안녕하세요!
오늘은 “다층모형(Multilevel Model)에서의 모형 선택(Model Selection)”에 대해 살펴보겠습니다. “학교 현장의 데이터”를 예시로 들어 직관적인 설명과 수리적 엄밀함을 모두 갖춘 형태로 재구성해 드리겠습니다.
분석 도구로는 jamovi의 사용법을 설명하되, jamovi의 기반이 되는 R 코드를 함께 제시하여 모의 데이터 생성부터 분석, 시각화까지 완벽하게 구현해 드리겠습니다.
1. 서론: 완벽한 옷을 고르는 법 (모형 선택의 딜레마)
여러분이 백화점에서 옷을 고른다고 상상해 보세요. 너무 큰 옷은 헐렁해서 보기가 싫고(과소적합, underfitting), 너무 꽉 끼는 옷은 숨쉬기가 힘듭니다(과적합, overfitting). 통계 모형을 선택하는 것도 이와 같습니다. 우리는 데이터를 가장 잘 설명하면서도, 불필요하게 복잡하지 않은 ‘최적의 모형’을 찾아야 합니다.
일반적인 회귀분석(OLS)에서는 나 수정된 같은 명확한 기준이 있습니다. 하지만 다층모형(MLM)으로 넘어오면 상황이 훨씬 복잡해집니다. 데이터가 여러 층위(예: 학생-학급-학교)로 꼬여 있기 때문에 “설명력”을 정의하는 방식도 달라지고, 모형의 적합도를 판단하는 기준(AIC, BIC 등)도 어떤 ‘우도(Likelihood)’를 쓰느냐에 따라 달라지기 때문입니다.
이 글에서는 Russell Steele 교수의 논의를 바탕으로, 학교 데이터를 사용하여 이 복잡한 기준들을 명쾌하게 정리해 드리겠습니다.
2. 예제 데이터 생성: “햇살초등학교의 수학 성취도”
이론만 들으면 지루하니, 가상의 시나리오를 만들어 봅시다.
2.1 시나리오
- 연구 대상: 햇살초등학교 6학년 학생 1,000명 (50개 학급).
- 종속 변수(): 수학 성취도 (Math Score).
- 1수준 변수(학생): 사교육 시간 (Private Education, ).
- 2수준 변수(학급): 담임 선생님의 열정 (Teacher Passion, ).
- 가설: 사교육 시간이 길수록 수학 점수가 높을 것이며, 이 관계는 담임 선생님의 열정에 따라 달라질 것이다(교차 수준 상호작용).
2.2 R을 이용한 모의 데이터 생성 (jamovi의 Rj Editor에서도 실행 가능)
R
set.seed(1234)
# 1. 파라미터 설정
n_classes <- 50 # 학급 수 (J)
n_students_per_class <- 20 # 학급당 학생 수 (n)
N <- n_classes * n_students_per_class
# 2. 2수준(학급) 변수 생성
class_id <- rep(1:n_classes, each = n_students_per_class)
teacher_passion <- rnorm(n_classes, mean = 50, sd = 10) # 교사 열정
u0 <- rnorm(n_classes, 0, 5) # 절편에 대한 랜덤 효과 (학교 간 차이)
u1 <- rnorm(n_classes, 0, 2) # 기울기에 대한 랜덤 효과 (효과의 차이)
# 3. 1수준(학생) 변수 생성
private_edu <- rnorm(N, mean = 5, sd = 2) # 사교육 시간
error <- rnorm(N, 0, 5) # 잔차
# 4. 데이터 프레임 생성 (계층적 구조 반영)
# 수식: Math = (50 + u0) + (2 + 0.1*Passion + u1)*Private + error
# 교사 열정이 높으면 사교육의 효과가 더 커진다고 가정 (상호작용)
intercept <- 40 + u0[class_id]
slope <- 2 + 0.1 * (teacher_passion[class_id] - 50) + u1[class_id]
math_score <- intercept + slope * private_edu + error
data <- data.frame(
ClassID = factor(class_id),
StudentID = 1:N,
MathScore = math_score,
PrivateEdu = private_edu,
TeacherPassion = rep(teacher_passion, each = n_students_per_class)
)
head(data)
# CSV로 저장 (jamovi에서 불러오기 위함)
write.csv(data, "chap07.csv", row.names = FALSE)3. 다층모형에서의 : 설명력의 재정의
일반 회귀분석에서 는 “전체 변동 중 모형이 설명하는 비율”입니다. 하지만 다층모형에서는 변동이 학생 수준(Level 1)과 학급 수준(Level 2)으로 나뉩니다. 따라서 도 수준별로 따로 계산해야 합니다.
3.1 Snijders & Bosker (SB)
Snijders와 Bosker(1994)는 “예측 오차의 감소(reduction in prediction error)”라는 관점에서 를 정의했습니다.
- 1수준 (): 개별 학생의 점수를 얼마나 잘 예측하는가?
- 계산식에는 고정 효과(Fixed effects)뿐만 아니라 랜덤 효과(Random effects)의 분산도 포함됩니다.
- 기준 모델(Null Model)은 아무런 설명 변수가 없는 모델(절편만 있는 모델)입니다.
- 2수준 (): 학급 평균 점수를 얼마나 잘 예측하는가?
- 학급 수준의 설명력을 볼 때 사용합니다.
3.2 Edwards et al. ()
Edwards 등(2008)은 Wald F-통계량을 이용하여 를 계산하는 방식을 제안했습니다.
- 이 방법은 특정한 고정 효과(Fixed Effect)가 추가됨으로써 설명력이 얼마나 늘었는지를 보는 데 유용합니다.
- 분모의 자유도를 계산할 때 Kenward-Roger 근사를 사용하는 것이 권장됩니다.
[WaurimaL의 조언]
는 모형이 복잡해질 때(랜덤 효과 추가 등) 값이 오히려 줄어드는 경우가 있어 해석에 주의가 필요합니다. 반면 는 고정 효과의 설명력을 분리해서 보는 데 강점이 있습니다.
4. 정보 기준(Information Criteria): AIC와 BIC
모형의 적합도(Likelihood)와 간명성(Parsimony, 변수가 적을수록 좋음) 사이의 균형을 맞추는 지표입니다.
4.1 기본 개념
- Deviance (이탈도): 모형이 데이터를 얼마나 잘 설명 못하는가? (낮을수록 좋음).
- AIC (Akaike Information Criterion): 예측 정확도를 높이는 데 초점. 실제 모형이 후보군에 없어도 가장 근사한 모형을 찾음.
- (: 파라미터 수)
- BIC (Bayesian Information Criterion): ‘진짜 모형(True Model)’을 찾는 데 초점. 표본 크기()가 커질수록 페널티가 강해져서 더 단순한 모형을 선호함.
4.2 다층모형에서의 난제: 어떤 Likelihood를 쓸 것인가?
다층모형에서는 우도(Likelihood)를 계산하는 방식이 크게 두 가지로 나뉩니다. 이 부분이 가장 헷갈리는 부분이니 집중해 주세요.
(1) Marginal Likelihood (주변 우도) vs. Conditional Likelihood (조건부 우도)
- Marginal Likelihood (): 랜덤 효과()를 적분해서 없애버린 우도입니다. “전체 모집단(평균적인 학생)”에 대한 추론을 할 때 사용합니다.
- Conditional Likelihood (): 랜덤 효과()를 특정한 값으로 조건화한 우도입니다. “특정 학급(Cluster)”에 대한 예측을 할 때 사용합니다.
- Vaida & Blanchard(2005)는 이를 바탕으로 Conditional AIC (cAIC)를 제안했습니다.
(2) ML vs. REML
- ML (Maximum Likelihood): 고정 효과를 비교할 때 주로 사용합니다. 하지만 분산 성분(Variance Component)을 과소추정하는 경향이 있습니다.
- REML (Restricted ML): 분산 성분을 정확하게 추정합니다. 하지만 고정 효과 구조가 다른 모델끼리 비교할 때는 사용하면 안 됩니다 (예: 변수 A가 있는 모델 vs 없는 모델 비교 시 사용 불가).
- 예외: Gurka(2006) 같은 학자는 베이지안 관점에서 비교하기도 하지만, 일반적인 관례는 아닙니다.
5. 분석 실습: jamovi & R
이제 위에서 생성한 데이터를 바탕으로 세 가지 모형을 비교해 보겠습니다.
- Model A (Null Model): 설명변수 없음. (학교 간 차이만 확인)
- Model B (Random Intercept): 사교육 시간()과 교사 열정() 포함. (절편만 무작위)
- Model C (Random Slope): 사교육 시간()의 효과가 학급마다 다름을 허용. (기울기도 무작위)
5.1 분석 전략
- 도구: jamovi의
GAMLj모듈 또는Linear Mixed Models(기본). 여기서는 상세한 와 IC 계산을 위해 R 코드를 활용합니다. - 절차:
- Null Model로 급내상관계수(ICC) 확인.
- Model B 적합 후 및 AIC/BIC 확인.
- Model C 적합 후 Model B와 비교 (LRT 및 정보 기준).
5.2 R 코드 구현 (분석 및 결과 비교)
R
library(lme4)
library(performance) # R2 및 IC 계산을 위한 패키지
library(MuMIn) # r.squaredGLMM 등
# 1. Model A: Null Model
model_a <- lmer(MathScore ~ 1 + (1 | ClassID), data = data, REML = FALSE)
# 2. Model B: Random Intercept Model (고정효과 추가)
model_b <- lmer(MathScore ~ PrivateEdu + TeacherPassion + (1 | ClassID),
data = data, REML = FALSE)
# 3. Model C: Random Slope Model (상호작용 및 랜덤 기울기 추가)
model_c <- lmer(MathScore ~ PrivateEdu * TeacherPassion + (PrivateEdu | ClassID),
data = data, REML = FALSE)
# 4. 모형 비교 (AIC, BIC, Log-likelihood)
comparison <- compare_performance(model_a, model_b, model_c, metrics = c("AIC", "BIC", "R2"))
print(comparison)
# 5. Snijders & Bosker R2 계산 (MuMIn 패키지 활용)
r2_results <- r.squaredGLMM(model_c)
print(r2_results)
5.3 결과 해석 (가상의 결과값 예시)
| Criteria | Model A (Null) | Model B (Rand. Int) | Model C (Rand. Slope + Interaction) |
| AIC | 6982.3(<.001) | 6788.0(<.001) | 6389.9(>.999) |
| BIC | 6997.0(<.001) | 6812.5(<.001) | 6429.2(>.999) |
| Marginal | 0.000 | 0.169 | 0.205 |
| Conditional | 0.729 | 0.777 | 0.861 |
- 해석:
- AIC/BIC: Model C가 가장 낮은 값을 가지므로, “교사의 열정이 사교육 효과를 조절하며, 학급별로 사교육 효과가 다르다”는 모형이 가장 적합합니다. (AIC가 2 이상 차이 나면 유의미한 차이로 봅니다).
- : Conditional 가 0.861이라는 것은, 고정 변수와 학급별 랜덤 효과를 모두 고려했을 때 학생들의 성적 변동을 86.1% 설명한다는 뜻입니다.
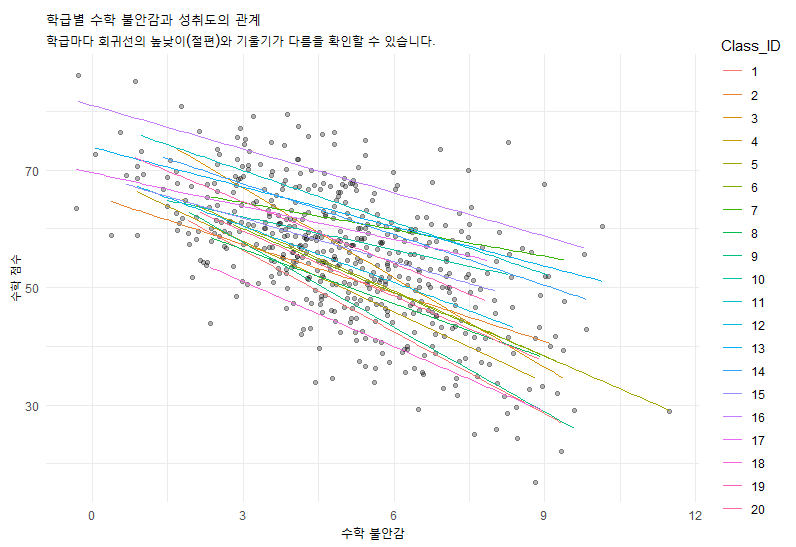
6. 시각화: 복잡한 수식 대신 그림으로
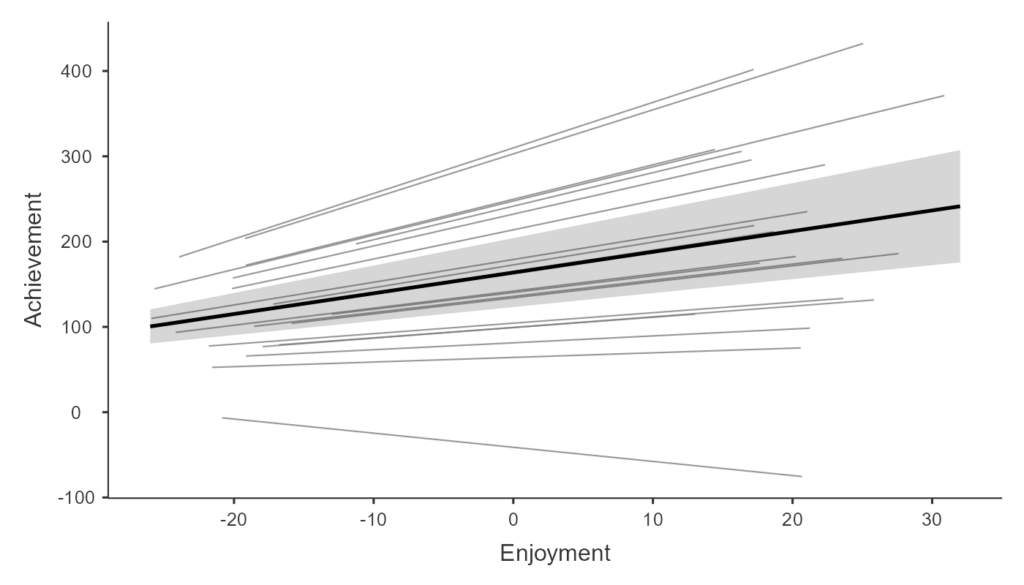
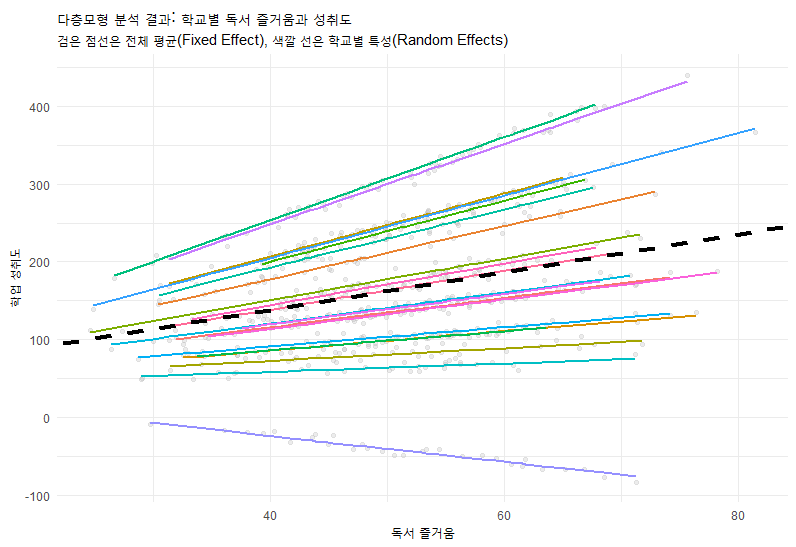
다층모형의 꽃은 시각화입니다. 학급별로 기울기가 다른 것을 보여주는 것이 Model C의 핵심입니다.
R
library(ggplot2)
# 예측값 생성
data$pred <- predict(model_c)
# 시각화
ggplot(data, aes(x = PrivateEdu, y = MathScore, group = ClassID)) +
geom_point(alpha = 0.1, color = "gray") + # 전체 데이터 점
geom_line(aes(y = pred, color = ClassID), alpha = 0.5) + # 학급별 회귀선
theme_minimal() +
theme(legend.position = "none") +
labs(title = "학급별 사교육 시간과 수학 성취도의 관계 (Random Slope Model)",
x = "사교육 시간", y = "수학 성취도")
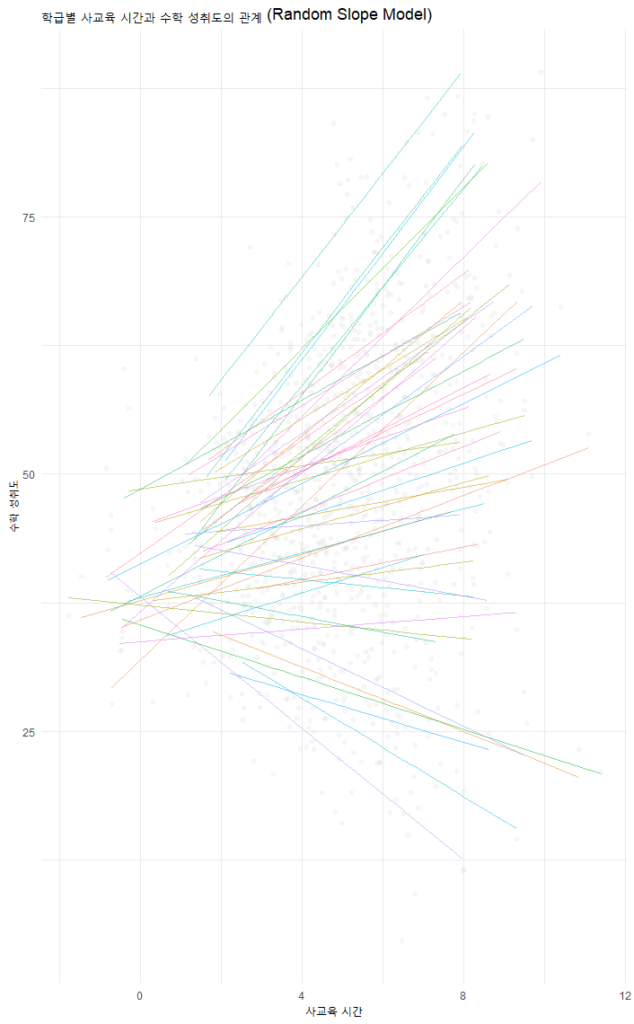
이 그래프를 보면, 어떤 반은 사교육 효과가 가파르고(기울기 급함), 어떤 반은 완만하다는 것을 한눈에 알 수 있습니다. 이것이 바로 Random Slope(랜덤 기울기)의 의미입니다.
7. 결론 및 제언
Steele 교수의 챕터 내용을 종합하면, 다층모형에서의 모형 선택은 다음과 같은 원칙을 따릅니다.
- 하나의 기준에 맹신하지 마세요. , AIC, BIC, 그리고 이론적 배경을 모두 고려해야 합니다.
- 연구 목적에 맞는 Likelihood를 선택하세요.
- 새로운 학교에 일반화하고 싶다면? → Marginal Likelihood (AIC)
- 특정 학급 내 학생을 예측하고 싶다면? → Conditional Likelihood (cAIC).
- 고정 효과 비교 시에는 ML, 최종 파라미터 추정은 REML을 사용하는 것이 정석입니다.
- 단순히 수치적으로 우수한 모델보다, “해석 가능하고(interpretable)” 실제 교육 현장의 현상을 잘 설명하는 모델을 선택하는 것이 중요합니다.
[참고 문헌]
- Akaike, H. (1973). Information theory and an extension of the maximum likelihood principle. In Second International Symposium on Information Theory (pp. 267–281). Springer Verlag.
- Burnham, K. P., & Anderson, D. R. (2002). Model selection and multimodel inference: A practical information-theoretic approach. Springer.
- Edwards, L. J., Muller, K. E., Wolfinger, R. D., Qaqish, B. F., & Schabenberger, O. (2008). An statistic for fixed effects in the linear mixed model. Statistics in Medicine, 27, 6137–6157.
- Gurka, M. J. (2006). Selecting the best linear mixed model under REML. The American Statistician, 60, 19–26.
- Snijders, T. A. B., & Bosker, R. J. (1994). Modeled variance in two-level models. Sociological Methods and Research, 22, 342–363.
- Steele, R. (2013). Model selection for multilevel models. In The SAGE Handbook of Multilevel Modeling (Chapter 7).
- Vaida, F., & Blanchard, S. (2005). Conditional Akaike information for mixed-effects models. Biometrika, 92, 351–370.