안녕하세요!
오늘은 “다층 연구 설계의 최적화(Sample Size and Power Analysis in Multilevel Designs)”에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 기반이 되는 R 코드를 함께 제시하여 ‘최적 표본 크기 산출’부터 ‘모의 데이터 생성’, 그리고 ‘분석’까지 완벽하게 구현해 드리겠습니다. (참고: jamovi는 데이터 분석에는 강력하지만, 연구 설계 단계의 복잡한 ‘최적 표본 산출’ 기능은 제한적이므로, 이 부분은 R의 수리적 계산 기능을 활용하고 분석은 jamovi의 혼합모형 논리로 설명하겠습니다.)
1. 서론: 연구자의 영원한 딜레마, “돈이냐, 정확성이냐?”
교육 연구를 진행할 때 우리는 항상 두 가지 제약 조건 사이에서 고민합니다.
- 통계적 검증력(Power): 효과가 있다면 있다고 말할 수 있는 힘 (높을수록 좋음).
- 예산(Budget): 연구비와 시간은 한정되어 있음.
이 장에서는 다층 모형(Multilevel Modeling) 상황, 즉 학생이 학교에 소속되어 있는 구조에서 어떻게 하면 가장 적은 비용으로 가장 높은 정확성을 얻을 수 있는지, 그 최적 설계(Optimal Design) 방법을 알려드리겠습니다.
우리의 가상 시나리오를 소개합니다.
[시나리오: 프로젝트 ‘독서왕’]
교육심리학자 김 교수는 새로운 독서 프로그램이 초등학생의 ‘문해력’을 높이는지 검증하려 합니다.
- 총 예산: 1,000만 원 (가상의 화폐 단위)
- 비용 구조:
- 학교 하나를 섭외하는 비용(행정 절차, 학교 보상 등): 200만 원 (c)
- 학생 한 명을 검사하는 비용(검사지, 간식 등): 10만 원 (s)
- 연구 질문: 몇 개의 학교를 섭외하고, 학교당 몇 명의 학생을 뽑아야 내 돈 1,000만 원 안에서 가장 정확한 결과를 얻을까요?
2. 군집 무작위 배정(Cluster Randomized Trial)의 설계
2.1 왜 다층 설계인가?
가장 쉬운 방법은 전국의 학생 명부에서 무작위로 학생을 뽑는 것입니다. 하지만 현실적으로 불가능합니다.
- 실행 가능성: 학교 단위로 프로그램을 돌려야 합니다.
- 오염(Contamination): 한 반에서 철수는 실험집단, 영희는 통제집단이면 서로 이야기하며 효과가 섞여버립니다.
그래서 우리는 학교(Cluster)를 통째로 실험군 혹은 대조군으로 배정하는 군집 무작위 배정(Cluster Randomized Trial)을 사용합니다.
2.2 급내상관계수(ICC)와 설계 효과
문제는 같은 학교 아이들끼리는 서로 비슷하다는 점입니다(학교 분위기, 선생님의 영향 등). 이를 급내상관계수(ICC, )라고 합니다.
- ICC가 높다 = 학교 간 차이가 크다 = 같은 학교 아이들은 매우 비슷하다.
- ICC가 높으면, 학생을 100명 더 뽑는 것보다 학교를 1개 더 섭외하는 게 훨씬 중요해집니다.
2.3 최적 표본 크기 공식 (The Magic Formula)
주어진 예산() 하에서 처치 효과()의 분산()을 최소화하는 최적의 학교 수()와 학교당 학생 수()는 다음과 같습니다.
- : 학교당 비용 (200)
- : 학생당 비용 (10)
- : ICC (가정된 값, 보통 0.05~0.10)
이 공식을 보면, ICC()가 커질수록 학교당 학생 수()는 줄여야 합니다. 왜냐하면 같은 학교에서 많이 뽑아봤자 정보가 중복되기 때문입니다.
3. R과 jamovi를 활용한 최적 설계 및 데이터 생성
이제 김 교수의 ‘독서왕’ 프로젝트를 위해 R을 사용하여 최적 표본을 계산하고, 이를 분석할 수 있는 모의 데이터를 생성해 보겠습니다.
3.1 최적 표본 크기 계산 (R Code)
김 교수의 상황: 예산 10,000, , 그리고 ICC()는 선행연구를 통해 0.05로 가정합니다.
R
# [R Code] 최적 표본 크기 산출
# 파라미터 설정
B <- 10000 # 총 예산
c <- 200 # 학교(Cluster)당 비용
s <- 10 # 학생(Person)당 비용
rho <- 0.05 # 급내상관계수 (ICC)
# 1. 최적의 학생 수 (n) 계산 [cite: 120]
n_opt <- sqrt((c * (1 - rho)) / (s * rho))
# 2. 최적의 학교 수 (K) 계산 [cite: 119]
K_opt <- B / (c + s * n_opt)
# 결과 출력
cat("최적의 학교당 학생 수 (n):", round(n_opt, 2), "명\n")
cat("최적의 학교 수 (K):", round(K_opt, 2), "개교\n")
[분석 결과 해석]
- 계산 결과, , 가 나옵니다.
- 현실적으로 반올림하여 학교당 19명, 총 26개 학교(실험 13, 통제 13)를 섭외하는 것이 최적입니다.
3.2 비용 효율성 시각화 (Design Efficiency Plot)
아래 그래프는 학교당 학생 수()를 변화시킬 때, 추정의 오차(분산)가 어떻게 변하는지 보여줍니다. 우리는 분산이 가장 낮은 지점을 찾아야 합니다.
R
# [R Code] 시각화 생성
library(ggplot2)
n_seq <- seq(5, 50, by = 1) # 학생 수를 5명에서 50명까지 변화시킴
K_seq <- B / (c + s * n_seq) # 예산 제약에 따른 학교 수
# 분산 계산 공식 (단순화된 형태) [cite: 128]
# g_rho 부분과 예산 부분을 결합
design_var <- function(n, K, rho) {
# Standard Error calculation based on Eq 11.3 & 11.6 logic relation
# Here we look at relative variance proportional to the function
design_effect <- 1 + (n - 1) * rho
total_N <- n * K
return(design_effect / total_N)
}
var_values <- design_var(n_seq, K_seq, rho)
df_plot <- data.frame(n = n_seq, Variance = var_values)
ggplot(df_plot, aes(x = n, y = Variance)) +
geom_line(color = "blue", linewidth = 1.2) +
geom_vline(xintercept = 19, linetype = "dashed", color = "red") +
annotate("text", x = 19, y = max(var_values), label = "Optimal n = 19", vjust = -1) +
labs(title = "최적 표본 설계: 학교당 학생 수 vs. 추정 오차",
subtitle = "예산 고정 시, 학생을 19명 뽑을 때 오차가 최소화됨",
x = "학교당 학생 수 (n)", y = "치료 효과의 분산 (낮을수록 좋음)") +
theme_minimal()
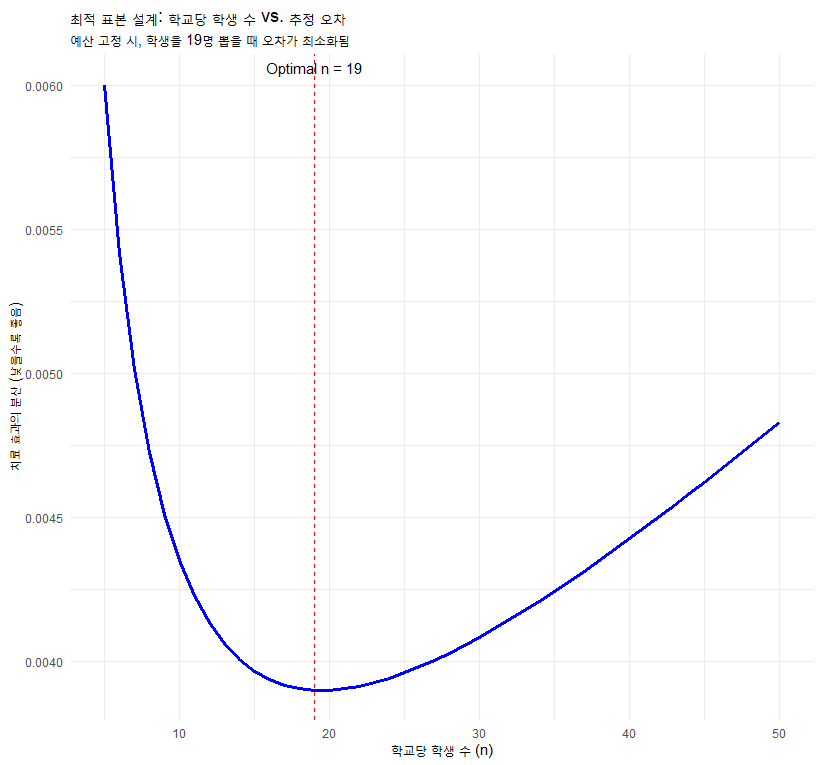
이 그래프를 통해 김 교수는 무작정 학생을 많이 뽑는다고 좋은 게 아니라, 학교 수와 학생 수의 황금 비율을 맞춰야 함을 알 수 있습니다.
4. 모의 데이터 생성 및 분석 (Linear Mixed Model)
이제 최적 설계()에 따라 데이터를 수집했다고 가정하고, 이를 jamovi(또는 R의 lmer)에서 분석하는 방법을 보여드리겠습니다.
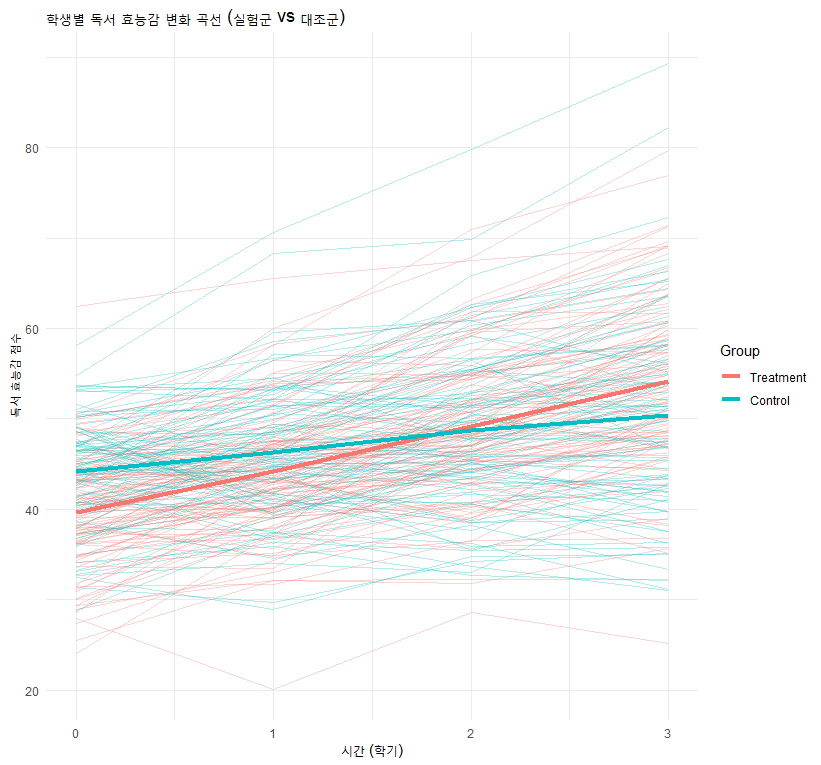
4.1 데이터 생성 (Backstory 포함)
- 상황: 26개 학교를 선정, 절반은 ‘독서왕 프로그램(Treatment)’, 절반은 ‘기존 수업(Control)’ 진행.
- 효과: 프로그램은 문해력 점수를 평균 5점 정도 높여줄 것으로 기대.
- 변산: 학교 간 차이(ICC) 반영.
R
# [R Code] 모의 데이터 생성
set.seed(123) # 재현성을 위해 시드 설정
K <- 26 # 학교 수
n <- 19 # 학교당 학생 수
N <- K * n # 총 학생 수
# 학교 ID 및 치료 집단 배정 (0: 통제, 1: 처치)
school_id <- rep(1:K, each = n)
treatment <- rep(c(rep(0, K/2), rep(1, K/2)), each = n)
# 랜덤 효과 생성 (학교 간 차이)
u0j <- rep(rnorm(K, mean = 0, sd = sqrt(5)), each = n) # 학교 분산 = 5
# 오차항 생성 (학생 간 차이)
# ICC = 0.05 이려면, 학교분산/(학교분산+오차분산) = 0.05
# 5 / (5 + 95) = 0.05 -> 오차 분산은 95, SD는 약 9.75
eij <- rnorm(N, mean = 0, sd = sqrt(95))
# 고정 효과 (진짜 치료 효과 = 5점)
beta0 <- 50 # 평균 점수
beta1 <- 5 # 치료 효과
# 종속 변수 (문해력 점수) 생성
# y_ij = beta0 + beta1*x_j + u_0j + e_ij
y <- beta0 + beta1 * treatment + u0j + eij
# 데이터 프레임 생성
data_sim <- data.frame(
SchoolID = factor(school_id),
StudentID = 1:N,
Treatment = factor(treatment, labels = c("Control", "Program")),
Score = y
)
# 데이터 확인
head(data_sim)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data_sim, "chap11.csv", row.names = FALSE)
4.2 jamovi 식 분석 절차 (R lme4 문법 활용)
jamovi의 Linear Mixed Models (GAMLj 모듈) 메뉴에서 분석하는 것과 동일한 R 코드입니다.
데이터 구조는 다음과 같습니다.
- Level 1 (Person): 학생별 문해력 점수 (
Score) - Level 2 (Cluster): 학교 (
SchoolID) - Predictor: 처치 여부 (
Treatment, Level 2 변수)
수식 모형은 다음과 같습니다15:
R
# [R Code] 다층 모형 분석
library(lme4)
library(lmerTest)
# 모형 적합: 절편에 대해서만 학교별 무선 효과(Random Intercept) 허용
model <- lmer(Score ~ Treatment + (1 | SchoolID), data = data_sim)
# 결과 요약
summary(model)
[결과 해석 방법]
- Fixed Effects:
TreatmentProgram의 Estimate가 5에 가까운지, p-value가 0.05보다 작은지 확인합니다. (우리가 5로 설정했으므로 유의하게 나올 것입니다.) - Random Effects:
SchoolID의 Variance가 설계 시 가정한 분산과 유사한지 확인합니다.
5. 심화: 더 복잡한 상황들
5.1 다기관 임상시험 (Multisite Trials)
만약 김 교수가 학교 전체를 배정하는 게 아니라, 각 학교 안에서 철수는 실험반, 영희는 통제반으로 나눌 수 있다면 어떨까요?
이를 Multisite Trial이라고 합니다.
- 장점: 학교 효과()가 치료 효과 추정에서 사라지므로 훨씬 강력한 검증력(Power)을 가집니다.
- 설계: 이 경우 은 학교 분산에 영향을 받지 않으므로, 더 적은 예산으로도 유의한 결과를 얻을 수 있습니다. 하지만 ‘오염’ 문제가 없어야만 가능합니다.
5.2 반복 측정 (Longitudinal Design)
만약 김 교수가 프로그램을 1년 동안 진행하면서 학생들의 변화를 보고 싶다면 몇 번 측정해야 할까요?
- 선형 변화(직선 성장)를 가정할 때: 시작(Baseline)과 끝(End), 딱 2번 측정하거나, 중간 지점 하나를 추가하는 것이 비용 대비 가장 효율적입니다.
- 이차 함수(곡선 성장)를 가정할 때: 최소 3번의 측정이 필요하며, 등간격으로 측정하는 것이 좋습니다.
5.3 현실적인 문제와 해결책
- ICC를 모를 때: 보통 문헌 연구를 통해 보수적으로(약간 높게) 잡습니다. ICC를 실제보다 절반 정도로 낮게 잘못 예측했더라도, 최적 설계 대비 효율성 손실은 약 10% 내외로 크지 않다는 연구가 있습니다.
- 학교 크기가 다를 때: 모든 학교가 19명일 수는 없습니다. 학교 간 크기 편차(CV)가 0.5 정도라면, 계산된 학교 수()보다 약 11% 정도 더 많은 학교를 섭외하여 이를 보정해야 합니다.
6. 결론 및 제언
오늘 살펴본 내용을 요약하면 다음과 같습니다.
- 학교 현장 연구에서는 학생 수만큼이나 학교 수(Cluster Number)가 중요하다.
- 비용 함수와 ICC를 고려하면, 무조건 많은 표본보다 최적의 비율을 찾는 것이 경제적이다.
- 학교를 통째로 배정(CRT)하는 것보다 학교 내 무선 배정(Multisite)이 통계적으로는 더 유리하나, 오염 가능성을 고려해야 한다.
참고문헌 (APA Style)
- Maas, C. J. M., & Hox, J. J. (2005). Sufficient sample sizes for multilevel modeling. Methodology, 1(3), 86-92.
- Moerbeek, M., & Teerenstra, S. (2011). Optimal design in multilevel experiments. In J. J. Hox & J. K. Roberts (Eds.), Handbook of Advanced Multilevel Analysis (pp. 257-281). New York: Routledge.
- Raudenbush, S. W. (1997). Statistical analysis and optimal design for cluster randomized trials. Psychological Methods, 2(2), 173-185.
- Snijders, T. A. B., & Bosker, R. J. (1993). Standard errors and sample sizes for two-level research. Journal of Educational Statistics, 18(3), 237-259.
- Van Breukelen, G. J. P., & Moerbeek, M. (2013). Design considerations in multilevel studies. In M. A. Scott, J. S. Simonoff, & B. D. Marx (Eds.), The SAGE Handbook of Multilevel Modeling (pp. 183-200). SAGE Publications.