안녕하세요!
오늘은 다층모형의 가장 핵심적이고 기초적인 내용인 다층모델 프레임워크에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
제1장. 다층모형(Multilevel Models)의 세계: 교실 속 아이들, 학교 속 교실
1. 서론: 왜 우리는 ‘층(Level)’을 고려해야 할까요?
우리가 교육 현장에서 마주하는 데이터는 결코 독립적인 섬처럼 존재하지 않습니다. 전통적인 통계 분석(예: 단순 회귀분석)은 모든 학생이 서로 아무런 관계없이 독립적으로 존재한다고 가정합니다. 하지만 현실은 어떤가요?
“학생은 학급에 속해 있고, 학급은 학교에 속해 있으며, 학교는 교육청(지역)에 속해 있습니다.”
이것이 바로 위계적 구조(Hierarchical Structure) 또는 내재된 구조(Nested Structure)입니다. 만약 우리가 이 구조를 무시하고 분석한다면 어떻게 될까요?
- 통계적 오류: 같은 반 아이들은 같은 선생님, 같은 분위기를 공유하기 때문에 서로 비슷할 가능성이 큽니다. 이를 무시하면 표준오차(Standard Error)가 잘못 계산되어, 효과가 없는데도 있다고 착각하는(1종 오류) 심각한 실수를 범하게 됩니다.
- 잘못된 해석: 개인의 특성(지능)과 집단의 특성(학교 풍토)을 뒤섞어 버려, 현상을 제대로 설명하지 못하게 됩니다.
따라서 우리는 개인(1수준)과 집단(2수준)을 동시에 고려하는 다층모형(Multilevel Modeling)을 사용해야 합니다.
이제부터 ‘행복 초등학교’의 가상 데이터를 통해 이 문제를 해결하는 다층모형의 마법을 살펴보겠습니다.
2. 모의 데이터 생성: 행복 초등학교 이야기
우리의 연구 문제는 다음과 같습니다.
- 연구 문제: “학생의 독서 즐거움(Enjoyment)은 학업 성취도(Achievement)에 영향을 미치는가? 그리고 이 관계는 담임 선생님의 경력(Teacher Experience)에 따라 달라지는가?”
이 데이터를 생성하기 위해 R 코드를 사용하겠습니다. (jamovi에서는 Rj 에디터를 쓰거나, 이 코드로 생성된 CSV를 불러와서 분석한다고 가정하면 됩니다.)
R
# [R Code: 모의 데이터 생성]
set.seed(2026)
# 1. 구조 설정
n_schools <- 20 # 학교 수 (Level 2)
n_students <- 30 # 학교당 학생 수 (Level 1)
N <- n_schools * n_students
# 2. 학교(Level 2) 변수 생성
school_id <- rep(1:n_schools, each = n_students)
teacher_exp <- rep(rnorm(n_schools, mean = 10, sd = 5), each = n_students) # 교사 경력
# 학교마다 출발점(절편)과 독서 효과(기울기)가 다름을 가정
u0 <- rep(rnorm(n_schools, mean = 0, sd = 5), each = n_students) # 학교별 절편 차이 (Random Intercept)
u1 <- rep(rnorm(n_schools, mean = 0, sd = 2), each = n_students) # 학교별 기울기 차이 (Random Slope)
# 3. 학생(Level 1) 변수 생성
enjoyment <- rnorm(N, mean = 50, sd = 10) # 독서 즐거움
error <- rnorm(N, mean = 0, sd = 5) # 개인 오차
# 4. 종속변수 생성 (다층 구조 반영)
# 성취도 = 전체평균 + (전체기울기 * 즐거움) + 학교별절편 + (학교별기울기 * 즐거움) + (상호작용: 교사경력 * 즐거움) + 오차
beta0 <- 40 # 기본 절편
beta1 <- 0.5 # 독서 즐거움의 기본 효과
beta2 <- 0.3 # 교사 경력의 조절 효과 (Cross-level interaction)
achievement <- (beta0 + u0) + (beta1 + u1 + beta2 * teacher_exp) * enjoyment + error
# 데이터프레임 생성
data <- data.frame(SchoolID = as.factor(school_id),
Achievement = achievement,
Enjoyment = enjoyment,
TeacherExp = teacher_exp)
# 데이터 확인 (상위 5개)
head(data)
# CSV 저장 (jamovi에서 불러오기 위함)
write.csv(data, "chap01.csv", row.names = FALSE)
이 데이터에서 학생()은 학교()에 내재되어 있습니다().
3. 다층모형의 기초: 고정효과와 무선효과
다층모형을 이해하려면 두 가지 핵심 단어를 구별해야 합니다.
- 고정효과 (Fixed Effects): 전체 데이터에 공통적으로 적용되는 평균적인 효과입니다. “일반적으로 독서를 좋아하면 성적이 오른다”라는 명제에서 ‘오른다’의 평균값입니다.
- 무선효과 (Random Effects): 집단(학교)마다 달라지는 고유한 특성입니다. 어떤 학교는 평균보다 성적이 더 높고(절편의 차이), 어떤 학교는 독서의 효과가 더 강력합니다(기울기의 차이). 이 차이를 확률분포(주로 정규분포)로 가정합니다.
모형 1: 무선 절편 모형 (Random Intercept Model)
가장 기초적인 모형입니다. 우리는 먼저 “어떤 학교는 애초에 성적이 더 잘 나오는가?”를 묻습니다. 이를 그림으로 그리면 모든 학교의 기울기는 같지만, 출발점(절편)의 높낮이가 다른 평행선들이 나타납니다.
수식으로는 다음과 같습니다.
- : 학교 학생의 성취도
- : 학교의 평균 성취도 (학교마다 다름)
- : 전체 학교의 평균 성취도 (고정효과)
- : 학교가 전체 평균에서 얼마나 벗어났는가? (무선효과, 잔차)
[jamovi 분석 방법]
Linear Models->Linear Mixed Model선택- Dependent Variable:
Achievement - Covariates:
Enjoyment - Cluster Variable (Grouping):
SchoolID - Random Effects:
Intercept | SchoolID체크
이 분석을 통해 우리는 급내상관계수(ICC)를 구할 수 있습니다. 이는 전체 성적 차이 중 학교 간 차이가 얼마나 되는지를 보여줍니다. 만약 ICC가 0에 가깝다면 굳이 다층모형을 쓸 필요가 없겠지만, 학교 데이터에서는 보통 0.1~0.3 정도가 나옵니다.
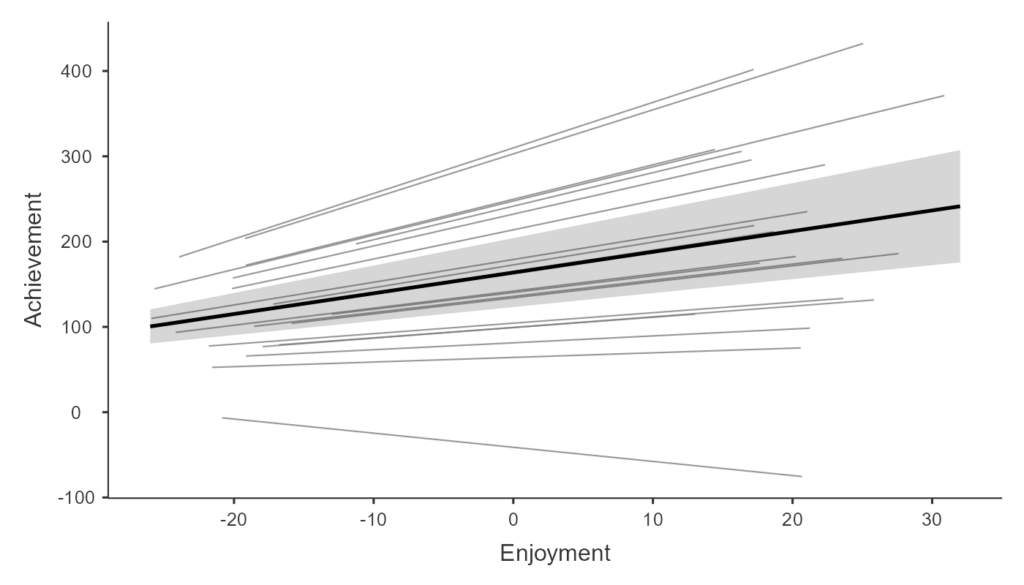
모형 2: 무선 기울기 모형 (Random Slope Model)
이제 더 흥미로운 질문을 던집니다. “독서의 즐거움이 성적에 미치는 영향이 학교마다 다른가?”
어떤 학교에서는 독서를 좋아하면 성적이 쑥쑥 오르지만, 어떤 학교에서는 별 차이가 없을 수 있습니다. 즉, 기울기가 학교마다 다릅니다.
수식이 조금 더 복잡해집니다.
이 모형은 아래 그림처럼 각 학교의 회귀선들이 출발점도 다르고 기울기도 제각각인 ‘스파게티’ 같은 모양을 띱니다.
[jamovi 분석 방법]
- 위의 설정에서 Random Effects에
Enjoyment변수를 추가하여Slope를 허용합니다. (Enjoyment + Intercept | SchoolID)
4. 설명변수의 추가와 상호작용 (Contextual Effects)
이제 데이터의 계층 구조를 완전히 활용해 봅시다.
“왜 어떤 학교는 독서 효과(기울기)가 더 클까?”
우리는 그 이유가 ‘선생님의 경력(TeacherExp)’ 때문이라고 가설을 세웠습니다. 이것은 학교 수준(Level 2)의 변수입니다.
이것을 수식에 넣으면 놀라운 일이 벌어집니다. 2수준 변수(교사 경력)가 1수준 변수(독서 즐거움)의 기울기를 설명하게 되는데, 이를 ‘층간 상호작용(Cross-level Interaction)’이라고 합니다.
여기서 는 독서 즐거움, 는 교사 경력입니다. 가 유의미하다면, “교사의 경력이 많을수록 학생의 독서 즐거움이 성적에 미치는 긍정적 효과가 더 커진다”고 해석할 수 있습니다.
library(lme4)
library(lmerTest) # p-value 확인용
library(ggplot2)
# 모형 적합: 성취도 ~ 독서*경력 + (1+독서|학교)
# * 기호를 쓰면 주효과와 상호작용 효과가 모두 포함됩니다.
full_model <- lmer(Achievement ~ Enjoyment * TeacherExp + (1 + Enjoyment | SchoolID),
data = data)
# 결과 요약
summary(full_model)
# --- 시각화: 상호작용 효과 확인 ---
# 교사 경력을 '고경력'과 '저경력' 집단으로 구분 (시각화 목적)
data$ExpGroup <- ifelse(data$TeacherExp > mean(data$TeacherExp),
"High Experience", "Low Experience")
data$pred <- predict(full_model)
ggplot(data, aes(x = Enjoyment, y = pred, color = ExpGroup)) +
geom_point(alpha = 0.1) + # 개별 학생 점수 (흐릿하게)
geom_smooth(method = "lm", se = FALSE, linewidth = 1.5) + # 집단별 회귀선 (굵게!)
theme_minimal() +
scale_color_manual(values = c("blue", "orange")) +
labs(title = "교사 경력이 독서 효과를 조절하는가?",
subtitle = "High Experience 집단의 기울기가 더 가파르다면 조절효과가 있는 것입니다.",
x = "독서 즐거움", y = "예측된 학업 성취도")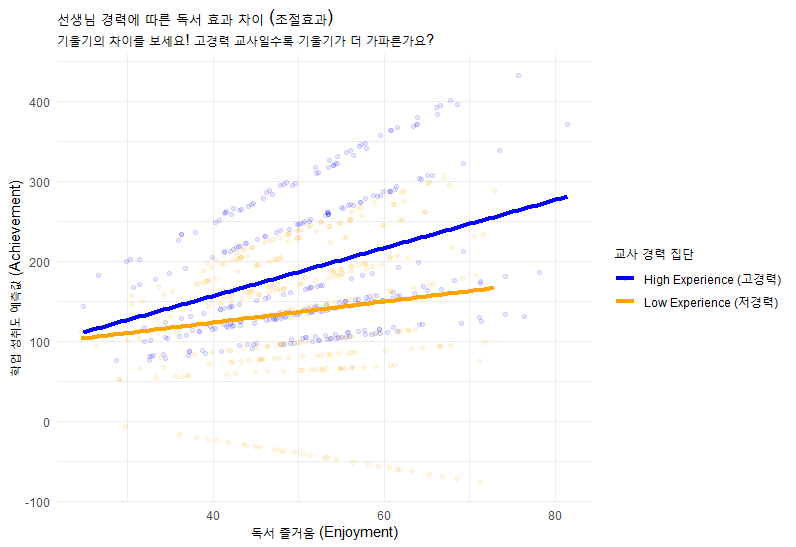
[jamovi 분석 방법]
- ★ 핵심: 상호작용 항 만들기 (Fixed Effects):
Fixed Effects탭을 엽니다.- 왼쪽 변수 목록에서
Enjoyment와TeacherExp를 동시에 선택(Ctrl/Shift 클릭)합니다. - 가운데 [Interaction] 버튼을 누릅니다.
- 오른쪽 박스에
Enjoyment ✻ TeacherExp항목이 생성되었는지 확인합니다.
- 결과 확인:
Fixed Effects Parameter Estimates표에서 상호작용 항(Enjoyment ✻ TeacherExp)의 p-value가 0.05 미만인지 확인합니다.
- 그래프 그리기:
Estimated Marginal Means탭에서Enjoyment ✻ TeacherExp항을 선택하여 아래로 내립니다.
5. 결과의 해석과 교훈
분석 결과를 보면 다음과 같은 패턴을 발견할 수 있습니다.
- Intercept (절편): 학교 간 성적 차이가 존재합니다. (ICC > 0)
- Enjoyment (주효과): 독서를 좋아할수록 성적이 오릅니다. (기울기 > 0)
- Interaction (상호작용): 교사 경력이 높은 학교일수록 독서의 효과(기울기)가 더 가파릅니다. 즉, 노련한 선생님은 독서를 좋아하는 아이들의 잠재력을 더 크게 성적으로 연결해 줍니다.
6. 풀링(Pooling)의 미학: 정보의 줄다리기
다층모형은 “완전 결합(Fully Pooled)”과 “비결합(Fully Unpooled)” 사이의 타협점입니다. 이 개념이 아주 중요합니다.
1) 완전 결합 (Complete Pooling)
- 개념: “학교 차이는 없어!” 하고 모든 데이터를 한 통에 넣고 분석하는 것입니다.
- 문제: 학교 간의 고유한 특성을 완전히 무시합니다.
2) 비결합 (No Pooling)
- 개념: “학교는 완전히 달라!” 하고 각 학교마다 따로따로 회귀분석을 20번 돌리는 것입니다.
- 문제: 학생 수가 적은 학교는 데이터가 부족해 결과가 엉망이 됩니다(과적합).
3) 부분 결합 (Partial Pooling) = 다층모형
- 개념: 다층모형은 이 둘의 중간입니다. 학교별 특성을 인정하되, 전체 데이터의 경향성도 빌려옵니다.
- 수축 효과 (Shrinkage): 학생 수가 적거나 데이터가 불안정한 학교의 추정치는 전체 평균 쪽으로 살짝 당겨집니다. 이것은 마치 “잘 모를 때는 남들이 하는 만큼은 한다고 치자”는 지혜와 같습니다. 이를 통해 훨씬 안정적이고 정확한 추정치를 얻습니다.
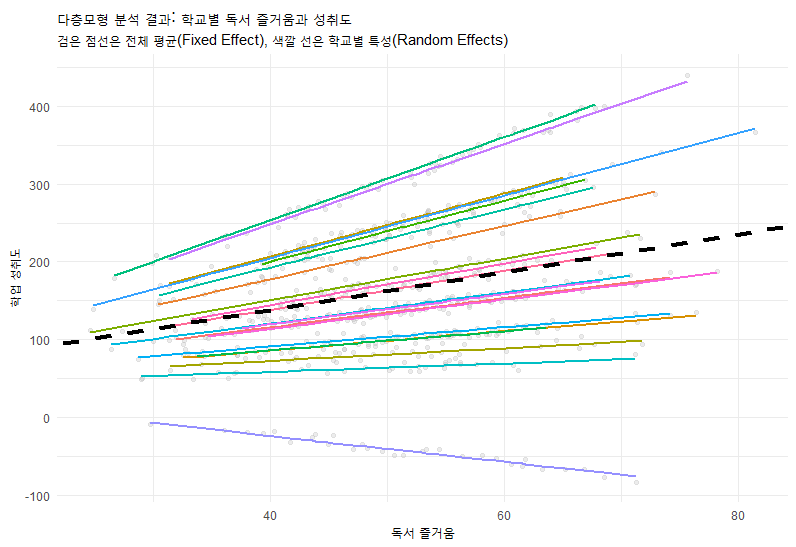
7. 시각화: R을 이용한 그래프
R
library(ggplot2)
library(lme4)
# 모형 적합 (Random Slope Model)
model <- lmer(Achievement ~ Enjoyment + (1 + Enjoyment | SchoolID), data = data)
# 예측값 생성
data$pred <- predict(model)
# 시각화
ggplot(data, aes(x = Enjoyment, y = Achievement, group = SchoolID)) +
geom_point(alpha = 0.3, color = "gray") + # 실제 데이터 점
geom_line(aes(y = pred, color = as.factor(SchoolID)), size = 0.8) + # 학교별 회귀선 (Random Slopes)
geom_abline(intercept = fixef(model)[1], slope = fixef(model)[2],
color = "black", size = 1.5, linetype = "dashed") + # 전체 고정효과 (평균선)
theme_minimal() +
labs(title = "다층모형 분석 결과: 학교별 독서 즐거움과 성취도",
subtitle = "검은 점선은 전체 평균(Fixed Effect), 색깔 선은 학교별 특성(Random Effects)",
x = "독서 즐거움", y = "학업 성취도", color = "학교 ID") +
theme(legend.position = "none")
8. 확장과 적용: 더 복잡한 세상으로
다층모형은 여기서 멈추지 않습니다. 현실은 더 복잡하니까요.
- 3수준 모형: 학생 학급 학교 지역구… 이렇게 계속 확장할 수 있습니다.
- 교차 분류 (Cross-classified) 모형: 학생이 ‘학교’에도 속하지만 동시에 ‘거주 지역(동네)’에도 속할 때, 학교와 동네는 서로 완전히 포함관계가 아닐 수 있습니다(예: A학교에 사는 애들이 1동, 2동에 섞여 삼). 이럴 때도 다층모형은 유연하게 대처합니다.
- 일반화 선형 혼합모형 (GLMM): 종속변수가 점수가 아니라 ‘합격/불합격(0/1)’인 경우(로지스틱)에도 다층모형을 적용할 수 있습니다.
9. 맺음말
다층모형은 단순히 통계 기법이 아닙니다. 세상을 바라보는 ‘관점’입니다. 개인이 처한 환경(Context)을 무시하지 않고, 개인과 환경의 상호작용을 있는 그대로 존중하며 분석하는 방법입니다.
여러분도 jamovi와 R을 통해 교실 속 아이들, 그리고 그 아이들을 감싸고 있는 학교의 이야기를 숫자로 풀어내는 즐거움을 느껴보시길 바랍니다.
참고문헌 (References)
Gill, J., & Womack, A. J. (2014). The Multilevel Model Framework. In The SAGE Handbook of Multilevel Modeling (pp. 3–20). SAGE Publications Ltd.
[WaurimaL의 팁]
jamovi에서
lmer(Linear Mixed Effects Regression) 결과를 해석할 때, Fixed Effects Parameter Estimates 표는 전체적인 경향성을, Random Components 표의 Variance(분산)는 집단 간의 차이 크기를 나타낸다는 점을 꼭 기억하세요!