[출처] Strauß, S., & Rummel, N. (2026). Fostering collaborative learning and promoting collaboration skills: What generative AI could contribute. In OECD Digital Education Outlook 2026. (Excerpt from Chapter 4).
안녕하세요!
오늘은 교육계의 핫한 트렌드인 ‘생성형 AI(Generative AI)’가 학교나 직장의 ‘협동 학습(팀 프로젝트)’을 어떻게 바꿀 수 있는지에 대한 아주 흥미로운 보고서를 가져왔습니다.
OECD에서 발표된 따끈따끈한 내용을 바탕으로, 챗GPT 같은 AI가 우리 아이들의, 혹은 우리의 ‘팀플’을 어떻게 도와줄 수 있는지 알기 쉽게 정리해 드릴게요.
[AI 교육] 챗GPT가 ‘팀플’의 구세주가 될 수 있을까?
여러분, 학창 시절이나 회사에서 ‘조별 과제’나 ‘팀 프로젝트’ 때문에 스트레스받으신 적 있으시죠? 누구는 말 안 하고, 누구는 딴짓하고, 대화는 산으로 가고…🤯
그런데 만약 AI가 이 팀 프로젝트에 참여해서 우리를 도와준다면 어떨까요? 최신 OECD 보고서(Chapter 4)는 생성형 AI가 협동 학습에서 어떤 역할을 할 수 있는지 흥미로운 분석을 내놓았습니다. 어려운 전문 용어 다 빼고 핵심만 쏙쏙 뽑아 전해드립니다!
1. 협동 학습, 왜 AI가 필요할까?
‘협동 학습’은 단순히 일을 나눠서 하는 게 아닙니다. 서로 머리를 맞대고 대화하며 새로운 지식을 만들어가는 과정이죠. 하지만 이게 말처럼 쉽지 않습니다. 누군가는 참여를 안 하고(무임승차), 대화가 뚝 끊기기도 하거든요.
이때 AI가 등장합니다! AI는 팀원들이 서로 잘 뭉치고 더 깊게 생각할 수 있도록 도와주는 ‘똑똑한 도우미’ 역할을 할 수 있습니다.
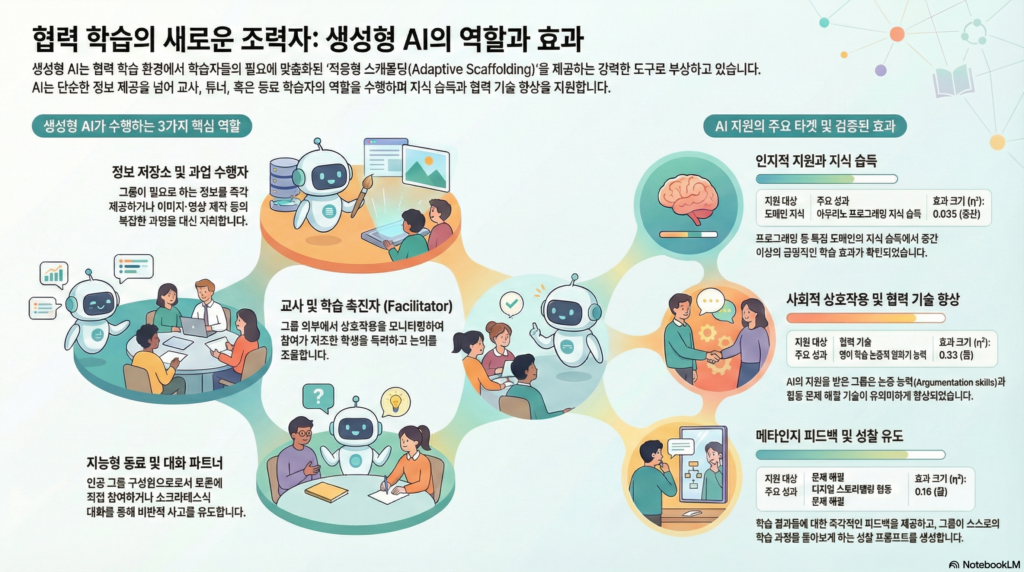
2. AI가 팀플에서 맡을 수 있는 5가지 역할
이 보고서에서는 생성형 AI(예: 챗GPT)가 팀 활동에서 맡을 수 있는 역할을 크게 5가지로 정리했습니다. 상상해 보세요, 우리 팀에 이런 AI가 있다면 어떨까요?
① 걸어 다니는 도서관 (Repository of information)
가장 기본적인 역할입니다. 팀원들이 토론하다가 막히는 정보가 있으면 AI에게 물어봅니다. 마치 검색엔진처럼 필요한 정보를 척척 찾아주죠.
② 맞춤형 자료 제작자 (Personalized materials)
AI가 우리 팀의 토론 내용을 듣고 있다가, “이런 반대 의견도 생각해 보는 건 어때?”라며 새로운 자료를 만들어줍니다. 또는 우리 아이디어를 바탕으로 멋진 이미지나 이야기를 대신 만들어주기도 합니다.
③ 친절한 선생님 또는 사회자 (Teacher or Facilitator)
이게 정말 대박입니다. AI가 팀의 대화를 모니터링하다가 “철수 님은 아직 말씀을 별로 안 하셨네요, 의견 어떠세요?”라며 참여를 유도합니다. 혹은 대화가 딴 길로 새면 “자, 다시 주제로 돌아옵시다”라고 방향을 잡아주기도 하죠.
④ 1:1 과외 선생님 (Tutor or Dialogue Partner)
AI가 소크라테스처럼 팀원들에게 끊임없이 질문을 던집니다. “왜 그렇게 생각했나요?”, “근거는 무엇인가요?”라며 팀원들이 더 깊게 사고할 수 있도록 훈련시키는 대화 파트너가 되어줍니다.
⑤ 가상의 팀원 (Artificial Group Member)
AI가 아예 팀의 일원이 됩니다! 예를 들어 엔지니어 역할을 맡은 AI가 “제 전문가적 소견으로는…”이라며 회의에 참여하는 거죠. 사람이 부족할 때, 혹은 전문가의 시각이 필요할 때 AI가 그 빈자리를 채워줄 수 있습니다.
3. 그래서, 효과가 있었나요?
연구 결과들을 살펴봤더니 꽤 긍정적인 신호들이 보입니다.
지식 습득: 코딩 교육 같은 분야에서는 AI의 도움을 받은 그룹이 더 잘 배우는 경향이 있었습니다.
협업 능력 향상: 영어를 배우는 학생들이 AI의 도움을 받았을 때 논리적으로 말하는 능력이 좋아졌다는 연구 결과도 있네요.
태도 변화: AI와 함께 디지털 스토리텔링을 한 그룹이 문제 해결 능력이 더 좋아지기도 했습니다.
하지만 연구진은 아직 ‘초기 단계’라고 말합니다. 모든 상황에서 AI가 만능은 아니며, 때로는 AI가 엉뚱한 정보를 주거나(환각 현상), 학생들이 AI에 너무 의존해서 스스로 생각하는 것을 멈출 수도 있기 때문입니다.
4. 앞으로 우리가 주의할 점
AI를 팀플에 쓰려면 ‘균형’이 중요합니다.
AI에게 다 떠넘기지 말기: 어려운 생각은 AI에게 맡기고 인간은 ‘생각하는 게으름뱅이’가 되면 안 됩니다.
AI는 거들 뿐: 결국 협동 학습의 핵심은 ‘사람과 사람의 상호작용’입니다. AI는 이 관계를 돕는 도구여야지, 사람 간의 대화를 대체해서는 안 됩니다.
천천히, 제대로 검증하기(Slow Science): 무작정 AI를 도입하기보다, 정말 학습에 도움이 되는지 꼼꼼히 따져보고 윤리적인 문제(편향성 등)는 없는지 살피는 ‘느린 과학’의 태도가 필요합니다.
✍️ WaurimaL의 한마디
“AI가 조별 과제 잔혹사를 끝낼 수 있을까?”라는 질문에 이 논문은 “가능성은 매우 높지만, 어떻게 쓰느냐에 달렸다”라고 답하고 있습니다.
AI가 사회자처럼 공평하게 발언권을 주고, 전문가처럼 지식을 보태준다면, 앞으로의 팀 프로젝트는 고통이 아니라 즐거운 성장의 시간이 될 수도 있겠네요. 우리 아이들이 AI라는 똑똑한 친구와 함께 더 잘 협력하는 법을 배우는 미래, 기대해 봐도 좋겠죠? 😄
출처 (APA Style): OECD. (2026). OECD Digital Education Outlook 2026: Exploring Effective Uses of Generative AI in Education. (Specifically Chapter 3: Learning with dialogue-based AI tutors: Implementing the Socratic method with Generative AI). OECD Publishing.
안녕하세요!
오늘은 교육계에서 정말 핫한 주제인 ‘생성형 AI(Generative AI)가 교육을 어떻게 바꾸고 있는가’에 대한 따끈따끈한 OECD 보고서 내용을 가져왔습니다. 챗GPT 같은 AI가 단순히 숙제를 대신 해주는 기계가 아니라, 소크라테스처럼 끊임없이 질문하며 사고력을 키워주는 선생님이 된다면 어떨까요?
이 글을 통해 AI 튜터의 진화와 핵심 원리를 아주 쉽게 설명해 드릴게요.
🤖 AI가 “정답” 대신 “질문”을 던진다? 교육의 미래, 소크라테스 AI
여러분, 학창 시절에 선생님이나 과외 선생님께 모르는 걸 물어보면 바로 답을 알려주시는 분이 좋았나요, 아니면 “왜 그렇게 생각하니?”라고 되물으며 스스로 답을 찾게 도와주시는 분이 좋았나요? 교육적으로는 후자가 훨씬 도움이 된다고 하죠.
오늘 소개할 핵심 내용은 바로 ‘소크라테스 놀이터(Socratic Playground, SPL)’라는 시스템을 통해 본 생성형 AI의 미래입니다.
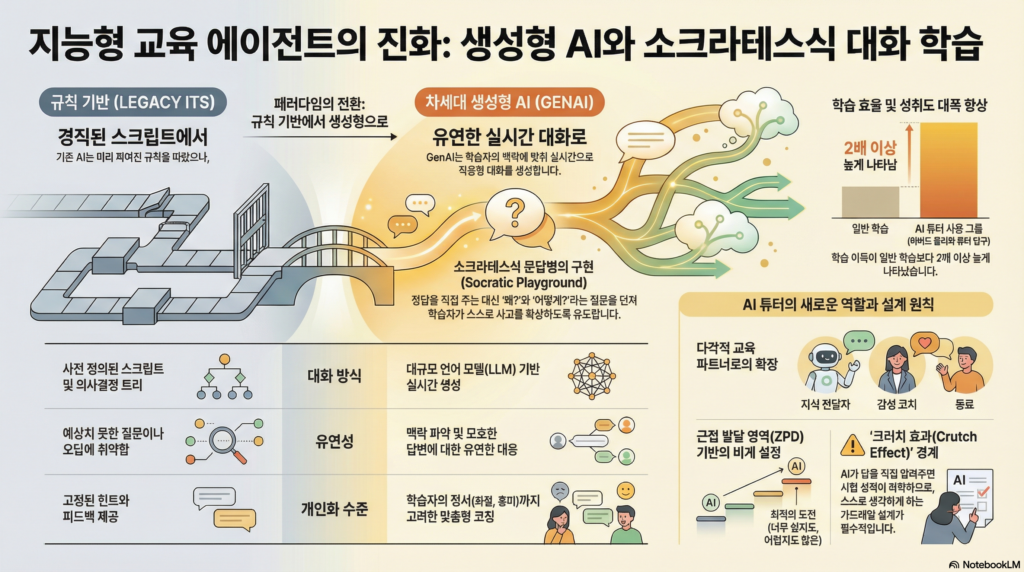
1. 딱딱한 로봇에서 ‘대화하는 파트너’로 진화
예전의 AI 교육 프로그램(튜터)들은 마치 짜여진 각본 같았습니다. 개발자가 미리 입력해 둔 질문과 답변 외에는 소화하지 못했죠. 학생이 예상치 못한 엉뚱한 질문을 하면 “이해하지 못했습니다”라고 하거나 멈춰버리곤 했습니다.
하지만 지금의 생성형 AI(GPT-4 등)는 다릅니다. 미리 정해진 대본이 없어도 상황에 맞춰 즉석에서 자연스러운 대화를 만들어냅니다. 학생의 기분이나 답변 수준에 따라 AI가 실시간으로 반응할 수 있게 된 것이죠.
2. ‘소크라테스식 문답법’을 구사하는 AI
이 논문의 핵심 사례인 ‘소크라테스 놀이터(SPL)’는 단순히 지식을 주입하는 게 아니라, 소크라테스처럼 질문을 통해 학생의 비판적 사고력을 키워주는 데 집중합니다.
예를 들어, 학생이 “재생 에너지는 정부 보조금을 받아야 해”라고 글을 썼다고 가정해 봅시다.
과거 AI: “맞춤법이 틀렸네요.” 또는 “관련된 사실은 이렇습니다.”
생성형 AI (SPL): “좋은 지적이야! 그런데 시장에 그냥 맡겨두지 않고 왜 굳이 정부가 개입해야 한다고 생각하니?”.
이렇게 꼬리에 꼬리를 무는 질문(Why & How)을 통해 학생은 자신의 주장을 더 논리적으로 다듬게 됩니다. 실제로 이 시스템을 써본 학생들은 처음보다 훨씬 더 깊이 있는 글을 쓰게 되었다고 해요.
3. AI의 다양한 변신: 멘토부터 친구까지
생성형 AI는 단순히 선생님 역할만 하는 게 아닙니다. 상황에 따라 카멜레온처럼 변신합니다.
멘토 & 코치: 학생이 문제를 어떻게 풀어야 할지 모를 때, 답을 주는 대신 힌트를 주며 스스로 깨우치게 도와줍니다. 학생이 좌절하면 격려해 주는 ‘감정 코칭’도 가능하죠.
동료 & 친구: 때로는 AI가 학생과 함께 문제를 푸는 친구가 되거나, “나는 이렇게 생각하는데 너는 어때?”라며 토론 파트너가 되어줍니다. 심지어 AI가 모르는 척하고 학생에게 가르쳐달라고 부탁해서(Learning by teaching), 학생이 설명하면서 공부하게 만들기도 합니다.
평생 학습 동반자: 미래에는 학교를 졸업해도 내가 무엇을 배웠고 무엇을 어려워했는지 기억하며 평생 공부를 도와주는 AI 친구가 될 수도 있습니다.
4. “교육이 먼저, 기술은 거들 뿐” (Pedagogy First)
이 보고서에서 가장 강조하는 점은 “아무리 AI가 똑똑해도 교육학적 원리가 우선되어야 한다”는 것입니다.
AI가 아무 말이나 막 던지는 게 아니라, 교육적으로 검증된 방식(예: 비계 설정, Scaffolding)으로 학생을 이끌어야 합니다. 학생이 스스로 할 수 있는 수준보다 딱 한 단계 높은 질문을 던져서 성장하게 만드는 것이죠.
또한, 학생이 AI에게만 의존해서 생각하는 것을 멈추지 않도록(일명 ‘목발 효과’), AI는 정답을 바로 주지 않고 끊임없이 학생이 스스로 생각하게 유도해야 합니다.
5. 해결해야 할 과제들: AI가 거짓말을 한다면?
물론 장점만 있는 건 아닙니다. 해결해야 할 현실적인 문제들도 있습니다.
환각 현상(Hallucination): AI가 그럴듯한 거짓말을 사실인 것처럼 말할 수 있습니다. 예를 들어 존재하지 않는 법률을 진짜인 것처럼 설명할 수도 있죠. 이를 막기 위해 교과서 등 검증된 자료만 참고하도록 제한하는 기술(RAG)이 필수적입니다.
속도 문제(Latency): AI가 답변을 생각하느라 5~10초씩 걸리면 대화의 맥이 끊길 수 있습니다.
투명성: AI가 왜 이런 질문을 했는지, 왜 이런 피드백을 줬는지 학생과 선생님이 이해할 수 있어야 합니다.
📝 요약 및 마무리
결국 미래의 AI 튜터는 ‘정답 자판기’가 아니라 ‘생각하게 만드는 파트너’가 되어야 합니다. 이 보고서는 기술의 화려함보다는 ‘어떻게 가르칠 것인가’라는 교육의 본질을 지키면서 AI를 활용해야 한다고 강조하고 있습니다.
AI가 내 생각의 근육을 키워주는 트레이너가 되는 세상, 생각보다 빨리 우리 곁에 올지도 모르겠네요!
출처 (APA Style): Gašević, D., & Yan, L. (2026). Generative AI for human skill development and assessment: Implications for existing practices and new horizons. In OECD Digital Education Outlook 2026-02. OECD Publishing.
안녕하세요!
오늘은 교육계의 뜨거운 감자, 바로 ‘생성형 AI(Generative AI)’와 ‘학습’에 대한 아주 중요한 이야기를 들고 왔습니다. ChatGPT가 나오고 나서 “이제 공부는 AI가 다 해주는 거 아냐?”라는 생각, 한 번쯤 해보셨죠?
최근 OECD에서 발표한 디지털 교육 전망 보고서에 아주 흥미로운 내용이 담겨 있습니다. AI가 우리 교육을 어떻게 바꾸고 있는지, 그리고 우리가 ‘진짜 실력’을 키우기 위해 조심해야 할 점은 무엇인지 핵심만 쏙쏙 뽑아 정리해 드릴게요.
🤖 AI가 내 과외 선생님이 된다면? (기회)
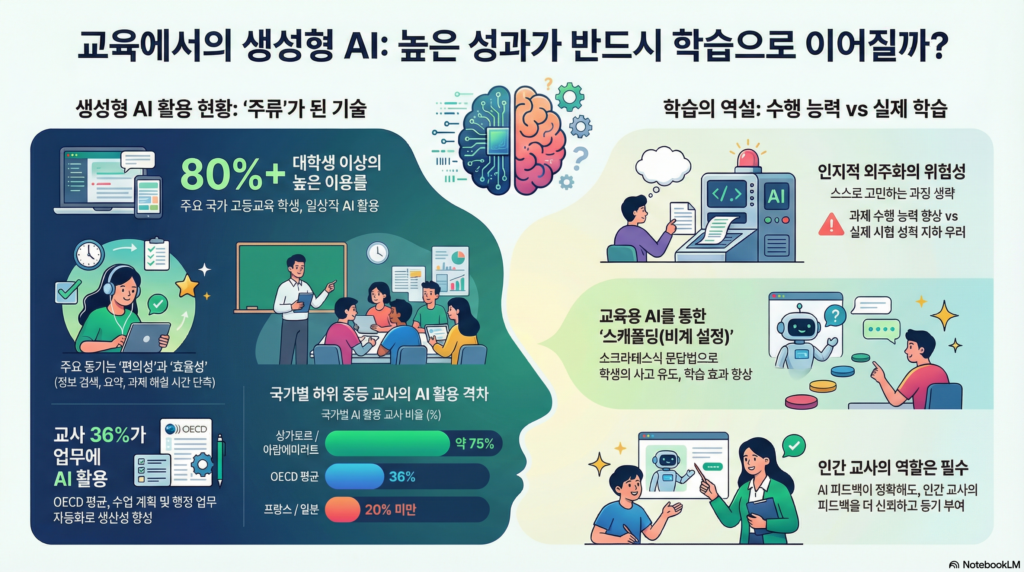
가장 먼저 눈에 띄는 변화는 ‘맞춤형 교육’의 가능성입니다. 예전에는 선생님 한 분이 수십 명의 학생을 가르쳐야 해서 개개인을 봐주기 힘들었죠. 하지만 생성형 AI는 1:1 과외 선생님처럼 학생 한 명 한 명에게 맞춤형 지도를 해줄 수 있습니다.
나만의 AI 튜터: 칸 아카데미의 ‘칸미고(Khanmigo)’ 같은 AI 챗봇은 학생들에게 정답을 바로 알려주는 게 아니라, 소크라테스처럼 질문을 던지며 스스로 답을 찾게 도와줍니다.
선생님의 든든한 보조: 선생님들도 AI의 도움을 받아 수업 계획을 짜거나 행정 업무 시간을 줄이고, 학생들과 소통하는 데 더 집중할 수 있게 되었어요.
초고속 피드백: AI는 학생의 글을 읽고 문법이나 스타일을 순식간에 교정해 줍니다. 심지어 사람보다 더 읽기 좋고 매끄러운 피드백을 주기도 한다는 연구 결과도 있죠.
⚠️ 잠깐! ‘가짜 실력’의 함정에 빠지지 마세요 (위험)
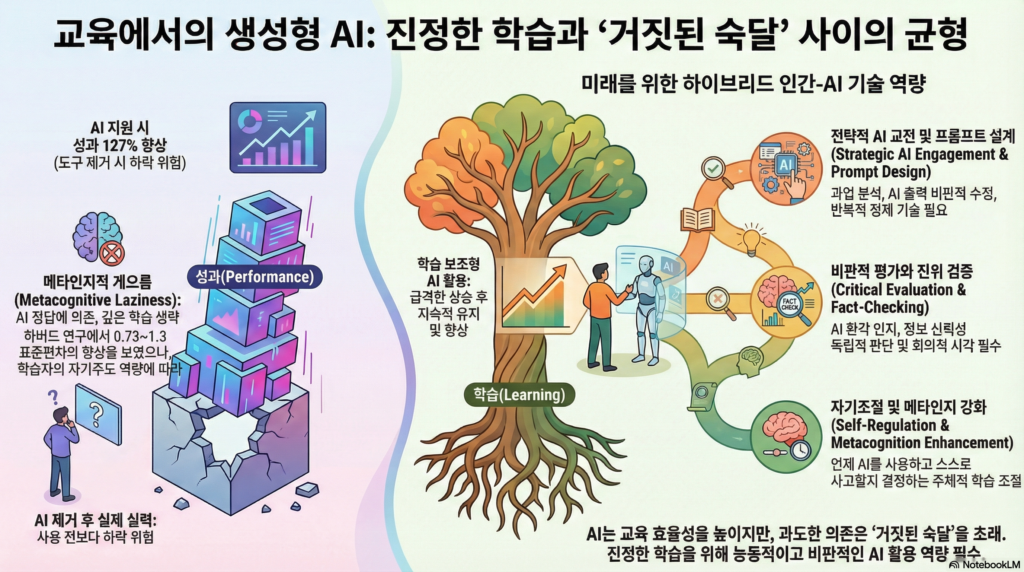
하지만 이 보고서가 경고하는 아주 중요한 ‘함정’이 있습니다. 바로 “거짓 숙달의 신기루(Mirage of False Mastery)”라는 개념입니다.
쉽게 말해, AI를 써서 숙제를 완벽하게 해냈다고 해서 그게 ‘내 실력(학습)’은 아니라는 겁니다.
성과 vs 학습: AI 덕분에 결과물(에세이, 코딩 등)의 수준은 높아질 수 있습니다(성과). 하지만 AI가 다 해줘서 정작 내 머릿속에는 남는 게 없을 수도 있죠(학습 실패),.
생각의 게으름(Metacognitive Laziness): AI에게 너무 의존하다 보면, 스스로 생각하고 점검하는 과정을 건너뛰게 됩니다. 연구에 따르면 AI 챗봇을 단순히 ‘답안지’로만 활용한 학생들은 오히려 사고력이 떨어지거나 학습 동기를 잃기도 했습니다,.
🚀 결과보다 ‘과정’이 중요한 시대 (해결책)
그렇다면 AI 시대에 우리는 어떻게 공부해야 할까요? 보고서는 ‘결과물’보다는 ‘과정’을 평가해야 한다고 강조합니다.
과정 중심 피드백: 단순히 “정답입니다/틀렸습니다”가 아니라, 학생이 어떤 전략으로 공부했는지, 시간 관리는 잘했는지 같은 ‘학습 과정’에 대해 조언해 주는 것이 중요합니다.
하이브리드 기술 (Human-AI Skills): 이제는 AI 없이 공부하는 게 아니라, AI를 ‘똑똑하게 부리는 능력’이 필요합니다.
질문 잘하기: AI에게 원하는 답을 얻기 위해 프롬프트(명령어)를 잘 만드는 능력.
의심하고 검증하기: AI가 만든 내용이 진짜인지 가짜인지 팩트 체크하는 비판적 사고력.
내 것으로 만들기: AI의 도움을 받되, 주도권은 내가 쥐고 내 지식으로 소화하는 능력.
📝 결론: AI는 도구일 뿐, 조종사는 ‘나’
AI는 교육의 판도를 바꿀 엄청난 도구임은 분명합니다. 하지만 맹목적으로 의존했다가는 화려한 결과물 뒤에 숨겨진 ‘빈 깡통’ 실력만 남을 수 있습니다.
핵심은 이것입니다. AI가 과제를 ‘대신’ 하게 하지 말고, AI와 ‘함께’ 생각하는 힘을 기르세요. 결과물이 얼마나 훌륭한지보다, 그 결과를 만들어내기 위해 내가 얼마나 치열하게 고민했는지가 더 중요한 시대가 되었습니다.
오늘은 “다층모형과 인과추론(Multilevel Models and Causal Inference)”에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 들어가며: 왜 다층모형인가?
전통적인 회귀분석은 모든 학생이 서로 독립적이라고 가정합니다. 하지만 교육 현장은 그렇지 않습니다. 같은 학교, 같은 반 학생들은 급훈, 담임 선생님, 학교 분위기 등을 공유합니다. 이를 위계적 구조(Hierarchical Structure) 또는 집단 의존성(Group Dependencies)이라고 합니다.
인과추론(Causal Inference)의 관점에서, 데이터가 이러한 계층 구조를 가질 때 다층모형(Multilevel Model)을 사용하는 것은 단순한 통계적 선호가 아니라, 편향(Bias)을 줄이고 정확한 표준오차를 추정하기 위한 필수 전략입니다.
2. 인과추론의 기초 개념과 교육적 예시
본격적인 분석에 앞서, 인과추론의 핵심 개념을 학교 상황에 빗대어 정의해 봅시다.
2.1 잠재적 결과 (Potential Outcomes)
어떤 학생 철수()가 있습니다.
: 철수가 ‘방과후 보충수업()’을 들었을 때의 성적
: 철수가 ‘방과후 보충수업()’을 듣지 않았을 때의 성적
인과 효과(Causal Effect)는 이 둘의 차이 입니다. 하지만 현실에서 우리는 철수가 수업을 듣거나, 듣지 않거나 둘 중 하나의 결과만 볼 수 있습니다. 이를 “인과추론의 근본적인 문제(Missing Data Problem)”라고 합니다.
2.2 SUTVA (Stable Unit Treatment Value Assumption)
이 가정은 “철수가 보충수업을 받았는지 여부가, 옆 짝꿍 영희의 성적에 영향을 주지 않아야 한다(상호간섭 없음)”는 것입니다.
문제점: 학교에서는 이 가정이 자주 깨집니다. 철수가 보충수업에서 배운 내용을 영희에게 알려줄 수 있기 때문입니다. 이를 해결하기 위해 집단(학교/학급) 단위 무선화가 권장되기도 합니다.
3. 연구 설계에 따른 다층모형 적용
3.1 무선화 실험 (Randomized Experiments)
가장 이상적인 상황입니다. 처치(Treatment)가 무작위로 배정되면, 평균적으로 두 집단은 성향이 비슷해집니다().
A. 개인 단위 무선배정 (학생별 제비뽑기)
학생들에게 무작위로 새로운 ‘독서 프로그램’을 배정했습니다. 하지만 학생들은 학교()라는 집단에 속해 있습니다. 학교마다 평균 독서 능력이 다를 수 있으므로, 이를 반영한 다층모형(Random Intercept Model)이 필요합니다.
: 번째 학교의 고유한 특성(학교 효과, 랜덤 절편)
: 독서 프로그램의 효과 (우리가 알고 싶은 값)
이 모형을 쓰면 학교 간 차이()를 통제하고 순수한 프로그램 효과()를 더 정밀하게 추정할 수 있습니다.
B. 집단 단위 무선배정 (학교별 제비뽑기)
교육 정책 연구에서는 흔히 “A학교는 실험군, B학교는 대조군”으로 배정합니다. 이를 군집 무선화(Cluster Randomized Experiments)라고 합니다.
이유: ‘학교 폭력 예방 캠페인’처럼 학교 전체 분위기를 바꾸는 처치는 학생 개인별로 쪼개서 적용할 수 없기 때문입니다.
분석: 처치 변수()가 학생 수준()이 아닌 학교 수준()에 들어갑니다.
3.2 관찰 연구 (Observational Studies)
현실적으로 무선 배정이 불가능할 때(예: 사립학교 진학 효과), 우리는 무시가능성(Ignorability) 가정을 도입합니다. 즉, “부모의 소득, 지능 등 공변량()이 같다면, 사립학교와 공립학교 학생은 비교 가능하다”고 가정하는 것입니다.
성향점수(Propensity Score) 활용: 다층 구조에서는 성향점수를 추정할 때도 다층모형을 사용하는 것이 좋습니다.
4. [실습] jamovi & R을 활용한 다층 인과 분석
이제 가상의 시나리오를 통해 실제 데이터를 생성하고 분석해 보겠습니다.
4.1 시나리오: “아침 독서 마라톤” 효과 분석
연구 배경: 경기도 교육청은 초등학생의 어휘력 향상을 위해 매일 아침 20분간 책을 읽는 ‘아침 독서 마라톤’ 프로그램을 개발했습니다.
연구 설계:
총 20개 학교, 학교당 30명의 학생(총 600명).
군집 무선화(Cluster RCT): 학교 단위로 제비뽑기를 하여 10개 학교는 ‘프로그램 시행(Treatment)’, 10개 학교는 ‘기존 자습(Control)’을 하도록 했습니다.
데이터 구조:
Level 1: 학생 (사후 어휘력 점수 score)
Level 2: 학교 (school_id)
처치: program (1=시행, 0=미시행)
4.2 R을 이용한 모의 데이터 생성
jamovi는 R 기반이므로, 아래 코드로 데이터를 생성하여 CSV로 저장한 뒤 jamovi에서 불러오면 됩니다.
R
# 필수 라이브러리 로드
library(lme4)
library(tidyverse)
set.seed(2026) # 재현성을 위한 시드 설정
# 1. 파라미터 설정
n_schools <- 20 # 학교 수
n_students <- 30 # 학교당 학생 수
n_total <- n_schools * n_students
# 2. 학교 수준 효과 (Level 2)
# 학교마다 평균 어휘력이 다름 (표준편차 5)
school_intercept <- rnorm(n_schools, mean = 0, sd = 5)
# 처치 배정 (학교 단위 무선화)
# 1~10번 학교: 통제군(0), 11~20번 학교: 실험군(1)
school_treatment <- c(rep(0, 10), rep(1, 10))
# 학교 데이터 프레임
school_data <- data.frame(
school_id = 1:n_schools,
school_eff = school_intercept,
program = school_treatment
)
# 3. 학생 수준 데이터 생성 (Level 1)
data <- data.frame(
student_id = 1:n_total,
school_id = rep(1:n_schools, each = n_students)
)
# 학교 정보 병합
data <- left_join(data, school_data, by = "school_id")
# 4. 결과 변수 생성 (어휘력 점수)
# 기본 점수 70점 + 프로그램 효과 8점 + 학교 효과 + 개인 오차(sd=8)
# y_ij = 70 + 8 * z_j + u_j + e_ij
data <- data %>%
mutate(
error = rnorm(n_total, mean = 0, sd = 8),
score = 70 + 8 * program + school_eff + error
)
# 팩터 변환
data$school_id <- as.factor(data$school_id)
data$program <- factor(data$program, levels = c(0, 1), labels = c("Control", "Treatment"))
# 데이터 확인
head(data)
이 데이터는 학교 간 차이(School Effect)가 존재하고, 처치가 학교 단위로 부여되었으므로 다층모형(Linear Mixed Model)을 사용해야 정확합니다.
Step 1: 데이터 탐색 및 시각화
분석 전에 데이터의 구조를 눈으로 확인해야 합니다.
jamovi 메뉴:Exploration > Descriptives
Variables에 score를 넣고, Split by에 program을 넣습니다.
Box Plot: 학교별 차이를 보기 위해 Box plot을 체크하고, X축에 program을 둡니다. (※ jamovi 기본 기능으로는 학교별 boxplot을 한 번에 그리기 어려우므로 R 모듈인 seolmatrix나 scatr 모듈을 설치하여 시각화하면 좋습니다.)
[R 시각화 코드]
R
# 학교별 점수 분포 시각화
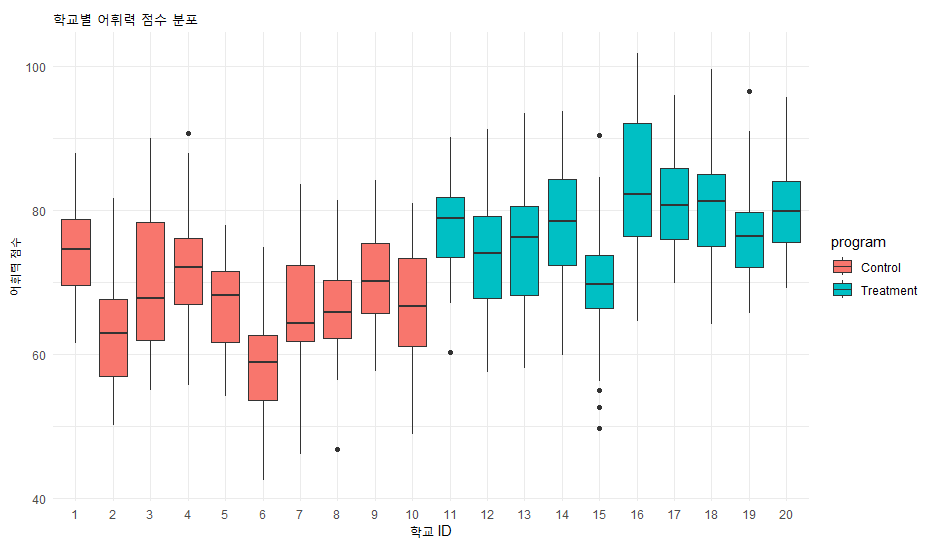
ggplot(data, aes(x = school_id, y = score, fill = program)) +
geom_boxplot() +
theme_minimal() +
labs(title = "학교별 어휘력 점수 분포", y = "어휘력 점수", x = "학교 ID")
해석: 상자 그림을 보면 같은 처치 집단 내에서도 학교마다 점수의 높낮이가 다름을 알 수 있습니다. 이것이 바로 (학교 효과)입니다.
Step 2: 다층모형 분석 (Linear Mixed Models)
모듈 선택: 상단 메뉴에서 Linear Models > Mixed Model을 클릭합니다. (보이지 않으면 jamovi Library에서 GAMLj 모듈을 설치하는 것을 강력 추천합니다. 여기서는 기본 Mixed Model 기준으로 설명합니다.)
변수 설정:
Dependent Variable (종속변수):score
Covariates (공변량) 또는 Factors:program (처치 변수)
Cluster (군집 변수):school_id
Random Effects (랜덤 효과) 설정:
왼쪽의 program을 오른쪽으로 옮기지 않고, Intercept만 Random Coefficients에 둡니다. (기본적으로 (Intercept | school_id)로 설정됨)
이는 학교마다 평균 점수(절편)가 다름을 허용하는 것입니다.
Fixed Effects (고정 효과) 설정:
program을 Model Terms에 넣습니다. 이것이 우리가 알고 싶은 ‘독서 마라톤 효과’입니다.
Step 3: 결과 해석
jamovi의 결과표(Estimates)는 다음과 유사하게 나옵니다.
Effect
Estimate
SE
t
p
Intercept
72.574
0.972
74.681
< .001
program (Treatment)
10.162
1.944
5.228
< .001
Fixed Effects:program의 Estimate가 약 10.162입니다. 즉, 독서 마라톤을 한 학교 학생들이 하지 않은 학교보다 평균적으로 약 10.162점 더 높은 어휘력을 보입니다. 이므로 통계적으로 유의합니다.
Random Components (Variance):
(School Intercept): 학교 간 분산. 이 값이 0보다 크다면 학교 효과가 존재한다는 뜻입니다.
ICC (Intraclass Correlation Coefficient): 전체 분산 중 학교가 설명하는 비율입니다.
5. 심화: 불응(Noncompliance)과 도구변수(IV)
실험을 했는데, 독서 프로그램을 하라고 배정받은 학교의 일부 학생이 땡땡이를 쳤다면(Noncompliance) 어떻게 될까요? 이때는 “배정된 상태()”를 도구변수(Instrument)로 사용하여, 실제 “참여한 상태()”의 효과를 추정해야 합니다.
jamovi/R 구현 (2단계 최소자승법 개념)
1단계: 실제 참여 여부()를 배정 여부()로 예측합니다.
2단계: 1단계에서 예측된 참여값()을 사용하여 점수()를 예측합니다.
이 분석은 jamovi의 sem (구조방정식) 모듈이나 R의 AER 패키지(ivreg)를 통해 수행할 수 있습니다. 중요한 건 배정()은 오직 참여()를 통해서만 결과()에 영향을 미쳐야 한다(배제 제한)는 가정입니다.
6. 결론
다층모형을 활용한 인과추론은 교육 현장과 같이 “집단 속에 개인이 속한 데이터”를 분석할 때 가장 강력한 도구입니다.
설계: 가능하다면 학교 단위 무선화(Cluster RCT)가 상호간섭(SUTVA 위배) 문제를 피하는 데 유리합니다.
분석: 단순히 평균을 비교하는 t-test 대신, 학교의 무선 절편(Random Intercept)을 포함한 혼합 모형을 사용해야 표준오차의 과소추정을 막을 수 있습니다.
해석: 결과는 “개인 수준의 효과”인지 “학교 수준의 효과”인지 명확히 구분하여 해석해야 합니다.
이 장의 내용이 여러분의 연구에 튼튼한 방법론적 기초가 되기를 바랍니다.
참고문헌 (APA Style)
Almond, D., Chay, K., & Lee, D. (2005). The costs of low birth weight. The Quarterly Journal of Economics, 120(3), 1031-1083.
Angrist, J. D., Imbens, G. W., & Rubin, D. B. (1996). Identification of causal effects using instrumental variables. Journal of the American Statistical Association, 91(434), 444-472.
Cornfield, J. (1978). Randomization by group: A formal analysis. American Journal of Epidemiology, 108(2), 100-102.
Gelman, A., & Hill, J. (2007). Data analysis using regression and multilevel/hierarchical models. Cambridge University Press.
Hill, J. (2013). Multilevel models and causal inference. In The SAGE Handbook of Multilevel Modeling (Chapter 12, pp. 201-219).
Hong, G., & Raudenbush, S. W. (2006). Evaluating kindergarten retention policy: A case study of causal inference for multilevel observational data. Journal of the American Statistical Association, 101(475), 901-910.
Kim, J., & Seltzer, M. (2007). Causal inference in multilevel settings in which selection processes vary across schools (Tech. Rep.). CRESST, UCLA.
Rubin, D. B. (1978). Bayesian inference for causal effects: The role of randomization. The Annals of Statistics, 6(1), 34-58.
Rubin, D. B. (1990). Formal modes of statistical inference for causal effects. Journal of Statistical Planning and Inference, 25(3), 279-292.
Slavin, R. E., Madden, N. A., Dolan, L. J., & Wasik, B. A. (1996). Every child, every school: Success for all. Corwin Press.
오늘은 “다층 연구 설계의 최적화(Sample Size and Power Analysis in Multilevel Designs)”에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 기반이 되는 R 코드를 함께 제시하여 ‘최적 표본 크기 산출’부터 ‘모의 데이터 생성’, 그리고 ‘분석’까지 완벽하게 구현해 드리겠습니다. (참고: jamovi는 데이터 분석에는 강력하지만, 연구 설계 단계의 복잡한 ‘최적 표본 산출’ 기능은 제한적이므로, 이 부분은 R의 수리적 계산 기능을 활용하고 분석은 jamovi의 혼합모형 논리로 설명하겠습니다.)
1. 서론: 연구자의 영원한 딜레마, “돈이냐, 정확성이냐?”
교육 연구를 진행할 때 우리는 항상 두 가지 제약 조건 사이에서 고민합니다.
통계적 검증력(Power): 효과가 있다면 있다고 말할 수 있는 힘 (높을수록 좋음).
예산(Budget): 연구비와 시간은 한정되어 있음.
이 장에서는 다층 모형(Multilevel Modeling) 상황, 즉 학생이 학교에 소속되어 있는 구조에서 어떻게 하면 가장 적은 비용으로 가장 높은 정확성을 얻을 수 있는지, 그 최적 설계(Optimal Design) 방법을 알려드리겠습니다.
우리의 가상 시나리오를 소개합니다.
[시나리오: 프로젝트 ‘독서왕’]
교육심리학자 김 교수는 새로운 독서 프로그램이 초등학생의 ‘문해력’을 높이는지 검증하려 합니다.
총 예산: 1,000만 원 (가상의 화폐 단위)
비용 구조:
학교 하나를 섭외하는 비용(행정 절차, 학교 보상 등): 200만 원 (c)
학생 한 명을 검사하는 비용(검사지, 간식 등): 10만 원 (s)
연구 질문: 몇 개의 학교를 섭외하고, 학교당 몇 명의 학생을 뽑아야 내 돈 1,000만 원 안에서 가장 정확한 결과를 얻을까요?
2. 군집 무작위 배정(Cluster Randomized Trial)의 설계
2.1 왜 다층 설계인가?
가장 쉬운 방법은 전국의 학생 명부에서 무작위로 학생을 뽑는 것입니다. 하지만 현실적으로 불가능합니다.
실행 가능성: 학교 단위로 프로그램을 돌려야 합니다.
오염(Contamination): 한 반에서 철수는 실험집단, 영희는 통제집단이면 서로 이야기하며 효과가 섞여버립니다.
그래서 우리는 학교(Cluster)를 통째로 실험군 혹은 대조군으로 배정하는 군집 무작위 배정(Cluster Randomized Trial)을 사용합니다.
2.2 급내상관계수(ICC)와 설계 효과
문제는 같은 학교 아이들끼리는 서로 비슷하다는 점입니다(학교 분위기, 선생님의 영향 등). 이를 급내상관계수(ICC, )라고 합니다.
ICC가 높다 = 학교 간 차이가 크다 = 같은 학교 아이들은 매우 비슷하다.
ICC가 높으면, 학생을 100명 더 뽑는 것보다 학교를 1개 더 섭외하는 게 훨씬 중요해집니다.
2.3 최적 표본 크기 공식 (The Magic Formula)
주어진 예산() 하에서 처치 효과()의 분산()을 최소화하는 최적의 학교 수()와 학교당 학생 수()는 다음과 같습니다.
: 학교당 비용 (200)
: 학생당 비용 (10)
: ICC (가정된 값, 보통 0.05~0.10)
이 공식을 보면, ICC()가 커질수록 학교당 학생 수()는 줄여야 합니다. 왜냐하면 같은 학교에서 많이 뽑아봤자 정보가 중복되기 때문입니다.
3. R과 jamovi를 활용한 최적 설계 및 데이터 생성
이제 김 교수의 ‘독서왕’ 프로젝트를 위해 R을 사용하여 최적 표본을 계산하고, 이를 분석할 수 있는 모의 데이터를 생성해 보겠습니다.
3.1 최적 표본 크기 계산 (R Code)
김 교수의 상황: 예산 10,000, , 그리고 ICC()는 선행연구를 통해 0.05로 가정합니다.
R
# [R Code] 최적 표본 크기 산출
# 파라미터 설정
B <- 10000 # 총 예산
c <- 200 # 학교(Cluster)당 비용
s <- 10 # 학생(Person)당 비용
rho <- 0.05 # 급내상관계수 (ICC)
# 1. 최적의 학생 수 (n) 계산 [cite: 120]
n_opt <- sqrt((c * (1 - rho)) / (s * rho))
# 2. 최적의 학교 수 (K) 계산 [cite: 119]
K_opt <- B / (c + s * n_opt)
# 결과 출력
cat("최적의 학교당 학생 수 (n):", round(n_opt, 2), "명\n")
cat("최적의 학교 수 (K):", round(K_opt, 2), "개교\n")
[분석 결과 해석]
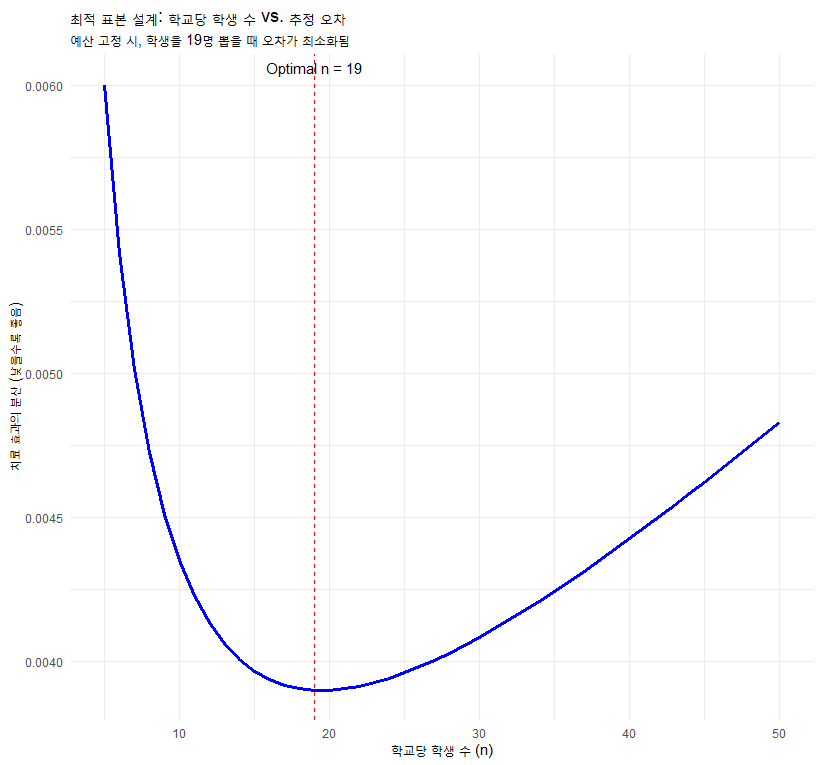
계산 결과, , 가 나옵니다.
현실적으로 반올림하여 학교당 19명, 총 26개 학교(실험 13, 통제 13)를 섭외하는 것이 최적입니다.
3.2 비용 효율성 시각화 (Design Efficiency Plot)
아래 그래프는 학교당 학생 수()를 변화시킬 때, 추정의 오차(분산)가 어떻게 변하는지 보여줍니다. 우리는 분산이 가장 낮은 지점을 찾아야 합니다.
R
# [R Code] 시각화 생성
library(ggplot2)
n_seq <- seq(5, 50, by = 1) # 학생 수를 5명에서 50명까지 변화시킴
K_seq <- B / (c + s * n_seq) # 예산 제약에 따른 학교 수
# 분산 계산 공식 (단순화된 형태) [cite: 128]
# g_rho 부분과 예산 부분을 결합
design_var <- function(n, K, rho) {
# Standard Error calculation based on Eq 11.3 & 11.6 logic relation
# Here we look at relative variance proportional to the function
design_effect <- 1 + (n - 1) * rho
total_N <- n * K
return(design_effect / total_N)
}
var_values <- design_var(n_seq, K_seq, rho)
df_plot <- data.frame(n = n_seq, Variance = var_values)
ggplot(df_plot, aes(x = n, y = Variance)) +
geom_line(color = "blue", linewidth = 1.2) +
geom_vline(xintercept = 19, linetype = "dashed", color = "red") +
annotate("text", x = 19, y = max(var_values), label = "Optimal n = 19", vjust = -1) +
labs(title = "최적 표본 설계: 학교당 학생 수 vs. 추정 오차",
subtitle = "예산 고정 시, 학생을 19명 뽑을 때 오차가 최소화됨",
x = "학교당 학생 수 (n)", y = "치료 효과의 분산 (낮을수록 좋음)") +
theme_minimal()
이 그래프를 통해 김 교수는 무작정 학생을 많이 뽑는다고 좋은 게 아니라, 학교 수와 학생 수의 황금 비율을 맞춰야 함을 알 수 있습니다.
4. 모의 데이터 생성 및 분석 (Linear Mixed Model)
이제 최적 설계()에 따라 데이터를 수집했다고 가정하고, 이를 jamovi(또는 R의 lmer)에서 분석하는 방법을 보여드리겠습니다.
# [R Code] 모의 데이터 생성
set.seed(123) # 재현성을 위해 시드 설정
K <- 26 # 학교 수
n <- 19 # 학교당 학생 수
N <- K * n # 총 학생 수
# 학교 ID 및 치료 집단 배정 (0: 통제, 1: 처치)
school_id <- rep(1:K, each = n)
treatment <- rep(c(rep(0, K/2), rep(1, K/2)), each = n)
# 랜덤 효과 생성 (학교 간 차이)
u0j <- rep(rnorm(K, mean = 0, sd = sqrt(5)), each = n) # 학교 분산 = 5
# 오차항 생성 (학생 간 차이)
# ICC = 0.05 이려면, 학교분산/(학교분산+오차분산) = 0.05
# 5 / (5 + 95) = 0.05 -> 오차 분산은 95, SD는 약 9.75
eij <- rnorm(N, mean = 0, sd = sqrt(95))
# 고정 효과 (진짜 치료 효과 = 5점)
beta0 <- 50 # 평균 점수
beta1 <- 5 # 치료 효과
# 종속 변수 (문해력 점수) 생성
# y_ij = beta0 + beta1*x_j + u_0j + e_ij
y <- beta0 + beta1 * treatment + u0j + eij
# 데이터 프레임 생성
data_sim <- data.frame(
SchoolID = factor(school_id),
StudentID = 1:N,
Treatment = factor(treatment, labels = c("Control", "Program")),
Score = y
)
# 데이터 확인
head(data_sim)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data_sim, "chap11.csv", row.names = FALSE)
Random Effects:SchoolID의 Variance가 설계 시 가정한 분산과 유사한지 확인합니다.
5. 심화: 더 복잡한 상황들
5.1 다기관 임상시험 (Multisite Trials)
만약 김 교수가 학교 전체를 배정하는 게 아니라, 각 학교 안에서 철수는 실험반, 영희는 통제반으로 나눌 수 있다면 어떨까요?
이를 Multisite Trial이라고 합니다.
장점: 학교 효과()가 치료 효과 추정에서 사라지므로 훨씬 강력한 검증력(Power)을 가집니다.
설계: 이 경우 은 학교 분산에 영향을 받지 않으므로, 더 적은 예산으로도 유의한 결과를 얻을 수 있습니다. 하지만 ‘오염’ 문제가 없어야만 가능합니다.
5.2 반복 측정 (Longitudinal Design)
만약 김 교수가 프로그램을 1년 동안 진행하면서 학생들의 변화를 보고 싶다면 몇 번 측정해야 할까요?
선형 변화(직선 성장)를 가정할 때: 시작(Baseline)과 끝(End), 딱 2번 측정하거나, 중간 지점 하나를 추가하는 것이 비용 대비 가장 효율적입니다.
이차 함수(곡선 성장)를 가정할 때: 최소 3번의 측정이 필요하며, 등간격으로 측정하는 것이 좋습니다.
5.3 현실적인 문제와 해결책
ICC를 모를 때: 보통 문헌 연구를 통해 보수적으로(약간 높게) 잡습니다. ICC를 실제보다 절반 정도로 낮게 잘못 예측했더라도, 최적 설계 대비 효율성 손실은 약 10% 내외로 크지 않다는 연구가 있습니다.
학교 크기가 다를 때: 모든 학교가 19명일 수는 없습니다. 학교 간 크기 편차(CV)가 0.5 정도라면, 계산된 학교 수()보다 약 11% 정도 더 많은 학교를 섭외하여 이를 보정해야 합니다.
6. 결론 및 제언
오늘 살펴본 내용을 요약하면 다음과 같습니다.
학교 현장 연구에서는 학생 수만큼이나 학교 수(Cluster Number)가 중요하다.
비용 함수와 ICC를 고려하면, 무조건 많은 표본보다 최적의 비율을 찾는 것이 경제적이다.
학교를 통째로 배정(CRT)하는 것보다 학교 내 무선 배정(Multisite)이 통계적으로는 더 유리하나, 오염 가능성을 고려해야 한다.
참고문헌 (APA Style)
Maas, C. J. M., & Hox, J. J. (2005). Sufficient sample sizes for multilevel modeling. Methodology, 1(3), 86-92.
Moerbeek, M., & Teerenstra, S. (2011). Optimal design in multilevel experiments. In J. J. Hox & J. K. Roberts (Eds.), Handbook of Advanced Multilevel Analysis (pp. 257-281). New York: Routledge.
Raudenbush, S. W. (1997). Statistical analysis and optimal design for cluster randomized trials. Psychological Methods, 2(2), 173-185.
Snijders, T. A. B., & Bosker, R. J. (1993). Standard errors and sample sizes for two-level research. Journal of Educational Statistics, 18(3), 237-259.
Van Breukelen, G. J. P., & Moerbeek, M. (2013). Design considerations in multilevel studies. In M. A. Scott, J. S. Simonoff, & B. D. Marx (Eds.), The SAGE Handbook of Multilevel Modeling (pp. 183-200). SAGE Publications.
오늘은 개체 내 오차 구조(Within-Individual Error Structures)의 복잡성과 모델링에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
우리가 학교에서 학생들의 성장을 추적할 때(종단 연구), 단순히 “평균 점수가 올랐나?”만 보는 것은 반쪽짜리 분석입니다. 학생 개개인이 어떻게 변화하는지, 그 변화의 폭(분산)은 일정한지, 어제의 성적이 오늘의 성적에 얼마나 영향을 미치는지(상관)를 파악해야 합니다. 제공해주신 텍스트는 이러한 공분산 구조(Covariance Structure)를 어떻게 모델링할 것인가에 대한 깊이 있는 통찰을 제공합니다.
1. 교육 현장의 예시: “읽기 유창성 성장 프로젝트”
이해를 돕기 위해 가상의 시나리오를 설정하겠습니다.
상황: A 초등학교에서 3학년 학생 50명을 대상으로 ‘읽기 유창성(1분당 읽은 단어 수)’을 1년 동안 4회(3월, 6월, 9월, 12월) 측정했습니다.
핵심 질문:
모든 학생의 읽기 실력 격차(분산)는 3월이나 12월이나 똑같을까요? (등분산성)
3월 성적이 좋은 학생은 6월에도 좋을까요? 12월까지 그 영향이 갈까요? (계열 상관)
2. 기본 모델과 개념 (The General Model)
우리는 데이터를 다음의 선형 회귀 모델로 표현할 수 있습니다.
: 학생들의 읽기 점수 벡터
(고정 효과): 전체 학생들의 평균적인 성장 곡선 (예: 시간이 지날수록 점수가 오른다).
(임의 효과): 학생 개인별 특성 (예: 어떤 학생은 시작부터 잘하고, 어떤 학생은 성장 속도가 빠르다).
(오차 항): 설명되지 않는 나머지 변동. 오늘의 핵심 주제는 바로 이 의 구조인 를 파헤치는 것입니다.
3. 데이터 시각화와 진단 (Diagnostics)
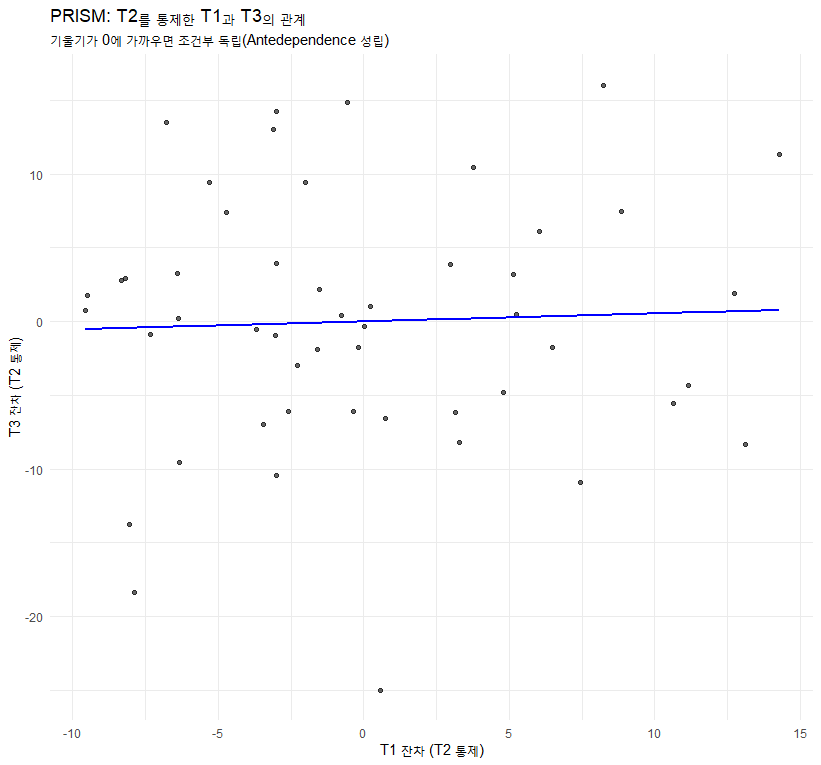
모델링을 하기 전에 눈으로 확인해야 합니다. 텍스트에서는 프로파일 도표(Profile Plot), OSM, PRISM을 추천합니다.
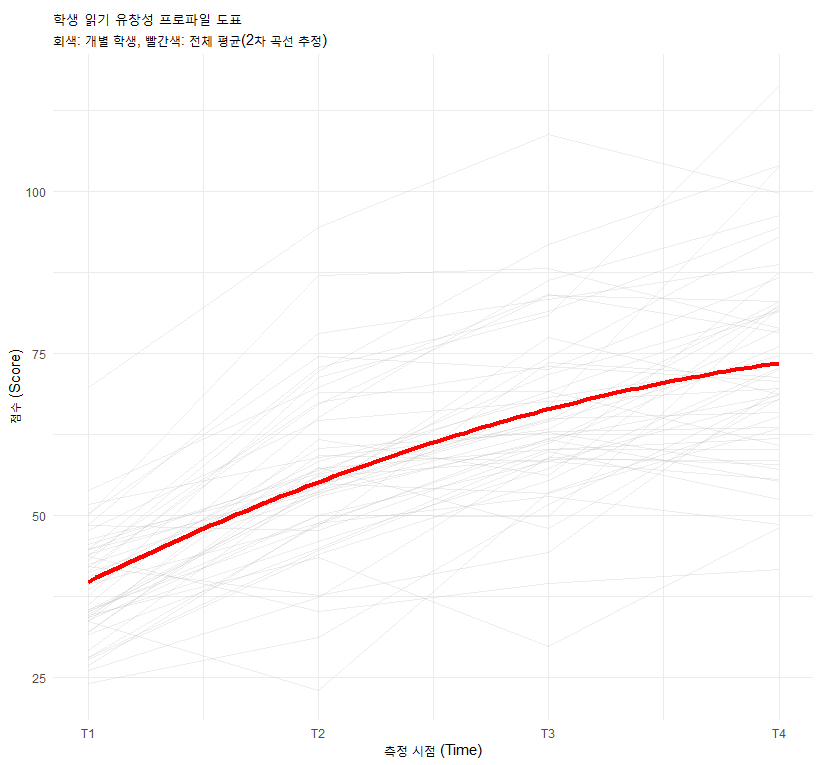
3.1 프로파일 도표 (Profile Plot)
학생 개개인의 성장 궤적을 그린 그래프입니다.
해석: 선들이 서로 꼬이지 않고 나란히 간다면? 학생 내 상관이 높음(잘하던 애가 계속 잘함).
분산: 시간이 갈수록 선들의 폭이 넓어진다면? 이분산성(Heterogeneity) 존재.
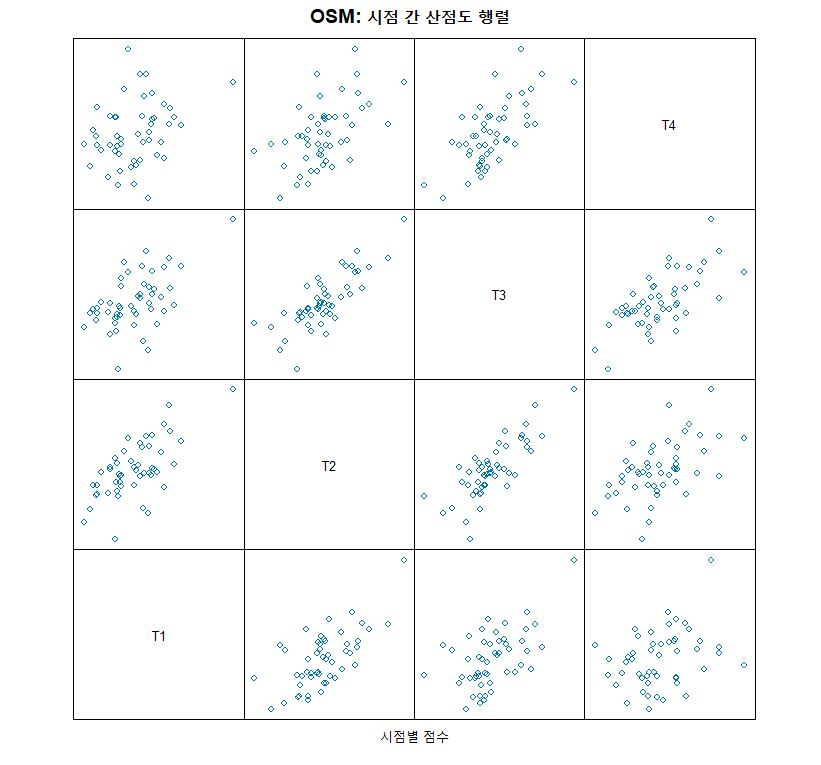
3.2 OSM (Ordinary Scatterplot Matrix)
모든 시점 간의 산점도 행렬입니다.
특징: 대각선에서 멀어질수록(시간 격차가 클수록) 상관관계가 어떻게 변하는지 보여줍니다. 읽기 데이터에서는 보통 시간이 지날수록(대각선에서 멀어질수록) 상관이 낮아지는 패턴을 보입니다.
오늘은 종단 자료 모델링(Longitudinal Data Modeling)에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 들어가며: 스냅샷이 아닌 영화처럼
우리가 흔히 접하는 연구는 특정 시점에 학생들의 성적을 조사하는 횡단 연구(Cross-sectional Study)가 많습니다. 이건 마치 학생들의 달리기 시합 중 한 순간을 찍은 ‘사진’과 같습니다. 하지만 교육은 변화의 과정입니다. 우리가 정말 알고 싶은 건 “철수가 지난 학기보다 얼마나 성장했는가?” 혹은 “새로운 독서 프로그램이 시간이 지날수록 효과가 커지는가?”입니다.
이처럼 한 개인(subject)에 대해 시간을 두고 반복적으로 측정한 데이터를 종단 자료(Longitudinal Data)라고 합니다.
왜 다층모형인가요?
종단 자료는 2수준 다층 구조의 특수한 형태입니다.
1수준 (Level 1): 시간(Time) 혹은 측정 시점 (예: 1학기, 2학기, 3학기…)
2수준 (Level 2): 개인 (Subject, 예: 학생)
일반적인 회귀분석을 쓰면 안 되나요? 안 됩니다. 한 학생이 여러 번 시험을 봤다면, 그 점수들끼리는 서로 관련(상관)이 있겠죠? “내 점수는 서로 독립적이지 않다”는 사실 때문에 일반 회귀분석의 가정(독립성)이 위배됩니다. 그래서 우리는 다층모형을 사용해야 합니다.
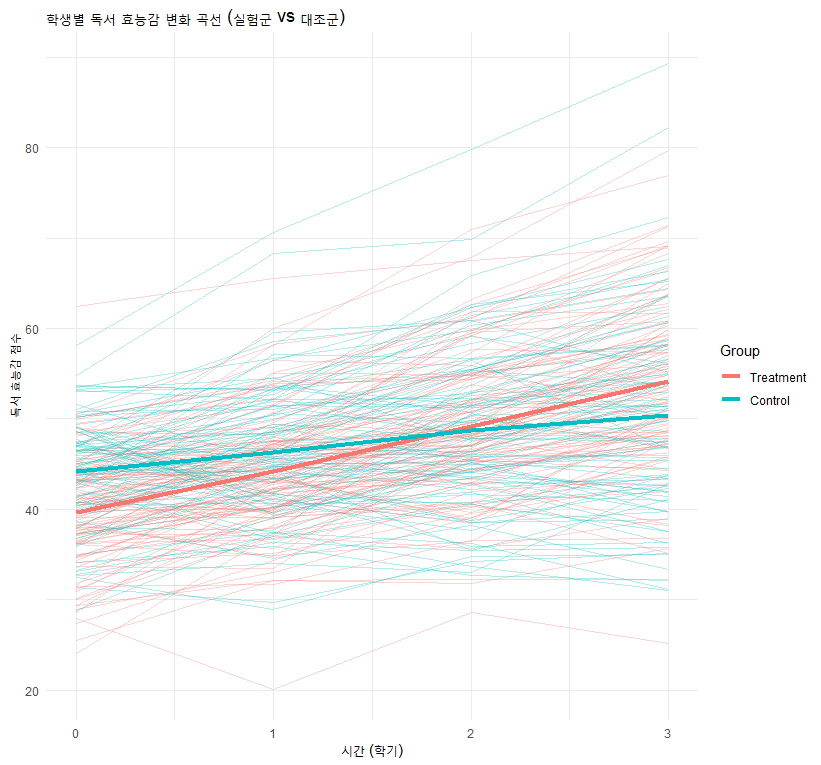
2. 시나리오 및 데이터 생성: “독서 자신감 프로젝트”
이론만 보면 지루하니 가상의 학교 데이터를 만들어보겠습니다.
[시나리오]
A 초등학교에서는 200명의 학생을 대상으로 ‘독서 효능감(Reading Self-Efficacy)’이 4학기 동안 어떻게 변하는지 추적했습니다.
Time (시간): 0(사전), 1(1학기 후), 2(2학기 후), 3(3학기 후)
Group (집단): 실험군(새로운 독서 프로그램), 대조군(기존 수업)
Outcome (종속변수): 독서 효능감 점수 (0~100점)
이제 R을 사용하여 이 시나리오에 맞는 데이터를 생성하겠습니다. (jamovi의 R Editor 모듈이나 RStudio에서 실행 가능합니다.)
R
# 데이터 생성 R 코드
set.seed(1234)
library(MASS)
library(lme4)
library(ggplot2)
# 1. 기본 설정
n_subjects <- 200
n_timepoints <- 4
time <- 0:3
# 2. 2수준(학생) 변수 생성
ids <- 1:n_subjects
group <- sample(c("Control", "Treatment"), n_subjects, replace = TRUE)
# 실험군은 초기치는 낮으나 성장률이 더 가파르도록 설정
intercept_mean <- ifelse(group == "Treatment", 40, 45)
slope_mean <- ifelse(group == "Treatment", 5, 2)
# 랜덤 효과 (개인별 차이): 절편과 기울기의 상관관계 설정
# 절편 분산=25, 기울기 분산=4, 상관계수=0.3
Sigma <- matrix(c(25, 3, 3, 4), 2, 2)
random_effects <- mvrnorm(n_subjects, mu = c(0, 0), Sigma = Sigma)
# 3. 데이터 프레임 만들기
data_long <- data.frame()
for(i in 1:n_subjects) {
# 개인별 고유한 절편과 기울기
b0i <- intercept_mean[i] + random_effects[i, 1]
b1i <- slope_mean[i] + random_effects[i, 2]
# 오차항 (1수준)
epsilon <- rnorm(n_timepoints, mean = 0, sd = 3)
# 종속변수 생성 (선형 성장 모형)
y <- b0i + b1i * time + epsilon
temp_df <- data.frame(
ID = factor(i),
Time = time,
Group = factor(group[i]),
Score = y
)
data_long <- rbind(data_long, temp_df)
}
# CSV로 저장 (jamovi에서 불러오기 위함)
# write.csv(data_long, "reading_growth.csv", row.names = FALSE)
# 데이터 확인
head(data_long)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data_long, "chap09.csv", row.names = FALSE)
“세상에는 사람 인구 수만큼의 언어가 있다.” 언어는 완벽히 통역하면서도 마음은 번역하지 못하는 사람들의 로맨스를 다룬 유쾌한 로맨스 코미디이다. 소통과 오역을 통해 진짜 마음의 언어를 찾아가는 감각적인 로맨틱 코미디이다. 보는 내내 즐거웠고, 한편한편의 영상이 예술일 정도로 해외 로케이션 촬영이 아름다웠다. 캐나다, 이탈리아는 더 늙기 전에 꼭 가봐야겠다.
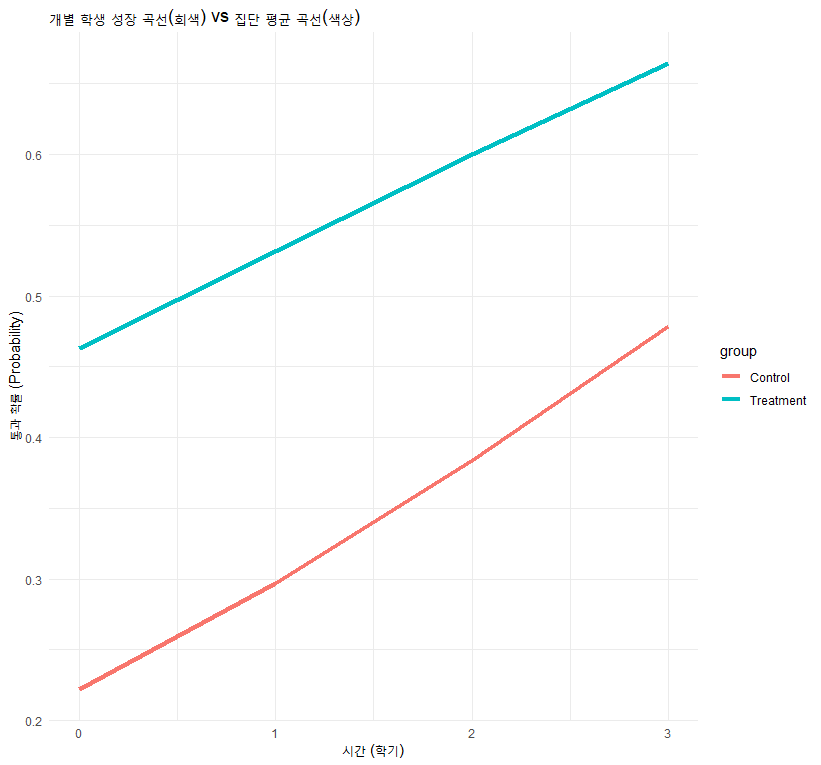
오히려, 주변(Marginal) 효과는 개별(Subject-specific) 효과보다 절댓값이 작게(완만하게) 나타납니다.
R로 시각화하여 이해하기
이 차이를 눈으로 확인해 봅시다. 개별 학생들의 곡선(회색)과 그 평균(빨간색, 파란색)을 그려보겠습니다.
R
# 시각화 코드
library(ggplot2)
# 예측값 생성 (개별 효과 포함)
# *주의: 실제 GLMM 예측은 복잡하지만, 여기서는 개념 설명을 위해 단순화하여 시각화합니다.
data_binary$pred_prob <- predict(glm(pass ~ time * group, data=data_binary, family=binomial), type="response")
# 그래프 그리기
ggplot(data_binary, aes(x = time, y = pred_prob, group = student_id)) +
# 개별 학생들의 성장 곡선 (회색, 얇게)
geom_line(alpha = 0.2, color = "gray") +
# 집단 평균 성장 곡선 (색상, 굵게)
# *변경사항: size = 1.5 -> linewidth = 1.5
stat_summary(aes(group = group, color = group), fun = mean, geom = "line", linewidth = 1.5) +
# 라벨 및 테마 설정
labs(title = "개별 학생 성장 곡선(회색) vs 집단 평균 곡선(색상)",
y = "통과 확률 (Probability)", x = "시간 (학기)") +
theme_minimal()
6. 결론
일반화 선형 혼합 모형(GLMM)은 현실 세계의 복잡한 데이터(O/X, 횟수 등)를 통계적으로 엄밀하게 다룰 수 있는 강력한 도구입니다.
데이터가 정규분포가 아닐 때(이항, 포아송 등) 사용합니다.
연결 함수(Link Function)를 통해 선형 예측식과 결과를 연결합니다.
개별 대상(Subject-specific)의 변화에 초점을 맞추므로, 전체 평균(Population-averaged) 해석 시 주의가 필요합니다.
학교 현장에서 “우리 반 아이들의 숙제 제출 여부”나 “문제 행동 횟수”를 종단적으로 연구하고 싶다면, GLMM이 가장 적합한 친구가 되어줄 것입니다.
참고문헌
Breslow, N. E., & Clayton, D. G. (1993). Approximate inference in generalized linear mixed models. Journal of the American Statistical Association, 88(421), 9-25.
Diggle, P. J., Heagerty, P., Liang, K. Y., & Zeger, S. L. (2002). Analysis of longitudinal data (2nd ed.). Oxford University Press.
Faught, E., Wilder, B. J., Ramsay, R. E., Reife, R. A., Kramer, L. D., Pledger, G. W., & Karim, R. M. (1996). Topiramate placebo-controlled dose-ranging trial in refractory partial epilepsy using 200-, 400-, and 600-mg daily dosages. Neurology, 46(6), 1684-1690.
Liang, K. Y., & Zeger, S. L. (1986). Longitudinal data analysis using generalized linear models. Biometrika, 73(1), 13-22.
Molenberghs, G., & Verbeke, G. (2005). Models for discrete longitudinal data. Springer.
Verbeke, G., & Molenberghs, G. (2000). Linear mixed models for longitudinal data. Springer.
Verbeke, G., & Molenberghs, G. (n.d.). Generalized Linear Mixed Models – Overview. In The SAGE Handbook of Multilevel Modeling (Chapter 8).