 사회학 등 다양한 분야에서 활용됩니다. 하지만 교재마다, 소프트웨어마다 수식을 쓰는 방식이 달라서 학생들이 처음 접할 때 큰 혼란을 겪습니다.
어떤 책은 회귀분석 식을 하나로 길게 쓰고(복합 표기법), 어떤 책은 1수준 식과 2수준 식을 따로 씁니다(위계적 표기법). 하지만 걱정하지 마세요. 이들은 결국 같은 개념을 다른 그릇에 담은 것일 뿐입니다. 오늘 우리는 가상의 초등학교 데이터를 통해 이 표기법들이 실제 분석에서 어떻게 연결되는지 아주 쉽게 파헤쳐 보겠습니다.
2. 분석 시나리오: 행복초등학교의 수학 성취도
우리는 다음과 같은 교육적 가설을 검증하고자 합니다.
- 연구 문제: 학생의 수학 불안(Math Anxiety)은 수학 성취도(Math Achievement)에 부정적인 영향을 미치는가? 그리고 이 관계는 학교의 교사 지지(Teacher Support) 분위기에 따라 달라지는가?
- 데이터 구조:
- 1수준 (학생, ): 50개 학교, 총 1,000명의 학생.
- 2수준 (학교, ): 각 학교의 교사 지지 점수.
- 변수:
- : 수학 성취도 (종속변수)
- : 수학 불안 (1수준 독립변수, )
- : 교사 지지 (2수준 독립변수, )
이 시나리오를 바탕으로 R을 이용해 실제와 유사한 데이터를 생성해 보겠습니다.
[R Code] 모의 데이터 생성
R
# 필요한 패키지 로드
library(MASS)
library(lme4)
library(tidyverse)
set.seed(2026)
# 1. 파라미터 설정
J <- 50 # 학교 수
N_per_J <- 20 # 학교당 학생 수 (총 1000명)
gamma_00 <- 50 # 전체 평균 성취도
gamma_10 <- -5 # 수학 불안의 주효과 (불안 높으면 성적 하락)
gamma_01 <- 10 # 교사 지지의 주효과 (지지 높으면 성적 상승)
gamma_11 <- 3 # 상호작용 효과 (교사 지지가 높으면 불안의 부정적 효과 완화)
tau_0 <- 15 # 절편의 학교 간 분산 (SD)
tau_1 <- 5 # 기울기의 학교 간 분산 (SD)
sigma <- 10 # 학생 개인 오차 (SD)
# 2. 데이터 생성
schools <- data.frame(school_id = 1:J,
support = rnorm(J, 0, 1)) # 교사 지지 (표준화 점수)
# 학교별 랜덤 효과 (절편 u0, 기울기 u1) 생성 (상관관계 0.3 가정)
cov_matrix <- matrix(c(tau_0^2, 0.3*tau_0*tau_1,
0.3*tau_0*tau_1, tau_1^2), 2, 2)
random_effects <- mvrnorm(J, mu = c(0, 0), Sigma = cov_matrix)
schools$u0j <- random_effects[,1]
schools$u1j <- random_effects[,2]
# 학생 데이터 생성 및 병합
data <- expand.grid(student_id = 1:N_per_J, school_id = 1:J) %>%
left_join(schools, by = "school_id") %>%
mutate(
anxiety = rnorm(n(), 0, 1), # 수학 불안 (표준화 점수)
e_ij = rnorm(n(), 0, sigma), # 개인 오차
# 다층모형 수식 적용 (데이터 생성의 핵심)
math_score = (gamma_00 + u0j + gamma_01 * support) +
(gamma_10 + u1j + gamma_11 * support) * anxiety + e_ij
)
head(data)
# CSV 저장 (jamovi에서 불러오기 위함)
write.csv(data, "chap02.csv", row.names = FALSE)3. 다층모형의 표기법 완전 정복
이 데이터를 분석하기 위해 모형을 세울 때, 크게 두 가지 방식이 있습니다.
3.1. 위계적 표기법 (Hierarchical/Level Notation)
HLM 소프트웨어나 WinBUGS 같은 베이지안 도구에서 주로 사용합니다. 직관적으로 “수준(Level)”을 나누어 생각하기 좋습니다.
- 1수준 (학생 수준): 학생 개인의 성적은 그 학교의 평균()과 불안이 미치는 영향()에 의해 결정됩니다.
- 2수준 (학교 수준): 1수준의 계수들()이 학교 특성(교사 지지)에 따라 어떻게 변하는지 설명합니다.
WaurimaL의 팁: 이 표기법의 장점은 각 수준에서 어떤 변수가 영향을 미치는지 명확히 보여준다는 점입니다. 특히 “배경 변수”와 “효과”를 구분하기 좋습니다.
3.2. 복합 표기법 (Composite Notation)
SAS(PROC MIXED), SPSS, Stata(xtmixed), R(lmer), jamovi 등이 채택한 방식입니다. 위계적 표기법의 식을 대입하여 하나로 합친 것입니다.
- 고정 효과(Fixed Effects): 앞의 대괄호 부분. 전체 평균적인 효과를 의미합니다.
- 랜덤 효과(Random Effects): 뒤의 대괄호 부분. 학교마다, 학생마다 달라지는 오차(변동)를 의미합니다.
WauriamL의 팁: jamovi나 R을 사용할 때는 이 복합 표기법의 논리를 이해해야 “어떤 변수를 Fixed에 넣고, 어떤 변수를 Random에 넣을지” 결정할 수 있습니다.
4. 단계별 분석 및 jamovi/R 실습
분석은 보통 무조건 모형(기초) 랜덤 절편 모형 랜덤 기울기 및 상호작용 모형 순서로 진행합니다.
단계 1: 무조건 평균 모형 (Unconditional Means Model)
아무런 설명 변수 없이, 성적의 변동이 “학교 간 차이” 때문인지 “학생 간 차이” 때문인지만 봅니다.
- jamovi 실습:
Analyses>Linear Models>Mixed Model선택- Dependent Variable:
math_score - Cluster Variable:
school_id - Random Effects:
Intercept | school_id체크 (기본값)
- R Code:
Rmodel1 <- lmer(math_score ~ 1 + (1 | school_id), data = data)summary(model1)- 해석: 결과에서 급내상관계수(ICC)를 계산합니다.
. 만약 ICC가 0.2(20%)라면 성적 차이의 20%는 학교 차이로 설명된다는 뜻입니다.
단계 2: 랜덤 절편 모형 (Random Intercept Model)
학생 수준의 ‘수학 불안’과 학교 수준의 ‘교사 지지’를 투입합니다. 단, 수학 불안의 효과(기울기)는 모든 학교에서 동일하다고 가정합니다.
- 표기법적 의미: 위계적 표기법에서 으로 두어 학교별 차이()를 없앤 것입니다.
- jamovi 실습:
- Covariates에
anxiety,support추가. - Fixed Effects에
anxiety,support이동. - Random Effects에는 여전히
Intercept | school_id만 존재.
- Covariates에
- 변동의 설명(Targeting Variance): ‘교사 지지’는 학교 수준 변수이므로 학교 간 분산()을 줄이고, ‘수학 불안’은 학생 수준 변수이므로 잔차 분산()을 줄일 것으로 기대합니다.
단계 3: 랜덤 기울기 및 층위 간 상호작용 모형 (Full Model)
이제 “학교마다 수학 불안의 영향력이 다를 수 있다()”는 가정과, “교사 지지가 그 차이를 설명한다(상호작용)”는 가설을 검증합니다.
- 수식:
- jamovi 실습:
- Fixed Effects:
anxiety,support, 그리고anxiety * support상호작용항 추가. - Random Effects:
anxiety를school_id아래로 이동시켜 Random Slope 설정. (즉, 추가).
- Fixed Effects:
- R Code:
Rmodel3 <- lmer(math_score ~ anxiety * support + (1 + anxiety | school_id), data = data) summary(model3)5. 결과의 해석과 시각화
5.1. 주요 결과 해석
분석 결과표를 볼 때 가장 중요한 것은 고정 효과의 유의성과 랜덤 효과의 분산 성분입니다.
- 고정 효과 (Fixed Effects):
- Intercept (): 평균적인 수학 성취도
- Support (): 교사 지지가 높을수록 성취도가 높아지는가? (주효과)
- Anxiety (): 불안이 높을수록 성취도가 낮아지는가? (주효과)
- Interaction (): 교사 지지가 높은 학교에서는 불안이 성적에 미치는 부정적 영향이 줄어드는가? (조절효과)
- 랜덤 효과 (Variance Components):
- (Intercept Variance): 교사 지지를 고려하고도 남은 학교 간 성적 차이
- (Slope Variance): 학교마다 ‘불안의 효과’가 얼마나 들쑥날쑥한가? 이 값이 유의하면 학교마다 불안에 대처하는 양상이 다르다는 뜻입니다.
5.2. 시각화 (R을 이용한 개념도)
결과를 이해하기 쉽게 시각화해 보겠습니다. 아래 그래프는 교사 지지(Support)가 높고 낮은 두 학교 유형에서 수학 불안(Anxiety)과 성취도(Math Score)의 관계가 어떻게 다른지를 보여줍니다.
R
# 필요한 패키지 로드
if(!require(ggplot2)) install.packages("ggplot2")
library(ggplot2)
# 1. 데이터 생성 (앞서 Python 코드의 로직을 그대로 R로 구현)
set.seed(2026)
# X축 데이터: 수학 불안 (Centered) -2에서 +2까지 생성
anxiety <- seq(-2, 2, length.out = 100)
# 시나리오에 따른 예측값 생성
# 학교 A (높은 교사 지지): 기울기 완만 (-2), 절편 높음 (55)
score_high_support <- 55 - 2 * anxiety
# 학교 B (낮은 교사 지지): 기울기 급격 (-8), 절편 낮음 (45)
score_low_support <- 45 - 8 * anxiety
# 메인 효과(두 학교 유형)를 담을 데이터프레임 만들기
main_effects <- data.frame(
anxiety = rep(anxiety, 2),
score = c(score_high_support, score_low_support),
support_type = rep(c("High Teacher Support", "Low Teacher Support"), each = 100)
)
# 랜덤 효과 (배경에 깔릴 20개 개별 학교들의 회귀선) 데이터 생성
n_schools <- 20
random_lines <- data.frame()
for(i in 1:n_schools) {
# Python 예시와 동일한 분포 사용: 절편 ~ N(50, 5), 기울기 ~ N(-5, 2)
intercept <- rnorm(1, 50, 5)
slope <- rnorm(1, -5, 2)
y_values <- intercept + slope * anxiety
temp_df <- data.frame(
school_id = factor(i),
anxiety = anxiety,
score = y_values
)
random_lines <- rbind(random_lines, temp_df)
}
# 2. ggplot2를 이용한 시각화 그리기
ggplot() +
# [Layer 1] 배경: 개별 학교들의 회귀선 (랜덤 효과) - 회색으로 흐리게 처리
geom_line(data = random_lines, aes(x = anxiety, y = score, group = school_id),
color = "gray", alpha = 0.3) +
# [Layer 2] 전경: 교사 지지 수준별 평균 회귀선 (고정 효과 + 상호작용) - 굵고 선명하게
geom_line(data = main_effects, aes(x = anxiety, y = score, color = support_type, linetype = support_type),
linewidth = 1.5) +
# [Layer 3] 색상 및 선 스타일 지정 (파란색 실선 vs 빨간색 점선)
scale_color_manual(values = c("blue", "red")) +
scale_linetype_manual(values = c("solid", "dashed")) +
# [Layer 4] 라벨 및 제목 설정
labs(
title = "Cross-Level Interaction: Teacher Support x Math Anxiety",
subtitle = "The moderating effect of teacher support on the anxiety-achievement relationship",
x = "Math Anxiety (Centered)",
y = "Math Achievement",
color = "School Context",
linetype = "School Context"
) +
# [Layer 5] 테마 적용 (깔끔한 논문 스타일)
theme_bw() +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
plot.subtitle = element_text(size = 12, hjust = 0.5, margin = margin(b = 20)),
legend.position = "bottom",
legend.title = element_text(face = "bold"),
axis.title = element_text(size = 12)
)
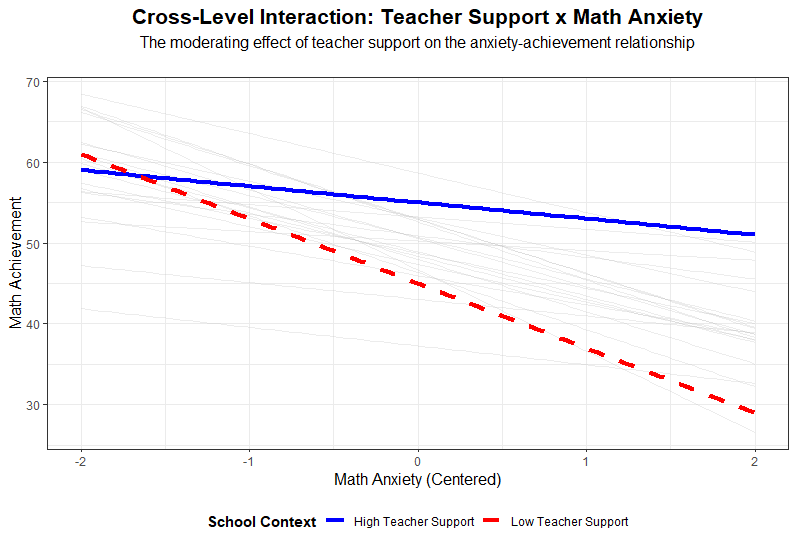
High Support 학교(파란선)에서는 불안이 높아져도 성적이 완만하게 떨어지지만, Low Support 학교(빨간선)에서는 급격하게 떨어지는 것을 볼 수 있습니다. 이것이 바로 상호작용 효과입니다.
6. 결론 및 요약
오늘 우리는 다층모형의 표기법과 분석 방법을 “행복초등학교” 예시를 통해 살펴보았습니다. 핵심을 정리해 드립니다.
- 표기법은 결국 하나다: 위계적 표기법(HLM)은 교육적 층위를 이해하기 좋고, 복합 표기법(R, jamovi)은 수리적 모델링에 편리합니다. 두 식은 수학적으로 완전히 동일합니다.
- 분산의 설명: 학교 변수는 학교 간 분산()을, 학생 변수는 학생 내 분산()을 설명하는 것을 목표로 합니다.
- 소프트웨어 활용: jamovi나 R은 복합 표기법을 따르므로, 고정 효과와 랜덤 효과를 구분하여 입력하는 것이 중요합니다.
다층모형은 복잡해 보이지만, “맥락(Context)이 개인(Individual)에게 미치는 영향”을 분석하는 가장 강력한 도구입니다. 이 강의가 여러분의 연구에 도움이 되기를 바랍니다.
References
- Browne, W. J., Goldstein, H., & Rasbash, J. (2001). Multiple membership multiple classification (MMMC) models. Statistical Modelling, 1(2), 103-124.
- Bryk, A. S., & Raudenbush, S. W. (1992). Hierarchical linear models: Applications and data analysis methods. Sage.
- Fitzmaurice, G. M., Ware, J. H., & Laird, N. M. (2004). Applied longitudinal analysis. Wiley-Interscience.
- Gelman, A., & Hill, J. (2007). Data analysis using regression and multilevel/hierarchical models. Cambridge University Press.
- Goldstein, H. (1995). Multilevel statistical models. Edward Arnold.
- Hox, J. (2002). Multilevel analysis: Techniques and applications. Erlbaum.
- Pinheiro, J. C., & Bates, D. M. (2000). Mixed-effects models in S and S-PLUS. Springer.
- Scott, M. A., Shrout, P. E., & Weinberg, S. L. (2013). Multilevel model notation: Establishing the commonalities. In The SAGE Handbook of Multilevel Modeling (pp. 21-38). Sage.
- Singer, J. D. (1998). Using SAS PROC MIXED to fit multilevel models, hierarchical models, and individual growth models. Journal of Educational and Behavioral Statistics, 23(4), 323-355.
- Singer, J. D., & Willett, J. B. (2003). Applied longitudinal data analysis: Modeling change and event occurrence. Oxford University Press.
- Snijders, T. A. B., & Bosker, R. (1999). Multilevel analysis: An introduction to basic and advanced multilevel modeling. Sage.