
안녕하세요!
오늘은 다층모형(Multilevel Model)의 우도 추정(Likelihood Estimation)과 그 적용에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 다층모형, 왜 필요한가요? (직관적 이해)
1.1 피셔(Fisher)의 형제들 이야기
통계학의 아버지라 불리는 Fisher(1925)는 아주 오래전, 형제(brother) 쌍의 데이터를 분석하면서 급내상관계수(Intraclass Correlation Coefficient, ICC)라는 개념을 도입했습니다.
- 상황: 형제들은 유전적 특징과 가정환경을 공유합니다. 따라서 형 A의 키가 크면, 동생 B의 키도 클 확률이 높습니다.
- 문제: 일반적인 회귀분석은 모든 데이터가 서로 독립적(남남)이라고 가정합니다. 하지만 형제 데이터는 서로 ‘의존적’입니다. 이를 무시하면 통계적으로 오류가 발생합니다.
1.2 학교 현장으로의 확장
이 개념을 오늘날 학교로 가져와 볼까요?
- 형제 = 같은 반 학생들: 같은 선생님, 같은 교실 분위기, 같은 급식을 공유합니다.
- 가정 = 학급(Class): 학생들은 학급 안에 내재(Nested)되어 있습니다.
우리는 이것을 2수준(2-level) 모형이라고 부릅니다.
- 1수준 (Level 1): 학생 개인 (형제 중 한 명)
- 2수준 (Level 2): 학급 (형제 쌍)
이 구조를 무시하면, 마치 학생들의 성적이 온전히 개인의 노력만으로 결정되는 것처럼 착각하게 되어, 교사나 학교의 효과를 과소평가하거나 통계적 유의성을 과대포장하는 실수를 범하게 됩니다.
2. 분석 시나리오 및 데이터 생성
이론을 실제처럼 느끼기 위해 가상의 데이터를 만들어 보겠습니다.
📖 시나리오: ‘행복초등학교’ 수학 성취도 분석
- 대상: 20개 학급, 총 500명의 6학년 학생.
- 종속변수(): 기말고사 수학 점수.
- 설명변수(): 수학 불안감 (0~10점, 높을수록 불안).
- 연구문제: 수학 불안감이 수학 점수에 미치는 영향은 학급마다 다른가?
2.1 R을 이용한 모의 데이터 생성 (jamovi에서 열기 가능)
R
# R 코드: 다층모형 데이터 생성
set.seed(123)
# 1. 기본 설정
n_classes <- 20 # 2수준: 학급 수
n_students <- 25 # 1수준: 학급당 학생 수 (균형 설계 가정)
N <- n_classes * n_students
# 2. 2수준(학급) 효과 생성
class_id <- rep(1:n_classes, each = n_students)
# 학급별 평균 성적의 차이 (절편의 변동): u0j ~ N(0, 25)
u0j <- rnorm(n_classes, mean = 0, sd = 5)
# 학급별 불안감 효과의 차이 (기울기의 변동): u1j ~ N(0, 1)
u1j <- rnorm(n_classes, mean = 0, sd = 1)
# 데이터 프레임 확장을 위해 학급 효과를 학생 수만큼 반복
u0_expanded <- rep(u0j, each = n_students)
u1_expanded <- rep(u1j, each = n_students)
# 3. 1수준(학생) 변수 및 오차 생성
# 수학 불안감 (X): 평균 5, 표준편차 2인 정규분포
Anxiety <- rnorm(N, mean = 5, sd = 2)
# 학생 개인 오차 (eij): eij ~ N(0, 36) -> 표준편차 6
eij <- rnorm(N, mean = 0, sd = 6)
# 4. 고정 효과(Fixed Effects) 설정
beta_0 <- 70 # 전체 평균 수학 점수 (절편)
beta_1 <- -3 # 불안감이 1점 오를 때 수학 점수 변화 (기울기)
# 5. 종속변수(Y) 생성: 수학 점수
# Y_ij = (beta_0 + u0j) + (beta_1 + u1j) * X_ij + e_ij
Math_Score <- (beta_0 + u0_expanded) + (beta_1 + u1_expanded) * Anxiety + eij
# 데이터 프레임 생성
data <- data.frame(
Class_ID = factor(class_id),
Student_ID = 1:N,
Anxiety = Anxiety,
Math_Score = Math_Score
)
# 데이터 확인
head(data)
# CSV 저장 (jamovi에서 불러오기 위함)
write.csv(data, "chap03.csv", row.names = FALSE)3. 다층모형의 추정 논리: IGLS 알고리즘
우리가 이 데이터를 jamovi나 R에 넣고 “분석해 줘”라고 할 때, 컴퓨터 내부에서는 어떤 일이 일어날까요? Goldstein 교수는 IGLS (Iterative Generalized Least Squares, 반복 일반화 최소자승법)를 핵심 알고리즘으로 소개합니다.
3.1 탁구 치기 (Ping-Pong) 비유
IGLS는 마치 탁구를 치듯 두 단계 과정을 반복하며 정답을 찾아갑니다.
- 고정 효과() 추정: “일단 학급 차이는 무시하고(또는 현재 추정된 차이를 감안하고) 전체 평균 회귀선을 그어보자.”
- 랜덤 효과() 추정: “방금 그은 선에서 실제 점수들이 얼마나 떨어져 있지? 이 잔차(Residuals)를 가지고 학급 간 분산()과 학생 간 분산()을 계산해보자.”
- 반복: 2번에서 구한 분산 정보를 이용해 가중치를 조절하여 다시 1번(회귀선)을 더 정교하게 그립니다. 이 과정을 값이 더 이상 변하지 않을 때까지(수렴) 계속합니다.
3.2 수리적 표현 (Strict)
기본적인 2수준 모형은 다음과 같습니다.
- : 학급 효과 (2수준 잔차)
- : 학생 효과 (1수준 잔차)
IGLS는 이 모수들을 추정할 때, 편향(Bias)이 발생할 수 있는데, 이를 보정한 것이 바로 우리가 흔히 쓰는 REML (Restricted Maximum Likelihood) 입니다. 데이터 수가 적은 학교 현장 연구에서는 REML이 더 권장됩니다.
4. jamovi 및 R을 활용한 단계별 분석
이제 생성된 데이터를 바탕으로 분석을 수행해보겠습니다. jamovi에서는 Linear Models > Mixed Models 메뉴를 사용합니다.
단계 1: 시각화 (기초선 파악)
먼저 데이터를 눈으로 확인해야 합니다. 학급마다 성적 분포가 다른지 봅니다.
R
# R 시각화 코드
library(ggplot2)
ggplot(data, aes(x = Anxiety, y = Math_Score, group = Class_ID)) +
geom_point(alpha = 0.3) +
geom_smooth(method = "lm", se = FALSE, aes(color = Class_ID), size = 0.5) +
theme_minimal() +
labs(title = "학급별 수학 불안감과 성취도의 관계",
subtitle = "학급마다 회귀선(기울기와 절편)이 다름을 볼 수 있습니다.")
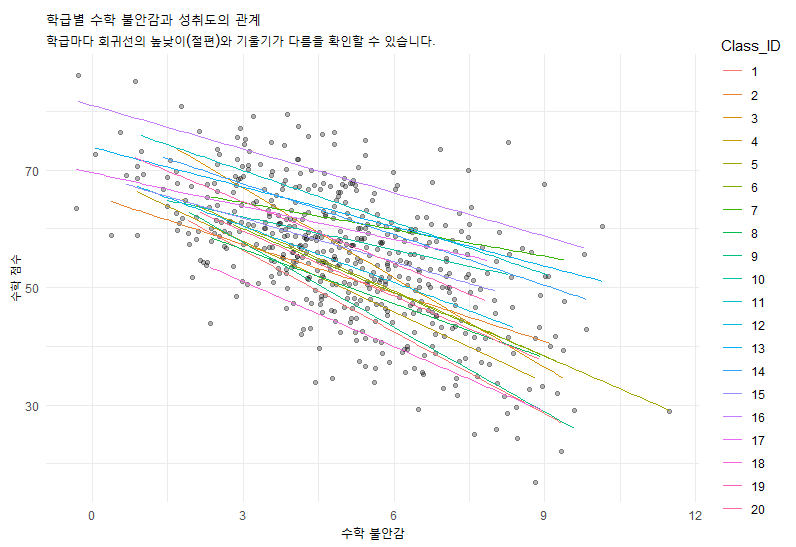
이 그래프를 보면, 어떤 반은 전체적으로 점수가 높고(절편 차이), 어떤 반은 불안감이 커져도 점수가 덜 떨어지는(기울기 차이) 패턴을 볼 수 있습니다.
단계 2: 무선형 (Null Model)과 ICC 확인
아무런 설명변수 없이, 오직 학급에 따른 점수 차이만 봅니다.
- jamovi 설정:
- Dependent Variable:
Math_Score - Cluster Variable:
Class_ID - Covariates: 없음
- Dependent Variable:
- 해석:
- (Level 2 분산): 학급 간 점수 차이.
- (Level 1 분산): 학급 내 학생 간 점수 차이.
- ICC (급내상관계수) : 전체 분산 중 학급이 설명하는 비율. 보통 0.05~0.1 이상이면 다층모형이 필요합니다.
단계 3: 랜덤 절편 모형 (Random Intercept Model)
“모든 반에서 불안감이 성적에 미치는 영향(기울기)은 같지만, 반마다 평균 성적(절편)은 다르다”고 가정합니다.
- jamovi 설정:
- Covariates에
Anxiety추가. - Random Effects에
Intercept | Class_ID체크.
- Covariates에
- 수식: .
단계 4: 랜덤 기울기 모형 (Random Slope Model)
“반마다 평균 성적도 다르고, 불안감이 성적에 미치는 충격도 다르다”고 가정합니다.
- jamovi 설정:
- Random Effects에
Anxiety를 추가 (즉,Intercept + Anxiety | Class_ID).
- Random Effects에
- 수식: .
- 여기서 가 바로 학급별 기울기의 차이입니다.
- 만약 이 모형이 랜덤 절편 모형보다 적합하다면(예: -2 Log Likelihood 차이 검증), 학급별로 맞춤형 지도가 필요함을 시사합니다.
분석 결과 예시표 (jamovi 스타일 재구성)
| 효과 (Effects) | 모수 (Parameter) | 추정치 (Estimate) | 의미 |
| 고정 효과 | 절편 () | 70.21 | 전체 학생의 평균적인 수학 기초 점수 |
| 불안감 () | -3.05 | 불안감이 1점 오를 때 평균 점수 변화 | |
| 랜덤 효과 | 학급 분산 () | 26.50 | 학급 간 평균 성적의 차이 (큼) |
| 기울기 분산 () | 1.12 | 학급 간 불안감 영향력의 차이 | |
| 잔차 분산 () | 35.80 | 설명되지 않는 학생 개인의 변동 |
5. 잔차(Residuals)와 진단: 셜록 홈즈가 되어보자
다층모형을 돌리고 나면, 우리는 각 학교나 학급의 성적표(잔차, )를 얻을 수 있습니다.
5.1 축소 추정량 (Shrunken Residuals)
단순히 그 반의 평균을 쓰는 게 아니라, 전체 평균 쪽으로 살짝 당겨진(Shrinkage) 값을 사용합니다.
- 왜? 학생 수가 적은 학급은 우연에 의해 점수가 튀었을 수 있기 때문입니다. 신뢰도가 낮은(학생 수가 적은) 학급의 추정치를 전체 평균 쪽으로 보정해 줍니다. 이를 통해 더 안정적인 추정이 가능합니다.
- 수식적으로는 로 계산됩니다.
5.2 모형 진단
잔차들이 정규분포를 따르는지 확인해야 합니다.
- Caterpillar Plot (애벌레 그림): 각 학급의 잔차()를 순서대로 나열하여 신뢰구간을 봅니다. 0을 포함하지 않는 학급은 평균보다 유의하게 높거나 낮은 학급입니다.
- QQ Plot: 잔차들이 대각선 직선 위에 잘 놓이는지 확인하여 정규성을 검증합니다.
6. 심화: 복잡한 학교 현실 반영하기
현실은 단순히 ‘반’에만 속하지 않을 수 있습니다. Goldstein 교수는 이를 위한 확장 모형을 제시합니다.
6.1 교차 분류 (Cross-classified) 모형
학생이 ‘학교’에도 속하고, 방과후 ‘학원’에도 속한다면 어떨까요?
- 학교와 학원은 위계 관계가 아닙니다. (A학교 학생이 모두 B학원에 다니는 게 아님).
- 이때는 처럼 두 개의 2수준을 동시에 고려해야 합니다.
- 이때 와 를 분리하여 어느 쪽 영향이 더 큰지 분석할 수 있습니다.
6.2 다중 소속 (Multiple Membership) 모형
한 학생이 학기 중에 1반에서 2반으로 전학을 갔다면요?
- 이 학생은 1반의 영향(50%)과 2반의 영향(50%)을 모두 받았습니다.
- 가중치()를 사용하여 형태로 모델링합니다. 이를 무시하면 학교 효과가 과소추정될 수 있습니다.
7. 결론 및 제언
오늘 우리는 Fisher의 형제 연구부터 시작하여 현대의 다층모형(IGLS/MLE)까지 살펴보았습니다.
- 핵심: 교육 데이터는 계층적(Nested)이며, 이를 무시하면 오류가 발생합니다.
- 방법: IGLS/MLE 알고리즘은 고정 효과와 랜덤 효과를 탁구 치듯 반복 추정하여 최적의 값을 찾습니다.
- 확장: jamovi와 R을 통해 랜덤 절편, 랜덤 기울기 모형뿐만 아니라 교차 분류 모형 등으로 확장이 가능합니다.
이 분석 방법을 통해 여러분은 단순히 “어느 학교가 공부를 잘하나?”를 넘어, “어떤 학교 환경이 학생의 불안감을 완충해 주는가?”와 같은 깊이 있는 교육적 질문에 답할 수 있게 됩니다.
참고문헌 (APA Style)
- Fisher, R. A. (1925). Statistical methods for research workers. London: Oliver and Boyd.
- Goldstein, H. (1986). Multilevel mixed model analysis using iterative generalized least squares. Biometrika, 73(1), 43–56.
- Goldstein, H. (2011). Multilevel statistical models (4th ed.). Chichester: Wiley.
- Goldstein, H., Rasbash, J., Yang, M., Woodhouse, G., Pan, H., Nuttall, D., & Thomas, S. (1993). A multilevel analysis of school examination results. Oxford Review of Education, 19(4), 425–433.
- Lindley, D. V., & Smith, A. F. M. (1972). Bayes estimates for the linear model. Journal of the Royal Statistical Society: Series B (Methodological), 34(1), 1–41.