오늘은 비선형 혼합 효과 모델(Nonlinear Mixed Effects Models)에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 왜 ‘비선형(Nonlinear)’ 모델이 필요할까요?
우리가 흔히 쓰는 ‘선형 모델(Linear Models)’은 계산이 쉽고 해석이 명확하다는 장점이 있습니다. 하지만 학교 현장에서 일어나는 실제 현상들은 직선으로 설명되지 않는 경우가 훨씬 많습니다.
선형 모델(Empirical Models): 관찰된 데이터를 잘 설명하기 위해 직선을 긋는 ‘경험적 모델’입니다. 데이터 범위 안에서는 잘 맞을지 몰라도, 범위를 벗어나면 예측력이 떨어질 수 있습니다.
비선형 모델(Mechanistic/Scientific Models): 데이터가 왜 그렇게 만들어졌는지, 즉 ‘생성 메커니즘’에 집중하는 ‘과학적 모델’입니다. 성장 곡선이나 학습 속도처럼 자연스러운 변화 과정을 반영하므로, 데이터가 없는 구간에 대해서도 더 정확한 예측이 가능합니다.
비선형 모델의 장점:
실제 관계를 더 잘 근사합니다.
관찰 데이터 범위를 벗어난 값에 대해서도 더 신뢰할 수 있는 예측을 제공합니다.
파라미터(Parameter) 자체가 자연적인 물리적/교육적 의미를 갖습니다 (예: 학생의 최대 학습 잠재력, 학습 속도 등).
2. 학교 현장 스토리: “우리 아이들의 단어 암기량은 어떻게 변할까?”
초등학교 1학년 학생들이 매일 아침 10분씩 영어 단어를 외운다고 가정해 봅시다. 시간이 지날수록 외운 단어 수는 늘어나겠지만, 처음에는 천천히 늘다가 어느 순간 급격히 늘고, 결국 인간의 한계 때문에 정체기에 접어들 것입니다. 이러한 ‘S자 곡선(Logistic Curve)’은 직선인 선형 모델로는 설명할 수 없습니다.
[모의 데이터 생성 및 분석을 위한 R 코드]
먼저 학교 현장과 유사한 데이터를 만들어 보겠습니다.
R
# 필요한 라이브러리 로드
library(nlme)
library(ggplot2)
# 1. 모의 데이터 생성 (학생 50명, 10회 측정)
set.seed(123)
n_students <- 50
n_days <- 10
data <- data.frame(
student = rep(1:n_students, each = n_days),
day = rep(1:n_days, n_students)
)
# 비선형 파라미터 설정 (Asym: 최대 암기량, xmid: 가속 지점, scal: 증가 속도)
# 학생마다 개인차(Random Effects) 부여
asym_pop <- 100 # 평균 최대 암기량 100개
xmid_pop <- 5 # 평균 5일째에 급격히 상승
scal_pop <- 1 # 증가 기울기 계수
# 학생별 랜덤 효과 생성
random_effects <- rnorm(n_students, 0, 5)
# 로지스틱 성장 곡선 적용
data$word_count <- with(data, {
asym_i <- asym_pop + random_effects[student]
asym_i / (1 + exp((xmid_pop - day) / scal_pop)) + rnorm(nrow(data), 0, 2)
})
# 데이터 확인
head(data)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data, "chap13.csv", row.names = FALSE)
jamovi에서 비선형 혼합 모델을 직접 수행하려면 GAMLj 모듈이나 Rj Editor를 활용하는 것이 좋습니다. 기본 메뉴에 비선형 혼합 모델이 없을 경우, 다음과 같이 Rj Editor를 통해 분석합니다.
jamovi 분석 단계:
Library 설치: Rj - Editor에서 nlme 패키지를 호출합니다.
모델 설정: 학생별로 다른 성장 곡선을 갖도록 ‘혼합 효과(Mixed Effects)’를 설정합니다.
수식 입력:
# nlme 패키지를 이용한 비선형 혼합 모델 분석
library(nlme)
model <- nlme(word_count ~ SSlogis(day, Asym, xmid, scal),
data = data,
fixed = Asym + xmid + scal ~ 1,
random = Asym ~ 1 | student,
start = c(Asym = 100, xmid = 5, scal = 1))
summary(model)
# Asym: 학생이 도달할 수 있는 '최종 암기량' (상한선)
# xmid: 학습 효율이 최대가 되는 '시점'
# scal: 암기량이 증가하는 '가속도'
4. 결과 해석 및 시각화
분석 결과, 우리는 학생 전체의 평균적인 학습 곡선뿐만 아니라, 특정 학생이 다른 학생에 비해 얼마나 더 빨리 배우는지(xmid), 혹은 잠재력이 얼마나 큰지(Asym)를 개별적으로 파악할 수 있습니다.
R
# 시각화 코드
library(tidyverse)
ggplot(data, aes(x = day, y = word_count, group = student)) +
geom_line(alpha = 0.3, color = "blue") + # 개별 학생 곡선
stat_summary(aes(group = 1), fun = mean, geom = "line", size = 1.5, color = "red") + # 전체 평균
labs(title = "학생별 영어 단어 암기량 성장 곡선",
x = "학습 일수(Day)",
y = "암기한 단어 수") +
theme_minimal()
5. 주의할 점 (Limitations)
비선형 모델은 강력하지만 몇 가지 주의사항이 있습니다:
복잡성: 데이터 생성 메커니즘을 정확히 모르면 모델을 세우기 어렵습니다.
계산의 어려움: 선형 모델과 달리 반복적인 계산 과정이 필요하며, 때로는 수렴(Convergence)되지 않아 결과가 나오지 않을 수도 있습니다.
샘플 사이즈: 파라미터를 안정적으로 추정하기 위해 충분한 양의 데이터가 필요합니다.
6. 참고문헌 (APA Style)
Wu, L., & Liu, W. (2010). Nonlinear models. In J. J. Hox & J. K. Roberts (Eds.), The SAGE Handbook of Multilevel Modeling (pp. 249-266). SAGE Publications. +1
오늘은 “다층모형과 인과추론(Multilevel Models and Causal Inference)”에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 들어가며: 왜 다층모형인가?
전통적인 회귀분석은 모든 학생이 서로 독립적이라고 가정합니다. 하지만 교육 현장은 그렇지 않습니다. 같은 학교, 같은 반 학생들은 급훈, 담임 선생님, 학교 분위기 등을 공유합니다. 이를 위계적 구조(Hierarchical Structure) 또는 집단 의존성(Group Dependencies)이라고 합니다.
인과추론(Causal Inference)의 관점에서, 데이터가 이러한 계층 구조를 가질 때 다층모형(Multilevel Model)을 사용하는 것은 단순한 통계적 선호가 아니라, 편향(Bias)을 줄이고 정확한 표준오차를 추정하기 위한 필수 전략입니다.
2. 인과추론의 기초 개념과 교육적 예시
본격적인 분석에 앞서, 인과추론의 핵심 개념을 학교 상황에 빗대어 정의해 봅시다.
2.1 잠재적 결과 (Potential Outcomes)
어떤 학생 철수()가 있습니다.
: 철수가 ‘방과후 보충수업()’을 들었을 때의 성적
: 철수가 ‘방과후 보충수업()’을 듣지 않았을 때의 성적
인과 효과(Causal Effect)는 이 둘의 차이 입니다. 하지만 현실에서 우리는 철수가 수업을 듣거나, 듣지 않거나 둘 중 하나의 결과만 볼 수 있습니다. 이를 “인과추론의 근본적인 문제(Missing Data Problem)”라고 합니다.
2.2 SUTVA (Stable Unit Treatment Value Assumption)
이 가정은 “철수가 보충수업을 받았는지 여부가, 옆 짝꿍 영희의 성적에 영향을 주지 않아야 한다(상호간섭 없음)”는 것입니다.
문제점: 학교에서는 이 가정이 자주 깨집니다. 철수가 보충수업에서 배운 내용을 영희에게 알려줄 수 있기 때문입니다. 이를 해결하기 위해 집단(학교/학급) 단위 무선화가 권장되기도 합니다.
3. 연구 설계에 따른 다층모형 적용
3.1 무선화 실험 (Randomized Experiments)
가장 이상적인 상황입니다. 처치(Treatment)가 무작위로 배정되면, 평균적으로 두 집단은 성향이 비슷해집니다().
A. 개인 단위 무선배정 (학생별 제비뽑기)
학생들에게 무작위로 새로운 ‘독서 프로그램’을 배정했습니다. 하지만 학생들은 학교()라는 집단에 속해 있습니다. 학교마다 평균 독서 능력이 다를 수 있으므로, 이를 반영한 다층모형(Random Intercept Model)이 필요합니다.
: 번째 학교의 고유한 특성(학교 효과, 랜덤 절편)
: 독서 프로그램의 효과 (우리가 알고 싶은 값)
이 모형을 쓰면 학교 간 차이()를 통제하고 순수한 프로그램 효과()를 더 정밀하게 추정할 수 있습니다.
B. 집단 단위 무선배정 (학교별 제비뽑기)
교육 정책 연구에서는 흔히 “A학교는 실험군, B학교는 대조군”으로 배정합니다. 이를 군집 무선화(Cluster Randomized Experiments)라고 합니다.
이유: ‘학교 폭력 예방 캠페인’처럼 학교 전체 분위기를 바꾸는 처치는 학생 개인별로 쪼개서 적용할 수 없기 때문입니다.
분석: 처치 변수()가 학생 수준()이 아닌 학교 수준()에 들어갑니다.
3.2 관찰 연구 (Observational Studies)
현실적으로 무선 배정이 불가능할 때(예: 사립학교 진학 효과), 우리는 무시가능성(Ignorability) 가정을 도입합니다. 즉, “부모의 소득, 지능 등 공변량()이 같다면, 사립학교와 공립학교 학생은 비교 가능하다”고 가정하는 것입니다.
성향점수(Propensity Score) 활용: 다층 구조에서는 성향점수를 추정할 때도 다층모형을 사용하는 것이 좋습니다.
4. [실습] jamovi & R을 활용한 다층 인과 분석
이제 가상의 시나리오를 통해 실제 데이터를 생성하고 분석해 보겠습니다.
4.1 시나리오: “아침 독서 마라톤” 효과 분석
연구 배경: 경기도 교육청은 초등학생의 어휘력 향상을 위해 매일 아침 20분간 책을 읽는 ‘아침 독서 마라톤’ 프로그램을 개발했습니다.
연구 설계:
총 20개 학교, 학교당 30명의 학생(총 600명).
군집 무선화(Cluster RCT): 학교 단위로 제비뽑기를 하여 10개 학교는 ‘프로그램 시행(Treatment)’, 10개 학교는 ‘기존 자습(Control)’을 하도록 했습니다.
데이터 구조:
Level 1: 학생 (사후 어휘력 점수 score)
Level 2: 학교 (school_id)
처치: program (1=시행, 0=미시행)
4.2 R을 이용한 모의 데이터 생성
jamovi는 R 기반이므로, 아래 코드로 데이터를 생성하여 CSV로 저장한 뒤 jamovi에서 불러오면 됩니다.
R
# 필수 라이브러리 로드
library(lme4)
library(tidyverse)
set.seed(2026) # 재현성을 위한 시드 설정
# 1. 파라미터 설정
n_schools <- 20 # 학교 수
n_students <- 30 # 학교당 학생 수
n_total <- n_schools * n_students
# 2. 학교 수준 효과 (Level 2)
# 학교마다 평균 어휘력이 다름 (표준편차 5)
school_intercept <- rnorm(n_schools, mean = 0, sd = 5)
# 처치 배정 (학교 단위 무선화)
# 1~10번 학교: 통제군(0), 11~20번 학교: 실험군(1)
school_treatment <- c(rep(0, 10), rep(1, 10))
# 학교 데이터 프레임
school_data <- data.frame(
school_id = 1:n_schools,
school_eff = school_intercept,
program = school_treatment
)
# 3. 학생 수준 데이터 생성 (Level 1)
data <- data.frame(
student_id = 1:n_total,
school_id = rep(1:n_schools, each = n_students)
)
# 학교 정보 병합
data <- left_join(data, school_data, by = "school_id")
# 4. 결과 변수 생성 (어휘력 점수)
# 기본 점수 70점 + 프로그램 효과 8점 + 학교 효과 + 개인 오차(sd=8)
# y_ij = 70 + 8 * z_j + u_j + e_ij
data <- data %>%
mutate(
error = rnorm(n_total, mean = 0, sd = 8),
score = 70 + 8 * program + school_eff + error
)
# 팩터 변환
data$school_id <- as.factor(data$school_id)
data$program <- factor(data$program, levels = c(0, 1), labels = c("Control", "Treatment"))
# 데이터 확인
head(data)
이 데이터는 학교 간 차이(School Effect)가 존재하고, 처치가 학교 단위로 부여되었으므로 다층모형(Linear Mixed Model)을 사용해야 정확합니다.
Step 1: 데이터 탐색 및 시각화
분석 전에 데이터의 구조를 눈으로 확인해야 합니다.
jamovi 메뉴:Exploration > Descriptives
Variables에 score를 넣고, Split by에 program을 넣습니다.
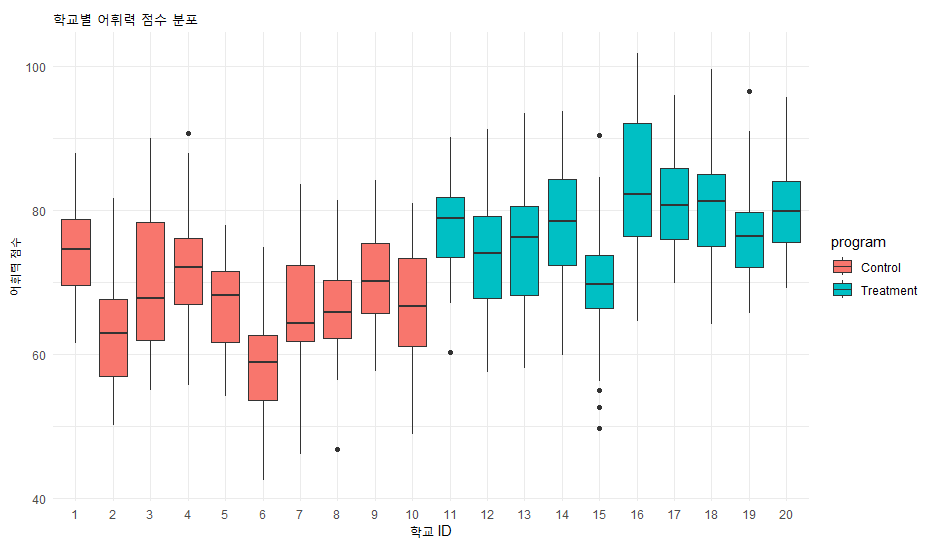
Box Plot: 학교별 차이를 보기 위해 Box plot을 체크하고, X축에 program을 둡니다. (※ jamovi 기본 기능으로는 학교별 boxplot을 한 번에 그리기 어려우므로 R 모듈인 seolmatrix나 scatr 모듈을 설치하여 시각화하면 좋습니다.)
[R 시각화 코드]
R
# 학교별 점수 분포 시각화
ggplot(data, aes(x = school_id, y = score, fill = program)) +
geom_boxplot() +
theme_minimal() +
labs(title = "학교별 어휘력 점수 분포", y = "어휘력 점수", x = "학교 ID")
해석: 상자 그림을 보면 같은 처치 집단 내에서도 학교마다 점수의 높낮이가 다름을 알 수 있습니다. 이것이 바로 (학교 효과)입니다.
Step 2: 다층모형 분석 (Linear Mixed Models)
모듈 선택: 상단 메뉴에서 Linear Models > Mixed Model을 클릭합니다. (보이지 않으면 jamovi Library에서 GAMLj 모듈을 설치하는 것을 강력 추천합니다. 여기서는 기본 Mixed Model 기준으로 설명합니다.)
변수 설정:
Dependent Variable (종속변수):score
Covariates (공변량) 또는 Factors:program (처치 변수)
Cluster (군집 변수):school_id
Random Effects (랜덤 효과) 설정:
왼쪽의 program을 오른쪽으로 옮기지 않고, Intercept만 Random Coefficients에 둡니다. (기본적으로 (Intercept | school_id)로 설정됨)
이는 학교마다 평균 점수(절편)가 다름을 허용하는 것입니다.
Fixed Effects (고정 효과) 설정:
program을 Model Terms에 넣습니다. 이것이 우리가 알고 싶은 ‘독서 마라톤 효과’입니다.
Step 3: 결과 해석
jamovi의 결과표(Estimates)는 다음과 유사하게 나옵니다.
Effect
Estimate
SE
t
p
Intercept
72.574
0.972
74.681
< .001
program (Treatment)
10.162
1.944
5.228
< .001
Fixed Effects:program의 Estimate가 약 10.162입니다. 즉, 독서 마라톤을 한 학교 학생들이 하지 않은 학교보다 평균적으로 약 10.162점 더 높은 어휘력을 보입니다. 이므로 통계적으로 유의합니다.
Random Components (Variance):
(School Intercept): 학교 간 분산. 이 값이 0보다 크다면 학교 효과가 존재한다는 뜻입니다.
ICC (Intraclass Correlation Coefficient): 전체 분산 중 학교가 설명하는 비율입니다.
5. 심화: 불응(Noncompliance)과 도구변수(IV)
실험을 했는데, 독서 프로그램을 하라고 배정받은 학교의 일부 학생이 땡땡이를 쳤다면(Noncompliance) 어떻게 될까요? 이때는 “배정된 상태()”를 도구변수(Instrument)로 사용하여, 실제 “참여한 상태()”의 효과를 추정해야 합니다.
jamovi/R 구현 (2단계 최소자승법 개념)
1단계: 실제 참여 여부()를 배정 여부()로 예측합니다.
2단계: 1단계에서 예측된 참여값()을 사용하여 점수()를 예측합니다.
이 분석은 jamovi의 sem (구조방정식) 모듈이나 R의 AER 패키지(ivreg)를 통해 수행할 수 있습니다. 중요한 건 배정()은 오직 참여()를 통해서만 결과()에 영향을 미쳐야 한다(배제 제한)는 가정입니다.
6. 결론
다층모형을 활용한 인과추론은 교육 현장과 같이 “집단 속에 개인이 속한 데이터”를 분석할 때 가장 강력한 도구입니다.
설계: 가능하다면 학교 단위 무선화(Cluster RCT)가 상호간섭(SUTVA 위배) 문제를 피하는 데 유리합니다.
분석: 단순히 평균을 비교하는 t-test 대신, 학교의 무선 절편(Random Intercept)을 포함한 혼합 모형을 사용해야 표준오차의 과소추정을 막을 수 있습니다.
해석: 결과는 “개인 수준의 효과”인지 “학교 수준의 효과”인지 명확히 구분하여 해석해야 합니다.
이 장의 내용이 여러분의 연구에 튼튼한 방법론적 기초가 되기를 바랍니다.
참고문헌 (APA Style)
Almond, D., Chay, K., & Lee, D. (2005). The costs of low birth weight. The Quarterly Journal of Economics, 120(3), 1031-1083.
Angrist, J. D., Imbens, G. W., & Rubin, D. B. (1996). Identification of causal effects using instrumental variables. Journal of the American Statistical Association, 91(434), 444-472.
Cornfield, J. (1978). Randomization by group: A formal analysis. American Journal of Epidemiology, 108(2), 100-102.
Gelman, A., & Hill, J. (2007). Data analysis using regression and multilevel/hierarchical models. Cambridge University Press.
Hill, J. (2013). Multilevel models and causal inference. In The SAGE Handbook of Multilevel Modeling (Chapter 12, pp. 201-219).
Hong, G., & Raudenbush, S. W. (2006). Evaluating kindergarten retention policy: A case study of causal inference for multilevel observational data. Journal of the American Statistical Association, 101(475), 901-910.
Kim, J., & Seltzer, M. (2007). Causal inference in multilevel settings in which selection processes vary across schools (Tech. Rep.). CRESST, UCLA.
Rubin, D. B. (1978). Bayesian inference for causal effects: The role of randomization. The Annals of Statistics, 6(1), 34-58.
Rubin, D. B. (1990). Formal modes of statistical inference for causal effects. Journal of Statistical Planning and Inference, 25(3), 279-292.
Slavin, R. E., Madden, N. A., Dolan, L. J., & Wasik, B. A. (1996). Every child, every school: Success for all. Corwin Press.
오늘은 “다층 연구 설계의 최적화(Sample Size and Power Analysis in Multilevel Designs)”에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 기반이 되는 R 코드를 함께 제시하여 ‘최적 표본 크기 산출’부터 ‘모의 데이터 생성’, 그리고 ‘분석’까지 완벽하게 구현해 드리겠습니다. (참고: jamovi는 데이터 분석에는 강력하지만, 연구 설계 단계의 복잡한 ‘최적 표본 산출’ 기능은 제한적이므로, 이 부분은 R의 수리적 계산 기능을 활용하고 분석은 jamovi의 혼합모형 논리로 설명하겠습니다.)
1. 서론: 연구자의 영원한 딜레마, “돈이냐, 정확성이냐?”
교육 연구를 진행할 때 우리는 항상 두 가지 제약 조건 사이에서 고민합니다.
통계적 검증력(Power): 효과가 있다면 있다고 말할 수 있는 힘 (높을수록 좋음).
예산(Budget): 연구비와 시간은 한정되어 있음.
이 장에서는 다층 모형(Multilevel Modeling) 상황, 즉 학생이 학교에 소속되어 있는 구조에서 어떻게 하면 가장 적은 비용으로 가장 높은 정확성을 얻을 수 있는지, 그 최적 설계(Optimal Design) 방법을 알려드리겠습니다.
우리의 가상 시나리오를 소개합니다.
[시나리오: 프로젝트 ‘독서왕’]
교육심리학자 김 교수는 새로운 독서 프로그램이 초등학생의 ‘문해력’을 높이는지 검증하려 합니다.
총 예산: 1,000만 원 (가상의 화폐 단위)
비용 구조:
학교 하나를 섭외하는 비용(행정 절차, 학교 보상 등): 200만 원 (c)
학생 한 명을 검사하는 비용(검사지, 간식 등): 10만 원 (s)
연구 질문: 몇 개의 학교를 섭외하고, 학교당 몇 명의 학생을 뽑아야 내 돈 1,000만 원 안에서 가장 정확한 결과를 얻을까요?
2. 군집 무작위 배정(Cluster Randomized Trial)의 설계
2.1 왜 다층 설계인가?
가장 쉬운 방법은 전국의 학생 명부에서 무작위로 학생을 뽑는 것입니다. 하지만 현실적으로 불가능합니다.
실행 가능성: 학교 단위로 프로그램을 돌려야 합니다.
오염(Contamination): 한 반에서 철수는 실험집단, 영희는 통제집단이면 서로 이야기하며 효과가 섞여버립니다.
그래서 우리는 학교(Cluster)를 통째로 실험군 혹은 대조군으로 배정하는 군집 무작위 배정(Cluster Randomized Trial)을 사용합니다.
2.2 급내상관계수(ICC)와 설계 효과
문제는 같은 학교 아이들끼리는 서로 비슷하다는 점입니다(학교 분위기, 선생님의 영향 등). 이를 급내상관계수(ICC, )라고 합니다.
ICC가 높다 = 학교 간 차이가 크다 = 같은 학교 아이들은 매우 비슷하다.
ICC가 높으면, 학생을 100명 더 뽑는 것보다 학교를 1개 더 섭외하는 게 훨씬 중요해집니다.
2.3 최적 표본 크기 공식 (The Magic Formula)
주어진 예산() 하에서 처치 효과()의 분산()을 최소화하는 최적의 학교 수()와 학교당 학생 수()는 다음과 같습니다.
: 학교당 비용 (200)
: 학생당 비용 (10)
: ICC (가정된 값, 보통 0.05~0.10)
이 공식을 보면, ICC()가 커질수록 학교당 학생 수()는 줄여야 합니다. 왜냐하면 같은 학교에서 많이 뽑아봤자 정보가 중복되기 때문입니다.
3. R과 jamovi를 활용한 최적 설계 및 데이터 생성
이제 김 교수의 ‘독서왕’ 프로젝트를 위해 R을 사용하여 최적 표본을 계산하고, 이를 분석할 수 있는 모의 데이터를 생성해 보겠습니다.
3.1 최적 표본 크기 계산 (R Code)
김 교수의 상황: 예산 10,000, , 그리고 ICC()는 선행연구를 통해 0.05로 가정합니다.
R
# [R Code] 최적 표본 크기 산출
# 파라미터 설정
B <- 10000 # 총 예산
c <- 200 # 학교(Cluster)당 비용
s <- 10 # 학생(Person)당 비용
rho <- 0.05 # 급내상관계수 (ICC)
# 1. 최적의 학생 수 (n) 계산 [cite: 120]
n_opt <- sqrt((c * (1 - rho)) / (s * rho))
# 2. 최적의 학교 수 (K) 계산 [cite: 119]
K_opt <- B / (c + s * n_opt)
# 결과 출력
cat("최적의 학교당 학생 수 (n):", round(n_opt, 2), "명\n")
cat("최적의 학교 수 (K):", round(K_opt, 2), "개교\n")
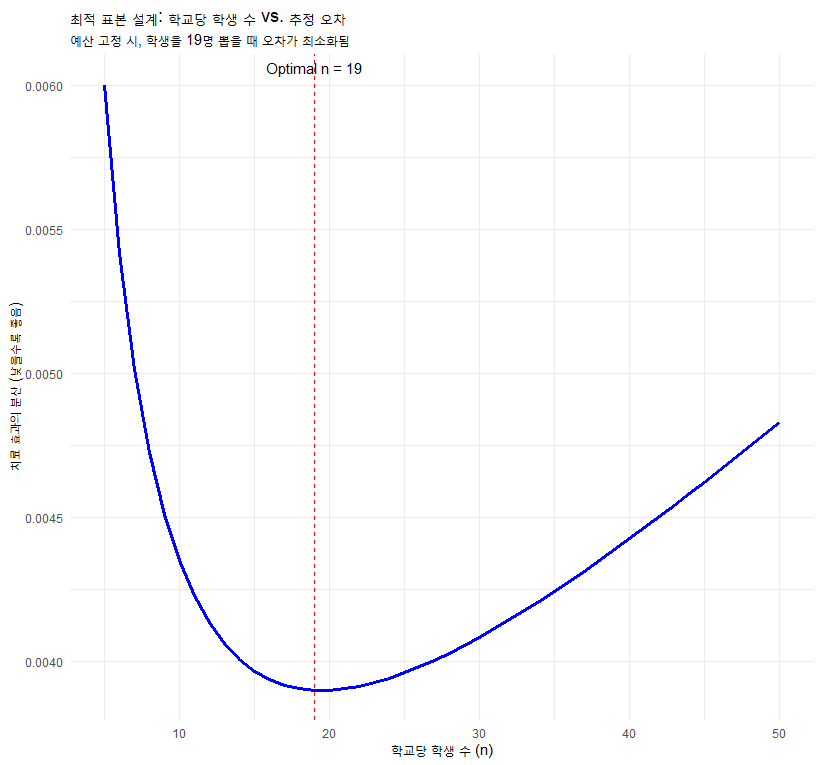
[분석 결과 해석]
계산 결과, , 가 나옵니다.
현실적으로 반올림하여 학교당 19명, 총 26개 학교(실험 13, 통제 13)를 섭외하는 것이 최적입니다.
3.2 비용 효율성 시각화 (Design Efficiency Plot)
아래 그래프는 학교당 학생 수()를 변화시킬 때, 추정의 오차(분산)가 어떻게 변하는지 보여줍니다. 우리는 분산이 가장 낮은 지점을 찾아야 합니다.
R
# [R Code] 시각화 생성
library(ggplot2)
n_seq <- seq(5, 50, by = 1) # 학생 수를 5명에서 50명까지 변화시킴
K_seq <- B / (c + s * n_seq) # 예산 제약에 따른 학교 수
# 분산 계산 공식 (단순화된 형태) [cite: 128]
# g_rho 부분과 예산 부분을 결합
design_var <- function(n, K, rho) {
# Standard Error calculation based on Eq 11.3 & 11.6 logic relation
# Here we look at relative variance proportional to the function
design_effect <- 1 + (n - 1) * rho
total_N <- n * K
return(design_effect / total_N)
}
var_values <- design_var(n_seq, K_seq, rho)
df_plot <- data.frame(n = n_seq, Variance = var_values)
ggplot(df_plot, aes(x = n, y = Variance)) +
geom_line(color = "blue", linewidth = 1.2) +
geom_vline(xintercept = 19, linetype = "dashed", color = "red") +
annotate("text", x = 19, y = max(var_values), label = "Optimal n = 19", vjust = -1) +
labs(title = "최적 표본 설계: 학교당 학생 수 vs. 추정 오차",
subtitle = "예산 고정 시, 학생을 19명 뽑을 때 오차가 최소화됨",
x = "학교당 학생 수 (n)", y = "치료 효과의 분산 (낮을수록 좋음)") +
theme_minimal()
이 그래프를 통해 김 교수는 무작정 학생을 많이 뽑는다고 좋은 게 아니라, 학교 수와 학생 수의 황금 비율을 맞춰야 함을 알 수 있습니다.
4. 모의 데이터 생성 및 분석 (Linear Mixed Model)
이제 최적 설계()에 따라 데이터를 수집했다고 가정하고, 이를 jamovi(또는 R의 lmer)에서 분석하는 방법을 보여드리겠습니다.
# [R Code] 모의 데이터 생성
set.seed(123) # 재현성을 위해 시드 설정
K <- 26 # 학교 수
n <- 19 # 학교당 학생 수
N <- K * n # 총 학생 수
# 학교 ID 및 치료 집단 배정 (0: 통제, 1: 처치)
school_id <- rep(1:K, each = n)
treatment <- rep(c(rep(0, K/2), rep(1, K/2)), each = n)
# 랜덤 효과 생성 (학교 간 차이)
u0j <- rep(rnorm(K, mean = 0, sd = sqrt(5)), each = n) # 학교 분산 = 5
# 오차항 생성 (학생 간 차이)
# ICC = 0.05 이려면, 학교분산/(학교분산+오차분산) = 0.05
# 5 / (5 + 95) = 0.05 -> 오차 분산은 95, SD는 약 9.75
eij <- rnorm(N, mean = 0, sd = sqrt(95))
# 고정 효과 (진짜 치료 효과 = 5점)
beta0 <- 50 # 평균 점수
beta1 <- 5 # 치료 효과
# 종속 변수 (문해력 점수) 생성
# y_ij = beta0 + beta1*x_j + u_0j + e_ij
y <- beta0 + beta1 * treatment + u0j + eij
# 데이터 프레임 생성
data_sim <- data.frame(
SchoolID = factor(school_id),
StudentID = 1:N,
Treatment = factor(treatment, labels = c("Control", "Program")),
Score = y
)
# 데이터 확인
head(data_sim)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data_sim, "chap11.csv", row.names = FALSE)
Random Effects:SchoolID의 Variance가 설계 시 가정한 분산과 유사한지 확인합니다.
5. 심화: 더 복잡한 상황들
5.1 다기관 임상시험 (Multisite Trials)
만약 김 교수가 학교 전체를 배정하는 게 아니라, 각 학교 안에서 철수는 실험반, 영희는 통제반으로 나눌 수 있다면 어떨까요?
이를 Multisite Trial이라고 합니다.
장점: 학교 효과()가 치료 효과 추정에서 사라지므로 훨씬 강력한 검증력(Power)을 가집니다.
설계: 이 경우 은 학교 분산에 영향을 받지 않으므로, 더 적은 예산으로도 유의한 결과를 얻을 수 있습니다. 하지만 ‘오염’ 문제가 없어야만 가능합니다.
5.2 반복 측정 (Longitudinal Design)
만약 김 교수가 프로그램을 1년 동안 진행하면서 학생들의 변화를 보고 싶다면 몇 번 측정해야 할까요?
선형 변화(직선 성장)를 가정할 때: 시작(Baseline)과 끝(End), 딱 2번 측정하거나, 중간 지점 하나를 추가하는 것이 비용 대비 가장 효율적입니다.
이차 함수(곡선 성장)를 가정할 때: 최소 3번의 측정이 필요하며, 등간격으로 측정하는 것이 좋습니다.
5.3 현실적인 문제와 해결책
ICC를 모를 때: 보통 문헌 연구를 통해 보수적으로(약간 높게) 잡습니다. ICC를 실제보다 절반 정도로 낮게 잘못 예측했더라도, 최적 설계 대비 효율성 손실은 약 10% 내외로 크지 않다는 연구가 있습니다.
학교 크기가 다를 때: 모든 학교가 19명일 수는 없습니다. 학교 간 크기 편차(CV)가 0.5 정도라면, 계산된 학교 수()보다 약 11% 정도 더 많은 학교를 섭외하여 이를 보정해야 합니다.
6. 결론 및 제언
오늘 살펴본 내용을 요약하면 다음과 같습니다.
학교 현장 연구에서는 학생 수만큼이나 학교 수(Cluster Number)가 중요하다.
비용 함수와 ICC를 고려하면, 무조건 많은 표본보다 최적의 비율을 찾는 것이 경제적이다.
학교를 통째로 배정(CRT)하는 것보다 학교 내 무선 배정(Multisite)이 통계적으로는 더 유리하나, 오염 가능성을 고려해야 한다.
참고문헌 (APA Style)
Maas, C. J. M., & Hox, J. J. (2005). Sufficient sample sizes for multilevel modeling. Methodology, 1(3), 86-92.
Moerbeek, M., & Teerenstra, S. (2011). Optimal design in multilevel experiments. In J. J. Hox & J. K. Roberts (Eds.), Handbook of Advanced Multilevel Analysis (pp. 257-281). New York: Routledge.
Raudenbush, S. W. (1997). Statistical analysis and optimal design for cluster randomized trials. Psychological Methods, 2(2), 173-185.
Snijders, T. A. B., & Bosker, R. J. (1993). Standard errors and sample sizes for two-level research. Journal of Educational Statistics, 18(3), 237-259.
Van Breukelen, G. J. P., & Moerbeek, M. (2013). Design considerations in multilevel studies. In M. A. Scott, J. S. Simonoff, & B. D. Marx (Eds.), The SAGE Handbook of Multilevel Modeling (pp. 183-200). SAGE Publications.
오늘은 개체 내 오차 구조(Within-Individual Error Structures)의 복잡성과 모델링에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
우리가 학교에서 학생들의 성장을 추적할 때(종단 연구), 단순히 “평균 점수가 올랐나?”만 보는 것은 반쪽짜리 분석입니다. 학생 개개인이 어떻게 변화하는지, 그 변화의 폭(분산)은 일정한지, 어제의 성적이 오늘의 성적에 얼마나 영향을 미치는지(상관)를 파악해야 합니다. 제공해주신 텍스트는 이러한 공분산 구조(Covariance Structure)를 어떻게 모델링할 것인가에 대한 깊이 있는 통찰을 제공합니다.
1. 교육 현장의 예시: “읽기 유창성 성장 프로젝트”
이해를 돕기 위해 가상의 시나리오를 설정하겠습니다.
상황: A 초등학교에서 3학년 학생 50명을 대상으로 ‘읽기 유창성(1분당 읽은 단어 수)’을 1년 동안 4회(3월, 6월, 9월, 12월) 측정했습니다.
핵심 질문:
모든 학생의 읽기 실력 격차(분산)는 3월이나 12월이나 똑같을까요? (등분산성)
3월 성적이 좋은 학생은 6월에도 좋을까요? 12월까지 그 영향이 갈까요? (계열 상관)
2. 기본 모델과 개념 (The General Model)
우리는 데이터를 다음의 선형 회귀 모델로 표현할 수 있습니다.
: 학생들의 읽기 점수 벡터
(고정 효과): 전체 학생들의 평균적인 성장 곡선 (예: 시간이 지날수록 점수가 오른다).
(임의 효과): 학생 개인별 특성 (예: 어떤 학생은 시작부터 잘하고, 어떤 학생은 성장 속도가 빠르다).
(오차 항): 설명되지 않는 나머지 변동. 오늘의 핵심 주제는 바로 이 의 구조인 를 파헤치는 것입니다.
3. 데이터 시각화와 진단 (Diagnostics)
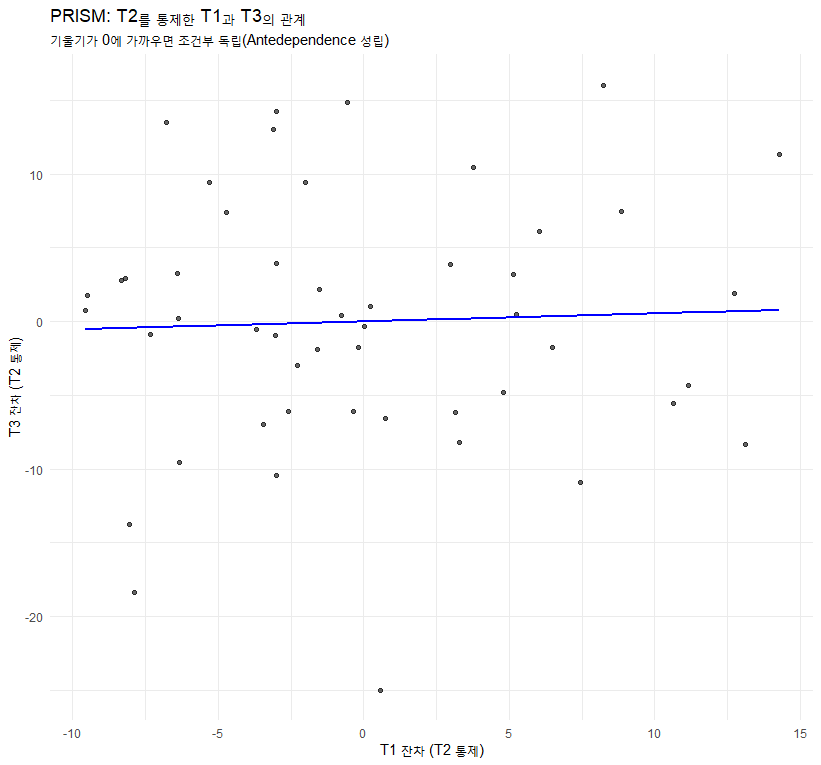
모델링을 하기 전에 눈으로 확인해야 합니다. 텍스트에서는 프로파일 도표(Profile Plot), OSM, PRISM을 추천합니다.
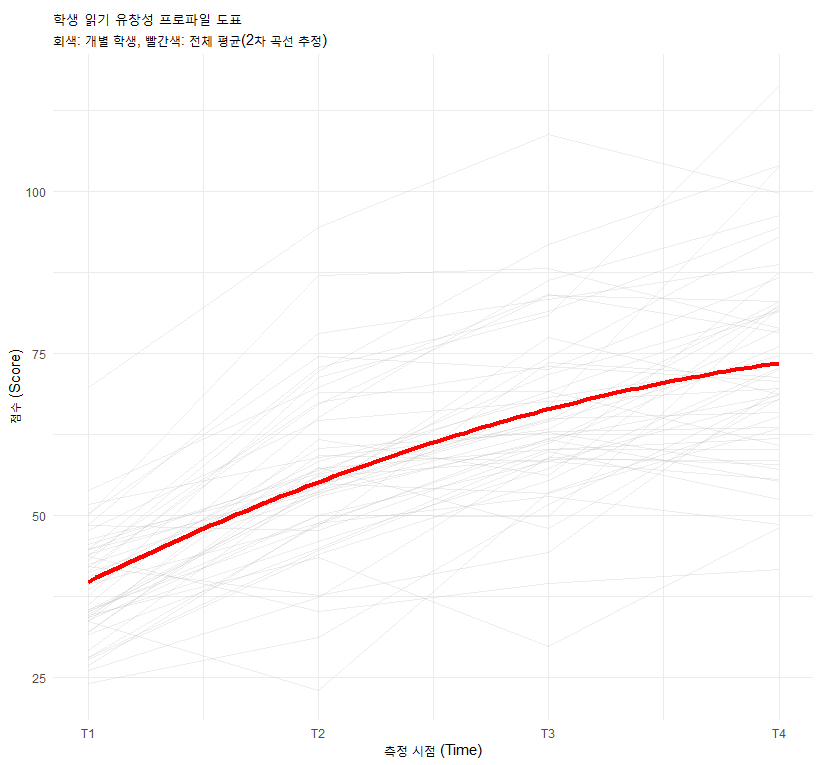
3.1 프로파일 도표 (Profile Plot)
학생 개개인의 성장 궤적을 그린 그래프입니다.
해석: 선들이 서로 꼬이지 않고 나란히 간다면? 학생 내 상관이 높음(잘하던 애가 계속 잘함).
분산: 시간이 갈수록 선들의 폭이 넓어진다면? 이분산성(Heterogeneity) 존재.
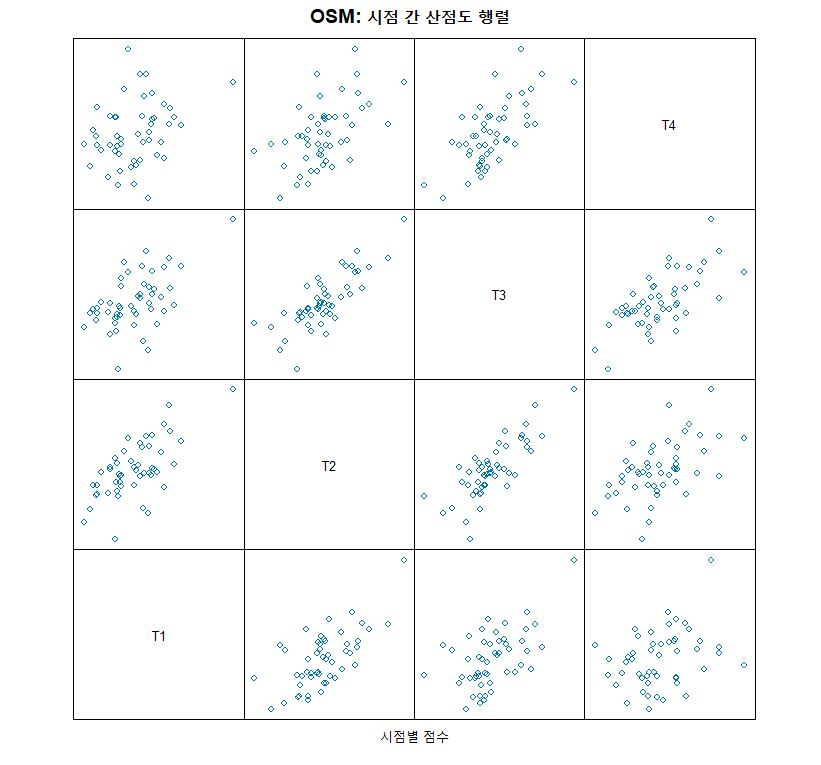
3.2 OSM (Ordinary Scatterplot Matrix)
모든 시점 간의 산점도 행렬입니다.
특징: 대각선에서 멀어질수록(시간 격차가 클수록) 상관관계가 어떻게 변하는지 보여줍니다. 읽기 데이터에서는 보통 시간이 지날수록(대각선에서 멀어질수록) 상관이 낮아지는 패턴을 보입니다.
오늘은 종단 자료 모델링(Longitudinal Data Modeling)에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 들어가며: 스냅샷이 아닌 영화처럼
우리가 흔히 접하는 연구는 특정 시점에 학생들의 성적을 조사하는 횡단 연구(Cross-sectional Study)가 많습니다. 이건 마치 학생들의 달리기 시합 중 한 순간을 찍은 ‘사진’과 같습니다. 하지만 교육은 변화의 과정입니다. 우리가 정말 알고 싶은 건 “철수가 지난 학기보다 얼마나 성장했는가?” 혹은 “새로운 독서 프로그램이 시간이 지날수록 효과가 커지는가?”입니다.
이처럼 한 개인(subject)에 대해 시간을 두고 반복적으로 측정한 데이터를 종단 자료(Longitudinal Data)라고 합니다.
왜 다층모형인가요?
종단 자료는 2수준 다층 구조의 특수한 형태입니다.
1수준 (Level 1): 시간(Time) 혹은 측정 시점 (예: 1학기, 2학기, 3학기…)
2수준 (Level 2): 개인 (Subject, 예: 학생)
일반적인 회귀분석을 쓰면 안 되나요? 안 됩니다. 한 학생이 여러 번 시험을 봤다면, 그 점수들끼리는 서로 관련(상관)이 있겠죠? “내 점수는 서로 독립적이지 않다”는 사실 때문에 일반 회귀분석의 가정(독립성)이 위배됩니다. 그래서 우리는 다층모형을 사용해야 합니다.
2. 시나리오 및 데이터 생성: “독서 자신감 프로젝트”
이론만 보면 지루하니 가상의 학교 데이터를 만들어보겠습니다.
[시나리오]
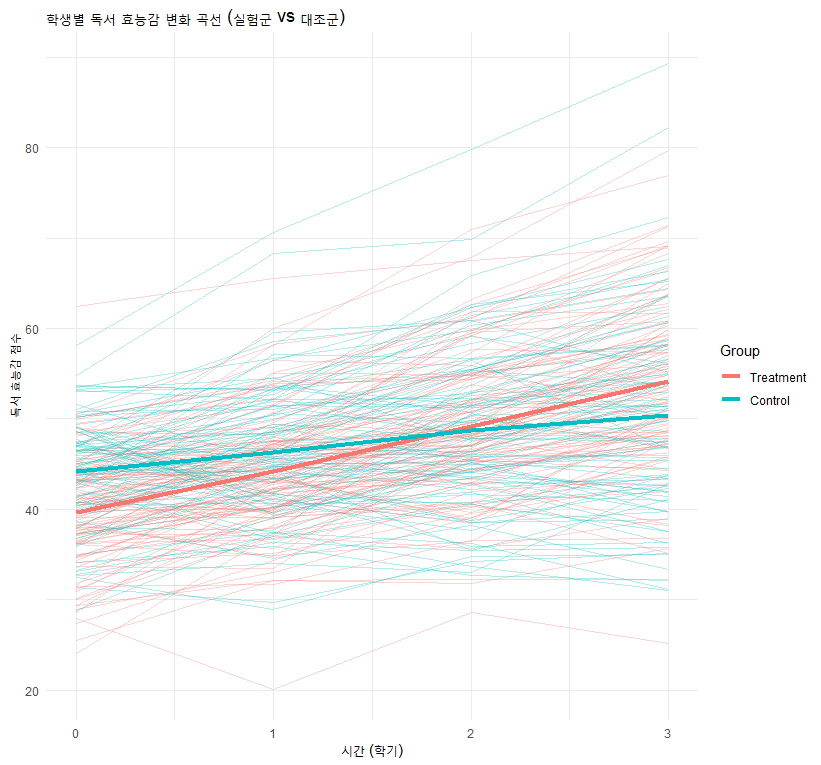
A 초등학교에서는 200명의 학생을 대상으로 ‘독서 효능감(Reading Self-Efficacy)’이 4학기 동안 어떻게 변하는지 추적했습니다.
Time (시간): 0(사전), 1(1학기 후), 2(2학기 후), 3(3학기 후)
Group (집단): 실험군(새로운 독서 프로그램), 대조군(기존 수업)
Outcome (종속변수): 독서 효능감 점수 (0~100점)
이제 R을 사용하여 이 시나리오에 맞는 데이터를 생성하겠습니다. (jamovi의 R Editor 모듈이나 RStudio에서 실행 가능합니다.)
R
# 데이터 생성 R 코드
set.seed(1234)
library(MASS)
library(lme4)
library(ggplot2)
# 1. 기본 설정
n_subjects <- 200
n_timepoints <- 4
time <- 0:3
# 2. 2수준(학생) 변수 생성
ids <- 1:n_subjects
group <- sample(c("Control", "Treatment"), n_subjects, replace = TRUE)
# 실험군은 초기치는 낮으나 성장률이 더 가파르도록 설정
intercept_mean <- ifelse(group == "Treatment", 40, 45)
slope_mean <- ifelse(group == "Treatment", 5, 2)
# 랜덤 효과 (개인별 차이): 절편과 기울기의 상관관계 설정
# 절편 분산=25, 기울기 분산=4, 상관계수=0.3
Sigma <- matrix(c(25, 3, 3, 4), 2, 2)
random_effects <- mvrnorm(n_subjects, mu = c(0, 0), Sigma = Sigma)
# 3. 데이터 프레임 만들기
data_long <- data.frame()
for(i in 1:n_subjects) {
# 개인별 고유한 절편과 기울기
b0i <- intercept_mean[i] + random_effects[i, 1]
b1i <- slope_mean[i] + random_effects[i, 2]
# 오차항 (1수준)
epsilon <- rnorm(n_timepoints, mean = 0, sd = 3)
# 종속변수 생성 (선형 성장 모형)
y <- b0i + b1i * time + epsilon
temp_df <- data.frame(
ID = factor(i),
Time = time,
Group = factor(group[i]),
Score = y
)
data_long <- rbind(data_long, temp_df)
}
# CSV로 저장 (jamovi에서 불러오기 위함)
# write.csv(data_long, "reading_growth.csv", row.names = FALSE)
# 데이터 확인
head(data_long)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data_long, "chap09.csv", row.names = FALSE)
오히려, 주변(Marginal) 효과는 개별(Subject-specific) 효과보다 절댓값이 작게(완만하게) 나타납니다.
R로 시각화하여 이해하기
이 차이를 눈으로 확인해 봅시다. 개별 학생들의 곡선(회색)과 그 평균(빨간색, 파란색)을 그려보겠습니다.
R
# 시각화 코드
library(ggplot2)
# 예측값 생성 (개별 효과 포함)
# *주의: 실제 GLMM 예측은 복잡하지만, 여기서는 개념 설명을 위해 단순화하여 시각화합니다.
data_binary$pred_prob <- predict(glm(pass ~ time * group, data=data_binary, family=binomial), type="response")
# 그래프 그리기
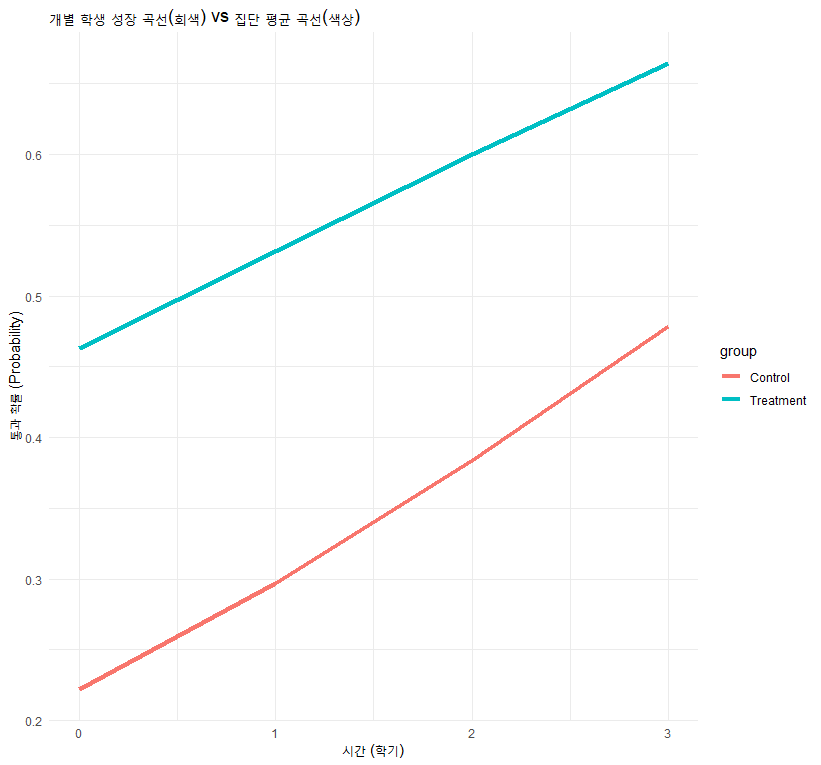
ggplot(data_binary, aes(x = time, y = pred_prob, group = student_id)) +
# 개별 학생들의 성장 곡선 (회색, 얇게)
geom_line(alpha = 0.2, color = "gray") +
# 집단 평균 성장 곡선 (색상, 굵게)
# *변경사항: size = 1.5 -> linewidth = 1.5
stat_summary(aes(group = group, color = group), fun = mean, geom = "line", linewidth = 1.5) +
# 라벨 및 테마 설정
labs(title = "개별 학생 성장 곡선(회색) vs 집단 평균 곡선(색상)",
y = "통과 확률 (Probability)", x = "시간 (학기)") +
theme_minimal()
6. 결론
일반화 선형 혼합 모형(GLMM)은 현실 세계의 복잡한 데이터(O/X, 횟수 등)를 통계적으로 엄밀하게 다룰 수 있는 강력한 도구입니다.
데이터가 정규분포가 아닐 때(이항, 포아송 등) 사용합니다.
연결 함수(Link Function)를 통해 선형 예측식과 결과를 연결합니다.
개별 대상(Subject-specific)의 변화에 초점을 맞추므로, 전체 평균(Population-averaged) 해석 시 주의가 필요합니다.
학교 현장에서 “우리 반 아이들의 숙제 제출 여부”나 “문제 행동 횟수”를 종단적으로 연구하고 싶다면, GLMM이 가장 적합한 친구가 되어줄 것입니다.
참고문헌
Breslow, N. E., & Clayton, D. G. (1993). Approximate inference in generalized linear mixed models. Journal of the American Statistical Association, 88(421), 9-25.
Diggle, P. J., Heagerty, P., Liang, K. Y., & Zeger, S. L. (2002). Analysis of longitudinal data (2nd ed.). Oxford University Press.
Faught, E., Wilder, B. J., Ramsay, R. E., Reife, R. A., Kramer, L. D., Pledger, G. W., & Karim, R. M. (1996). Topiramate placebo-controlled dose-ranging trial in refractory partial epilepsy using 200-, 400-, and 600-mg daily dosages. Neurology, 46(6), 1684-1690.
Liang, K. Y., & Zeger, S. L. (1986). Longitudinal data analysis using generalized linear models. Biometrika, 73(1), 13-22.
Molenberghs, G., & Verbeke, G. (2005). Models for discrete longitudinal data. Springer.
Verbeke, G., & Molenberghs, G. (2000). Linear mixed models for longitudinal data. Springer.
Verbeke, G., & Molenberghs, G. (n.d.). Generalized Linear Mixed Models – Overview. In The SAGE Handbook of Multilevel Modeling (Chapter 8).
오늘은 “다층모형(Multilevel Model)에서의 모형 선택(Model Selection)”에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 서론: 완벽한 옷을 고르는 법 (모형 선택의 딜레마)
여러분이 백화점에서 옷을 고른다고 상상해 보세요. 너무 큰 옷은 헐렁해서 보기가 싫고(과소적합, underfitting), 너무 꽉 끼는 옷은 숨쉬기가 힘듭니다(과적합, overfitting). 통계 모형을 선택하는 것도 이와 같습니다. 우리는 데이터를 가장 잘 설명하면서도, 불필요하게 복잡하지 않은 ‘최적의 모형’을 찾아야 합니다.
일반적인 회귀분석(OLS)에서는 나 수정된 같은 명확한 기준이 있습니다. 하지만 다층모형(MLM)으로 넘어오면 상황이 훨씬 복잡해집니다. 데이터가 여러 층위(예: 학생-학급-학교)로 꼬여 있기 때문에 “설명력”을 정의하는 방식도 달라지고, 모형의 적합도를 판단하는 기준(AIC, BIC 등)도 어떤 ‘우도(Likelihood)’를 쓰느냐에 따라 달라지기 때문입니다.
이 글에서는 Russell Steele 교수의 논의를 바탕으로, 학교 데이터를 사용하여 이 복잡한 기준들을 명쾌하게 정리해 드리겠습니다.
2. 예제 데이터 생성: “햇살초등학교의 수학 성취도”
이론만 들으면 지루하니, 가상의 시나리오를 만들어 봅시다.
2.1 시나리오
연구 대상: 햇살초등학교 6학년 학생 1,000명 (50개 학급).
종속 변수(): 수학 성취도 (Math Score).
1수준 변수(학생): 사교육 시간 (Private Education, ).
2수준 변수(학급): 담임 선생님의 열정 (Teacher Passion, ).
가설: 사교육 시간이 길수록 수학 점수가 높을 것이며, 이 관계는 담임 선생님의 열정에 따라 달라질 것이다(교차 수준 상호작용).
2.2 R을 이용한 모의 데이터 생성 (jamovi의 Rj Editor에서도 실행 가능)
R
set.seed(1234)
# 1. 파라미터 설정
n_classes <- 50 # 학급 수 (J)
n_students_per_class <- 20 # 학급당 학생 수 (n)
N <- n_classes * n_students_per_class
# 2. 2수준(학급) 변수 생성
class_id <- rep(1:n_classes, each = n_students_per_class)
teacher_passion <- rnorm(n_classes, mean = 50, sd = 10) # 교사 열정
u0 <- rnorm(n_classes, 0, 5) # 절편에 대한 랜덤 효과 (학교 간 차이)
u1 <- rnorm(n_classes, 0, 2) # 기울기에 대한 랜덤 효과 (효과의 차이)
# 3. 1수준(학생) 변수 생성
private_edu <- rnorm(N, mean = 5, sd = 2) # 사교육 시간
error <- rnorm(N, 0, 5) # 잔차
# 4. 데이터 프레임 생성 (계층적 구조 반영)
# 수식: Math = (50 + u0) + (2 + 0.1*Passion + u1)*Private + error
# 교사 열정이 높으면 사교육의 효과가 더 커진다고 가정 (상호작용)
intercept <- 40 + u0[class_id]
slope <- 2 + 0.1 * (teacher_passion[class_id] - 50) + u1[class_id]
math_score <- intercept + slope * private_edu + error
data <- data.frame(
ClassID = factor(class_id),
StudentID = 1:N,
MathScore = math_score,
PrivateEdu = private_edu,
TeacherPassion = rep(teacher_passion, each = n_students_per_class)
)
head(data)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data, "chap07.csv", row.names = FALSE)
일반 회귀분석에서 는 “전체 변동 중 모형이 설명하는 비율”입니다. 하지만 다층모형에서는 변동이 학생 수준(Level 1)과 학급 수준(Level 2)으로 나뉩니다. 따라서 도 수준별로 따로 계산해야 합니다.
3.1 Snijders & Bosker (SB)
Snijders와 Bosker(1994)는 “예측 오차의 감소(reduction in prediction error)”라는 관점에서 를 정의했습니다.
1수준 (): 개별 학생의 점수를 얼마나 잘 예측하는가?
계산식에는 고정 효과(Fixed effects)뿐만 아니라 랜덤 효과(Random effects)의 분산도 포함됩니다.
기준 모델(Null Model)은 아무런 설명 변수가 없는 모델(절편만 있는 모델)입니다.
2수준 (): 학급 평균 점수를 얼마나 잘 예측하는가?
학급 수준의 설명력을 볼 때 사용합니다.
3.2 Edwards et al. ()
Edwards 등(2008)은 Wald F-통계량을 이용하여 를 계산하는 방식을 제안했습니다.
이 방법은 특정한 고정 효과(Fixed Effect)가 추가됨으로써 설명력이 얼마나 늘었는지를 보는 데 유용합니다.
분모의 자유도를 계산할 때 Kenward-Roger 근사를 사용하는 것이 권장됩니다.
[WaurimaL의 조언]
는 모형이 복잡해질 때(랜덤 효과 추가 등) 값이 오히려 줄어드는 경우가 있어 해석에 주의가 필요합니다. 반면 는 고정 효과의 설명력을 분리해서 보는 데 강점이 있습니다.
4. 정보 기준(Information Criteria): AIC와 BIC
모형의 적합도(Likelihood)와 간명성(Parsimony, 변수가 적을수록 좋음) 사이의 균형을 맞추는 지표입니다.
4.1 기본 개념
Deviance (이탈도): 모형이 데이터를 얼마나 잘 설명 못하는가? (낮을수록 좋음).
AIC (Akaike Information Criterion): 예측 정확도를 높이는 데 초점. 실제 모형이 후보군에 없어도 가장 근사한 모형을 찾음.
(: 파라미터 수)
BIC (Bayesian Information Criterion): ‘진짜 모형(True Model)’을 찾는 데 초점. 표본 크기()가 커질수록 페널티가 강해져서 더 단순한 모형을 선호함.
4.2 다층모형에서의 난제: 어떤 Likelihood를 쓸 것인가?
다층모형에서는 우도(Likelihood)를 계산하는 방식이 크게 두 가지로 나뉩니다. 이 부분이 가장 헷갈리는 부분이니 집중해 주세요.
(1) Marginal Likelihood (주변 우도) vs. Conditional Likelihood (조건부 우도)
Marginal Likelihood (): 랜덤 효과()를 적분해서 없애버린 우도입니다. “전체 모집단(평균적인 학생)”에 대한 추론을 할 때 사용합니다.
Conditional Likelihood (): 랜덤 효과()를 특정한 값으로 조건화한 우도입니다. “특정 학급(Cluster)”에 대한 예측을 할 때 사용합니다.
Vaida & Blanchard(2005)는 이를 바탕으로 Conditional AIC (cAIC)를 제안했습니다.
(2) ML vs. REML
ML (Maximum Likelihood): 고정 효과를 비교할 때 주로 사용합니다. 하지만 분산 성분(Variance Component)을 과소추정하는 경향이 있습니다.
REML (Restricted ML): 분산 성분을 정확하게 추정합니다. 하지만 고정 효과 구조가 다른 모델끼리 비교할 때는 사용하면 안 됩니다 (예: 변수 A가 있는 모델 vs 없는 모델 비교 시 사용 불가).
예외: Gurka(2006) 같은 학자는 베이지안 관점에서 비교하기도 하지만, 일반적인 관례는 아닙니다.
5. 분석 실습: jamovi & R
이제 위에서 생성한 데이터를 바탕으로 세 가지 모형을 비교해 보겠습니다.
Model A (Null Model): 설명변수 없음. (학교 간 차이만 확인)
Model B (Random Intercept): 사교육 시간()과 교사 열정() 포함. (절편만 무작위)
Model C (Random Slope): 사교육 시간()의 효과가 학급마다 다름을 허용. (기울기도 무작위)
5.1 분석 전략
도구: jamovi의 GAMLj 모듈 또는 Linear Mixed Models (기본). 여기서는 상세한 와 IC 계산을 위해 R 코드를 활용합니다.
절차:
Null Model로 급내상관계수(ICC) 확인.
Model B 적합 후 및 AIC/BIC 확인.
Model C 적합 후 Model B와 비교 (LRT 및 정보 기준).
5.2 R 코드 구현 (분석 및 결과 비교)
R
library(lme4)
library(performance) # R2 및 IC 계산을 위한 패키지
library(MuMIn) # r.squaredGLMM 등
# 1. Model A: Null Model
model_a <- lmer(MathScore ~ 1 + (1 | ClassID), data = data, REML = FALSE)
# 2. Model B: Random Intercept Model (고정효과 추가)
model_b <- lmer(MathScore ~ PrivateEdu + TeacherPassion + (1 | ClassID),
data = data, REML = FALSE)
# 3. Model C: Random Slope Model (상호작용 및 랜덤 기울기 추가)
model_c <- lmer(MathScore ~ PrivateEdu * TeacherPassion + (PrivateEdu | ClassID),
data = data, REML = FALSE)
# 4. 모형 비교 (AIC, BIC, Log-likelihood)
comparison <- compare_performance(model_a, model_b, model_c, metrics = c("AIC", "BIC", "R2"))
print(comparison)
# 5. Snijders & Bosker R2 계산 (MuMIn 패키지 활용)
r2_results <- r.squaredGLMM(model_c)
print(r2_results)
5.3 결과 해석 (가상의 결과값 예시)
Criteria
Model A (Null)
Model B (Rand. Int)
Model C (Rand. Slope + Interaction)
AIC
6982.3(<.001)
6788.0(<.001)
6389.9(>.999)
BIC
6997.0(<.001)
6812.5(<.001)
6429.2(>.999)
Marginal
0.000
0.169
0.205
Conditional
0.729
0.777
0.861
해석:
AIC/BIC: Model C가 가장 낮은 값을 가지므로, “교사의 열정이 사교육 효과를 조절하며, 학급별로 사교육 효과가 다르다”는 모형이 가장 적합합니다. (AIC가 2 이상 차이 나면 유의미한 차이로 봅니다).
: Conditional 가 0.861이라는 것은, 고정 변수와 학급별 랜덤 효과를 모두 고려했을 때 학생들의 성적 변동을 86.1% 설명한다는 뜻입니다.
6. 시각화: 복잡한 수식 대신 그림으로
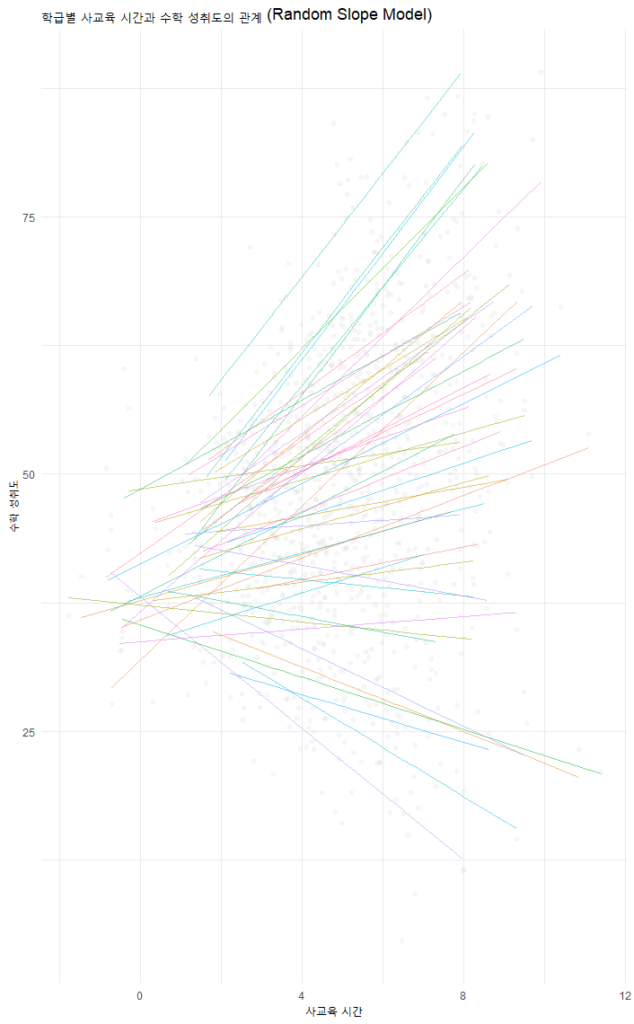
다층모형의 꽃은 시각화입니다. 학급별로 기울기가 다른 것을 보여주는 것이 Model C의 핵심입니다.
R
library(ggplot2)
# 예측값 생성
data$pred <- predict(model_c)
# 시각화
ggplot(data, aes(x = PrivateEdu, y = MathScore, group = ClassID)) +
geom_point(alpha = 0.1, color = "gray") + # 전체 데이터 점
geom_line(aes(y = pred, color = ClassID), alpha = 0.5) + # 학급별 회귀선
theme_minimal() +
theme(legend.position = "none") +
labs(title = "학급별 사교육 시간과 수학 성취도의 관계 (Random Slope Model)",
x = "사교육 시간", y = "수학 성취도")
이 그래프를 보면, 어떤 반은 사교육 효과가 가파르고(기울기 급함), 어떤 반은 완만하다는 것을 한눈에 알 수 있습니다. 이것이 바로 Random Slope(랜덤 기울기)의 의미입니다.
7. 결론 및 제언
Steele 교수의 챕터 내용을 종합하면, 다층모형에서의 모형 선택은 다음과 같은 원칙을 따릅니다.
하나의 기준에 맹신하지 마세요. , AIC, BIC, 그리고 이론적 배경을 모두 고려해야 합니다.
연구 목적에 맞는 Likelihood를 선택하세요.
새로운 학교에 일반화하고 싶다면? → Marginal Likelihood (AIC)
특정 학급 내 학생을 예측하고 싶다면? → Conditional Likelihood (cAIC).
고정 효과 비교 시에는 ML, 최종 파라미터 추정은 REML을 사용하는 것이 정석입니다.
단순히 수치적으로 우수한 모델보다, “해석 가능하고(interpretable)” 실제 교육 현장의 현상을 잘 설명하는 모델을 선택하는 것이 중요합니다.
[참고 문헌]
Akaike, H. (1973). Information theory and an extension of the maximum likelihood principle. In Second International Symposium on Information Theory (pp. 267–281). Springer Verlag.
Burnham, K. P., & Anderson, D. R. (2002). Model selection and multimodel inference: A practical information-theoretic approach. Springer.
Edwards, L. J., Muller, K. E., Wolfinger, R. D., Qaqish, B. F., & Schabenberger, O. (2008). An statistic for fixed effects in the linear mixed model. Statistics in Medicine, 27, 6137–6157.
Gurka, M. J. (2006). Selecting the best linear mixed model under REML. The American Statistician, 60, 19–26.
Snijders, T. A. B., & Bosker, R. J. (1994). Modeled variance in two-level models. Sociological Methods and Research, 22, 342–363.
Steele, R. (2013). Model selection for multilevel models. In The SAGE Handbook of Multilevel Modeling (Chapter 7).
Vaida, F., & Blanchard, S. (2005). Conditional Akaike information for mixed-effects models. Biometrika, 92, 351–370.
오늘은 다층모형(Multilevel Modeling) 분석의 핵심이면서도 많은 연구자가 가장 헷갈려 하는 주제, 바로 “예측변수의 중심화(Centering Predictors)”와 “맥락 효과(Contextual Effects)”에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 초등학생도 이해할 수 있는 직관적인 설명과 대학원 수준의 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 다층분석 여행을 위한 시나리오: “수학 불안”과 “학업 성취”
자, 우리가 교육청의 의뢰를 받은 연구자라고 상상해 봅시다. 우리는 ‘수학 불안(Math Anxiety)’이 ‘수학 문제 해결력(Math Problem Solving)’에 미치는 영향을 알고 싶습니다.
데이터 구조: 학생()들이 학교()에 소속된 2수준(2-level) 구조입니다.
변수:
(종속변수): 수학 문제 해결력 점수
(독립변수): 수학 불안 점수 (높을수록 불안함)
단순 회귀분석과 달리, 다층모형에서는 이 (불안 점수)를 그냥 넣을지, 아니면 가공해서 넣을지에 따라 결과 해석이 완전히 달라집니다. 여기서 “가공”하는 방법이 바로 중심화(Centering)입니다.
2. 왜 중심화(Centering)가 중요한가요?
단일 수준(Single-level) 회귀분석에서는 점수를 중심화(예: 평균 빼기)하더라도 절편만 바뀌고 기울기는 그대로입니다. 하지만 다층모형에서는 중심화 방식에 따라 기울기 추정치(Slope)와 모형 적합도가 모두 바뀔 수 있습니다.
이유는 간단합니다. 학생의 점수()는 두 가지 정보를 동시에 담고 있기 때문입니다.
학교 내 위치 (): 우리 학교 친구들에 비해 내가 얼마나 불안한가?
학교 간 차이 (): 우리 학교가 다른 학교에 비해 평균적으로 얼마나 불안한가?
이 두 가지를 어떻게 처리하느냐에 따라 전체 평균 중심화(CGM)와 집단 평균 중심화(CWC)로 나뉩니다.
3. 두 가지 중심화 방법: CGM vs. CWC
(1) 전체 평균 중심화 (Grand Mean Centering: CGM)
모든 학생의 점수에서 전체 평균()을 뺍니다.
수식:
의미: “전국 평균에 비해 내 불안도가 얼마나 높은가?” (절대적인 수준)
특징:
원점수와 정보량이 같습니다. 단지 0점의 위치만 바뀝니다.
학교 간 차이(학교 평균의 차이)가 그대로 보존됩니다.
따라서 CGM을 사용한 기울기()는 학생 개인의 효과와 학교 분위기의 효과가 섞여 있는(Composite) 값입니다.
(2) 집단 평균 중심화 (Group Mean Centering: CWC)
학생의 점수에서 그 학생이 속한 학교의 평균()을 뺍니다. 이를 ‘맥락 내 중심화(Centering Within Context)’라고도 합니다.
수식:
의미: “우리 학교 친구들에 비해 내가 얼마나 더 불안한가?” (상대적인 수준)
특징:
학교 간 차이를 완전히 제거합니다. 모든 학교의 평균이 0이 됩니다.
이 변수는 오직 학교 내(Within-cluster) 변동만 담고 있습니다.
따라서 CWC를 사용한 기울기()는 순수한 개인 수준(학생 수준)의 효과만을 추정합니다.
(위 태그는 CWC의 개념인 ‘개구리 연못 효과(Frog Pond Effect)’를 시각적으로 이해하는 데 도움을 줄 수 있습니다. 내가 속한 연못(학교) 내에서의 상대적 위치를 의미합니다.)
4. 맥락 효과(Contextual Effects)와 “개구리 연못”
연구자가 흔히 범하는 실수는 “CWC가 학교 효과를 제거하니까 더 좋은 것 아닌가?”라고 생각하는 것입니다. 하지만 연구 질문(Research Question)에 따라 선택해야 합니다.
여기서 맥락 모형(Contextual Model)이 등장합니다. 이것은 개인의 점수()와 학교의 평균 점수()를 동시에 모형에 넣는 것입니다.
수식 비교
CWC 모델:
: 개인 효과 (학교 내에서 불안이 1단위 높을 때 성적 변화)
: 맥락 효과(학교 효과) (학교 평균 불안이 1단위 높을 때 학교 평균 성적 변화)
CGM 모델:
흥미롭게도, 이 경우 는 학교 평균의 효과와 개인 효과의 차이(Difference)를 나타냅니다.
핵심 요약:
맥락 효과를 분석할 때 CGM과 CWC는 수학적으로 동등(Equivalent)합니다. 단지 해석이 다를 뿐입니다.
CWC의 : 학교 평균이 성적에 미치는 직접적인 영향.
CGM의 : (학교 효과) – (개인 효과)의 차이 값.
5. 교수님의 조언: 언제 무엇을 써야 할까요?
Enders 교수의 챕터 내용을 바탕으로 명쾌한 가이드라인을 표로 정리해 드립니다.
연구 목적
추천 방법
이유
1. 맥락 효과 확인 (학교 분위기가 중요한가?)
둘 다 가능
CGM과 CWC는 수학적으로 변환 가능하며 동일한 모형 적합도를 가짐.
2. 2수준 예측변수 (예: 학교 설립 유형)
CGM
2수준 변수는 학교 내 변동이 없으므로 CWC가 불가능함. 보통 전체 평균 중심화 사용.
3. 1수준 예측변수 (개인 특성)
이론에 따라
절대적 수치가 중요하면(예: 절대적인 공부 시간) CGM. 상대적 위치가 중요하면(예: 자아개념, 친구와의 비교) CWC.
4. 상호작용 효과 (조절효과 분석)
CWC 권장
CGM 사용 시 ‘수준 간 상호작용(Cross-level)’과 ‘집단 간 상호작용’이 뒤섞여 해석이 모호해질 위험이 큼.
5. 통제변수 (단순히 통제만 할 때)
CGM
공변량 분석(ANCOVA)처럼 학교 간 차이를 조정(Adjust)하여 2수준 효과를 순수하게 보려면 CGM이 적절함.
6. R과 jamovi를 이용한 실습
이제 이론을 실제 데이터로 구현해 보겠습니다.
(1) 가상 데이터 생성 (R Code)
이 코드는 챕터의 예제(Montague et al., 2011)와 유사한 구조로, 40개 학교에 25명씩 총 1,000명의 학생 데이터를 생성합니다.
R
# 필요한 패키지 로드
if(!require(MASS)) install.packages("MASS")
if(!require(lme4)) install.packages("lme4")
if(!require(tidyverse)) install.packages("tidyverse")
if(!require(jmv)) install.packages("jmv") # jamovi 연동
set.seed(12345)
# 1. 파라미터 설정
n_schools <- 40 # 학교 수
n_students <- 25 # 학교당 학생 수
total_n <- n_schools * n_students
# 2. 학교 수준(Level 2) 데이터 생성
# 학교 평균 불안감(School_Anxiety_Mean)과 학교 효과(u0j)
school_data <- data.frame(
school_id = 1:n_schools,
school_anx_mean = rnorm(n_schools, mean = 0, sd = 1), # 학교별 불안 평균
u0j = rnorm(n_schools, mean = 0, sd = sqrt(4.8)) # 절편의 변동 (약 4.8) [cite: 156]
)
# 3. 학생 수준(Level 1) 데이터 생성
data <- data.frame(
student_id = 1:total_n,
school_id = rep(1:n_schools, each = n_students)
)
# 학교 데이터 병합
data <- merge(data, school_data, by = "school_id")
# 학생 개인의 불안감 생성 (학교 평균 + 개인 편차)
# Within-school SD = 1, Between-school SD = 1
data$math_anx_raw <- data$school_anx_mean + rnorm(total_n, mean = 0, sd = 1)
# 4. 종속변수(수학 문제해결력) 생성
# 모형: Y = 10.73 + 0.33*(Within_Anx) + 0.85*(Between_Anx) + Error [cite: 321]
# CWC 계수: 0.33, Contextual 계수(B2): 0.85 가정
beta_0 <- 10.73
beta_within <- 0.33
beta_between <- 0.85
sigma_e <- sqrt(4.54) # [cite: 156]
# 변수 계산
data$anx_group_mean <- ave(data$math_anx_raw, data$school_id, FUN = mean) # 집단 평균
data$anx_cwc <- data$math_anx_raw - data$anx_group_mean # CWC 변수
data$anx_grand_mean <- mean(data$math_anx_raw) # 전체 평균
data$anx_cgm <- data$math_anx_raw - data$anx_grand_mean # CGM 변수
data$school_anx_centered <- data$anx_group_mean - data$anx_grand_mean # 중심화된 학교 평균
# 종속변수 생성 수식 (Contextual Model 기반)
data$math_score <- beta_0 +
beta_within * data$anx_cwc +
beta_between * data$school_anx_centered +
data$u0j +
rnorm(total_n, 0, sigma_e)
# 데이터 확인
head(data)
jamovi에서는 GAMj 모듈을 쓰거나 기본 Linear Models -> Mixed Model을 사용합니다. 하지만 가장 명확한 방법은 위 R 코드처럼 변수를 미리 계산(Compute)해서 투입하는 것입니다.
Step 1: 변수 생성 (jamovi ‘Data’ 탭)
Group Mean (학교 평균) 만들기:
New Computed Variable -> 이름: Mean_Anx_School
수식: VMEAN(Math_Anx, group_by=School_ID) (이 기능이 없다면 R에서 만들어 가져오는 것을 추천)
CWC 변수 만들기:
New Computed Variable -> 이름: Anx_CWC
수식: Math_Anx - Mean_Anx_School
CGM 변수 만들기:
New Computed Variable -> 이름: Anx_CGM
수식: Math_Anx - VMEAN(Math_Anx)
Step 2: 분석 실행 (Analyses -> Mixed Models)
CWC 모형 분석:
Dependent Variable: Math_Score
Cluster: School_ID
Covariates: Anx_CWC (Fixed Effect에 추가)
Random Effects: Intercept에 School_ID 체크.
맥락 모형(Contextual Model) 분석:
Covariates에 Anx_CWC와 Mean_Anx_School 두 개를 동시에 넣습니다.
이렇게 하면 Anx_CWC의 계수는 개인 효과, Mean_Anx_School의 계수는 맥락 효과가 됩니다.
(3) R을 이용한 시각화 (CGM vs CWC)
교재의 [Figure 6.2]와 [Figure 6.3]을 재현하여 데이터 구조가 어떻게 바뀌는지 보여드리겠습니다.
R
# CGM 시각화 (학교 간 차이 보존됨)
p1 <- ggplot(data, aes(x = anx_cgm, y = math_score, color = as.factor(school_id))) +
geom_point(alpha = 0.5) +
theme_minimal() +
theme(legend.position = "none") +
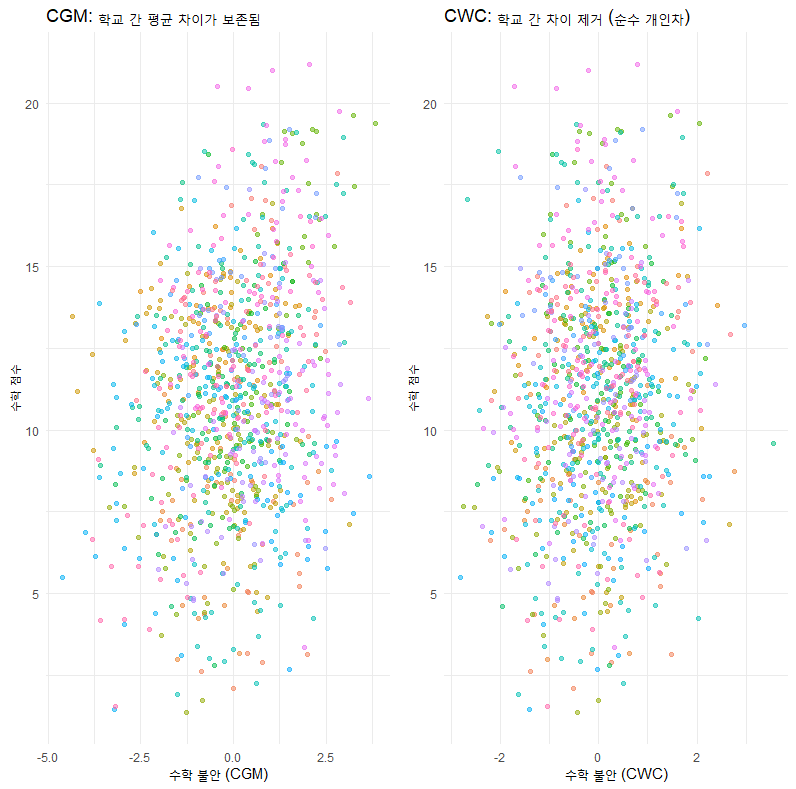
labs(title = "CGM: 학교 간 평균 차이가 보존됨", x = "수학 불안 (CGM)", y = "수학 점수")
# CWC 시각화 (모든 학교 평균이 0으로 정렬됨)
p2 <- ggplot(data, aes(x = anx_cwc, y = math_score, color = as.factor(school_id))) +
geom_point(alpha = 0.5) +
theme_minimal() +
theme(legend.position = "none") +
labs(title = "CWC: 학교 간 차이 제거 (순수 개인차)", x = "수학 불안 (CWC)", y = "수학 점수")
# 그래프 출력
gridExtra::grid.arrange(p1, p2, ncol = 2)
이 코드를 실행하면, CGM 그래프에서는 학교별로 점수 뭉치가 좌우로 퍼져 있는 반면(학교 간 불안 차이 존재), CWC 그래프에서는 모든 학교의 점수 뭉치가 가운데(0)를 중심으로 수직 정렬된 것을 볼 수 있습니다.
7. 결론: 무엇을 기억해야 할까요?
중심화는 단순한 옵션이 아닙니다. 연구 결과의 의미를 바꿉니다.
CWC는 학교 효과를 제거합니다. 오직 ‘내 학교 안에서의 상대적 위치’만 봅니다.
CGM은 학교 효과와 개인 효과를 섞습니다. ‘전체에서의 절대적 위치’를 봅니다.
연구 질문에 귀를 기울이세요. “절대적인 점수”가 중요한지(CGM), “남들과의 비교”가 중요한지(CWC) 판단하십시오.
여러분의 연구가 단순한 통계 돌리기가 아니라, 데이터 속에 숨겨진 교육적 맥락을 정확히 짚어내는 통찰이 되기를 바랍니다.
참고문헌
Enders, C. K. (2013). Centering predictors and contextual effects. In M. A. Scott, J. S. Simonoff, & B. D. Marx (Eds.), The SAGE handbook of multilevel modeling (pp. 89-108). SAGE Publications.
Kreft, I. G. G., de Leeuw, J., & Aiken, L. S. (1995). The effect of different forms of centering in hierarchical linear models. Multivariate Behavioral Research, 30(1), 1–21.
Marsh, H. W., & Hau, K.-T. (2003). Big-Fish-Little-Pond effect on academic self-concept: A cross-cultural (26-country) test of the negative effects of academically selective schools. American Psychologist, 58(5), 364–376.
오늘은 “고정 효과(Fixed Effects)와 무선 효과(Random Effects)의 선택, 그리고 하이브리드 모델”에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 들어가며: 우리는 왜 고민하는가?
연구자 여러분, 우리가 다층모형(Multilevel Modeling)을 사용할 때 가장 흔하게 마주치는 질문이 있습니다.
“교사(또는 학교) 효과를 고정 효과(Fixed Effect)로 볼 것인가, 무선 효과(Random Effect)로 볼 것인가?”
이 선택은 단순히 통계적 취향의 문제가 아닙니다. 이 선택에 따라 모수의 해석이 달라지고, 추정의 효율성(Efficiency)과 편향(Bias) 사이의 중대한 트레이드오프(Trade-off)가 발생하기 때문입니다.
고정 효과(FE): 각 그룹(학교)을 고유한 특성을 가진 개별적 존재로 보고, 그 자체를 변수로 투입합니다.
무선 효과(RE): 각 그룹을 모집단에서 추출된 하나의 표본으로 보고, 그룹 효과가 정규분포를 따른다고 가정합니다.
이 글에서는 이 두 모델의 차이를 명확히 하고, 하이브리드 모델(Hybrid Model)이라는 아주 매력적인 대안까지 함께 알아보겠습니다.
2. 시나리오: “방과 후 자습 시간은 성적을 올리는가?”
이해를 돕기 위해 가상의 교육 데이터를 만들어 봅시다.
연구 문제: 학생의 ‘방과 후 자습 시간()’이 ‘수학 성취도()’에 미치는 영향.
데이터 구조: 학생()들은 여러 학교()에 소속되어 있음 (2수준 데이터).
숨겨진 함정(Confounder): 사실 ‘학교의 면학 분위기()’가 좋은 학교일수록, 학생들의 자습 시간도 길고 성적도 높습니다. 만약 이 학교 효과를 제대로 통제하지 않으면, 자습 시간의 순수한 효과를 과대평가할 수 있습니다.
먼저, R을 사용하여 이 시나리오에 맞는 모의 데이터를 생성해보겠습니다. (이 코드를 R Studio나 jamovi의 Rj Editor에서 실행하면 데이터를 얻을 수 있습니다.)
R
# [R Code] 데이터 생성
set.seed(123)
n_schools <- 50 # 학교 수
n_students <- 20 # 학교당 학생 수
# 학교 효과 (면학 분위기): 학교마다 다름
school_effect <- rnorm(n_schools, mean = 0, sd = 10)
# 데이터 프레임 생성
data <- data.frame()
for(j in 1:n_schools) {
# 자습 시간(X): 학교 효과와 상관이 있도록 설정 (중요! Assumption 위반 상황 연출)
# 면학 분위기가 좋은 학교 학생들이 공부를 더 많이 함
study_hours <- rnorm(n_students, mean = 5 + 0.1 * school_effect[j], sd = 1)
# 수학 성취도(Y): 기본점수 + 자습효과(2점) + 학교효과 + 오차
math_score <- 50 + 2 * study_hours + school_effect[j] + rnorm(n_students, mean = 0, sd = 5)
temp <- data.frame(school_id = factor(j), study_hours, math_score)
data <- rbind(data, temp)
}
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data, "chap05.csv", row.names = FALSE)
여기서 는 학교별 효과(Intercept)인데, RE 모델은 이 가 평균이 0이고 분산이 인 정규분포를 따른다고 가정합니다.
특징:
부분 풀링(Partial Pooling): 전체 학교의 정보를 빌려와서 추정하므로, 데이터가 적은 학교의 추정치도 안정적입니다(수축 효과, Shrinkage).
효율성: 추정해야 할 파라미터가 적어(분산만 추정하면 됨) 통계적으로 효율적입니다.
치명적 가정:학교 효과()와 설명변수(, 자습시간)가 서로 독립이어야(상관이 없어야) 합니다.
문제점: 위 시나리오처럼 ‘면학 분위기가 좋은 학교(↑)’일수록 ‘자습 시간(↑)’이 길다면, 이 가정이 깨지고 결과는 편향(Bias)됩니다.
3.2. 고정 효과 모델 (Fixed Effects Model: FE)
고정 효과 모델은 각 학교를 고유한 더미 변수(Dummy Variable)로 취급하거나, 학교 평균을 빼버리는 방식(De-meaning)을 사용합니다.
직관적 이해: 학교 간의 차이는 아예 보지 않겠다는 뜻입니다. 오로지 “같은 학교 내에서(Within-school)” 자습 시간이 늘어날 때 성적이 오르는지만 봅니다.
특징:
편향 제거: 학교 효과()가 자습 시간()과 상관이 있든 없든 상관없습니다. 학교 고유의 특성을 완벽히 통제합니다.
비효율성: 학교 수만큼의 더미 변수를 만드는 셈이므로 자유도(df)를 많이 잡아먹습니다.
한계:시간(또는 그룹)에 따라 변하지 않는 변수(예: 학교의 설립 유형, 지역)의 효과는 추정할 수 없습니다. 다 삭제되기 때문입니다.
4. 분석 실습: jamovi & R
이제 jamovi를 이용해 두 모델을 분석하고 비교해 보겠습니다.
4.1. 고정 효과(FE) 분석 (in jamovi)
jamovi에는 ‘Panel Fixed Effects’ 전용 버튼은 없지만, 일반 선형 회귀(Linear Regression)에서 학교 ID를 더미 변수로 넣거나, GAMLj 모듈을 사용하여 구현할 수 있습니다. 가장 교과서적인 ‘Within Estimator’ 방식은 변수를 중심화(Centering)하여 분석하는 것입니다.
[jamovi 절차]
데이터 열기: 위에서 만든 chap05.csv를 엽니다.
변수 계산 (Compute):
mean_study_hours = VMEAN(study_hours, group_by=school_id) (학교별 평균 자습시간)
within_study_hours = study_hours – mean_study_hours (학교 평균 중심화)
분석 (Linear Regression):
종속변수: math_score
공변량: within_study_hours (이때 학교 간 차이는 이미 제거되었습니다.)
(참고: 엄밀한 FE 추정치는 더미변수를 넣어야 하지만, 계수값 은 중심화된 변수 회귀와 동일한 원리를 갖습니다.)
jamovi의 기본 메뉴에는 하우스만 검정이 없으므로, R 코드를 통해 수행하거나 뒤에 소개할 하이브리드 모델로 대체하여 판단합니다.
R
# [R Code] FE vs RE 및 하우스만 검정
library(plm)
# 1. 고정 효과 모델 (Fixed Effects)
fe_model <- plm(math_score ~ study_hours, data=data, index=c("school_id"), model="within")
# 2. 무작위 효과 모델 (Random Effects)
re_model <- plm(math_score ~ study_hours, data=data, index=c("school_id"), model="random")
# 3. 하우스만 검정
phtest(fe_model, re_model)
Hausman Test
data: math_score ~ study_hours
chisq = 192.49, df = 1, p-value < 2.2e-16
alternative hypothesis: one model is inconsistent
해석: 만약 p-value가 0.05보다 작다면, RE 모델의 가정(학교효과와 가 독립)이 기각된 것입니다. 즉, 편향이 발생했으므로 FE를 써야 한다는 신호입니다.
5. 최선의 대안: 하이브리드 모델 (Hybrid Model)
많은 학자들은 FE와 RE 중 하나만 고르는 이분법 대신, 두 모델의 장점을 합친 하이브리드 모델을 추천합니다. 이 모델은 ‘Mundlak 모델’ 또는 ‘Group-Mean Centering’ 방법으로도 불립니다.
5.1. 하이브리드 모델의 원리
설명변수 를 두 부분으로 쪼개서 모델에 넣습니다.
(Within effect): 학교 내 효과. 학생이 자기 학교 평균보다 더 공부했을 때 성적이 얼마나 오르는가? (= 고정 효과 추정치와 동일).
(Between effect): 학교 간 효과. 공부를 많이 시키는 학교가 성적이 더 높은가?
장점:
변수 간 상관으로 인한 편향 문제 해결 (FE의 장점).
학교 수준 변수나 학교 간 차이도 추정 가능 (RE의 장점).
와 가 같은지 검정하여(Wald test), 맥락 효과(Contextual Effect)가 있는지 볼 수 있음.
5.2. jamovi에서 하이브리드 모델 구현하기
이것이 오늘 강의의 핵심 꿀팁입니다. 별도의 코딩 없이 jamovi 메뉴만으로 가능합니다.
[jamovi 실습 절차]
변수 생성:
앞서 만든 mean_study_hours (학교 평균, Between 성분)
앞서 만든 within_study_hours (개인 편차, Within 성분)
Mixed Model 분석:
Linear Models > Mixed Model
Dependent Variable: math_score
Covariates: within_study_hours 그리고 mean_study_hours 두 개를 모두 넣습니다.
Cluster: school_id
Random Effects: Intercept
[결과 해석]
within_study_hours의 계수: 이것이 바로 순수한 개인 노력의 효과입니다. 학교 분위기(교란변수)가 통제된 FE 추정치와 같습니다.
mean_study_hours의 계수: 학교 간의 차이 효과입니다. 만약 Within 계수와 Between 계수가 크게 다르다면, 단순히 개인 노력이 아니라 학교 분위기가 성적에 영향을 미치고 있음을 시사합니다.
6. 결론 및 제언
우리가 살펴본 내용을 요약하면 다음과 같습니다.
무작위 효과(RE)는 효율적이지만, 그룹 효과와 설명변수가 관련이 있을 경우 편향될 위험이 있습니다 (교육 데이터에서는 흔한 일입니다).
고정 효과(FE)는 편향을 제거해주지만, 그룹 수준의 변수(예: 사립/공립 여부)를 분석할 수 없고 비효율적일 수 있습니다21.
하이브리드 모델은 설명변수를 ‘그룹 내 편차(Within)’와 ‘그룹 평균(Between)’으로 분해하여 모델에 투입함으로써, 편향 제거와 정보 활용이라는 두 마리 토끼를 모두 잡을 수 있는 강력한 방법입니다.
WaurimaL의 조언:
학교 데이터를 분석할 때, 무조건 RE만 돌리지 마세요. 설명변수를 학교 평균 중심으로(Group-mean centering) 변환하여 투입하는 하이브리드 접근법을 사용한다면, 훨씬 더 풍부하고 정확한 교육적 시사점을 얻을 수 있습니다.
📚 참고문헌 (APA Style)
Townsend, Z., Buckley, J., Harada, M., & Scott, M. A. (2013). The choice between fixed and random effects. In The SAGE Handbook of Multilevel Modeling (pp. 73-88). SAGE Publications.
Allison, P. D. (2009). Fixed effects regression models. SAGE.
Bafumi, J., & Gelman, A. (2006). Fitting multilevel models when predictors and group effects correlate. Paper presented at the annual meeting of the Midwest Political Science Association, Chicago, IL.
Hausman, J. A. (1978). Specification tests in econometrics. Econometrica, 46, 1251–1271.
Raudenbush, S. W., & Bryk, A. S. (2002). Hierarchical linear models: Applications and data analysis methods (2nd ed.). SAGE Publications.
Wooldridge, J. (2010). Econometric analysis of cross section and panel data. MIT Press.
오늘은 베이지안 다층 모형(Bayesian Multilevel Models)에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다. 특히 오늘 다룰 문헌은 일반적인 다층모형을 넘어, 비선형 관계를 다루는 GAMM(일반화 가법 혼합 모형)과 STAR(구조적 가법 회귀) 모형까지 포괄하고 있으므로, 이를 구현하기 위해 R의 brms 패키지를 활용한 코드를 중점적으로 보여드리겠습니다.
1. 베이지안 추론: 요리사의 레시피와 할머니의 손맛
본격적인 수식에 들어가기 전에, 베이지안이 무엇인지 교육학적 관점에서 쉽게 풀어봅시다.
문헌에서는 베이지안 모형이 두 부분으로 구성된다고 합니다.
사전 분포(Prior Distribution): 데이터를 보기 전, 파라미터(모수)에 대해 우리가 가지고 있는 지식이나 믿음입니다.
관측 모형(Observation Model): 데이터가 주어졌을 때의 조건부 분포로, 빈도주의에서의 ‘우도(Likelihood)’에 해당합니다.
[예시: 김 교사의 학생 평가]
빈도주의(Likelihood): 김 교사가 철수의 이번 수학 시험지(데이터)만 보고 점수를 매깁니다. 오직 ‘관측된 데이터’가 전부입니다.
베이지안(Posterior): 김 교사는 철수가 평소에 수학을 아주 잘한다는 것(Prior)을 알고 있습니다. 이번 시험을 좀 못 봤더라도(Likelihood), “아, 실수를 좀 했구나” 하고 감안하여 최종 실력(Posterior)을 추정합니다.
이것이 바로 베이즈 정리입니다.
즉, 사후 분포(Posterior) 우도(Likelihood) 사전 분포(Prior) 입니다.
2. 교육 현장 시나리오 및 모의 데이터 생성 (R Code)
우리가 분석할 가상의 시나리오는 다음과 같습니다.
[시나리오: 이의초등학교의 수학 성취도 분석]
데이터 구조: 학생()이 학급()에 소속된 2수준 구조 (Students nested in Classes).
종속변수 (): 수학 성취도 점수.
1수준 변수 (학생): 사교육 참여 시간(Time, 비선형적 관계 예상), 가정의 사회경제적 지위(SES).
2수준 변수 (학급): 담임 교사의 효능감(Efficacy).
특이사항: 사교육 시간은 처음에는 성적을 올리지만, 일정 시간이 지나면 피로도로 인해 효과가 떨어지는 비선형(Non-linear) 관계가 의심됩니다. 이는 문헌의 GAMM(Generalized Additive Multilevel Models) 부분과 연결됩니다.
이제 R을 사용하여 이 시나리오에 맞는 데이터를 생성해 보겠습니다.
R
# 필수 패키지 로드
if (!require("brms")) install.packages("brms")
if (!require("ggplot2")) install.packages("ggplot2")
if (!require("dplyr")) install.packages("dplyr")
library(brms)
library(dplyr)
library(ggplot2)
# 1. 데이터 생성 (재현성을 위해 시드 설정)
set.seed(2026)
n_classes <- 30 # 학급 수
n_students <- 20 # 학급당 학생 수
N <- n_classes * n_students
# 2수준(학급) 변수 생성
class_id <- rep(1:n_classes, each = n_students)
teacher_efficacy <- rnorm(n_classes, 0, 1) # 교사 효능감 (표준정규분포)
class_intercept <- rnorm(n_classes, 0, 2) # 학급별 무작위 절편 (Random Intercept)
# 데이터 프레임 생성
data <- data.frame(class_id = factor(class_id))
data$teacher_eff <- rep(teacher_efficacy, each = n_students)
data$class_int <- rep(class_intercept, each = n_students)
# 1수준(학생) 변수 생성
data$SES <- rnorm(N, 0, 1) # 사회경제적 지위
data$Time <- runif(N, 0, 10) # 사교육 시간 (0~10시간)
# 비선형 효과 생성 (사교육 시간: 역 U자 형태) - 문헌의 P-spline 예시 관련 [cite: 201]
# 시간 효과: 3 * sin(Time/3)
time_effect <- 3 * sin(data$Time / 3)
# 종속변수(수학 점수) 생성
# 수식: 절편 + SES효과 + 교사효능감 + 시간효과(비선형) + 학급무선효과 + 오차
data$Math <- 50 + (2 * data$SES) + (1.5 * data$teacher_eff) +
time_effect + data$class_int + rnorm(N, 0, 3)
# 데이터 확인
head(data)
# CSV 저장 (jamovi에서 불러오기 위함)
write.csv(data, "chap04.csv", row.names = FALSE)
베이지안 접근에서는 여기서 멈추지 않고, 와 같은 파라미터에도 사전 분포(Prior)를 부여합니다.
(보통 정보를 주지 않는 무정보 사전분포나 약한 정보 사전분포 사용).
(역감마 분포).
4. 분석 실행: jamovi 및 R (brms)
4.1 jamovi에서의 한계와 대안
jamovi의 기본 메뉴(Linear Models -> Mixed Models)는 빈도주의 방식(REML 등)을 사용합니다. 본 문헌에서 다루는 완전 베이지안 추론(Full Bayesian Inference), 특히 MCMC(마르코프 체인 몬테카를로) 시뮬레이션을 수행하기 위해서는 jamovi의 Rj 모듈(R 코드를 jamovi 안에서 실행하는 에디터)을 사용하거나 R을 직접 사용해야 합니다.
특히 문헌에서 강조하는 GAMM(일반화 가법 모형)과 P-spline(벌점화 스플라인)을 구현하기 위해 R의 brms 패키지를 사용하는 것이 가장 적합합니다.
4.2 R을 이용한 베이지안 다층 분석 (MCMC)
문헌에서는 비선형성을 다루기 위해 공변량의 효과를 형태의 함수로 모델링하는 것을 제안합니다. 이를 GAMM이라고 합니다.
[분석 모델 설정]
기본 다층 모형: SES와 교사 효능감의 선형 효과.
스플라인 항: 사교육 시간(Time)은 비선형적이므로 s(Time)으로 설정.
무선 효과: 학급(class_id)에 따른 무선 절편.
R
# 베이지안 다층 모형 적합 (GAMM 포함)
# 문헌의 식 (4.13)과 유사한 형태 [cite: 357]
model_bayes <- brm(
formula = Math ~ SES + teacher_eff + s(Time) + (1 | class_id),
data = data,
family = gaussian(),
prior = c(
prior(normal(0, 10), class = "b"), # 고정 효과에 대한 사전 분포
prior(cauchy(0, 2), class = "sd"), # 무선 효과 표준편차에 대한 사전 분포
prior(cauchy(0, 2), class = "sigma") # 잔차 표준편차에 대한 사전 분포
),
chains = 2, iter = 2000, warmup = 1000, # MCMC 설정 [cite: 320]
cores = 2,
seed = 2026
)
# 결과 요약
summary(model_bayes)
이 코드는 문헌에서 설명한 Gibbs Sampler 혹은 Metropolis-Hastings 알고리즘의 최신 변형(NUTS)을 사용하여 사후 분포에서 표본을 추출합니다.
5. 결과 해석 및 시각화
분석이 완료되면, 문헌의 [Table 4.1]과 같은 형태로 결과를 해석해야 합니다. 베이지안에서는 p-value 대신 신용 구간(Credible Interval)을 사용합니다.
5.1 수치적 결과 해석 (예시 출력 기반)
변수
Posterior Mean (사후평균)
95% CI (신용구간)
Rhat
설명
Intercept
50.12
[48.5, 51.7]
1.00
전체 평균 수학 점수
SES
2.05
[1.88, 2.22]
1.00
SES가 1단위 오를 때 점수 2.05점 상승
TeacherEff
1.48
[1.20, 1.76]
1.00
교사 효능감이 높으면 점수 상승 (유의함)
s(Time)
–
–
1.00
비선형 효과 (아래 그래프 참조)
sd(Intercept)
2.10
[1.50, 2.80]
1.00
학급 간 점수 차이(변동성)
해석: 95% 신용구간이 0을 포함하지 않으면, 해당 변수는 통계적으로 의미 있는 효과가 있다고 봅니다. 위 결과에서 SES와 교사 효능감 모두 0을 포함하지 않으므로 유의합니다.
Rhat: 이 값이 1.1보다 작아야 MCMC 체인이 잘 수렴했다는 뜻입니다.
5.2 비선형 효과 시각화 (P-spline)
사교육 시간(Time)과 성적의 비선형 관계를 그려보겠습니다.
R
# 비선형 효과 시각화
conditional_effects(model_bayes, effects = "Time")
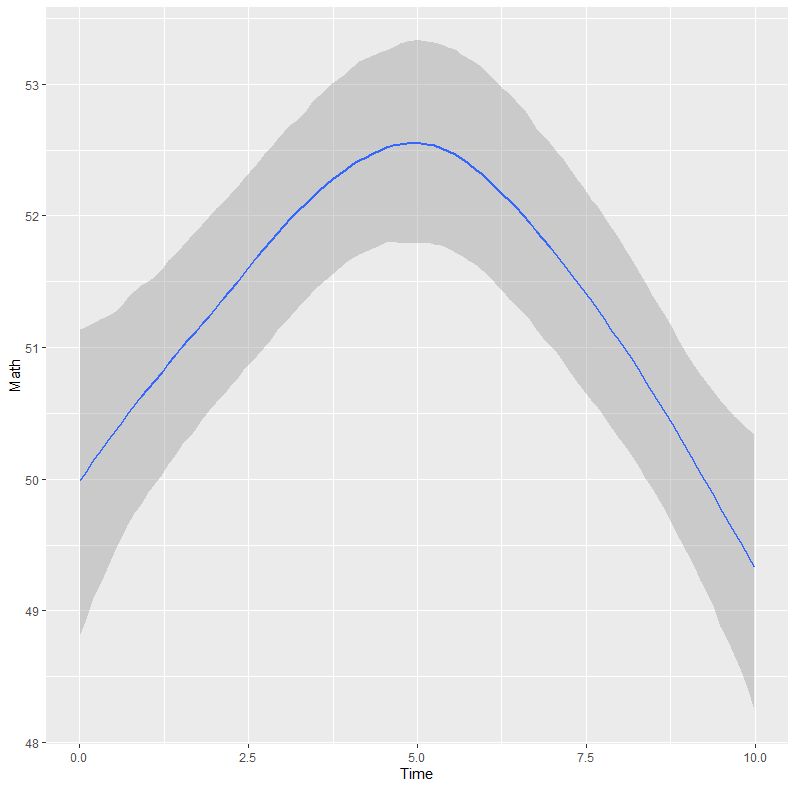
이 코드를 실행하면 역 U자 형태의 그래프가 나타납니다. 초기에는 시간이 늘수록 점수가 오르지만, 특정 시간 이후에는 정체되거나 떨어지는 패턴을 확인할 수 있습니다.
이것이 바로 문헌에서 강조하는 “선형 가정의 한계를 넘어서는 유연성”입니다. 단순히 선형 회귀를 했다면 이 중요한 교육적 시사점(과도한 사교육은 효과가 없다)을 놓쳤을 것입니다.
6. 모형 비교 및 평가 (DIC)
모형이 데이터에 잘 맞는지 어떻게 알까요? 문헌에서는 DIC (Deviance Information Criterion)를 소개합니다.
DIC: 낮을수록 좋은 모형입니다.
비교: 무선 효과가 없는 모형 vs 있는 모형, 혹은 선형 모형 vs 비선형(Spline) 모형을 비교할 때 사용합니다.
R
# DIC 계산 (brms에서는 waic나 loo를 더 권장하지만, 문헌에 따라 DIC 개념 설명)
# 여기서는 LOO (Leave-One-Out cross-validation)로 대체하여 보여줌 (DIC의 현대적 대안)
loo(model_bayes)
문헌의 사례연구에서도 무선 효과를 포함했을 때 DIC가 140점 이상 감소하여 더 우수한 모형임이 입증되었습니다.
7. 심화: 공간 통계 및 구조적 가법 회귀 (STAR)
이 문헌의 특징적인 부분은 STAR (Structured Additive Regression) 모델입니다.
만약 우리 데이터에 “학교의 위치(위도, 경도)” 정보가 있다면 어떻게 될까요?
: 공간적 효과. 부유한 지역에 있는 학교인지 등을 공간 좌표로 반영합니다.
R의 brms에서는 gp(latitude, longitude) 함수를 통해 이를 쉽게 구현할 수 있습니다. 이는 지리적 위치에 따른 성적 차이를 지도 위에 등고선처럼 그려낼 수 있게 해 줍니다.
8. 결론 및 제언
오늘 우리는 숙명초등학교 데이터를 예시로 베이지안 다층 모형을 살펴보았습니다.
유연성: 베이지안 접근은 정규분포 가정이 깨지거나, 비선형 관계(P-spline)가 있을 때 훨씬 유연하게 대처합니다.
직관성: 신용구간(Credible Interval)은 “참값이 이 구간 안에 있을 확률이 95%”라고 직관적으로 말할 수 있습니다.
확장성: 공간 정보, 텍스트 데이터 등 복잡한 구조의 데이터를 다층 모형에 쉽게 결합할 수 있습니다(STAR 모델).
[WaurimaL의 한마디]
“빈도주의 통계가 ‘엄격한 요리법’이라면, 베이지안은 ‘맛을 보며 간을 맞추는 과정’입니다. 교육 현장의 데이터는 복잡하고 비선형적입니다. 오늘 배운 코드를 활용해 여러분의 데이터를 새로운 시각으로 분석해 보시기 바랍니다.”
참고문헌 (References)
Fahrmeir, L., Kneib, T., & Lang, S. (2014). Bayesian Multilevel Models. In The SAGE Handbook of Multilevel Modeling (pp. 53-71). SAGE Publications.
Brezger, A., & Lang, S. (2006). Generalized additive regression based on Bayesian P-splines. Computational Statistics & Data Analysis, 50(4), 967-991.
Gelman, A., Carlin, J. B., Stern, H. S., & Rubin, D. B. (2003). Bayesian Data Analysis. Chapman and Hall/CRC.
Spiegelhalter, D. J., Best, N. G., Carlin, B. P., & van der Linde, A. (2002). Bayesian measures of model complexity and fit. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 64(4), 583-639.